Evaluá modelos de IA en AWS sin servidores dedicados
Una empresa de medios necesitaba saber cuál modelo de IA generaba mejores resúmenes de podcasts a partir de artículos de noticias. La solución fue una plataforma de evaluación de modelos IA serverless en AWS que, con una sola llamada a la API, envía el artículo a múltiples modelos en paralelo, puntúa cada output con un modelo juez, y devuelve un reporte HTML comparativo completo.
En 30 segundos
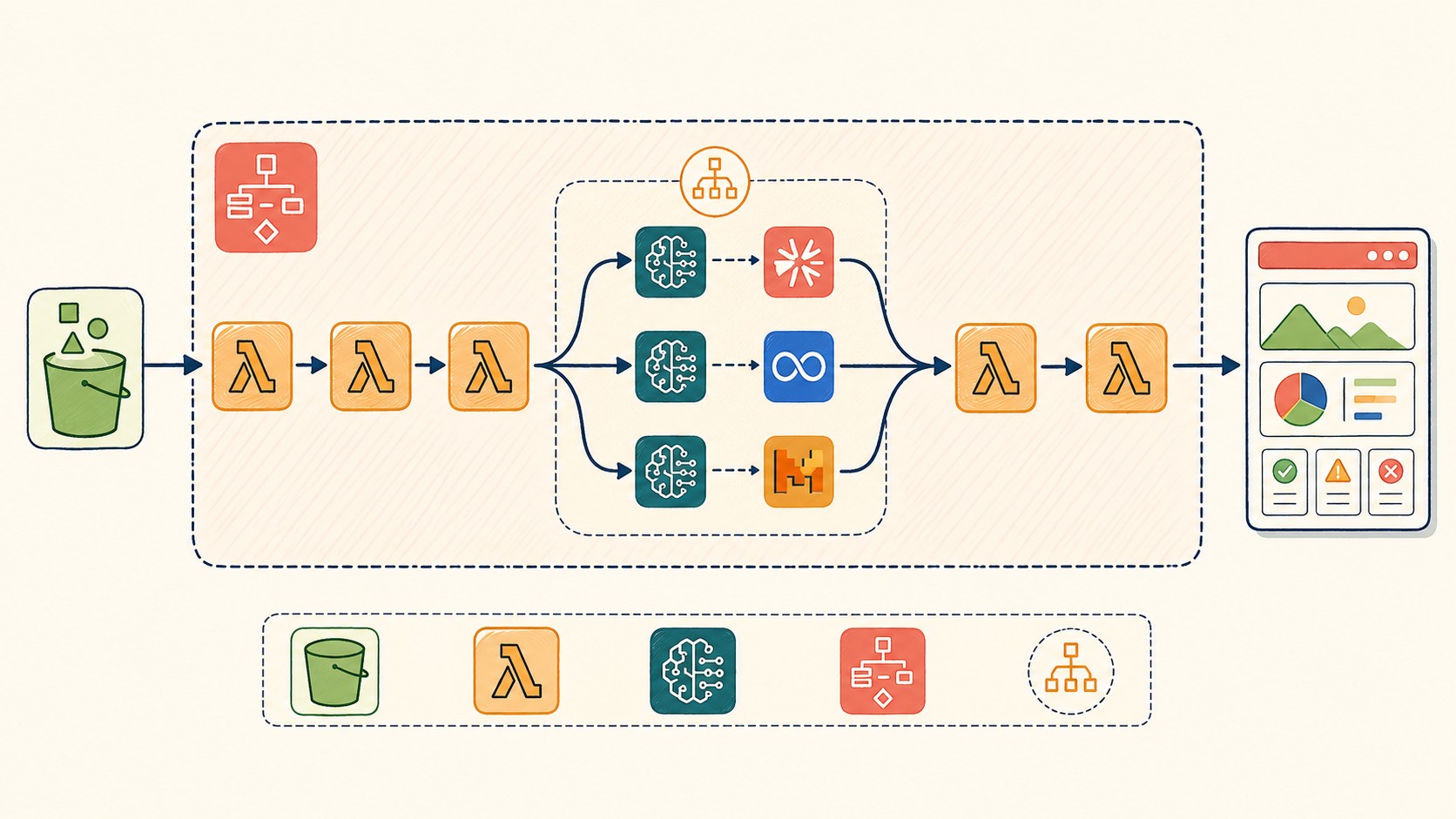
- La arquitectura usa AWS Step Functions para orquestar 6 funciones Lambda en secuencia, desde validación hasta reporte HTML final.
