Generá podcasts automáticos con n8n y Render
Con n8n como plataforma de generación automatizada de podcasts y Render como plataforma de hosting, cualquier equipo puede tener un sistema de producción de podcasts corriendo en menos de una hora, sin escribir una sola línea de código desde cero y con costos que parten desde cero dólares mensuales.
En 30 segundos
- n8n tiene workflows públicos listos para generar podcasts multi-speaker usando GPT, Claude y ElevenLabs como base de voces.
- Render ofrece un blueprint oficial para desplegar n8n con PostgreSQL en minutos, con tier gratuito disponible para proyectos pequeños.
- El flujo típico va de RSS o Google Sheets → LLM para el script → TTS para el audio → MP3 final → publicación automática en Buzzsprout o Spotify.
- Una agencia reportó producir 50 episodios en una semana con este stack, con un ahorro estimado de USD 15.000 frente a producción tradicional.
- Los errores más frecuentes están en la configuración de base de datos en Render y en la elección de motor TTS gratuito vs. pago.
¿Qué es n8n y por qué es ideal para automatizar podcasts?
n8n es una plataforma de automatización de workflows low-code, de código abierto, que te permite conectar cientos de servicios mediante nodos visuales. No necesitás ser desarrollador para armar flujos complejos, aunque si sabés algo de JavaScript podés extender casi cualquier nodo con código custom.
La comunidad hispanohablante de n8n creció un 141% durante 2025, según datos de la propia comunidad. Eso se nota: hay cada vez más workflows documentados en español, más casos de uso de agencias latinoamericanas y más integraciones con servicios regionales. Para podcasts, la combinación es casi perfecta: n8n maneja la orquestación, y vos conectás las APIs que ya usás (OpenAI, ElevenLabs, Google Sheets, tu hosting de podcast).
La ventaja frente a scripts manuales en Python o Node es real: cuando algo falla, el log visual te dice exactamente qué nodo se cayó y con qué error. No tenés que debuggear 200 líneas de código a las 2 de la mañana porque el episodio de mañana no se generó.
Render como hosting: instalación de n8n en 5 minutos
Render tiene un blueprint oficial preconfigurado para n8n que levanta toda la infraestructura con un render.yaml. El deployment incluye n8n con PostgreSQL managed, variables de entorno para credenciales, y HTTPS automático. Te puede servir nuestra cobertura de elegir el modelo de IA adecuado.
El proceso es así: vas al repositorio oficial de Render para n8n, hacés clic en “Deploy to Render”, configurás tu usuario y contraseña de n8n, y en menos de 5 minutos tenés la instancia corriendo. PostgreSQL managed corre en la misma región que el web service, lo que elimina la latencia y los problemas de conexión que aparecen si usás una base externa.
Sobre costos: el tier gratuito de Render tiene una limitación importante: el web service se “duerme” después de 15 minutos de inactividad. Para uso serio (workflows que corren solos a horarios fijos), necesitás al menos el plan Starter, que arranca en USD 7/mes para el web service más USD 7/mes para PostgreSQL. Unos USD 14/mes en total, lo cual sigue siendo barato para lo que hace. Si buscás alternativas de VPS con más control, donweb.com tiene opciones de cloud donde podés instalar n8n con Docker y manejarte sin las limitaciones del tier gratuito.
Eso sí: la documentación oficial de Render para self-hosting de n8n cubre también el tema de networking seguro entre servicios, con private network para que la base de datos no quede expuesta públicamente. Es el setup recomendado para cualquier instancia que maneje credenciales de APIs.
