Backups PostgreSQL de Render a S3 sin vendor lock-in
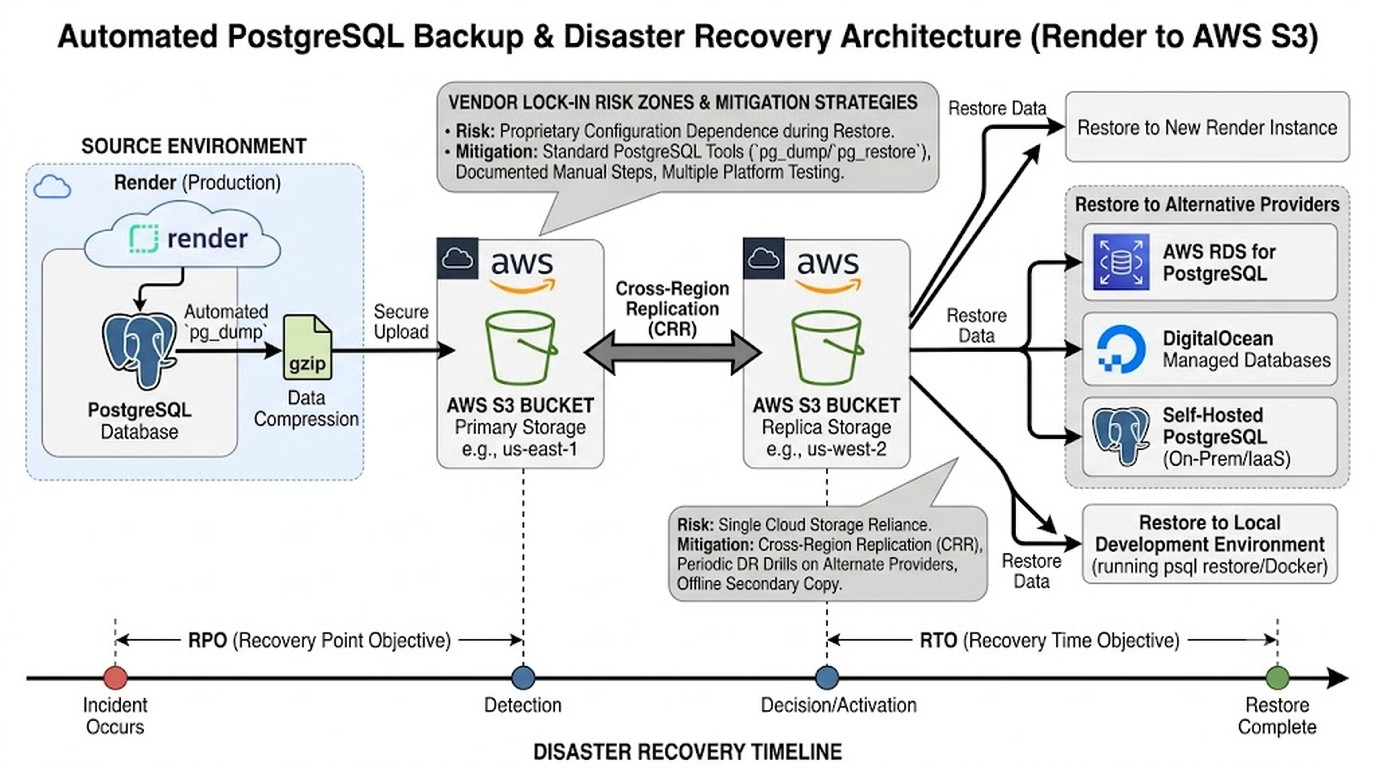
Configurar backups de PostgreSQL en Render a S3 se hace con un Cron Job que ejecuta pg_dump, comprime el volcado con gzip y lo sube a un bucket de Amazon S3 usando credenciales IAM de permisos mínimos. Así tenés una copia de tus datos fuera de la infraestructura de Render, lista para restaurar en cualquier proveedor. Para un SaaS multi-tenant, eso es la diferencia entre depender de un solo proveedor y dormir tranquilo.
En 30 segundos
- Render guarda backups, pero en su propia infraestructura: retiene 30 días y soporta point-in-time recovery, según su documentación. El problema es que el control de la copia y la restauración es de ellos, no tuyo.
- La solución es un Cron Job que corre
pg_dumpy sube a S3: tu base queda replicada en un bucket externo, portable a cualquier provider. - Necesitás un IAM user con permiso solo a S3: nada de credenciales root. Least privilege o nada.
- Restaurar es
gunzip+psql: dos comandos para levantar el dump en una instancia nueva. - SOC 2 lo pide: las auditorías exigen evidencia de que existen backups por fuera de la infraestructura primaria.