- Los modelos de Amazon Bedrock (Claude, Llama, Mistral) se invocan en paralelo con Map State, reduciendo la latencia total.
- Un segundo modelo actúa como “juez” y puntúa cada output según criterios de coherencia, precisión y relevancia.
- El modelo serverless es más económico que un endpoint dedicado en SageMaker para cargas bajas a medianas (4-8 artículos por día).
- Todo el pipeline se activa con una sola llamada a la API y no requiere infraestructura dedicada permanente.
Claude es un modelo de lenguaje grande desarrollado por Anthropic para procesar y generar texto, analizar información y asistir en programación. Fue introducido en 2023.
Por qué la evaluación manual de modelos no escala
Ponele que trabajás en una empresa de medios digitales y tu equipo decidió empezar a usar IA para generar resúmenes de podcast a partir de artículos. Fantástico. Ahora viene la parte incómoda: ¿qué modelo usás? ¿Claude Sonnet? ¿Llama 3? ¿Mistral? ¿El nuevo modelo que acaba de aparecer en Bedrock?
El flujo manual es el siguiente: abrís el playground de uno, pegás el artículo, leés el output, lo copiás a un doc. Repetís con el siguiente modelo. Después intentás comparar cinco resultados que escribiste en distintos momentos, con distintos niveles de atención, y llegás a una conclusión que en el fondo es bastante subjetiva. Eso no escala. Ni siquiera a diez artículos por semana.
Según el artículo publicado el 22 de mayo de 2026, exactamente ese era el problema de una empresa de medios real: necesitaban evaluar qué modelo producía los mejores resúmenes de podcasts a partir de noticias, con consistencia y a demanda. La solución fue automatizar todo el pipeline de evaluación sobre AWS, sin levantar ni un servidor dedicado.
Arquitectura serverless: Step Functions como orquestador central
Una plataforma de evaluación de modelos IA serverless en AWS se puede construir de varias formas, pero la elección de Step Functions como orquestador no es arbitraria.
La alternativa obvia sería una Lambda que llama a otras Lambdas directamente. El problema: si algo falla en el medio, no tenés estado persistente, el retry es manual, y el debugging es un infierno. Step Functions te da logging automático de cada transición, reintentos configurables por paso, y visibilidad de exactamente dónde falló el pipeline (en validación, en invocación al modelo, en scoring). Eso vale.
SageMaker también podría orquestar esto, pero viene con overhead operativo considerable: endpoints dedicados que cobran por hora aunque no los uses, configuración de instancias, gestión de modelos. Para evaluaciones on-demand, es sobredimensionado. Step Functions con Lambda escala a cero cuando no hay trabajo, y eso impacta directo en el costo.
La máquina de estados del caso real tiene seis funciones Lambda encadenadas. Cada una tiene una responsabilidad única y un motivo claro para existir separada del resto.
Los 6 pasos del pipeline: de la validación al reporte
Cada Lambda en la secuencia resuelve un problema concreto:
Paso 1: Validación del experimento
Lee la definición del experimento desde S3, verifica que el artículo esté presente, que los modelos estén especificados, que el prompt base exista. Si falla acá, el pipeline se detiene antes de gastar un solo token en Bedrock. Fail-fast puro. En automatización del pipeline de deployment profundizamos sobre esto.
Paso 2: Refinamiento del prompt con agente IA
Acá viene algo interesante: antes de enviar el prompt a los modelos evaluados, un agente de IA lo refina. Convierte las instrucciones del usuario en un prompt técnicamente efectivo para generación de resúmenes. El motivo es que los resultados del pipeline dependen de la calidad del prompt inicial, y no podés asumir que los usuarios van a escribir prompts óptimos.
