pg_hardstorage: backup PostgreSQL de la comunidad
El backup PostgreSQL pg_hardstorage es una herramienta nueva, presentada por Hans-Juergen Schoenig (CEO de CYBERTEC), que hace streaming continuo del WAL y permite recuperación a un punto exacto en el tiempo. Es un único binario en Go, con licencia Apache 2.0, pensado para que cualquier base, chica o gigante, tenga respaldos confiables sin pelearse con configuraciones eternas.
pg_hardstorage es una herramienta open source de backup y recuperación para PostgreSQL que combina dos cosas: streaming del Write-Ahead Log las 24 horas vía protocolo de replicación, y base backups periódicos. Soporta PostgreSQL 15 a 18, cifrado AES-256-GCM, deduplicación content-addressed y almacenamiento en S3, GCS, Blob, SFTP o filesystem local. Apunta a recuperación punto en tiempo sin huecos.
En 30 segundos
- Qué es: herramienta de backup PostgreSQL creada por la comunidad bajo Apache 2.0, impulsada por Hans-Juergen Schoenig (CYBERTEC).
- Cómo respalda: WAL streaming 24/7 por el protocolo de replicación más base backups periódicos, sin chains de dependencias.
- Recuperación: PITR al segundo exacto, a un LSN puntual o a un named restore point.
- Dónde corre: binario único en Go, sin dependencias, sobre PostgreSQL 15 a 18, con almacenamiento en S3, GCS, Blob, SFTP o disco.
- Compatibilidad: convive con pgBackRest, Barman y WAL-G, e integra con Patroni y entornos Kubernetes.
¿Qué es pg_hardstorage y por qué lo desarrolló Hans-Juergen Schoenig?
Si alguna vez configuraste backups en PostgreSQL, sabés que el tema no es trivial. Tenés que pensar en WAL archiving, en retención, en si el último respaldo realmente sirve para restaurar (spoiler: a veces te enterás que no justo cuando lo necesitás).
Acá viene lo bueno: pg_hardstorage nace para sacarte ese dolor de cabeza. Lo presentó Schoenig, que lleva años en el mundo de PostgreSQL al frente de CYBERTEC, y la idea central es que sea un proyecto community-driven, no una solución propietaria atada a un vendor. Sale con licencia Apache 2.0, así que lo podés usar, auditar y modificar.
El problema que ataca es concreto. Las herramientas de backup tradicionales suelen ser potentes pero pesadas de configurar, y muchas dependen de cadenas de respaldos donde si se rompe un eslabón, te quedaste sin recuperación. pg_hardstorage apunta a que el respaldo sea simple, confiable y parejo para todos los tamaños de base, según el anuncio oficial de CYBERTEC.
¿Cuáles son las características principales de pg_hardstorage?
Lo que más llama la atención es que viene como un solo binario en Go. Nada de instalar media docena de dependencias ni rezar para que la versión de cada librería sea la correcta. Cubrimos ese tema en detalle en automatizar backups con CI/CD.
- WAL streaming nativo: usa el protocolo de replicación de PostgreSQL para llevarse el Write-Ahead Log en vivo, no por archivado diferido.
- Deduplicación content-addressed: con FastCDC y alineación por página, evita guardar lo mismo dos veces y no arma chains de dependencia entre respaldos.
- Cifrado AES-256-GCM: protección de datos por defecto, con soporte de KMS en AWS, GCP, Azure y Vault.
- PITR al segundo: recuperación punto en tiempo hasta un instante específico.
- Multi-backend: guarda en S3, GCS, Blob, SFTP o filesystem local.
- Compatibilidad: convive con pgBackRest, Barman y WAL-G.
El detalle del cifrado por defecto no es menor. Muchas herramientas te dejan el cifrado como un “opcional” que después nadie activa, y cuando hay una filtración aparece el problema. Acá viene de fábrica.