El caso que disparó esta nota lo contó el dev de CitizenApp, una plataforma que lleva dos años corriendo sobre Render y maneja datos sensibles de más de 200 organizaciones. Su frase resume el miedo de cualquiera que opere un SaaS serio: la primera vez que leyó la documentación de backups de Render, se dio cuenta de que dependía por completo de la infraestructura de ellos para recuperar sus datos. “Eso me aterró”, escribió. Y no es paranoia. Es haber leído suficientes reportes de incidentes.
Un backup de PostgreSQL a S3 es una copia lógica de tu base de datos (generada con pg_dump) almacenada en Amazon S3, un servicio de object storage. A diferencia del backup nativo de la plataforma, vive fuera del proveedor donde corre la app, lo que garantiza portabilidad, cumplimiento de compliance y recuperación ante desastres incluso si el proveedor primario se cae o discontinúa el servicio.
¿Por qué los backups de Render no alcanzan para datos críticos en multi-tenant?
El sistema de backups de Render es confiable. Para los fines de Render. Retiene las copias 30 días, soporta PITR y el proceso de restauración, según el propio relato del usuario de CitizenApp, “funciona sin fricciones”. Hasta acá todo bien.
El tema es que hay una asimetría de fondo: ellos controlan el backup, ellos controlan el restore, y ellos deciden cuánto vive tu dato. Vos sos un pasajero en tu propia recuperación. Sobre eso hablamos en gestión segura de credenciales de acceso.
Tres cosas concretas que te tendrían que quitar el sueño si manejás datos de varios clientes en la misma plataforma:
- Portabilidad limitada: tus datos son tan exportables como las capacidades de exportación de Render lo permitan. Si querés migrar a otro proveedor, dependés de su herramienta.
- Compliance: las auditorías SOC 2 suelen pedir evidencia de que existen backups por fuera de la infraestructura primaria. Un backup que vive en el mismo lugar que la base no cuenta como copia independiente.
- RTO en caída de plataforma: si Render tiene un outage, no podés restaurar aunque tengas la copia, porque la copia está adentro del sistema caído.
Para CitizenApp, con datos de 200+ organizaciones, eso no era aceptable. Y la verdad es que para cualquier SaaS que cobre por confiabilidad, tampoco debería serlo.
¿Cómo configurar backups automáticos de PostgreSQL en Render a S3?
La arquitectura es simple, y eso es lo bueno. Render tiene Cron Jobs nativos. Aprovechás eso para correr un script que hace el dump y lo empuja a S3. Sin servidores extra, sin infra rara.
El flujo básico, paso a paso:
- Creás el bucket S3: uno dedicado a backups, con versioning activado y acceso público bloqueado. Nada de mezclarlo con assets de la app.
- Generás el dump comprimido:
pg_dump $DATABASE_URL | gzip > backup_$(date +%Y%m%d_%H%M%S).sql.gz. El timestamp en el nombre te evita pisar archivos. - Lo subís a S3: con
aws s3 cp backup_*.sql.gz s3://tu-bucket/postgres/. - Lo programás como Cron Job en Render: definís la frecuencia en la config del job (por ejemplo, diario a las 3 AM, o cada 4 horas si tu RPO lo exige).
- Logueás todo: que el script imprima inicio, tamaño del dump y resultado del upload. Un backup que falla en silencio es peor que no tener backup.
Ojo con un detalle: el pg_dump tiene que apuntar a la connection string interna de Render para no pagar transferencia de salida innecesaria. Y la compresión con gzip no es opcional. Una base de varios GB sin comprimir te infla la factura de S3 y el tiempo de upload.
¿Qué credenciales de AWS necesitás y cómo evitás el desastre?
Ponele que armás todo y, para que “funcione rápido”, metés las access keys de tu usuario root de AWS en las variables de entorno de Render. Felicitaciones: si esa key se filtra, le diste a cualquiera control total de tu cuenta de AWS, no solo de un bucket. Relacionado: alternativas a S3 sin costo de egreso.
Lo que necesitás de verdad:
- Un IAM user dedicado: creado solo para esta tarea, sin acceso a consola, solo programático.
- Una policy de least privilege: permisos
s3:PutObject,s3:GetObjectys3:ListBucket, restringidos al ARN de tu bucket de backups. Nada más. - Access keys de ese user: el
ACCESS_KEY_IDy elSECRET_ACCESS_KEYcargados como variables de entorno en Render, nunca hardcodeados en el código. - El AWS CLI en el entorno del Cron Job: que lee esas variables y autentica sin que vos toques nada más.