Paso 3: Invocación paralela de modelos
Map State en Step Functions permite disparar múltiples invocaciones simultáneas a Bedrock. Cada modelo recibe el mismo prompt refinado y el mismo artículo. Los timeouts por modelo son independientes: si uno tarda demasiado o falla, el resto del reporte continúa igual.
Paso 4: Scoring automático con modelo juez
Una segunda invocación a Bedrock (generalmente Claude, según la arquitectura del caso) evalúa cada output contra criterios predefinidos. Devuelve scores numéricos reproducibles por criterio.
Paso 5: Formato HTML del reporte
Toma todos los outputs y scores, genera el HTML comparativo con los resúmenes lado a lado y las puntuaciones de cada modelo.
Paso 6: Persistencia en S3
Guarda el reporte en S3 con un identificador del experimento. Queda disponible para consulta posterior, auditoría y feedback humano.
¿Por qué seis Lambdas separadas y no una sola que haga todo? Porque si el scoring falla, podés reejecutar solo esa parte sin repetir las invocaciones a los modelos (que cuestan tokens). Debugging granular, escalabilidad independiente por paso.
Ejecución en paralelo: múltiples modelos Bedrock simultáneamente
Amazon Bedrock expone modelos de Anthropic (Claude Sonnet, Claude Haiku), Meta (Llama 3), Mistral y otros, todos accesibles vía API unificada. Eso significa que el código de invocación es prácticamente idéntico para todos los modelos, y podés agregar o quitar modelos del experimento sin tocar la lógica central.
La paralelización con Map State es directa: definís el array de modelos, Step Functions lanza una ejecución por ítem en paralelo. En vez de esperar 10 segundos por modelo (secuencial = 40 segundos para cuatro modelos), todos corren al mismo tiempo y el tiempo total es el del modelo más lento. En el caso real de la empresa de medios, esto era crítico para que el pipeline fuera usable en un flujo editorial. Tema relacionado: comparativa de modelos de lenguaje.
Eso sí: más modelos simultáneos significa más tokens consumidos en paralelo. No hay magia acá. El costo sube linealmente con la cantidad de modelos evaluados.
Scoring automático: el modelo juez que evalúa a los demás
El método “LLM-as-a-Judge” tiene sus limitaciones, pero para evaluación de resúmenes es razonablemente efectivo. La idea es que Claude (u otro modelo de alta capacidad) recibe el artículo original, el resumen generado por el modelo evaluado, y un conjunto de criterios explícitos. Devuelve una puntuación numérica y una justificación.
Los criterios típicos para evaluación de resúmenes incluyen: coherencia narrativa, precisión factual respecto al original, longitud apropiada, relevancia de la información seleccionada. Cada criterio puede tener su propio peso.
Para quienes vienen de NLP clásico: la métrica ROUGE (Recall-Oriented Understudy for Gisting Evaluation) sigue siendo el estándar para comparar resúmenes contra referencias humanas. ROUGE-1 mide solapamiento de unigramas, ROUGE-L mide la subsecuencia común más larga. Según la documentación de evaluación de LLMs, ROUGE por sí solo no captura calidad semántica, coherencia narrativa ni adecuación al contexto, que es exactamente lo que el enfoque LLM-as-a-Judge complementa.
¿El modelo juez puede tener sesgos? Sí. Claude tiene tendencia a preferir outputs más similares a su propio estilo. Por eso el pipeline contempla feedback humano posterior para recalibrar los criterios del juez con el tiempo.
Costos y optimización en la arquitectura serverless
La pregunta que siempre aparece: ¿cuánto sale esto? Depende del volumen. Para un caso como el de donweb.news con 4-8 artículos por día, el modelo serverless gana sin discusión.
| Componente | Serverless (Lambda + Step Functions) | Endpoint dedicado (SageMaker) |
|---|---|---|
| Costo base mensual | Casi cero si no hay ejecuciones | USD 50-200+ por instancia activa |
| Costo por evaluación (4 modelos) | USD 0.01-0.05 según tokens | Amortizado sobre el endpoint |
| Latencia por evaluación | 30-60 segundos (paralelo) | 10-20 segundos (endpoint caliente) |
| Overhead operativo | Bajo (serverless) | Alto (instancias, versiones, monitoring) |
| Escalabilidad a pico | Automática | Requiere configuración de auto-scaling |
Los costos en AWS Bedrock se cobran por tokens de entrada y salida. Con artículos de 800-1200 palabras (aproximadamente 1000-1500 tokens) y resúmenes de 200-300 tokens por modelo, una evaluación de cuatro modelos más scoring consume entre 8.000 y 12.000 tokens totales. A los precios de Bedrock en 2026, eso está en el rango de USD 0.02-0.08 por evaluación completa, según el mix de modelos que uses.
