Por qué Cloudflare D1 no escala para todo (2026)
Cloudflare D1 es la base de datos SQLite serverless de Cloudflare, diseñada para correr dentro de Workers con latencia mínima. El problema: tiene un límite duro de 10GB por base de datos, arquitectura single-threaded, y una API que durante años tuvo comportamientos sin documentar. Sushidata, uno de los usuarios más exigentes de la plataforma, llegó a tener 421 bases D1 en producción antes de concluir que ningún workaround iba a sostener su escala.
En 30 segundos
- D1 tiene un límite duro de 10GB por base de datos que no podés aumentar pagando más — es una restricción de arquitectura.
- La ejecución es single-threaded: una query de 10ms limita el throughput a 100 requests/s por base; una de 100ms te deja en 10 req/s.
- Sushidata documentó en mayo de 2026 que llegó a 421 bases D1 en producción y terminó construyendo su propia solución.
- El sharding manual (múltiples bases + asignación por hash) escala hasta ~500GB, pero agrega complejidad operacional considerable.
- Para cargas de trabajo de alto volumen de escritura o multi-tenant exigente, Durable Objects o una base PostgreSQL detrás de Hyperdrive son opciones más realistas.
Cloudflare es una empresa de infraestructura de internet que proporciona servicios de CDN, seguridad web y bases de datos en la nube. Fundada en 2010, ofrece herramientas como Cloudflare D1 para almacenamiento y gestión de datos escalables.
Qué es Cloudflare D1 y por qué se hizo popular
Cloudflare D1 es una base de datos SQLite serverless que corre directamente dentro del ecosistema de Workers, con acceso por bindings sin latencia de red. Entró en alfa privado en agosto de 2022 y llegó a beta pública en septiembre de 2023. La propuesta era clara: SQL familiar, gratis para empezar, sin servidores que gestionar, y con la ventaja de estar físicamente cerca del edge donde corre tu código.
Para proyectos chicos y medianos, eso es un golazo. Sin configuración, sin instancias que escalar, sin preocuparte por conexiones. Cualquiera que haya arrancado un proyecto nuevo en 2023 y necesitara persistencia entendía por qué D1 parecía la opción obvia dentro del stack de Cloudflare.
El problema apareció cuando la gente empezó a usarlo en serio.
El verdadero problema del límite de 10GB
Hay un malentendido frecuente acá: el límite de 10GB por base de datos en D1 no es algo que se resuelve pagando un plan superior. Según la documentación oficial de Cloudflare, es una restricción de arquitectura. No existe una opción “premium” que lo suba.
Para una app de contenido estático o un catálogo de productos, 10GB alcanza y sobra. Para aplicaciones multi-tenant donde cada tenant tiene su propia base (el patrón recomendado por Cloudflare para aislar datos), el problema se escala rápido: si tenés 1,000 clientes y cada uno crece a 5GB, estás manejando 5TB distribuidos en cientos de bases.
Sushidata llegó a 421 bases D1 en producción (según su propio postmortem de mayo de 2026) antes de decidir que el modelo no sostenía lo que venía. Eso no es un edge case: es el resultado natural de construir un SaaS con crecimiento real sobre una base que tiene límites por diseño.
La arquitectura single-threaded: el cuello de botella que nadie menciona en los tutoriales
Acá viene el problema que más subestima la gente que evalúa D1 desde un tutorial de 5 minutos.
Cada instancia D1 procesa queries de forma secuencial. Una a la vez. Eso significa que el throughput máximo de una base D1 está directamente determinado por la duración de cada query. La matemática es simple: si tus queries tardan 10ms en promedio, podés procesar 100 requests por segundo. Si tardan 100ms, bajás a 10 req/s. Sin excepciones, sin paralelismo interno que lo compense.
En una base de datos tradicional con múltiples workers o conexiones concurrentes, esto no es un problema porque el motor distribuye la carga. En D1, no hay distribución. Si dos requests intentan escribir al mismo tiempo, una espera a la otra. Siempre.
