El caso GPT-4o: de USD 30 calculados a USD 340 reales
A un desarrollador le llegó una factura de AWS de USD 340 por un proyecto que armó en un fin de semana. El caso GPT-4o, contado por su autor en dev.to el 19 de junio de 2026, muestra cómo un cálculo prolijo de USD 30/mes terminó multiplicándose por once cuando el proyecto se hizo viral.
El error de estimación de costos de API es la diferencia entre lo que calculás antes de lanzar (tokens de input por el volumen esperado) y lo que pagás cuando entran picos de tráfico, tokens de output y los system prompts que se repiten en cada request. GPT-4o cobra por millón de tokens, con tarifas distintas para input y output. Ese detalle, multiplicado por miles de llamadas diarias, es lo que rompe presupuestos.
En 30 segundos
- Un side project estimado en USD 30/mes facturó USD 340 tras volverse viral en un chat grupal.
- Solo los system prompts (800 tokens) por 2000 requests diarios sumaban USD 4/día, o sea USD 120/mes con GPT-4o a USD 2,50/1M.
- El problema de fondo: cada proveedor cobra con unidades distintas (tokens, read/write units, GB-segundo) y comparar a ojo es casi imposible.
- El autor armó APICalculators.com, 16 calculadoras gratis en el navegador, para estimar antes de lanzar.
- Gemini Flash arranca en USD 0,075/1M de input; Claude Sonnet, en USD 3/1M. La brecha entre modelos es de 40x.
¿Cómo escalan los costos cuando un proyecto se hace viral?
Ponele que armás una herramienta que resume texto: el usuario pega un párrafo, el modelo devuelve un resumen. Hacés la cuenta antes de publicar: USD 0,002 por request, unos 500 requests por día, total redondeando USD 30 al mes. Cierra.
Después la herramienta se comparte en un chat grupal y los 500 requests se convierten en 2000 por día. Ahí aparece lo que nadie calcula: el system prompt. Son esas instrucciones fijas que viajan en cada llamada. En el caso real eran 800 tokens.
La cuenta del propio autor lo deja claro: (800 tokens × 2000 requests / 1.000.000) × 2,50 = USD 4/día. Eso da USD 120 al mes, y todavía no contamos los tokens que escribe el usuario ni los que devuelve el modelo. Sumás todo y llegás a los USD 340. El presupuesto original no estaba mal calculado: estaba calculado para otro escenario.
¿Por qué es tan difícil comparar precios entre OpenAI, Pinecone y AWS Lambda?
Acá viene lo bueno: ningún proveedor usa la misma unidad. Querés comparar dos servicios y terminás armando una planilla desde cero cada vez, o peor, adivinando. Y adivinar sale caro.
| Proveedor | Cómo cobra | Dato concreto |
|---|---|---|