Step Functions cobra por transición de estado: con seis Lambdas más estados de inicio y fin, son alrededor de 10-12 transiciones por ejecución. A USD 0.025 por 1000 transiciones, es ruido en el presupuesto.
Si tu volumen crece a centenares de evaluaciones por hora, el análisis cambia. Pero para flujos editoriales medianos, serverless es la opción económicamente superior. Sobre eso hablamos en evaluación de diferentes modelos.
El reporte HTML y el loop de feedback
El output final del pipeline es un archivo HTML en S3 con los resúmenes de cada modelo en columnas, sus scores por criterio, y un análisis de qué modelo ganó y por qué. La empresa de medios del caso real usaba este reporte para validar antes de publicar y para ajustar qué modelo usar en producción.
Lo que distingue a los pipelines que mejoran con el tiempo es el feedback loop: botones de “útil/inútil” en el reporte que actualizan los criterios del modelo juez. Con suficiente feedback, el juez aprende qué es un buen resumen para ese caso de uso específico, no para resúmenes en general.
Guardás el reporte en S3, podés versionar experimentos (mismo artículo, diferentes fechas, diferentes modelos) y comparar cómo evoluciona la calidad con el tiempo. Eso es un activo real para tomar decisiones de adopción de modelos con datos propios en vez de depender de benchmarks del fabricante (que, seamos honestos, siempre muestran lo mejor posible).
Lo que significa para equipos de contenido en Latinoamérica
Si manejás un sitio de noticias, una plataforma de contenido o incluso un flujo editorial interno con IA, este tipo de infraestructura cambia cómo tomás decisiones sobre qué modelo usar.
Los benchmarks públicos como MMLU, HumanEval o HellaSwag son útiles para comparaciones generales, pero no te dicen nada sobre cómo se comporta un modelo con tus artículos, en español argentino, en tu formato específico. Un pipeline de evaluación propio sí te lo dice.
Para hostear el reporte HTML estático o integrar el pipeline con tu CMS, donweb.com ofrece infraestructura cloud y hosting pensado para el mercado argentino, que puede complementar lo que corrés en AWS.
El setup inicial requiere configurar AWS, Step Functions, permisos IAM y las Lambdas. No es trivial, pero tampoco es un proyecto de meses. Con la documentación de Amazon Bedrock sobre evaluación de modelos, un equipo técnico puede tener un prototipo funcional en una semana.
Errores comunes al armar este tipo de pipelines
Usar un solo criterio de scoring. Puntuar solo “calidad general” en vez de desagregar en coherencia, precisión y relevancia produce scores poco accionables. No sabés si el modelo perdió puntos por inventar datos o por ser muy corto.
Asumir que el modelo juez es neutral. Si usás Claude como juez para evaluar Claude vs. Llama, hay sesgo de homofilia documentado. Probá con un juez diferente al modelo que estás evaluando, o usá múltiples jueces y promediá.
No versionar los experimentos. Si cambiás el prompt del juez o los criterios y no guardás el estado anterior, perdés la comparabilidad histórica. Cada experimento debería tener un ID y metadatos de versión tanto del prompt como de los criterios de evaluación. Para más detalles técnicos, mirá cuál es el mejor modelo.
Ignorar los timeouts de Bedrock. Algunos modelos tienen latencias más altas bajo carga. Si no configurás timeouts por modelo en Step Functions y un fallback, una invocación colgada puede bloquear todo el reporte.
Si querés profundizar en esto, tenemos un artículo sobre Building a Serverless AI Model Evaluation Platform on AWS.
Esto se conecta con Building a Serverless AI Model Evaluation Platform on AWS, donde cubrimos el tema en profundidad.