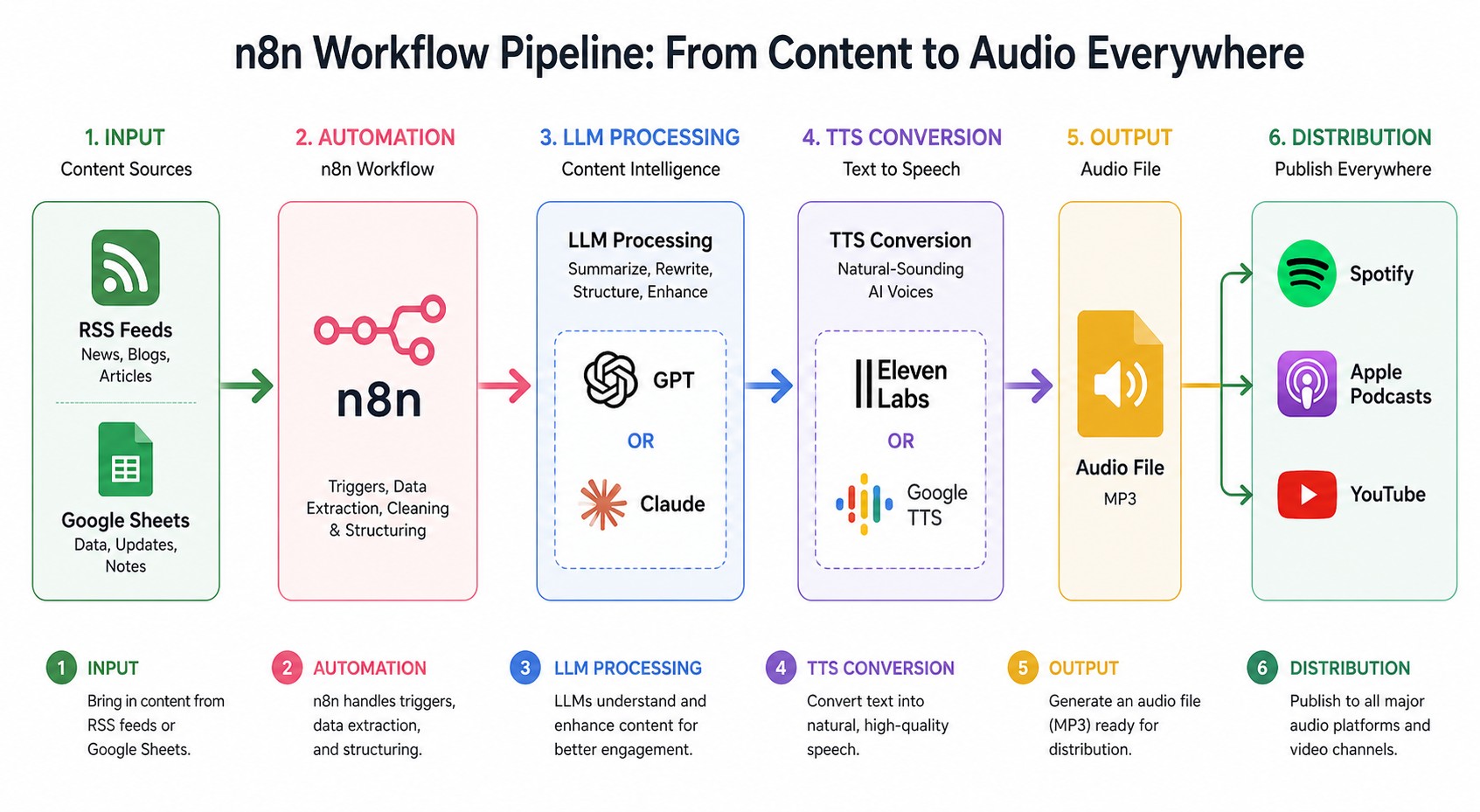
Arquitectura del workflow: de fuente a podcast final
El flujo estándar tiene cinco etapas, y la mayoría de los workflows públicos de n8n las siguen:
- Fuente de contenido: RSS feed o Google Sheets con temas/URLs
- Procesamiento con LLM: GPT-4o o Claude para generar el script conversacional
- Síntesis de voz: ElevenLabs, Google TTS o Kokoro para generar el audio
- Post-procesamiento: FFmpeg para concatenar segmentos, añadir intro/outro, normalizar volumen
- Distribución: upload automático a Buzzsprout, Spotify for Podcasters o cualquier hosting RSS
El workflow Automate Podcast Creation with GPT, Claude and ElevenLabs de la biblioteca oficial es el punto de entrada más directo. Tiene 23 nodos, está documentado, y en la sección de comentarios hay varios forks de usuarios que lo adaptaron para multi-speaker.
Para multi-speaker, el workflow Generate Multispeaker Podcast with AI usa Google Sheets como fuente y asigna voces distintas de ElevenLabs a cada speaker según columnas del sheet. Ponele que tenés un podcast de debate: una columna para el “host”, otra para el “guest”, y el workflow genera los audios por separado antes de mezclarlos.
