Errores reales de agentes n8n en producción
Todo workflow de automatización termina fallando en algún momento, y si no tenés un plan para cuando eso pasa, el error queda escondido y te enterás cuando ya rompió algo. El manejador de errores n8n se arma con el nodo Error Trigger: un workflow dedicado que se dispara solo cada vez que otro workflow crashea, con datos estructurados que podés mandar a Slack, mail, una planilla o una cola de reintentos. La guía de referencia salió el 2 de julio de 2026 en dev.to.
El Error Trigger de n8n es un nodo especial que arranca un workflow de manejo de errores cada vez que cualquier otro workflow de tu instancia lanza un error sin capturar. No se conecta a un flujo normal: es el primer nodo de un workflow que designás como manejador. Recibe contexto rico del fallo (mensaje de error, ID de la ejecución fallida y metadatos completos del workflow) y un solo manejador puede servir a varios workflows fuente a la vez.
En 30 segundos
- Se dispara solo: el Error Trigger arranca automáticamente cuando un workflow monitoreado lanza un error sin capturar.
- Uno sirve a muchos: un único workflow manejador cubre todos los workflows que lo asignen en Settings → Error Workflow.
- Trae contexto: recibís execution.id, execution.url, execution.error.message, execution.error.stack y execution.lastNodeExecuted.
- Ojo con las pruebas: no se ejecuta en corridas manuales, solo cuando el workflow está activo y falla de verdad.
- Riesgo real: si el manejador de errores falla, ese fallo es silencioso (n8n no anida un handler dentro de otro).
¿Cómo configurar el Error Trigger en n8n?
Son tres pasos y ninguno tiene misterio. Lo que sí engaña es el orden: primero armás el manejador, después lo enganchás. Te puede servir nuestra cobertura de al trabajar con integraciones externas.
- Creá el workflow manejador: nuevo workflow, y como primer nodo poné el Error Trigger. Después de ese nodo va toda tu lógica de alerta o log.
- Asignalo al workflow fuente: abrí el workflow que querés monitorear, andá al ícono de engranaje abajo a la izquierda (Options → Settings), y en Error Workflow elegí el nombre de tu manejador. Guardá.
- Activá los dos: el manejador tiene que estar guardado y el workflow fuente activo. Desde ahí, cada vez que ese workflow falle, n8n dispara tu handler.
¿Cómo lo probás sin esperar a que algo se rompa en producción? Armá un workflow temporal con un solo nodo que tire un error a propósito (un Code node con un throw alcanza), asignale tu manejador, activalo y ejecutalo. Ahí ves si tu handler reacciona. Según la documentación oficial de n8n, esa es la forma recomendada de validar el circuito antes de confiarle workflows reales.
¿Qué información recibe el Error Trigger sobre los fallos?
Acá está lo que hace útil al nodo. No te avisa “algo falló” y listo: te pasa un objeto con todo el contexto para que sepas qué reventó, dónde y con qué link ir a mirar.
Accedés a los campos con expresiones {{ $json.execution.error.message }} y similares. Estos son los que vas a usar el 90% del tiempo:
| Campo | Qué contiene |
|---|---|
| execution.id | ID de la ejecución que falló |
| execution.url | Link directo a la ejecución en tu instancia n8n |
| execution.error.message | El texto del error |
| execution.error.stack | El stack trace completo |
| execution.lastNodeExecuted | Nombre del último nodo que corrió antes de romperse |
| execution.retryOf | ID de la ejecución original (solo si es un reintento) |
| workflow.id | ID del workflow que falló |
| workflow.name | Nombre legible del workflow |
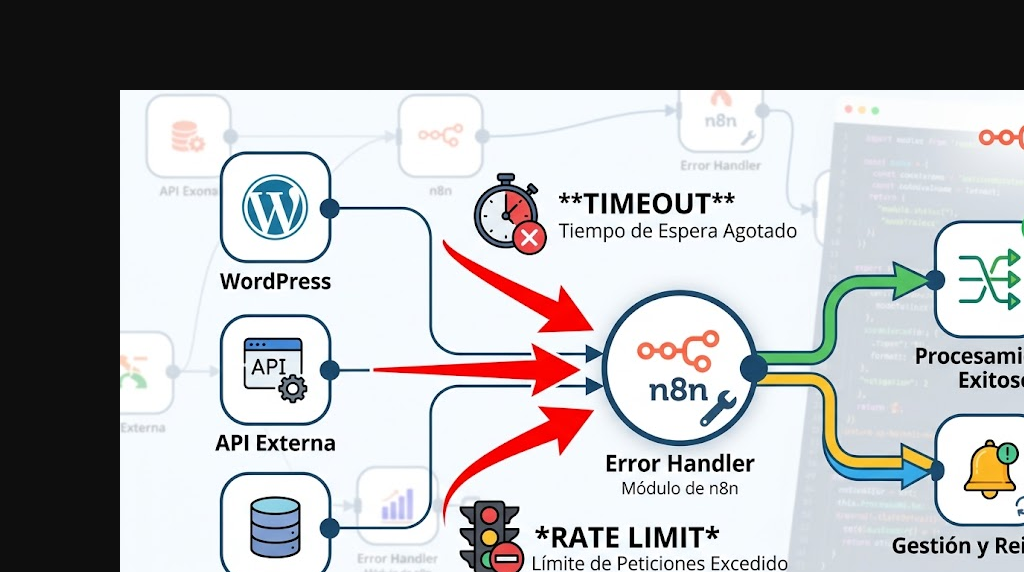
El campo execution.url es el que más tiempo te ahorra. En vez de buscar a mano cuál de las 200 ejecuciones de hoy fue la que falló, hacés clic en el link del mensaje de Slack y caés parado en la ejecución exacta, con el nodo culpable resaltado. Lo explicamos a fondo en cuando tus workflows hacen peticiones HTTP.