Para aplicaciones read-heavy con queries simples y rápidas, esto zafa. Para aplicaciones con writes frecuentes, queries complejas, o picos de tráfico concentrados, es un techo real que llegás a tocar antes de lo que pensás.
7 problemas concretos que documentó Sushidata en producción
El postmortem de Sushidata es probablemente la documentación más honesta que existe sobre las limitaciones de Cloudflare D1 y sus alternativas en condiciones de carga real. Acá van los problemas específicos que reportaron:
- REST vs bindings: Acceder a D1 vía API REST es significativamente más lento que por bindings directos en Workers. Problema: si necesitás acceder desde fuera de Workers (scripts de migración, herramientas externas), estás atrapado con la API lenta.
- Rate limiting de API: El límite inicial era de 1,200 requests por minuto. Lo empujaron hasta que Cloudflare los subió a 9,000+, pero el proceso tomó tiempo y fricción.
- Batch queries sin documentar: La funcionalidad de batch queries existía pero estuvo sin documentación pública por más de dos años. Si no la conocías, no la usabas.
- Límite de 50,000 bases de datos: Hay un techo de bases D1 por cuenta. Para SaaS de escala, ese número puede alcanzarse.
- Sin migración ni sharding automático: Cuando una base llega al límite, no hay herramienta oficial para dividirla. Lo hacés vos o no se hace.
- Regionalidad: D1 tiene comportamientos de regionalidad que pueden afectar la latencia dependiendo de dónde están tus usuarios vs. dónde está replicada la base.
- Errores sin documentación: Varios códigos de error que encontraron en producción no tenían documentación oficial en el momento en que los golpearon.
Sushidata reportó varios de estos problemas desde el alfa privado de 2022. Algunos tardaron años en resolverse (o siguen sin resolverse). ¿Alguien los verificó de forma independiente? El postmortem es público, las fechas están ahí.
Soluciones que intentaron (y por qué no funcionaron del todo)
Antes de construir su propia solución, Sushidata probó varios caminos:
VIP bindings para tenants críticos: Separar los clientes más exigentes en bases dedicadas con acceso prioritario. Funciona como parche, pero no escala como estrategia: estás decidiendo manualmente qué clientes merecen mejor performance, y la lógica se vuelve difícil de mantener.
Prototipo de failover multi-proveedor: Exploraron arquitecturas con GCP, Azure, y Hyperdrive como backup para D1. El problema: se rompe la coherencia del stack. Pasás de “todo en Cloudflare” a “todo en Cloudflare excepto cuando falla, ahí usamos otra cosa”, y eso tiene su propia complejidad operacional. Ya lo cubrimos antes en herramientas de automatización de despliegues.
D1 Scheduler con Durable Objects: Intentaron usar Durable Objects para coordinar writes y reducir la presión sobre D1. Funciona para ciertos patrones, pero Durable Objects tiene sus propias curvas de aprendizaje y costos.
Ningún workaround resolvió el problema de fondo: el diseño de D1 tiene límites que son de arquitectura, no de configuración.
Sharding manual: cómo se escala de 10GB a 500GB
La solución más documentada para el límite de 10GB es el sharding manual: dividir los datos entre múltiples bases D1 y enrutar cada request a la base correcta usando una función determinística.
El approach más común usa SHA-256 sobre el ID del tenant o registro para asignar una base de destino. Tristan Trommer documentó en Medium cómo logró escalar a 500GB usando 50 shards de D1, con una función de routing que asigna cada tenant a un shard basándose en el hash de su ID.
Funciona. Eso sí, la complejidad operacional sube: tenés que mantener el schema consistente en todos los shards, las migraciones se aplican a cada base individualmente, las queries que cruzan shards no existen (o las implementás vos en el application layer), y cualquier rebalanceo de datos requiere migración manual.
Para 50 bases, es manejable. Para 421 bases como tuvo Sushidata, empieza a ser un trabajo de tiempo completo.
