Router de soporte multiidioma con IA en n8n: lo que aprendí
Construir un router de soporte multiidioma con IA en n8n parece sencillo hasta que lo probás con emails reales. Lo que arrancó como un flujo de 5 nodos para clasificar mensajes en inglés y alemán terminó siendo un sistema con scoring categórico, señales de urgencia por idioma y una sola llamada de extracción estructurada que reemplazó tres llamadas separadas a la API.
En 30 segundos
- Los modelos LLM inflan scores de confianza hacia 0.7-1.0 por defecto; usar categorías “high/mid/low” en vez de escalas numéricas mejora la precisión real de clasificación.
- Señales de urgencia como “URGENT” en inglés no se traducen automáticamente: necesitás listas explícitas por idioma (“dringend”, “schnell” en alemán).
- Combinar clasificación, sentiment y resumen en una sola llamada de extracción reduce latencia y costo respecto a tres llamadas separadas.
- La confianza baja no es una señal para rechazar emails, sino para identificar dónde el prompt necesita refinamiento.
- El flujo completo integra Gmail trigger, Extractor node de n8n, Switch nodes condicionales y salida a Slack o cola manual según el nivel de confianza.
Un router de soporte multiidioma con IA en n8n es un flujo automatizado que recibe emails entrantes en múltiples idiomas, los clasifica por categoría y urgencia usando un modelo de lenguaje, y los deriva al equipo o canal correcto sin intervención humana. El desafío real no está en conectar los nodos, sino en hacer que el modelo decida bien cuando los emails son ambiguos, mezclan idiomas o usan expresiones coloquiales que el modelo nunca vio en el training.
Por qué los routers de soporte bilingüe son más complejos de lo que parecen
Ponele que recibís un email en alemán con “Das ist dringend, bitte antworten Sie schnell” y otro en inglés con “Hi, just following up on my ticket from last week.” Ambos son de soporte. Uno es urgente. El otro puede esperar tres días. Un modelo genérico sin contexto de idioma los va a clasificar con una diferencia de confianza de 0.03 puntos, que en la práctica es ruido estadístico.
Según el hilo original en la comunidad de n8n, lo que arrancó como un proyecto para un amigo (un sistema simple de clasificación de emails) se convirtió en algo bastante más sofisticado cuando se empezó a probar con emails reales. Cada idioma tiene sus propios marcadores de urgencia, su propio registro de frustración y su propio vocabulario técnico. El sistema necesitaba entender no solo el idioma, sino el tono cultural detrás.
Bandas categóricas vs scores numéricos: el problema de la inflación de confianza
Acá viene lo bueno: los LLMs son pésimos para autoevaluar su confianza en una escala de 0 a 1.
Si le pedís a un modelo que clasifique un email y te diga “qué tan seguro estás del 0 al 1”, casi siempre te va a devolver algo entre 0.72 y 0.98, incluso cuando está genuinamente confundido. Los modelos aprenden a sonar seguros porque eso es lo que se refuerza en el training. El resultado: una escala de confianza que en la práctica funciona como binaria (¿es 0.78 diferente de 0.84 para tu lógica de routing?).
La solución que surgió en este caso de estudio es usar categorías discretas: high / mid / low confidence. Le pedís al modelo que categorice su certeza, no que la cuantifique. Esto tiene dos ventajas concretas: el modelo tiene que comprometerse con una categoría (“sé que es billing” vs “podría ser billing o podría ser soporte técnico”) y vos podés escribir lógica condicional mucho más clara en los Switch nodes de n8n. En instalación de n8n con Docker profundizamos sobre esto.
Confianza como herramienta diagnóstica, no como filtro de descarte
Un error común al implementar este tipo de sistemas: cuando el modelo devuelve confianza baja, muchos lo tratan como señal para rechazar el email o enviarlo directamente a revisión manual. El problema es que así perdés información valiosa.
Guardá la confianza como metadata en cada clasificación. Después de una semana de emails reales, revisá qué categorías acumulan más clasificaciones de confianza baja. Si el 60% de los emails de “billing” tienen confianza “mid” o “low”, el prompt para esa categoría está mal escrito, no el modelo. (Spoiler: casi siempre es el prompt.)
¿Cómo lo usás entonces? El email con baja confianza entra al flujo igual, pero se marca para revisión posterior. No lo parás, lo rastreás. Con ese dataset podés refinar el prompt de forma quirúrgica: más ejemplos de la categoría problemática, contexto adicional sobre el dominio del negocio, instrucciones explícitas sobre qué hacer cuando hay ambigüedad.