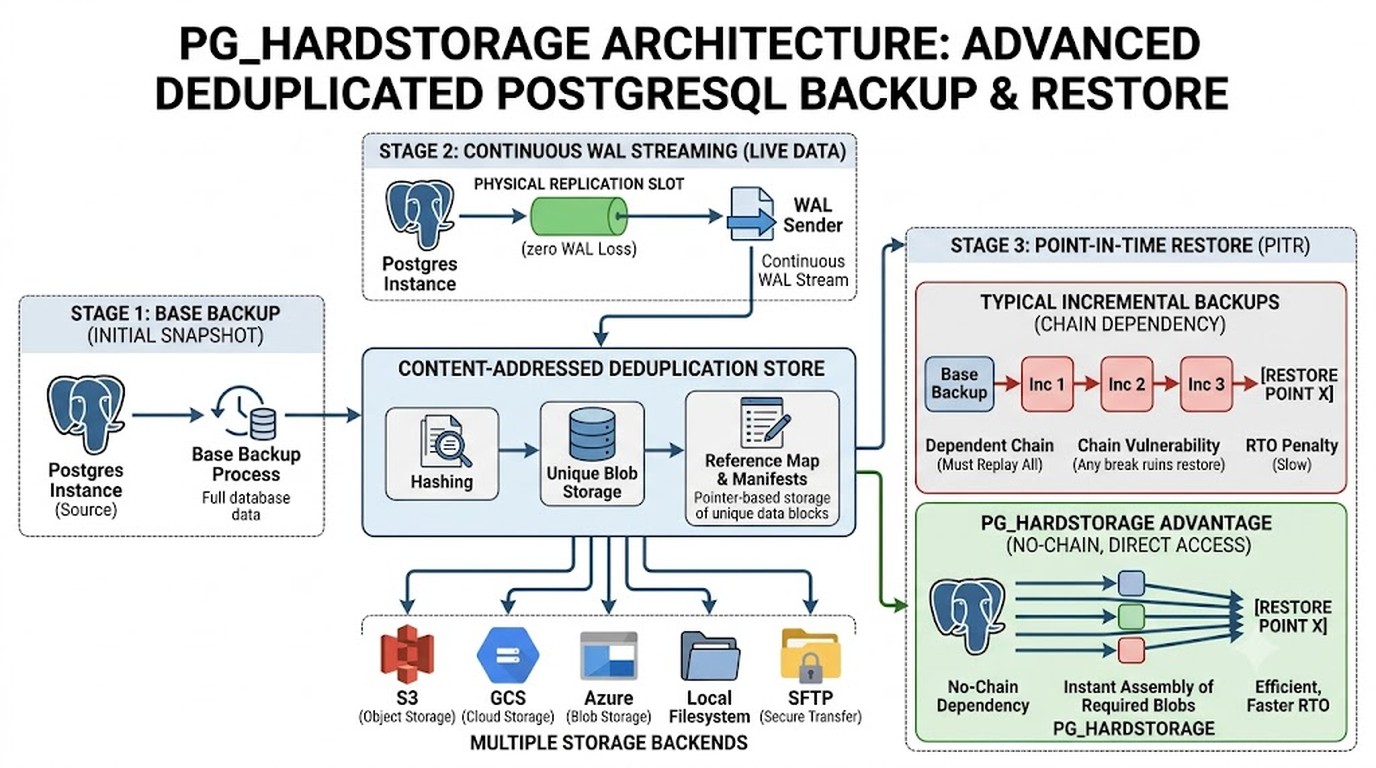
¿Cómo funciona el WAL streaming continuo en pg_hardstorage?
La arquitectura corre con dos procesos en paralelo. Uno hace el streaming del WAL todo el tiempo, conectado por un physical replication slot. El otro toma base backups periódicos. La combinación de ambos te da una recuperación sin huecos.
¿Por qué importa esto frente al WAL archiving de toda la vida? Porque el archivado tradicional manda los segmentos cuando se llenan, y entre uno y otro puede quedar una ventana de minutos sin cubrir. Con streaming, el log fluye de forma continua: armás un base backup, dejás el stream 24/7 corriendo, y tenés PITR sin brechas.