¿Por qué tanto cuidado con un permiso de más? Porque el día que esa credencial aparezca en un log público o en un commit por error, querés que el daño máximo sea “alguien escribió en mi bucket de backups”, no “alguien borró toda mi cuenta”.
¿Cuáles son los pasos para restaurar desde S3?
Un backup que nunca probaste restaurar no es un backup. Es una ilusión. Lo descubrís el día peor, cuando el dump está corrupto y ya no hay vuelta atrás.
El proceso de restauración tiene tres movimientos:
- Bajás el archivo:
aws s3 cp s3://tu-bucket/postgres/backup_20260609.sql.gz . - Descomprimís y restaurás en un solo pipe:
gunzip -c backup_20260609.sql.gz | psql $NUEVA_DATABASE_URL. Apuntá a una instancia nueva o de staging, no a producción, hasta validar. - Validás integridad: contás filas en las tablas clave, chequeás que los datos del último día estén, corrés tu suite de tests contra esa base restaurada.
La recomendación que repite todo el que pasó por un incidente: agendá una restauración de prueba periódica. Mensual, como mínimo. Levantás el último backup en una instancia descartable, verificás, y la tirás. Cuesta media hora y te salva la empresa.
¿Cómo manejar backups con múltiples tenants en un SaaS?
Acá viene lo bueno, porque “multi-tenant” no es una sola cosa. Cómo separás los datos de tus clientes define cómo hacés (y restaurás) los backups. Y restaurar un solo cliente sin tocar a los otros 199 es la diferencia entre un incidente puntual y un downtime general.
| Modelo | Aislamiento | Backup | Restaurar un tenant | Mejor para |
|---|---|---|---|---|
| Database-per-tenant | Máximo | Un dump por base | Trivial: restaurás solo esa base | Pocos clientes, datos muy sensibles, compliance estricto |
| Schema-per-tenant | Medio | Dump con filtro por schema | Posible: pg_dump -n schema_cliente | Equilibrio entre aislamiento y costo |
| Pool (tabla compartida con tenant_id) | Mínimo | Un solo dump de todo | Complejo: hay que filtrar por tenant_id | Muchísimos clientes, datos no críticos, costo bajo |
El modelo pool es el más barato de operar, pero te complica la restauración granular: si un cliente la pifia y borra sus datos, sacarlo de un dump compartido sin afectar al resto es un dolor de cabeza. El database-per-tenant es lo contrario: más caro de mantener, pero restaurar un cliente es agarrar su archivo y listo. Lo explicamos a fondo en automatizar backups en tu pipeline CI/CD.
Para 200+ organizaciones con datos sensibles, como el caso de CitizenApp, el schema-per-tenant suele ser el punto medio que zafa: aislamiento razonable sin multiplicar bases por mil.
¿Con qué frecuencia y dónde guardar los backups?
La frecuencia no se define por gusto. Se define por tu RPO, que es cuánto dato estás dispuesto a perder. Si tu RPO es de una hora, un backup diario no sirve: en el peor caso perdés 23 horas de datos.
- RPO de 24 horas: backup diario alcanza. Típico de apps internas o de bajo movimiento.
- RPO de 4 horas: backup cada 4 horas vía Cron. Razonable para la mayoría de los SaaS.
- RPO casi cero: ahí necesitás replicación continua o WAL archiving, no solo
pg_dump. El dump periódico es tu segunda línea, no la única.
Sobre el dónde: no guardes todo en una sola región. Configurá replicación cross-region en S3 para que el backup viva en al menos dos regiones geográficas. Si toda tu infra y tu backup están en us-east-1 y esa región tiene un mal día, te quedaste sin las dos cosas a la vez.
Sobre el costo: S3 Standard ronda los USD 0,023 por GB al mes, así que guardar copias comprimidas es barato. Definí una retention policy con lifecycle rules (por ejemplo, pasar a S3 Glacier los backups de más de 90 días) y no vas a sufrir la factura. Si además corrés tu hosting o tus dominios en infraestructura argentina, podés combinar el almacenamiento en la nube con un proveedor local como donweb.com para la capa de aplicación.
Qué está confirmado y qué depende de tu setup
Para separar lo que dice la documentación oficial de lo que es decisión tuya:
- Confirmado: Render ofrece backups diarios nativos con retención de 30 días y point-in-time recovery, según su documentación.
- Confirmado: Render tiene Cron Jobs nativos, lo que permite correr el script de backup sin infraestructura adicional.
- Depende de vos: la frecuencia exacta, el modelo multi-tenant, la política de retención y la estrategia cross-region. No hay un número mágico, hay un RPO que vos definís.