Alternativas reales que escalan mejor
Durable Objects
Para coordinación distribuida y estado stateful por entidad, Durable Objects es la herramienta nativa de Cloudflare. Cada Durable Object corre en una sola ubicación geográfica (colocation), lo que evita conflictos de concurrencia. Son más complejos de modelar que una base SQL, pero para ciertos patrones (chats, contadores, sesiones de usuario) son la solución correcta dentro del stack de Cloudflare. Tema relacionado: configurar sitios multiidioma correctamente.
Hyperdrive
Si ya tenés una base PostgreSQL o MySQL, Hyperdrive es un proxy de Cloudflare que reduce la latencia de conexión desde Workers. No reemplaza tu base: la envuelve. Es la opción si querés conservar el ecosistema de Cloudflare para el compute pero necesitar una base que escale sin los límites de D1.
Supabase + Cloudflare Pages
Para proyectos que necesitan PostgreSQL completo con Row Level Security, funciones, y un backend maduro, Supabase para el backend + Cloudflare Pages para el frontend es un stack que funciona bien en producción. Perdés la integración nativa con Workers, pero ganás una base de datos que no tiene límites artificiales de 10GB.
| Opción | Límite de datos | Concurrencia | Complejidad | Mejor para |
|---|---|---|---|---|
| Cloudflare D1 | 10GB/base | Single-threaded | Baja | Apps pequeñas, read-heavy |
| D1 con sharding | ~500GB (50 shards) | Single-threaded por shard | Alta | Multi-tenant con tenants moderados |
| Durable Objects | Sin límite fijo | Por objeto | Media-alta | Estado por entidad, coordinación |
| Hyperdrive + PG | Sin límite fijo | Multi-threaded | Media | Apps existentes con PostgreSQL |
| Supabase | Sin límite fijo | Multi-threaded | Media | Backend completo con SQL moderno |
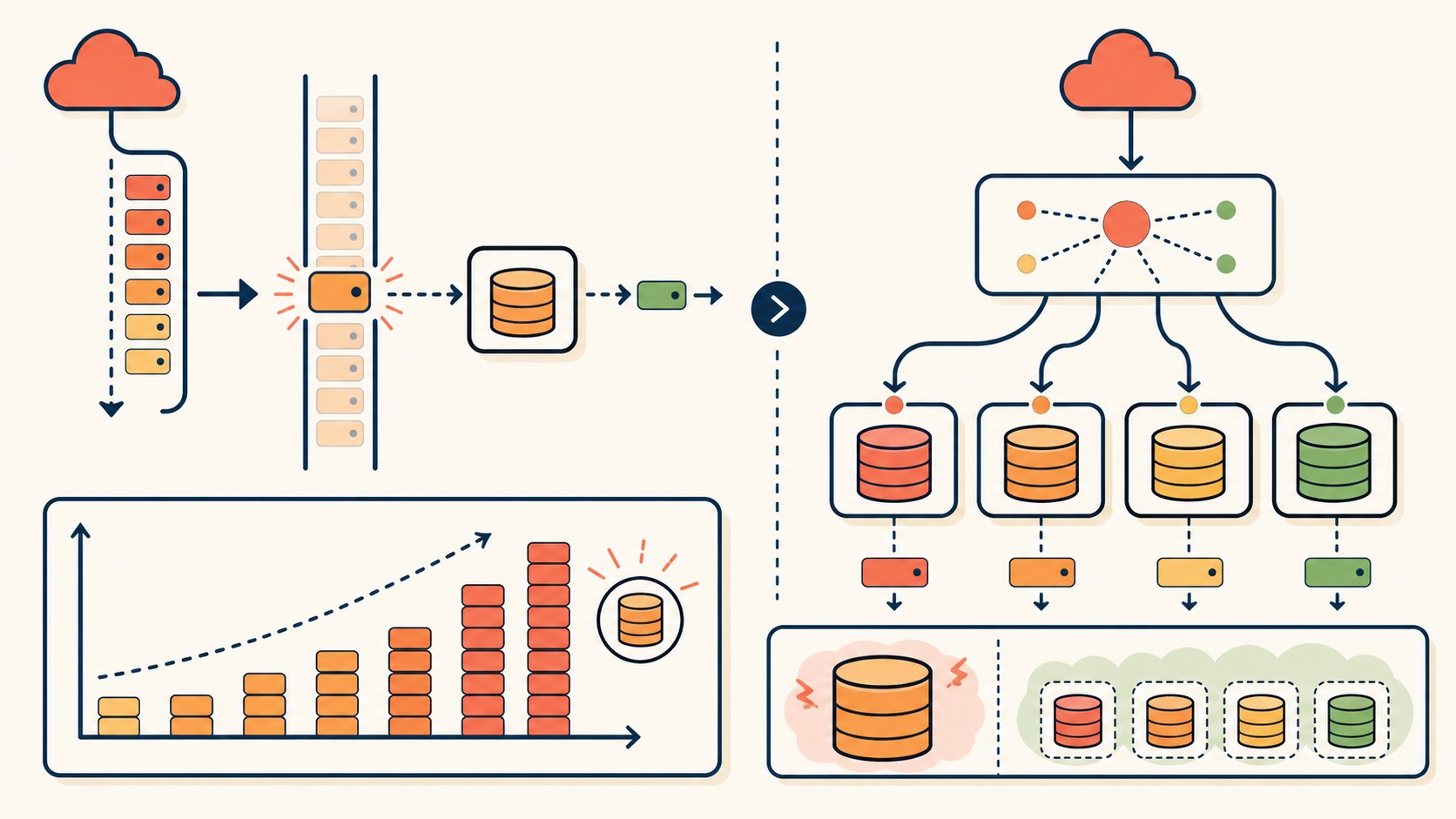
¿Cuándo D1 sigue siendo la elección correcta?
Con todo lo anterior, D1 no es una herramienta rota. Tiene casos de uso donde es exactamente lo que necesitás.
Si construís un sitio de contenido estático con búsqueda, un catálogo de productos, perfiles de usuario de una app con tráfico moderado, o cualquier workload donde las lecturas superan ampliamente a las escrituras y los datos de cada base no van a crecer más de 2-3GB, D1 es una opción re piola. La latencia es mínima, la configuración es cero, y el costo en el plan gratuito cubre casos de uso reales.