¿Cómo enviar notificaciones de error a Slack y Gmail?
Ponele que se te cae el workflow que sincroniza pedidos cada hora. Querés enterarte en el momento, no al otro día. Ahí conectás un nodo de Slack o de Gmail directo después del Error Trigger.
- Slack para lo urgente: conectá el nodo Slack, apuntá al canal de alertas, y en el texto meté algo como
Falló {{ $json.workflow.name }} en el nodo {{ $json.execution.lastNodeExecuted }}. Ver: {{ $json.execution.url }}. Notificación inmediata, con link para investigar. - Gmail para el registro: el nodo Gmail sirve mejor para un correo con más detalle, incluido el stack trace, que quede en la bandeja como constancia. Hay una plantilla centralizada de manejo de errores con alertas por Gmail lista para importar.
La diferencia práctica: Slack lo mirás al toque y sirve para incidentes que necesitan reacción. El mail asincrónico lo dejás para el histórico y para errores de menor prioridad que revisás cuando podés. No hace falta elegir uno, podés mandar a los dos con severidades distintas.
Patrones de logging, retry y escalamiento
El nodo es la base. Lo que hacés después define si tenés un sistema serio o solo un pitido molesto. Estos son los cuatro patrones que más se usan. Relacionado: para alertar al equipo sobre fallos.
| Patrón | Para qué sirve | Herramienta típica |
|---|---|---|
| Notificación | Enterarte al instante de un fallo crítico | Slack, Gmail |
| Logging persistente | Historial para detectar patrones y errores recurrentes | Google Sheets, base de datos |
| Retry automático | Reintentar el workflow que falló con backoff | Wait node + re-ejecución |
| Routing por severidad | Mandar crítico a un lado y warning a otro | Switch/IF por tipo de error |
El patrón de logging es el más subestimado. Si escribís cada fallo en una planilla con timestamp, nombre del workflow y mensaje, en dos semanas tenés un mapa clarísimo de qué se rompe seguido. Eso vale más que veinte alertas sueltas que nadie relaciona entre sí. La guía de buenas prácticas de manejo de errores en n8n insiste en esto: los fallos silenciosos son los que te terminan costando plata.
Para el routing por severidad, un Switch después del Error Trigger revisa el mensaje o el workflow de origen y decide: si es un cobro fallido, escala a un canal de guardia; si es un scraping que devolvió vacío, va a un mail de baja prioridad. Así no despertás a nadie a las 3 de la mañana por algo que espera hasta el lunes.
Limitaciones del Error Trigger en producción
Antes de confiarle tu infraestructura, tres cosas que conviene tener claras (porque las descubrís justo cuando más las necesitás).
- Si el manejador falla, nadie te avisa: n8n no anida un handler dentro de otro. Si tu workflow de errores se rompe, ese fallo es silencioso. Mantené el manejador simple y sin dependencias frágiles.
- No corre en pruebas manuales: el Error Trigger solo se dispara con el workflow activo y un fallo real. Probarlo desde el editor con “Execute Workflow” no lo activa.
- execution.retryOf solo aparece en reintentos: si tu lógica de retry lo lee sin chequear que exista, en la primera ejecución te va a dar undefined. Validá siempre antes de usarlo.
Si corrés n8n self-hosted, todo esto depende de que tu servidor aguante. Un VPS con recursos garantizados en donweb.com te evita que el propio n8n se caiga por falta de memoria justo cuando más lo necesitás para atrapar errores.
