Observabilidad Kubernetes: antes de agregar otro agente
La observabilidad en Kubernetes empieza simple. Después, casi inevitablemente, se complica. Equipos que arrancaron con un par de herramientas terminan administrando cinco agentes distintos, pipelines redundantes y dashboards que nadie sabe bien de dónde vienen. El problema no es recolectar telemetría (eso es lo fácil) — es mantener todo manejable cuando la infraestructura crece.
En 30 segundos
- La observabilidad Kubernetes se complica progresivamente: los equipos agregan herramientas sin planificación y terminan con overhead operacional mayor al esperado.
- El verdadero desafío no es recolectar logs, métricas y trazas — es mantener los sistemas de observabilidad manejables cuando la infraestructura escala.
- Fluent Bit sigue siendo el estándar para logging a nivel de nodo (liviano, en C), mientras Grafana Alloy unifica logs, métricas, trazas y perfiles en un solo agente.
- El stack más adoptado en 2026: Prometheus + Grafana + Loki + Tempo, con OpenTelemetry como capa de instrumentación.
- Los errores más comunes: aislar herramientas por silos, no definir retención de datos, y sobre-alertar hasta que nadie le presta atención a las alertas.
Por qué la observabilidad Kubernetes empieza simple y se complica
La observabilidad en Kubernetes es la capacidad de entender el estado interno de un cluster a partir de los datos que genera: logs, métricas y trazas. En clusters pequeños, con dos o tres servicios, alcanza con un Prometheus básico y mirar los logs por consola. El problema aparece cuando el sistema crece.
Ponele que tenés un equipo que arranca con Fluent Bit para logs, Prometheus para métricas, y un par de dashboards en Grafana. Funciona. Después alguien necesita trazas distribuidas y agrega Jaeger. Otro necesita profiling y suma otro agente. De repente tenés cuatro o cinco componentes corriendo en cada nodo, ninguno habla con el otro de forma coherente, y el overhead operacional te empieza a comer tiempo real de desarrollo.
Según el análisis publicado en mayo de 2026, este patrón se repite con una consistencia llamativa: los equipos van sumando componentes de monitoreo gradualmente, sin una estrategia de conjunto, y terminan con más complejidad de la que esperaban. La discusión sobre herramientas deja de ser sobre features y se vuelve operacional. Cuánto consume cada agente. Cómo se actualiza. Quién lo mantiene cuando falla.
Los tres pilares: logs, métricas y trazas
Kubernetes hace que los tres pilares de observabilidad sean críticos de una forma que no tenés en un monolito tradicional.
Los logs son eventos ordenados cronológicamente que generan los pods y los componentes del sistema. En Kubernetes cada pod puede reiniciarse, moverse de nodo, o escalar horizontalmente — y necesitás centralizar esos logs antes de que el pod desaparezca y te lleve los datos consigo.
Las métricas (CPU, memoria, latencia, errores por segundo) te dicen si el sistema está saludable ahora mismo. Prometheus scrapea endpoints /metrics cada 15-30 segundos y guarda series temporales que podés consultar con PromQL. Esto se conecta con lo que analizamos en cómo configurar pipelines de CI/CD.
Las trazas muestran cómo se mueve un request a través de microservicios. Si una request tarda 2 segundos y pasó por seis servicios, las trazas te dicen exactamente cuál de los seis tardó 1.8 segundos. Sin trazas, debuggear latencia en sistemas distribuidos es básicamente adivinar.
La trampa de la complejidad: más agentes no siempre es mejor
Acá viene lo bueno: recolectar telemetría es técnicamente sencillo. Mantener el sistema de observabilidad manejable cuando tenés 50 nodos, tres clusters y 200 microservicios — eso es donde la gente pierde semanas.
El problema típico: cada herramienta nueva que agregás necesita configuración propia, actualizaciones propias, troubleshooting propio. Si tenés Fluent Bit para logs, cAdvisor para métricas de containers, node-exporter para métricas de nodo, un agente de APM de otra empresa y OpenTelemetry Collector encima — eso son cinco binarios corriendo en cada nodo, cinco pipelines que configurar, cinco puntos de falla.