| OpenAI (GPT-4o) | Por millón de tokens, input y output con tarifas distintas | USD 2,50/1M de input |
| Anthropic (Claude Sonnet) | Por millón de tokens | USD 3/1M de input |
| Google (Gemini Flash) | Por millón de tokens | USD 0,075/1M de input |
| Pinecone | Read units + write units + storage | GB/mes de almacenamiento |
| Stripe | % de la transacción + fee fijo + plataforma | Tres variables por cobro |
| AWS Lambda | GB-segundo + requests + transferencia de datos | Tres líneas de factura distintas |
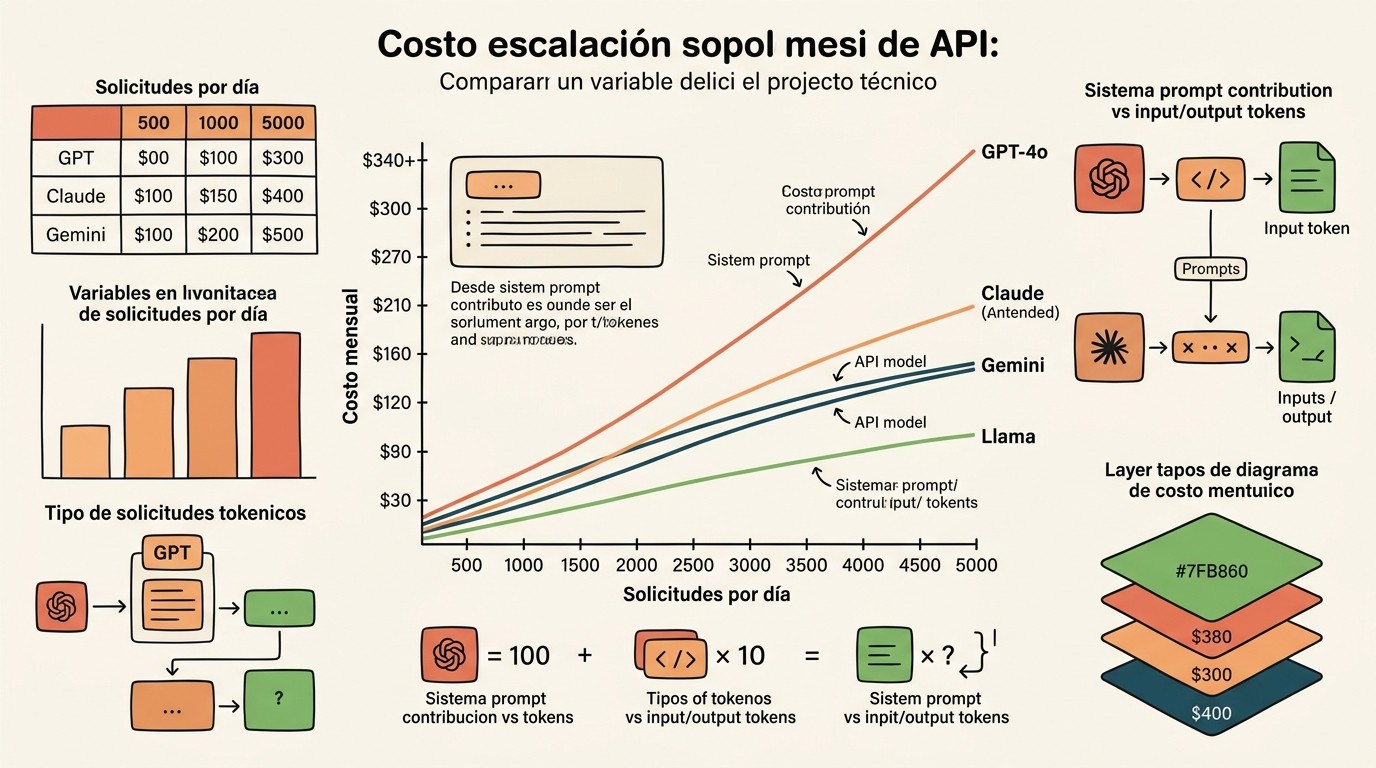
Mirando la tabla se entiende el lío. Un servicio te cobra por token, otro por unidad de lectura, otro por segundo de cómputo. No hay forma de poner los números lado a lado sin traducirlos primero a tu volumen real. Por eso el autor terminó construyendo APICalculators.com: 16 calculadoras gratuitas en el navegador que hacen esa traducción por vos.
Cómo estimar bien el costo antes de lanzar
La fórmula base es simple: (tokens × requests diarios / 1.000.000) × precio por 1M. El problema no es la fórmula, es lo que metés adentro. Cubrimos ese tema en detalle al elegir entre las herramientas de deployment.
- Contá el system prompt aparte. Esos 800 tokens viajan en cada llamada. A 2000 requests diarios ya son USD 4/día solo de instrucciones fijas.
- Sumá los tokens de output. Suelen ser más caros que los de input y, en una herramienta que genera texto, más voluminosos.
- Multiplicá por un pico realista. Si planeás para 500 requests y te llegan 2000, tu factura se cuadruplica sin avisar.
- Probá con varios modelos. El mismo flujo con Gemini Flash (USD 0,075/1M) o con Claude Sonnet (USD 3/1M) tiene una diferencia de 40x.
Errores de estimación que comete todo el mundo
- Olvidar el system prompt. Es el costo invisible. Se repite en cada request y nadie lo suma en la planilla inicial.
- No contar los tokens de output. En muchos casos pesan más que el input, y a tarifa más alta.
- Estimar con el tráfico “normal”. Un proyecto viral no respeta tu promedio. Calculá para el pico, no para el día tranquilo.
- Elegir modelo sin comparar contexto vs precio. A veces un modelo más barato con ventana más chica zafa igual.
- Ignorar la transferencia de datos. En AWS, el data transfer es una línea aparte que aparece cuando ya es tarde.
- No poner alertas de gasto. Sin un tope, te enterás del problema cuando llega la factura.
¿Cómo monitorear y frenar el gasto antes de que escale?
La regla es no esperar a la factura. ¿Alguien revisa el gasto a diario en un side project? Casi nunca. Por eso conviene automatizar el control.