El problema aparece cuando la arquitectura crece y los límites dejan de ser teóricos. En ese momento, el costo de migrar (que no existe ahora) empieza a acumularse en el costo de workarounds (que existe todos los días).
Qué significa para equipos que están evaluando el stack
Si estás armando un proyecto nuevo en 2026 y evaluás Cloudflare como infraestructura, la pregunta que hay que hacerse antes de elegir D1 es: ¿cuántos datos por tenant espero en 18 meses? Si la respuesta honesta supera los 5GB, el sharding manual va a estar sobre la mesa antes de lo que querés. Mejor planificar la arquitectura desde el principio. Relacionado: alternativas de infraestructura para ecommerce.
Para proyectos que ya están en D1 y sienten el techo: el sharding manual es viable, documentado, y en producción en varios casos reales. El costo es complejidad operacional, no dinero. Si tu equipo puede manejarlo, extiende la vida útil de la arquitectura. Si no, Hyperdrive sobre una base PostgreSQL convencional (o incluso un hosting con base de datos como los que ofrece donweb.com para proyectos con backend en la región) puede ser la transición más limpia.
Errores comunes al trabajar con D1
Usar la API REST cuando hay bindings disponibles
Muchos equipos acceden a D1 vía REST porque es lo que conocen de otras bases de datos. Dentro de Workers, los bindings directos son considerablemente más rápidos. Si usás REST desde un Worker, estás agregando latencia de red innecesaria. Usá REST solo cuando no tenés acceso a bindings (scripts externos, migraciones desde tu máquina).
Ignorar el throughput single-threaded en el diseño inicial
El error más común: diseñar la arquitectura asumiendo que D1 va a escalar horizontalmente como PostgreSQL. No lo hace. Ponele que tenés una feature que hace 3 writes por request: a 50 requests simultáneos, estás apilando 150 operaciones secuenciales. Si ese cálculo no lo hiciste antes de lanzar, lo vas a hacer cuando el sistema empiece a latir.