Integradores clave: qué APIs necesitás y cuánto cuestan
No todos los componentes del stack valen lo mismo ni tienen la misma calidad. Acá va el comparativo que importa:
| Herramienta | Rol | Costo estimado | Calidad de voz/output | Limitación principal |
|---|---|---|---|---|
| ElevenLabs (Starter) | TTS principal | USD 5/mes (30k chars) | Muy alta, natural | Límite de caracteres por plan |
| Google TTS (Standard) | TTS alternativo | USD 4 por 1M chars | Media, robótica | Voces menos naturales |
| Kokoro TTS | TTS gratuito/local | Gratis (self-hosted) | Media-alta, mejora rápido | Requiere instancia propia |
| GPT-4o | Generación de scripts | USD 2.50 por 1M tokens input | Alta, conversacional | Costo escala con volumen |
| Claude 3.5 Sonnet | Generación de scripts | USD 3 por 1M tokens input | Alta, más narrativo | Idem GPT |
| Google Gemini 2.0 | Generación + síntesis | Tier gratuito disponible | Media en TTS propio | Menos control sobre el output |
El workflow RSS to Podcast con Gemini + Kokoro + FFmpeg es el más interesante para quien quiere costo cero en TTS, aunque Kokoro requiere que lo corras vos en tu infraestructura. Si querés ir a producción rápido y con calidad alta, ElevenLabs Starter es el camino.
Templates y workflows listos para usar: cómo empezar sin partir de cero
En n8n.io/workflows podés buscar “podcast” y encontrar más de 15 templates activos. Los cuatro más usados en 2026 son: Lo explicamos a fondo en comparar herramientas de IA alternativas.
- Workflow 10051: GPT + Claude + ElevenLabs, el más completo, ideal para podcasts de 5-15 minutos
- Workflow 2927: Multi-speaker desde Google Sheets, bueno para debates o entrevistas simuladas
- Workflow 6945: RSS → Gemini → Kokoro → FFmpeg, el stack gratuito, más técnico de configurar
- Workflow de Javadex: documentado en español, pensado para podcasts de noticias diarias con resumen automático
Para clonarlos: hacés login en n8n.io, abrís el workflow, clic en “Use workflow” y se importa directamente a tu instancia. Después editás las credenciales (API keys de OpenAI, ElevenLabs, etc.) en el panel de Credentials de n8n y listo. El setup inicial lleva entre 30 y 90 minutos dependiendo de cuántas APIs tenés que configurar por primera vez.
Caso real: cómo una agencia ahorró USD 15.000 en producción
Una agencia de contenido documentó haber generado 50 episodios en una semana usando n8n + ElevenLabs, con un tiempo de setup inicial de 4 horas. El costo total de la producción: aproximadamente USD 47 en APIs (GPT para scripts + ElevenLabs para audio), más los USD 14/mes de infraestructura en Render.
Comparado con producción tradicional: un productor freelance cobra entre USD 300 y USD 600 por episodio de calidad media, incluyendo edición y post-producción. Por 50 episodios, el rango va de USD 15.000 a USD 30.000. El ahorro en ese lote fue de, como mínimo, USD 14.953. El setup inicial se paga solo en el primer mes.
¿Y la calidad? El punto flaco sigue siendo la naturalidad de las voces en conversaciones largas (más de 10 minutos el oído lo nota) y los scripts generados por LLM que a veces suenan demasiado formales. La solución que usaron fue un paso de “revisión de tono” con un prompt adicional en Claude antes de pasar al TTS. Agrega 30 segundos al workflow pero mejora notablemente el resultado.
Errores comunes y cómo evitarlos
Error 1: usar SQLite en Render en lugar de PostgreSQL. Si configurás n8n con SQLite en Render, cuando el servicio se reinicia (cosa que pasa con el tier gratuito), perdés todos los workflows y credenciales guardadas. La solución es siempre configurar PostgreSQL managed desde el inicio, aunque uses el tier gratuito. Cubrimos ese tema en detalle en diferenciar entre plataformas de IA.
Error 2: elegir Kokoro TTS sin tener instancia propia lista. Varios tutoriales mencionan Kokoro como alternativa gratuita, pero omiten que necesitás tu propio servidor para correrlo. Si intentás apuntar a un endpoint de Kokoro que no existe, el workflow falla sin un mensaje de error claro. O lo hosteás vos, o usás Google TTS standard mientras armás esa infraestructura.