¿Y qué pasa cuando uno de esos agentes tiene un bug de memoria y empieza a consumir 4GB en cada nodo? Exacto: o lo matás y perdés visibilidad, o dejás que se coma los recursos de producción.
Fluent Bit vs Grafana Alloy: cuál elegir en 2026
Esta es la comparativa que más se repite ahora mismo. Según el análisis de KubeBlogs publicado en 2026, la elección no es técnica sino operacional: depende de qué tan complejo es tu pipeline y cuánto querés unificar.
Fluent Bit: especialista en logs
Escrito en C, consume muy poca memoria (típicamente 450KB de base), y hace una sola cosa bien: recolectar y enrutar logs. Es el estándar de facto para node-level logging en Kubernetes desde hace años. Si lo que necesitás es tomar los logs de /var/log/containers en cada nodo y mandárselos a Loki, Elasticsearch o S3 — Fluent Bit es la opción obvia. Simple de configurar, liviano, battle-tested.
El límite aparece cuando querés hacer algo más complejo: enriquecer logs con metadatos de Kubernetes, manejar backpressure sofisticado, o integrar métricas en el mismo pipeline. Ahí empezás a pirarle la configuración. En elegir entre Jenkins y GitHub Actions profundizamos sobre esto.
Grafana Alloy: agente unificado
Alloy (antes Grafana Agent) unifica logs, métricas, trazas y perfiles en un solo binario con un lenguaje de configuración propio (River/Alloy syntax). La ventaja: en vez de cuatro agentes distintos, tenés uno solo. La desventaja: es más complejo de configurar y consume más recursos que Fluent Bit en modo logs-only.
LiveRamp migró su monitoreo de Kubernetes a Grafana Alloy con Fleet Management y reportó mejoras en la gestión centralizada de configuración a través de múltiples clusters. El valor real de Alloy no es en un cluster chico — es cuando tenés pipelines complejos que antes requerían varios agentes coordinados.