- Poné límites de presupuesto duros en la consola de OpenAI y en AWS Budgets. Es lo primero, antes de la primera línea de código en producción.
- Logueá los tokens por request. Si no medís cuántos tokens consume cada llamada, no podés detectar cuándo se dispara.
- Configurá alertas al 80% del presupuesto. Un aviso por email o Slack cuando llegás a ese umbral te da margen para reaccionar.
- Mirá el costo por usuario. Si un solo usuario consume el 40% del gasto, ahí tenés un patrón de abuso o un bug.
Para el cómputo y el monitoreo de fondo, si tu app vive en infraestructura propia conviene una base estable: hosting y servidores en Argentina los podés resolver con donweb.com, y dejás el gasto variable solo para las llamadas al modelo.
Buenas prácticas para side projects con poco presupuesto
El truco no es gastar menos, es gastar donde corresponde. Empezás barato, validás, y recién ahí escalás al modelo caro.
- Arrancá con un modelo económico. Gemini Flash a USD 0,075/1M de input alcanza de sobra para un MVP. Si el producto valida, subís a Claude Sonnet (USD 3/1M).
- Cacheá los prompts repetidos. Si el system prompt es siempre el mismo, no lo proceses de cero en cada llamada.
- Aplicá rate limiting. Un tope por usuario y por hora frena el pico viral antes de que te coma el presupuesto.
- Definí un fallback más barato. Si el gasto supera el umbral, que la app baje a un modelo económico en vez de cortar el servicio.
Qué está confirmado y qué no
- Confirmado: el caso fue publicado por su autor el 19 de junio de 2026 con los números del cálculo (800 tokens de system prompt, 2000 requests/día, USD 2,50/1M en GPT-4o, factura final de USD 340).
- Confirmado: APICalculators.com existe y ofrece 16 calculadoras gratuitas en el navegador para GPT-4o, Claude Sonnet, Gemini Flash y Llama, entre otros.
- Pendiente: los precios de cada modelo cambian seguido. Verificá siempre la tarifa vigente en la página oficial del proveedor antes de presupuestar.
- Pendiente: el relato es la experiencia de un desarrollador, no una auditoría independiente de costos. Tomá los números como referencia, no como benchmark universal.
Preguntas Frecuentes
¿Por qué mi factura de AWS o de la API fue tan alta?
El costo se dispara por tres factores que no se calculan al inicio: los system prompts que se repiten en cada request, los tokens de output (más caros que el input) y los picos de tráfico. En el caso GPT-4o, solo los system prompts sumaban USD 120/mes. Complementá con ejecutando tus agentes localmente.
¿Cómo calculo el costo real de una API antes de lanzar?
Usá la fórmula (tokens × requests diarios / 1.000.000) × precio por 1M, sumando system prompt, input y output por separado, y multiplicando por un pico de tráfico realista. Herramientas como APICalculators.com hacen ese cálculo gratis en el navegador.
¿Qué proveedor de LLM es más barato?
Por token de input, Gemini Flash es el más económico de los tres (USD 0,075/1M), seguido por GPT-4o (USD 2,50/1M) y Claude Sonnet (USD 3/1M). La diferencia entre el más barato y el más caro es de unas 40 veces, así que el modelo elegido define el presupuesto.
¿Cómo monitoreo gastos de APIs en tiempo real?
Configurá límites de presupuesto en la consola del proveedor (OpenAI, AWS Budgets), logueá los tokens consumidos por request y armá alertas que avisen al 80% del tope por email o Slack. Eso te da margen para reaccionar antes de que llegue la factura. En si usás herramientas de IA con GPU profundizamos sobre esto.
¿Qué es un system prompt y por qué encarece tanto?
El system prompt es el bloque de instrucciones fijas que viaja en cada llamada al modelo para definir su comportamiento. Como se repite en cada request, su costo se multiplica por el volumen: 800 tokens por 2000 requests diarios ya son USD 4/día con GPT-4o.
Conclusión
La lección del caso GPT-4o no es que las APIs sean caras. Es que el costo real no es el que calculás con el tráfico de tus sueños. Los system prompts, los tokens de output y un pico viral pueden multiplicar tu factura por once sin que cambies una línea de código.
Antes de publicar, hacé la cuenta completa con un pico realista, probá el mismo flujo en dos o tres modelos y poné un tope de presupuesto con alerta al 80%. Empezá barato con Gemini Flash, validá, y recién ahí pagá por Claude Sonnet. Cinco minutos de planilla te ahorran una sorpresa de USD 340 un martes a la mañana.