Error 3: prompts genéricos para el script del podcast. “Generá un podcast sobre X” le da a GPT demasiada libertad. Los mejores resultados vienen con prompts que especifican: duración estimada, cantidad de speakers, tono (técnico, divulgativo, conversacional), y una estructura concreta (intro → punto 1 → punto 2 → cierre). Sin esto, los episodios son inconsistentes entre sí.
Error 4: no monitorear los workflows con ejecuciones fallidas. n8n guarda el historial de ejecuciones, pero si no configurás una alerta (por mail o Slack) cuando algo falla, podés llegar a la semana sin saber que el batch del lunes se cayó. Dos minutos de configuración en el nodo “Error Trigger” evitan este problema.
Error 5: olvidar el límite de caracteres de ElevenLabs. Un episodio de 10 minutos consume entre 8.000 y 12.000 caracteres. Con el plan Starter (30.000 chars/mes) solo tenés para 2-3 episodios largos por mes. Si tu volumen es mayor, necesitás el plan Creator (USD 22/mes, 100.000 chars) o calcular bien antes de arrancar.
Preguntas Frecuentes
¿Cómo genero podcasts automáticamente con n8n?
Con n8n armás un workflow que toma una fuente de contenido (RSS, Google Sheets, o un trigger manual), la procesa con un LLM para generar el script, lo pasa a un motor TTS (ElevenLabs, Google TTS o Kokoro) para generar el audio, y finalmente lo publica en tu plataforma de podcast. Podés usar templates listos desde n8n.io/workflows buscando “podcast”, que aceleran el setup inicial a menos de 2 horas. Relacionado: distribuir podcasts en varios idiomas.
¿Puedo alojar n8n en Render de forma gratuita?
Sí, Render tiene un tier gratuito compatible con n8n, pero tiene una limitación crítica: el web service se suspende tras 15 minutos de inactividad. Para workflows que deben correr solos según un schedule, necesitás al menos el plan Starter (USD 7/mes para el web service + USD 7/mes para PostgreSQL). El blueprint oficial de Render para n8n simplifica el deployment a un par de clics.
¿Qué es más barato: contratar un productor o automatizar con n8n?
Automatizar es más barato a partir del tercer o cuarto episodio. La infraestructura (Render + APIs) ronda los USD 20-50/mes dependiendo del volumen, mientras que un productor freelance cobra entre USD 300 y USD 600 por episodio. El costo de setup inicial es de 2-4 horas de configuración. Para agencias o creadores con volumen mensual constante, el ROI es claro desde el primer mes.
¿Qué herramientas integrar con n8n para podcasts?
El stack más usado combina OpenAI o Claude para el script, ElevenLabs para voces de alta calidad, Google Sheets como fuente de temas, FFmpeg para mezcla de audio, y Buzzsprout o Spotify for Podcasters para la distribución. Para el hosting del propio n8n, Render es la opción más documentada. Kokoro TTS es una alternativa gratuita para la voz si tenés infraestructura propia donde correrlo.
¿Cuánto tiempo tarda crear un podcast automatizado con n8n?
El setup inicial lleva entre 2 y 4 horas: deployment en Render (15 minutos), importar y configurar el workflow (30-60 minutos), configurar credenciales de APIs (30 minutos), y ajustar prompts y voces (1-2 horas). Una vez configurado, cada episodio se genera en 3-8 minutos dependiendo de la longitud y el motor TTS elegido. El tiempo de generación no requiere intervención humana.
Conclusión
La combinación n8n + Render bajó la barrera de entrada para producción automatizada de podcasts a un nivel que hace dos años parecía impensable fuera de equipos con ingenieros dedicados. Hoy, con un fin de semana de configuración y menos de USD 20/mes de infraestructura, tenés un pipeline completo que escala a decenas de episodios semanales.
Lo que cambió en 2026 es la calidad de los motores TTS: ElevenLabs llegó a un punto donde la voz sintética pasa el filtro de la mayoría de los oyentes en episodios de menos de 15 minutos. Eso despeja el principal obstáculo de adopción que existía antes.
Si tu equipo produce contenido de audio regularmente y todavía lo hace a mano, el costo de oportunidad de no automatizar ya es mayor que el costo de aprender a hacerlo. Los templates de n8n.io son el punto de entrada más directo: elegí el que más se parece a tu caso de uso, configuralo, y ajustá desde ahí.

![Kelsey Hightower: Kubernetes and retiring at the top [video] - ilustracion](https://donweb.news/wp-content/uploads/2026/06/kelsey-hightower-retiro-google-kubernetes-hero-768x429.jpg)