| Característica | Fluent Bit | Grafana Alloy |
|---|---|---|
| Señales soportadas | Logs (principalmente) | Logs, métricas, trazas, perfiles |
| Consumo de memoria base | ~450KB | ~50-100MB |
| Lenguaje config | YAML/INI | Alloy (River) |
| Curva de aprendizaje | Baja | Media-alta |
| Ideal para | Node-level logging simple | Pipelines complejos, multi-señal |
| Fleet management | No nativo | Sí (Grafana Fleet) |
| Integración con Loki | Nativa y documentada | Nativa vía componentes |
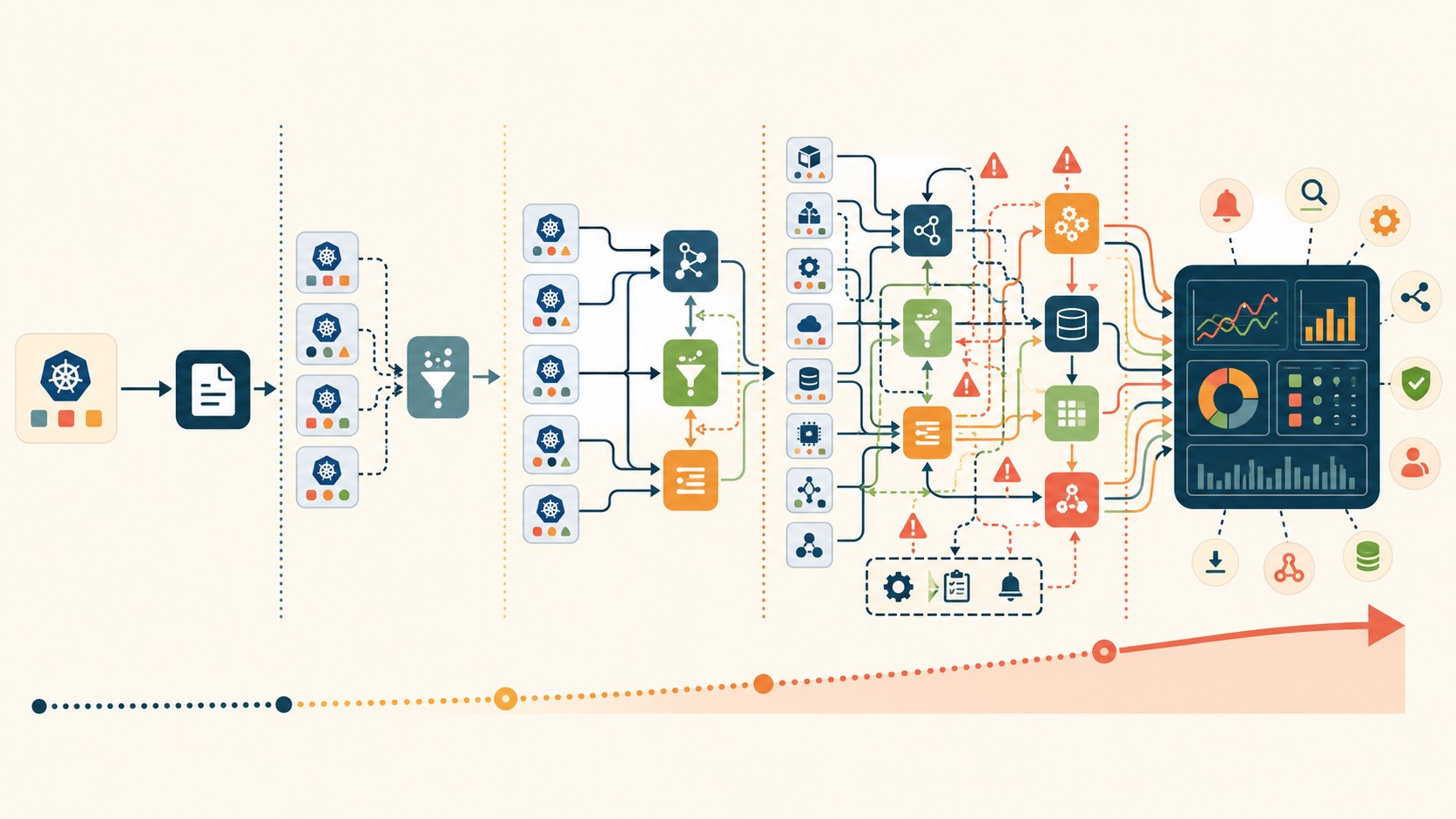
El stack estándar: Prometheus, Loki, Tempo y OpenTelemetry
Si arrancás desde cero en 2026, el stack más adoptado en la comunidad Kubernetes es:
- Prometheus: scraping de métricas, alertas vía Alertmanager
- Grafana: visualización, dashboards, correlación entre señales
- Loki: almacenamiento de logs indexado por labels (no full-text, lo cual lo hace más barato que Elasticsearch)
- Tempo: backend de trazas distribuidas compatible con OpenTelemetry
- OpenTelemetry Collector: capa de instrumentación y recolección agnóstica al backend
OpenTelemetry merece mención especial. Según Elastic, OpenTelemetry se consolidó como el estándar de instrumentación para Kubernetes: te permite instrumentar tu código una vez y mandar los datos a cualquier backend (Grafana, Datadog, Elastic, lo que sea). Eso evita el lock-in de instrumentar directamente contra el SDK de un proveedor.
Las soluciones integrales (Datadog, Dynatrace, New Relic, Elastic) te dan todo en uno con menos configuración. El trade-off es el costo: Datadog puede salir caro a escala, especialmente si medís por host o por GB de logs ingestados. Para equipos chicos o medianos, el stack open source probablemente tenga más sentido.