- Pendiente de validar siempre: que la restauración funcione. Esto no lo confirma ninguna doc, lo confirmás vos probándolo.
Errores comunes al configurar backups a S3
Los que se repiten en todos los post-mortem:
- Usar credenciales root de AWS: el error más caro. Corrección: IAM user dedicado con policy restringida al bucket de backups y nada más.
- Nunca testear la restauración: el backup se ve “verde” en los logs por meses y el día del incidente el dump está corrupto. Corrección: restauración de prueba mensual en una instancia descartable.
- Guardar todo en una sola región: si la región se cae, perdés app y backup juntos. Corrección: replicación cross-region en S3.
- No comprimir el dump: uploads lentos y factura de S3 inflada. Corrección:
gzipsiempre en el pipe delpg_dump. - Backups que fallan en silencio: el Cron Job se rompe y nadie se entera hasta que es tarde. Corrección: logging explícito y una alerta si el job no corrió o el dump pesa 0 bytes.
Preguntas Frecuentes
¿Por qué necesito backups fuera de Render si ya tiene los suyos?
Porque los backups nativos de Render viven en su propia infraestructura, con retención de 30 días y bajo su control. Si Render tiene un outage no podés restaurar, y las auditorías SOC 2 exigen copias por fuera de la infraestructura primaria. Un backup externo en S3 te da portabilidad y cumplimiento.
¿Cómo restauro mi base desde S3?
Bajás el archivo con aws s3 cp, lo descomprimís y restaurás en un solo paso: gunzip -c backup.sql.gz | psql $DATABASE_URL. Apuntá siempre a una instancia nueva o de staging primero, validá la integridad de los datos y recién después promovés a producción. Más contexto en herramientas para orquestar tareas DevOps.
Mirá en Render PostgreSQL Backups to S3: Automating Disaster Recover cómo hacer esto sin vueltas.
Esto se conecta con Render PostgreSQL Backups to S3: Automating Disaster Recover, donde profundizamos en proteger tu infraestructura.
Si querés profundizar en la estrategia de respaldos, chequeá nuestro artículo sobre automatizar backups PostgreSQL.
Si querés profundizar, tenemos un artículo completo sobre Automatizar disaster recovery en cloud.
Esto se conecta con Render PostgreSQL Backups to S3: Automating Disaster Recover, donde cubrimos el tema en detalle.
Si querés profundizar en esta estrategia, mirá Render PostgreSQL Backups to S3: Automating Disaster Recover.
¿Cuánto cuesta guardar backups en S3?
S3 Standard cuesta alrededor de USD 0,023 por GB al mes, así que copias comprimidas de pocos GB salen centavos. Con lifecycle rules que muevan los backups viejos a S3 Glacier, bajás todavía más el costo de retención a largo plazo.
¿Cada cuánto debería correr el backup?
Depende de tu RPO, el dato máximo que tolerás perder. Un backup diario sirve si tu RPO es de 24 horas; para 4 horas, programás el Cron cada 4 horas. Si necesitás pérdida casi cero, ya no alcanza pg_dump: necesitás replicación continua o WAL archiving.
¿Cómo evito el vendor lock-in con mi base en Render?
Manteniendo backups en formato estándar de PostgreSQL (pg_dump) en un almacenamiento neutral como S3. Ese dump lo restaurás en cualquier proveedor que corra PostgreSQL, sin depender de las herramientas de exportación de Render ni de su disponibilidad.
Conclusión
Render es una plataforma sólida, y sus backups nativos funcionan. El punto no es desconfiar de Render: es no poner toda tu recuperación en manos de un solo proveedor. Un Cron Job con pg_dump a S3, un IAM user de permisos mínimos y una restauración de prueba mensual te dan portabilidad, compliance SOC 2 y RTO real frente a un outage de plataforma.
Si manejás un SaaS multi-tenant, definí hoy tu RPO, elegí el modelo de aislamiento que mejor te deje restaurar un solo cliente, y configurá la replicación cross-region. Lo más importante de todo: probá la restauración antes de necesitarla. El backup que nunca restauraste no existe hasta que lo demostrás.
Fuentes
- Render Docs – Backups nativos de PostgreSQL (retención 30 días y PITR)
- Render Docs – Guía oficial para backups de PostgreSQL a S3
- render-examples/postgres-s3-backups – Ejemplo de implementación en GitHub
- Dev.to – El caso de CitizenApp: disaster recovery multi-tenant sin vendor lock-in
- AWS Database Blog – Backup y recuperación en aplicaciones SaaS multi-tenant