Si querés profundizar, tenemos un artículo sobre Building a Serverless AI Model Evaluation Platform on AWS.
Esto se entrelaza perfecto con Building a Serverless AI Model Evaluation Platform on AWS.
Esto se conecta directamente con Building a Serverless AI Model Evaluation Platform on AWS, donde cubrimos la infraestructura necesaria.
Preguntas Frecuentes
¿Cómo evaluar automáticamente múltiples modelos de IA en AWS?
Con Step Functions orquestando Lambdas que invocan Amazon Bedrock en paralelo. El flujo es: validar inputs, refinar el prompt, invocar todos los modelos simultáneamente con Map State, puntuar cada output con un modelo juez, y generar un reporte comparativo guardado en S3. Todo se activa con una llamada a la API, sin infraestructura dedicada.
¿Qué arquitectura serverless se necesita para comparar modelos de IA?
La combinación central es AWS Step Functions + AWS Lambda + Amazon Bedrock. Step Functions maneja la orquestación y el estado, Lambda ejecuta cada paso del pipeline, y Bedrock provee acceso unificado a modelos de Anthropic, Meta, Mistral y otros. S3 almacena inputs y outputs. No hace falta ningún servidor o endpoint dedicado permanente.
¿Cómo usar AWS Lambda con Bedrock para evaluación de modelos?
Cada Lambda del pipeline recibe el contexto necesario (artículo, prompt, lista de modelos) e invoca la API de Bedrock con el model ID correspondiente. La API es uniforme entre modelos, por lo que el código cambia solo el identificador del modelo. Para invocación paralela, Step Functions Map State lanza una ejecución por modelo simultáneamente, y cada Lambda es independiente.
¿Es posible automatizar la puntuación de resúmenes generados por IA?
Sí, usando el método LLM-as-a-Judge: un modelo (generalmente de alta capacidad como Claude) recibe el texto original, el resumen a evaluar, y criterios explícitos de calidad. Devuelve scores numéricos reproducibles. Se puede complementar con métricas clásicas como ROUGE-1 y ROUGE-L para solapamiento léxico, aunque estas no capturan coherencia semántica.
¿Cuánto cuesta implementar un pipeline de evaluación serverless en AWS?
Para volúmenes bajos a medianos (4-8 evaluaciones diarias), el costo principal son los tokens de Bedrock: entre USD 0.02 y 0.08 por evaluación completa de cuatro modelos, según el mix usado. Lambda y Step Functions tienen costos marginales en este volumen. Comparado con un endpoint dedicado en SageMaker (USD 50-200+/mes de costo base), serverless es considerablemente más económico para demanda irregular.
Conclusión
Lo que demostró el caso de esta empresa de medios es que evaluar modelos de IA de forma sistemática ya no requiere infraestructura dedicada ni un equipo de MLOps. Con Step Functions, Lambda y Bedrock, podés tener un pipeline reproducible que corre on-demand y te da datos propios sobre qué modelo funciona mejor para tu caso de uso específico.
La clave está en tres decisiones de arquitectura: fail-fast con validación temprana, paralelización para que el tiempo total sea el del modelo más lento (no la suma de todos), y un modelo juez configurado con criterios propios en vez de depender solo de benchmarks externos. Si estás eligiendo modelos de IA para producción en 2026, tener tu propio pipeline de evaluación es la diferencia entre decidir con datos o decidir con marketing.
Fuentes
- Dev.to – Building a Serverless AI Model Evaluation Platform on AWS (caso real, mayo 2026)
- AWS Documentation – Evaluación de modelos en Amazon Bedrock
- Dev.to AWS Builders – Evaluación de modelos en Amazon Bedrock: el arte de la selección inteligente
- IA360 – Evaluación y métricas de rendimiento en modelos de lenguaje
- Nerds.ai – Evaluación de LLMs: principales benchmarks y cómo entenderlos

![[Databricks on AWS #4] The BOOTSTRAP_TIMEOUT Mystery: Tracing a Databricks Cluster from Data Plane to Control Plane (Transit Gateway + Firewall) - ilustracion](https://donweb.news/wp-content/uploads/2026/07/databricks-cluster-bootstrap-timeout-aws-firewall-hero-768x432.jpg)