Errores comunes al usar el Error Trigger
- Probarlo en manual y creer que no anda: el error más frecuente. Ejecutás desde el editor, no pasa nada, y pensás que está roto. No: solo funciona con el workflow activo y un fallo genuino. Armá un workflow de prueba que tire un throw real.
- Loops de retry infinitos: si el manejador reintenta el workflow y ese workflow vuelve a fallar, disparás el manejador otra vez, y así hasta el infinito. Poné un límite de reintentos y chequeá
execution.retryOfpara cortar la cadena. - Olvidarte de activar el manejador: lo armás, lo asignás, pero queda inactivo. Verificá que esté guardado y que el workflow fuente lo tenga seleccionado en Error Workflow.
- Hardcodear secretos: tokens de Slack o credenciales de mail escritos en el nodo. Usá el gestor de credenciales de n8n, no texto plano dentro de una expresión.
Preguntas Frecuentes
¿Cómo crear un manejador de errores global en n8n?
Creá un workflow nuevo con el nodo Error Trigger como primer nodo y agregá tu lógica de alerta después. Luego, en cada workflow que quieras monitorear, andá a Options → Settings → Error Workflow y seleccioná ese manejador. Un solo manejador puede servir a todos tus workflows. Para más detalles técnicos, mirá si aún no tenés n8n configurado.
¿Qué información recibe el Error Trigger sobre los fallos?
Recibe un objeto con execution.id, execution.url, execution.error.message, execution.error.stack, execution.lastNodeExecuted, más workflow.id y workflow.name. Accedés a cada campo con expresiones como {{ $json.execution.error.message }}. El campo execution.url te lleva directo a la ejecución fallida.
¿Por qué el Error Trigger no se ejecuta cuando lo pruebo?
Porque el Error Trigger no se dispara en ejecuciones manuales desde el editor. Solo arranca cuando el workflow monitoreado está activo y falla de verdad. Para probarlo, creá un workflow temporal que tire un error a propósito y ejecutalo activado.
¿Cómo evitar loops de retry infinitos?
Poné un contador de reintentos y validá el campo execution.retryOf antes de reintentar. Si el workflow reintentado vuelve a fallar sin límite, el manejador se dispara en cadena sin parar. Cortá después de dos o tres intentos y escalá a una notificación humana.
¿Un solo manejador de errores sirve para varios workflows?
Sí. Un mismo workflow manejador puede servir a múltiples workflows fuente. Solo tenés que asignarlo en el Error Workflow de cada uno. Usá los campos workflow.name y workflow.id dentro del manejador para identificar cuál falló en cada aviso.
Conclusión
El Error Trigger es la diferencia entre enterarte de un fallo en el momento o descubrirlo cuando un cliente te reclama. Armás un workflow manejador, lo asignás una vez y cubrís toda tu instancia. Lo importante no es el nodo en sí, sino qué colgás después: una alerta a Slack para lo urgente, un log a planilla para detectar patrones, y un routing por severidad para no ahogarte en avisos. Empezá simple, con una notificación a un canal, y verificá que funcione tirando un error de prueba. Después sumás logging y retry. Y recordá la trampa principal: si el manejador falla, ese error es silencioso, así que mantenelo liviano y sin dependencias que se puedan caer.
¿Cómo saber si el Error Trigger de n8n está funcionando?
Activá el workflow manejador y el workflow fuente, luego ejecutá un workflow de prueba que tire un error a propósito (por ejemplo, con un nodo Code que lance un throw). Si el manejador se dispara y recibís la alerta, está andando. Recordá que no funciona en pruebas manuales desde el editor.
¿Cuántos workflows puede cubrir un solo Error Trigger en n8n?
Un único workflow manejador puede cubrir todos los workflows que quieras. Solo tenés que asignarlo en Settings → Error Workflow de cada workflow fuente. No hay límite documentado, pero mantené el manejador simple para evitar que falle silenciosamente.
¿Qué hago si mi manejador de errores n8n no se ejecuta?
Verificá que el workflow manejador esté guardado y activo, y que el workflow fuente tenga seleccionado el nombre correcto en Error Workflow. También asegurate de que el workflow fuente esté activo. Si probás desde el editor, no se va a disparar; usá un workflow de prueba con un throw real.
Fuentes
- Documentación oficial del nodo Error Trigger – n8n Docs
- Guía de manejo de errores en n8n – n8n Docs
- n8n Error Trigger Node: Build a Global Error Handler (dev.to, 2 jul 2026)
- Sistema centralizado de gestión de errores con alertas por Gmail – n8n Templates
- Buenas prácticas de manejo de errores en n8n – dev.to