La deduplicación content-addressed suma otra ventaja. Como cada bloque se identifica por su contenido y no depende de una cadena previa, podés borrar un respaldo viejo sin invalidar los nuevos. El que alguna vez perdió un backup full y descubrió que todos los incrementales colgaban de ese full, ya entiende por qué esto es un golazo.
¿Qué es PITR (Point-In-Time Recovery) y cómo lo resuelve?
PITR es restaurar tu base a un momento exacto del pasado. No al último backup, sino al segundo que vos elijas. Esto se conecta con lo que analizamos en orquestación automática de tareas.
Ponele que un viernes a las 14:30:45 alguien corre un DELETE sin WHERE y se lleva puesta media tabla de clientes. Con PITR, restaurás la base al estado que tenía a las 14:30:44, justo antes del desastre. pg_hardstorage te deja apuntar a un timestamp puntual, a un LSN específico o a un named restore point que hayas marcado antes.
Hay además una capacidad de preview para ver a qué punto vas a restaurar antes de ejecutar, y es Patroni-aware para failover. Eso último ayuda cuando tu cluster cambia de líder y no querés que la recuperación se confunda de timeline.
pg_hardstorage vs pgBackRest: ¿cuál conviene?
La pregunta del millón. pgBackRest es la herramienta madura, batalla y curtida en producción a gran escala. pg_hardstorage es la nueva, más liviana de operar y pensada para cloud desde el día cero.
| Criterio | pg_hardstorage | pgBackRest |
|---|---|---|
| Captura del WAL | Streaming nativo 24/7 (protocolo de replicación) | WAL archiving + full/diff/incremental |
| Dependencias entre backups | Sin chains (content-addressed) | Cadena full/diff/incremental |
| Cifrado / KMS | AES-256-GCM por defecto, KMS integrado | Cifrado disponible, configurable |
| Distribución | Binario único en Go | Binario maduro, amplia adopción |
| PostgreSQL | 15 a 18 | Amplio rango, años de soporte |
| Madurez | Reciente (2026) | Probada a gran escala |
Un dato que pesa en la decisión: el repositorio de pgBackRest fue archivado el 27 de abril de 2026, con la v2.58.0 marcada como versión final. Eso no significa que deje de funcionar (sigue siendo sólido y mucha gente lo va a seguir usando), pero sí cambia el cálculo si arrancás un proyecto nuevo hoy.
Mi lectura: para despliegues nuevos en cloud o Kubernetes, pg_hardstorage tiene sentido por el streaming nativo y el cifrado de fábrica. Si ya tenés una infraestructura legacy grande corriendo con pgBackRest y todo anda fino, no hay apuro en migrar. Eso sí: tomá esta comparación con pinzas, porque pg_hardstorage es muy joven y todavía le falta kilómetros en producción. Relacionado: documentación en múltiples idiomas.
¿Cómo se instala y se arranca pg_hardstorage?
Los requisitos son pocos: PostgreSQL 15 a 18, acceso al protocolo de replicación y algún destino de almacenamiento, local o en la nube.
- Instalación: un
curl | shy queda el binario listo. - Demo rápido:
pg_hardstorage demopara probarlo sin armar nada serio. - Flujo básico: inicializás el repo, arrancás el WAL stream, hacés el base backup y después restaurás cuando lo necesites.
- Migración: hay un
compat translateque convierte unpgbackrest.confo unbarman.confexistente, así no rearmás todo de cero.
Ese comando de compatibilidad es lo que más baja la fricción. Migrar configuraciones a mano es donde la gente abandona, y acá te lo traducen solo.
¿Cómo se implementa en Kubernetes y Patroni?
pg_hardstorage trae integración con CloudNativePG y soporte para clusters Patroni. La gracia es la recuperación gap-free durante un failover: cuando tu cluster cambia de nodo líder, el streaming sigue cubriendo la ventana sin dejar agujeros en el log.