Señales de urgencia específicas por idioma: no asumas que se traduce solo
El sistema genérico busca “URGENT” o “ASAP” y listo. Funciona para el 40% de los casos reales.
El problema es que cada idioma tiene su propio vocabulario de urgencia, y a veces es implícito. En alemán, nadie escribe en mayúsculas gritando. La urgencia se comunica con “dringend”, “schnell”, “sofort” o con el contexto (“wir verlieren Kunden” = estamos perdiendo clientes). Un modelo sin esa lista explícita lee esos emails como neutrales.
La solución que describe el segundo hilo de la comunidad es agregar al prompt una lista de señales de urgencia por idioma, explícitas. Para inglés: “ASAP”, “urgent”, “critical issue”, “system down”. Para alemán: “dringend”, “sofort”, “dringender Handlungsbedarf”, “Systemausfall”. Para español: “urgente”, “problema crítico”, “caída del sistema”, “necesito respuesta ahora”.
Con esas listas, el mismo email que antes clasificaba con urgencia “normal” empieza a clasificar correctamente. No es magia, es contexto que el modelo necesitaba y no tenía. Relacionado: automatizar sin límites con n8n.
Una sola llamada de extracción vs múltiples llamadas: latencia y costo
El flujo original tenía tres llamadas separadas a la API LLM: una para clasificar la categoría del email, otra para detectar el sentiment, otra para extraer el resumen. Parecía modular y prolijo. En la práctica, era caro, lento y a veces inconsistente (el sentiment contradecía la categoría porque cada llamada operaba sin contexto de las otras).
La alternativa: un solo Extractor node de n8n con un prompt que pide todo junto en una estructura JSON de respuesta. Algo así:
- category: billing / technical / sales / other
- confidence: high / mid / low
- urgency: high / normal / low
- sentiment: frustrated / neutral / positive
- summary: una oración del problema
- language: de / en / es / other
El modelo razona todo en una sola pasada. Además de reducir el costo de 3 requests a 1 (que en volumen alto es significativo), la consistencia mejora: el sentiment tiene en cuenta la categoría y el resumen refleja la urgencia detectada, porque el modelo los procesa juntos.
Según la documentación oficial de n8n, el nodo Text Classifier de LangChain soporta salida estructurada, pero para extracciones multi-campo complejas conviene usar el Information Extractor con un schema JSON definido.