Errores comunes que disparan la complejidad
Tres errores que se repiten consistentemente:
Silos por tipo de señal. Tener un equipo que maneja logs, otro que maneja métricas, y nadie que correlacione ambos. Cuando hay un incidente, tardás el doble en diagnosticar porque los datos están en herramientas distintas sin forma de cruzarlos. La solución es un backend que unifique logs y métricas con el mismo timestamp y los mismos labels de Kubernetes.
Sin estrategia de retención. Loki guarda todo por default. Prometheus también. Si no configurás retención desde el día uno, en tres meses estás pagando por almacenar logs de pods que ya no existen. Definí cuántos días necesitás logs en hot storage, cuántos en cold, y qué datos nunca necesitás guardar.
Fatiga de alertas. Configurás alertas para todo — CPU alta, memoria alta, latencia alta, errores 5xx — y a la semana nadie las mira porque suenan cincuenta veces por día por falsos positivos. Las alertas útiles son las que requieren acción humana inmediata. Todo lo demás va a dashboard o a un log de bajo nivel. Si estás considerando agregar una alerta, preguntate: ¿qué hace el on-call cuando recibe esta notificación a las 3am? Sobre eso hablamos en monitoreando seguridad en infraestructura.
Qué está confirmado / Qué no
Confirmado:
- Fluent Bit y Grafana Alloy son las dos opciones más adoptadas para recolección de logs en Kubernetes en 2026, con casos de uso claramente distintos.
- OpenTelemetry es el estándar de instrumentación recomendado por la CNCF (Cloud Native Computing Foundation) y tiene soporte en todos los backends principales.
- La documentación oficial de Kubernetes incluye guías de observabilidad con Prometheus como primera opción para métricas.
- Grafana Alloy Fleet Management está en producción en empresas como LiveRamp con múltiples clusters.
Pendiente o no confirmado:
- No hay benchmarks independientes recientes que comparen el consumo real de Grafana Alloy vs Fluent Bit en clusters de producción a gran escala. Los números que circulan vienen principalmente de los propios fabricantes (tomalo con pinzas).
- La adopción de OpenTelemetry para trazas sigue siendo menor que para logs y métricas — habría que ver cuánto se consolida en los próximos meses.
Mejores prácticas para mantener observabilidad manejable a escala
Unificar las tres señales en una sola vista correlacionada no es opcional cuando tenés más de veinte pods. Si un pod falla, querés ver el log del error, la métrica de CPU en ese momento, y el trace de la request que falló — todo junto, con el mismo timestamp.
Definí SLOs (Service Level Objectives) antes de configurar alertas. Un SLO de 99.5% de disponibilidad mensual te da contexto para saber cuándo una alerta es urgente y cuándo puede esperar hasta mañana. Sin SLOs, todas las alertas parecen igual de importantes (ninguna lo es).
La infraestructura de observabilidad también crece. Elegí herramientas que escalen: Loki es más económico que Elasticsearch para logs en clusters grandes porque indexa por labels, no full-text. Prometheus con Thanos o Cortex te da retention largo plazo sin explotar el disco local.
Roadmap práctico: de simple a robusto
Si estás arrancando o reorganizando la observabilidad de tu cluster, esta secuencia tiene sentido:
- Paso 1: Prometheus + Grafana básico. Scrapeás métricas de nodos y pods, tenés dashboards mínimos. Sirve para clusters de desarrollo o staging pequeños.
- Paso 2: Agregás Loki para logs centralizados con Fluent Bit como agente de recolección en cada nodo. Ahora podés ver logs sin hacer kubectl logs en cada pod.
- Paso 3: Sumás Tempo para trazas distribuidas si tus servicios se comunican entre sí. Instrumentás con OpenTelemetry SDK para no quedar atado a un vendor.
- Paso 4: Si los pipelines se vuelven complejos (necesitás transformar, enriquecer o enrutar a múltiples backends), evaluá Grafana Alloy para reemplazar o complementar Fluent Bit.
- Paso 5: Si operás múltiples clusters o el overhead de administrar el stack open source supera el valor que da, evaluá soluciones integrales — con presupuesto claro para saber qué aplica en tu caso.