Otra capacidad es el backup multi-cloud simultáneo. Podés mandar respaldos a S3, GCS y Blob al mismo tiempo, lo que te da redundancia entre proveedores. Y la gestión de claves va por KMS, así no terminás con secretos hardcodeados en un YAML que después alguien sube al repo (sí, pasa más de lo que uno quisiera).
Si estás montando una base PostgreSQL administrada sobre infraestructura propia y necesitás hosting o cloud confiable en la región, podés mirar las opciones de donweb.com para el server donde corre tu cluster.
Errores comunes al configurar backups en PostgreSQL
- No probar la restauración: un backup que nunca restauraste no es un backup, es una ilusión. Corré un restore de prueba periódico, no esperes a la emergencia.
- Dejar el cifrado para después: si tu herramienta lo hace opcional, lo más probable es que nunca lo prendas. pg_hardstorage lo trae por defecto, aprovechalo.
- Confiar en chains frágiles: cuando los incrementales dependen de un full y borrás el full, perdés todo. Por eso el enfoque content-addressed sin dependencias importa.
- Ignorar el timeline en failover: en clusters Patroni, un cambio de líder mal manejado te puede dejar la recuperación apuntando al timeline equivocado. Verificá que tu herramienta sea consciente del failover.
Preguntas Frecuentes
¿Qué es pg_hardstorage y para qué sirve?
pg_hardstorage es una herramienta open source de backup y recuperación para PostgreSQL impulsada por Hans-Juergen Schoenig (CYBERTEC). Sirve para respaldar bases con WAL streaming continuo y restaurarlas a un punto exacto en el tiempo, con licencia Apache 2.0 y soporte de PostgreSQL 15 a 18. Sobre eso hablamos en monitoreo local sin APIs externas.
¿Cómo funciona el WAL streaming?
El WAL streaming captura el Write-Ahead Log en vivo a través del protocolo de replicación de PostgreSQL, usando un physical replication slot. A diferencia del archivado tradicional, no espera a que el segmento se llene, así que cubre la ventana de cambios sin dejar huecos.
¿Cuál es la diferencia con pgBackRest?
pg_hardstorage usa streaming WAL nativo, no arma chains de dependencias y trae cifrado AES-256-GCM por defecto, en un binario único de Go. pgBackRest es más maduro y probado a gran escala, con respaldos full, diferenciales e incrementales. El repo de pgBackRest fue archivado el 27 de abril de 2026 con la v2.58.0 como versión final.
¿Qué ventaja da el PITR de pg_hardstorage?
El PITR permite restaurar la base a un segundo exacto, a un LSN específico o a un named restore point. Evita perder datos ante una corrupción o un cambio no deseado, y suma preview de a dónde vas a restaurar antes de ejecutar.
¿Se puede usar en Kubernetes?
Sí. pg_hardstorage integra con CloudNativePG y clusters Patroni, con recuperación gap-free durante el failover. Además soporta backup simultáneo a varios destinos (S3, GCS, Blob) y gestión de claves vía KMS de AWS, GCP, Azure o Vault.
Conclusión
pg_hardstorage llega a tapar un hueco real: backups de PostgreSQL que sean simples de operar, cifrados de fábrica y sin cadenas de dependencias que se rompen en el peor momento. El timing además ayuda, porque con pgBackRest archivado en abril de 2026, mucha gente va a estar mirando alternativas para proyectos nuevos.
¿Qué hacer ahora? Si arrancás un cluster nuevo en cloud o Kubernetes, probalo con pg_hardstorage demo y evaluá la migración con compat translate. Si ya tenés pgBackRest andando bien, no corras: testealo en un entorno aislado primero. Y pase lo que pase, hacé un restore de prueba. Es la única forma de saber que tu backup sirve.


![[P] Built GPT-2, Llama 3, and DeepSeek from scratch in PyTorch - open source code + book - ilustracion](https://donweb.news/wp-content/uploads/2026/04/construir-llm-desde-cero-pytorch-gpt2-llama3-deepseek-hero-768x429.jpg)