El flujo técnico: Gmail, el Extractor node y los Switch condicionales
El pipeline completo tiene esta estructura:
| Nodo | Función | Output |
|---|---|---|
| Gmail Trigger | Detecta email nuevo en bandeja de soporte | Raw email + metadata |
| Information Extractor | Clasifica, analiza sentiment, resume | JSON estructurado |
| Switch (Confidence) | Separa high vs mid/low confidence | Dos ramas |
| Switch (Category) | Routing por categoría | billing / tech / sales |
| Switch (Urgency) | Prioridad dentro de cada categoría | Alta / normal |
| Slack / Email / Queue | Notifica al equipo correcto | Mensaje con contexto |
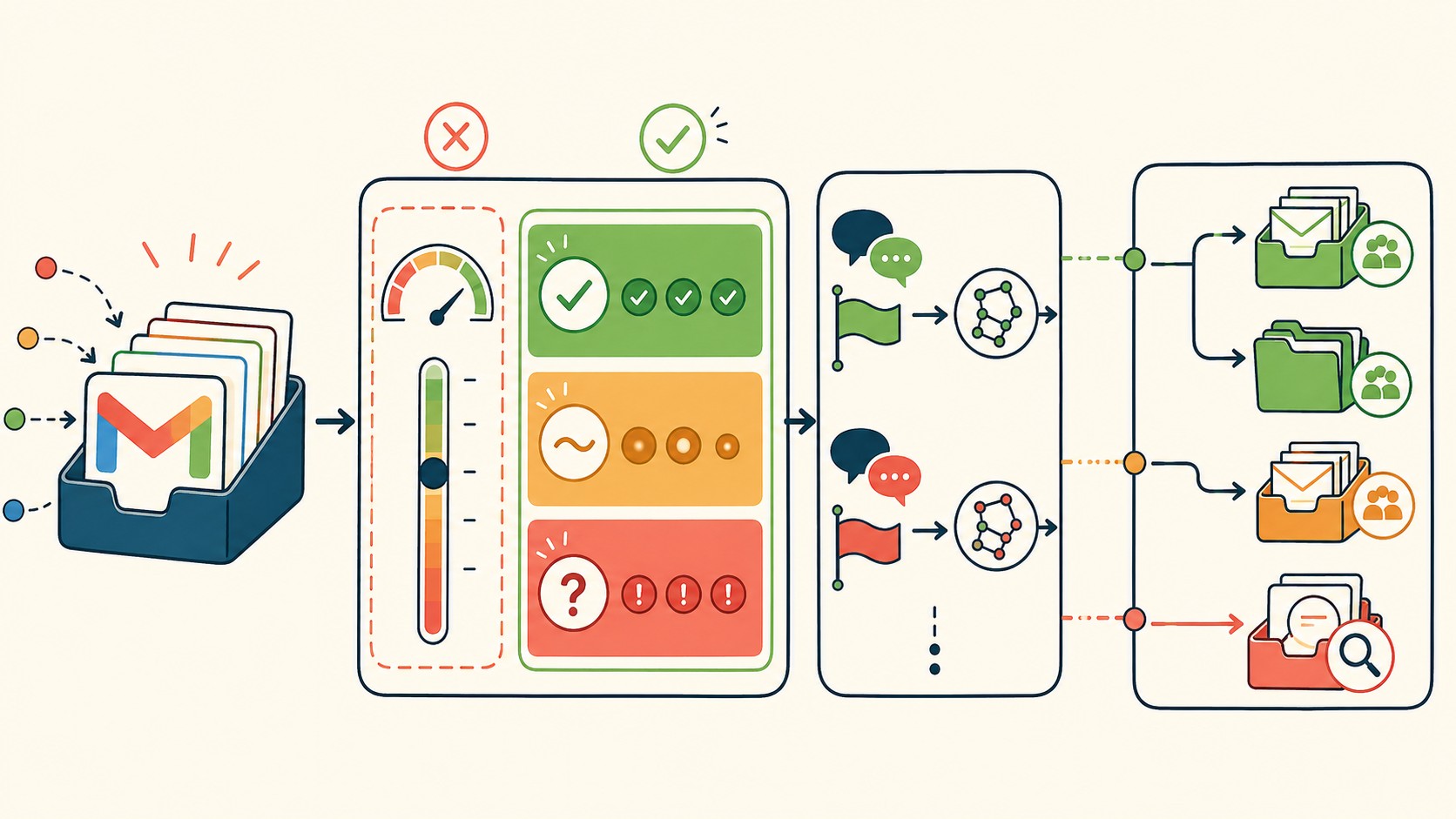
Los emails con confianza “low” van a una cola de revisión manual, no al circuito automático. Esto evita que el sistema cometa errores visibles con los casos más ambiguos, que son exactamente los que más importan al cliente.
Evaluación continua: cómo sabés si el flujo está mejorando
Acá la mayoría de los proyectos flaquea. Montás el flujo, funciona “bastante bien” en los primeros días y lo dejás correr. Dos meses después nadie sabe si sigue funcionando bien o si se degradó silenciosamente.
Lo que sirve: armarse un dataset de validación con emails reales clasificados a mano. Cien emails etiquetados manualmente son suficientes para tener una baseline. Cada semana, corrés el flujo sobre ese dataset y medís cuántas clasificaciones coinciden con la etiqueta manual. Si la tasa de acierto baja más de 5 puntos porcentuales, revisás el prompt. Más contexto en estrategia SEO para soporte multiidioma.
¿Alguien lo implementa en la práctica? La minoría. Pero es la diferencia entre un prototipo y un sistema que realmente escala en producción.
n8n tiene soporte nativo para evaluaciones de flujos (en plan Cloud) y también podés armar métricas customizadas guardando los resultados en Google Sheets o en una base de datos con un nodo adicional. No es complejo, pero hay que querer hacerlo.
Errores comunes al construir este tipo de sistemas
Usar un solo prompt en inglés para todos los idiomas
El prompt en inglés funciona bien para emails en inglés. Para alemán, los resultados bajan notoriamente. Lo correcto es incluir instrucciones explícitas sobre el idioma esperado o, mejor, prompts con ejemplos en cada idioma.