Si además del cluster necesitás infraestructura web para exponer tus aplicaciones, donweb.com tiene opciones de cloud y VPS compatibles con stacks Kubernetes administrado.
Preguntas Frecuentes
¿Por qué la observabilidad de Kubernetes se vuelve más compleja con la escala?
Porque los equipos agregan herramientas de monitoreo de forma incremental sin una estrategia de conjunto. Cada nuevo requerimiento (logs, métricas, trazas, profiling) suma un agente o pipeline nuevo, y el overhead operacional de administrar esos componentes crece más rápido que la infraestructura misma. El problema no es técnico sino de planificación.
¿Fluent Bit o Grafana Alloy: cuál elegir para monitoreo de logs en 2026?
Depende del caso de uso. Fluent Bit es la elección correcta si solo necesitás recolectar logs a nivel de nodo y mandarlos a un backend — consume muy poca memoria (~450KB base) y es simple de operar. Grafana Alloy tiene sentido cuando necesitás unificar logs, métricas, trazas y perfiles en un solo agente, especialmente en entornos con múltiples clusters donde el fleet management centralizado aporta valor real. Tema relacionado: integraciones completas para DevOps.
¿Cuáles son los componentes clave para observabilidad en Kubernetes?
El stack más adoptado en 2026 combina Prometheus (métricas), Loki (logs), Tempo (trazas) y Grafana (visualización), con OpenTelemetry como capa de instrumentación agnóstica. Este conjunto es open source, mantenido por la CNCF, y escala bien hasta clusters medianos-grandes. Para entornos enterprise con requerimientos de SLA o soporte, las plataformas integradas como Datadog o Elastic ofrecen todo en uno con soporte comercial.
¿Cómo evitar la fatiga de alertas en Kubernetes?
Definí alertas únicamente para situaciones que requieren acción humana inmediata. El resto va a dashboards o logs de baja prioridad. Una práctica efectiva es vincular cada alerta a un SLO específico: si la alerta no indica que un SLO está en riesgo, probablemente no necesite despertar a nadie a las 3am. Revisá y depurá las alertas cada mes — si una alerta nunca generó acción real en 30 días, desactivala o bajá su severidad.
¿Qué es OpenTelemetry y por qué importa para Kubernetes?
OpenTelemetry es un estándar open source, mantenido por la CNCF, para instrumentar aplicaciones y recolectar telemetría (logs, métricas, trazas) de forma agnóstica al backend. En Kubernetes permite instrumentar el código una sola vez y enviar los datos a cualquier plataforma de observabilidad compatible — Grafana, Elastic, Datadog, New Relic. Eso evita el lock-in de instrumentar directamente con el SDK de un proveedor, lo cual se vuelve relevante si en el futuro cambiás de backend.
Conclusión
La observabilidad Kubernetes no es un problema de herramientas — es un problema de estrategia. Elegir Fluent Bit vs Grafana Alloy importa menos que decidir desde el principio cuántos agentes querés administrar, cómo van a correlacionar las tres señales, y qué retención de datos tiene sentido para tu presupuesto.
El patrón que describe el análisis de mayo de 2026 es real: los equipos que terminan con sistemas de observabilidad inmanejables no tomaron malas decisiones técnicas — tomaron buenas decisiones técnicas de forma aislada, una por una, sin el contexto del conjunto. La complejidad no aparece en un día; se acumula en incrementos razonables hasta que el overhead operacional te frena.
Si estás rediseñando la observabilidad de tu cluster ahora, el punto de partida no es “qué herramienta agrego” — es “qué estoy dispuesto a operar a largo plazo”.
Fuentes
- Dev.to — Kubernetes Observability Usually Gets More Complicated Before It Gets Better (2026)
- KubeBlogs — Fluent Bit vs Grafana Alloy: Kubernetes Observability 2026
- Kubernetes.io — Documentación oficial de observabilidad
- Elastic — Implementando observabilidad Kubernetes con OpenTelemetry
- LiveRamp — Monitoreo Kubernetes con Grafana Alloy Fleet Management