Esperar que el sharding sea transparente
Cuando alguien dice “escalamos con sharding”, suena sencillo. La realidad es que cada shard es una base separada: las migraciones se aplican a cada una individualmente, las queries que necesitan datos de múltiples shards no tienen soporte nativo, y el routing hay que implementarlo y mantenerlo. No es automático ni gratuito en tiempo de desarrollo.
Si te interesa el tema, We Outgrew Cloudflare D1 relata cómo otros saltaron a otra plataforma.
Profundizamos en We Outgrew Cloudflare D1, donde compartimos cómo escalamos la infraestructura.
Preguntas Frecuentes
¿Cuáles son los límites reales de Cloudflare D1 en 2026?
Según la documentación oficial de Cloudflare, el límite es 10GB por base de datos, con un máximo de 50,000 bases por cuenta. La ejecución es single-threaded, lo que limita el throughput a aproximadamente 100 req/s con queries de 10ms de duración. Estos límites no son configurables con planes pagos: son restricciones de arquitectura.
¿Por qué D1 es single-threaded y cómo afecta el rendimiento?
D1 usa SQLite bajo el capó, que por diseño procesa writes de forma secuencial. Cada base D1 atiende una query a la vez: si dos requests intentan escribir simultáneamente, una espera a la otra. El impacto es proporcional a la duración de tus queries: a mayor tiempo de ejecución por query, menor throughput máximo posible.
¿Cómo se puede escalar D1 más allá de 10GB?
La técnica documentada es sharding manual: crear múltiples bases D1 y enrutar cada request a la base correcta usando una función hash sobre el ID del tenant o registro. Tristan Trommer implementó este patrón llegando a 500GB usando 50 shards. El costo es complejidad operacional: migraciones, mantenimiento de schema y routing son responsabilidad del equipo.
¿Es D1 adecuado para aplicaciones multi-tenant de alto volumen?
Depende del volumen de escritura. Para apps donde los tenants tienen datos de lectura predominante y crecimiento moderado (menos de 5GB por tenant), D1 con una base por tenant funciona. Para SaaS con escrituras frecuentes, tenants que crecen más de 5GB, o picos de concurrencia, el single-threaded y el límite de 10GB se convierten en limitaciones operacionales antes de lo esperado.
¿Qué alternativas a D1 escalan mejor para aplicaciones grandes?
Dentro del stack de Cloudflare, Durable Objects sirve para estado stateful por entidad con coordinación distribuida; Hyperdrive conecta Workers a una base PostgreSQL o MySQL existente sin los límites de D1. Fuera del stack, Supabase combina bien con Cloudflare Pages para proyectos que necesitan PostgreSQL completo con Row Level Security y sin restricciones de tamaño.
Conclusión
D1 es una herramienta útil dentro de sus límites. El problema es que esos límites son más estrechos de lo que parecen cuando arrancás, y el costo de ignorarlos no aparece el día uno sino cuando ya tenés cientos de bases en producción y una arquitectura que no doblega.
Lo que documentó Sushidata en mayo de 2026 es valioso porque viene de alguien que usó D1 desde el alfa privado de 2022 y lo empujó hasta el techo. Las limitaciones de Cloudflare D1 y las alternativas que describen no son teóricas: son el resultado de años de producción real con escala real. Si estás evaluando D1 para algo que va a crecer, leé ese postmortem antes de comprometer la arquitectura. El tiempo de leerlo ahora es menor que el tiempo de migrar después.
Fuentes
- Sushidata — Why We Outgrew Cloudflare D1 (postmortem completo, mayo 2026)
- Cloudflare — Documentación oficial de límites de D1
- Tristan Trommer — Scaling Cloudflare D1 from 10GB to 500GB with manual sharding
- Cloudflare — D1 FAQ oficial
- InventiveHQ — Comparativa de bases de datos edge: D1, KV, DynamoDB, Firestore