Tratar la confianza baja como error del sistema
Confianza baja no significa que el flujo está roto, significa que ese email es genuinamente ambiguo. Descartarlo o enviarlo siempre a manual sin trackear el patrón desperdicia información que podría mejorar el sistema.
No incluir el idioma en el output del extractor
Si el nodo de extracción no devuelve el idioma detectado, perdés la capacidad de auditar si las señales de urgencia específicas por idioma se están aplicando correctamente. Es un campo que tarda cero segundos en agregar al schema.
Confundir urgencia con sentiment negativo
Un cliente frustrado no necesariamente tiene un problema urgente. Un email técnico muy frío puede describir una caída de producción. Son dos dimensiones distintas y el flujo tiene que manejarlas por separado, no tratarlas como sinónimos. Esto se conecta con lo que analizamos en confiabilidad de servicios externos.
Si querés profundizar en esto, tenemos un artículo sobre 5 things I learned building a bilingual support inbox router.
En nuestro artículo sobre 5 things I learned building a bilingual support inbox router profundizamos en esta estrategia.
Si te interesa el tema de automatización multiidioma, revisá 5 things I learned building a bilingual support inbox router.
Preguntas Frecuentes
¿Cómo clasificar automáticamente emails de soporte por idioma en n8n?
Usás el nodo Information Extractor de n8n con LangChain y un schema JSON que incluya el campo “language” como output. El modelo detecta el idioma automáticamente si el prompt incluye instrucción explícita. Para mejorar la precisión, incluí ejemplos de frases de urgencia en cada idioma dentro del mismo prompt.
¿Qué herramientas sin código sirven para un router de emails multiidioma?
n8n es la opción más flexible para este caso, con soporte nativo para nodos de LangChain y Gmail. Permite combinar clasificación, extracción estructurada y routing condicional en un solo flujo visual. Para equipos sin experiencia técnica, el plan n8n Cloud incluye templates de inbox routing que se pueden adaptar sin escribir código.
¿Cómo sé si mi modelo de IA tiene confianza alta en la clasificación de emails?
Incluí “confidence” como campo en el schema de salida del extractor, con valores permitidos “high”, “mid” o “low”. Evitá pedirle un número entre 0 y 1: los LLMs inflan esos valores de forma poco útil. Con categorías discretas, podés escribir lógica condicional clara en los Switch nodes y trackear qué categorías acumulan baja confianza para refinar los prompts.
¿Cuál es la mejor forma de enrutar emails de soporte en múltiples idiomas?
Una sola llamada de extracción estructurada que clasifique categoría, urgencia, sentiment e idioma en simultáneo da mejores resultados que múltiples llamadas separadas. Después, Switch nodes condicionales en n8n manejan el routing según categoría y urgencia, con una rama separada para emails de confianza baja que van a revisión manual.
¿Conviene hacer un router de soporte en n8n o con una herramienta dedicada de help desk?
Depende del contexto. Si ya usás una plataforma de help desk (Zendesk, Freshdesk), tiene sentido integrarla vía API dentro del flujo de n8n en vez de reemplazarla. Si el equipo es pequeño y los emails llegan a Gmail, n8n con LLM es más rápido de implementar y más barato que licenciar una herramienta dedicada solo para clasificación inteligente.
Conclusión
Construir un router de soporte multiidioma con IA en n8n que funcione en producción requiere algo más que conectar un LLM a Gmail. Las cinco lecciones concretas de este caso de estudio, scoring categórico en vez de numérico, confianza como diagnóstico no como filtro, señales de urgencia por idioma, extracción en una sola llamada, y evaluación continua con dataset real, son la diferencia entre un prototipo que impresiona en demo y un sistema que el equipo de soporte puede confiar.
El nodo Information Extractor de n8n con LangChain hace el trabajo pesado si el schema y el prompt están bien pensados. Lo que no se resuelve solo es la disciplina de mantener el sistema: revisar los emails de baja confianza, actualizar las señales de urgencia cuando el vocabulario del cliente cambia, medir la tasa de acierto contra un dataset de referencia. Eso es lo que sostiene el sistema a los seis meses.
Fuentes
- Comunidad n8n – 5 things I learned building a bilingual support inbox router
- Comunidad n8n – I built a support inbox router for a friend
- Documentación oficial n8n – Text Classifier node
- Tu Consultor Digital – Cómo clasificar correos con IA y n8n