Monitoreo ciego de CDN: el caso Osaka y la solución
Un PoP de Cloudflare en Osaka estaba sirviendo un manifest HLS con una URL de variante eliminada. El resultado: 38% de caída en watch time en Tokio en 15 minutos. Todos los monitores mostraban verde. El agregador de health checks multi-región es el sistema que detecta exactamente este tipo de falla regional invisible antes de que el pager te despierte a las 3 AM.
En 30 segundos
- Un incidente real en Osaka (mayo 2026) mostró que el monitoreo desde una sola región es ciego: Cloudflare dashboard en verde, UptimeRobot en verde, miles de usuarios japoneses sin poder cargar video.
- El problema era caché stale en un PoP específico con una variant URL eliminada, invisible desde cualquier punto fuera de Japón en ISP residencial.
- Un agregador de health checks multi-región prueba paths reales desde 9 ubicaciones simultáneas y alerta por anomalías regionales, no globales.
- La diferencia clave con el monitoreo tradicional: en vez de “¿el sitio está up?”, pregunta “¿el manifest HLS en este PoP específico es válido?”
- Para sitios con audiencia en APAC, 100ms menos de latencia se traduce en 7% más de watch time — los números justifican la infraestructura.
Cloudflare es una plataforma de Content Delivery Network (CDN) y seguridad web que distribuye contenido y protege sitios contra ataques, desarrollada por Cloudflare desde 2009. Proporciona servicios como proxy inverso, caché DNS, firewall de aplicaciones web y protección DDoS.
El problema: monitoreo ciego a nivel regional
Son las 03:14 de un sábado. El pager suena. Watch time en el PoP de Tokio cayó 38% en 15 minutos. Abrís el dashboard de Cloudflare: verde. UptimeRobot pinga el apex domain: todo bien. Los servidores LiteSpeed de origen responden en menos de 80ms. Y sin embargo, miles de usuarios japoneses están fallando silenciosamente al cargar el manifest HLS de los videos más populares.
Esto es exactamente lo que le pasó al equipo detrás de este post técnico publicado el 24 de mayo de 2026. El culpable era un único PoP en Osaka donde Cloudflare cacheaba un manifest stale con una variant URL ya eliminada. Desde cualquier punto fuera de ese edge específico, el archivo se veía bien. Desde Japón, en un ISP residencial JP, estaba roto.
Sus health checks existentes, del tipo que pingan desde una sola región en AWS us-east, no podían ver esto. Estaban ciegos.
El error conceptual de fondo es tratar “¿el sitio está arriba?” como un booleano único. Con un sitio de video detrás de Cloudflare, esa pregunta no alcanza. “¿El manifest sirve correctamente en Tokio?” es tan crítico como “¿la base de datos acepta escrituras?” Pero casi ningún sistema de monitoreo tradicional lo mide así.
Qué es un agregador de health checks multi-región
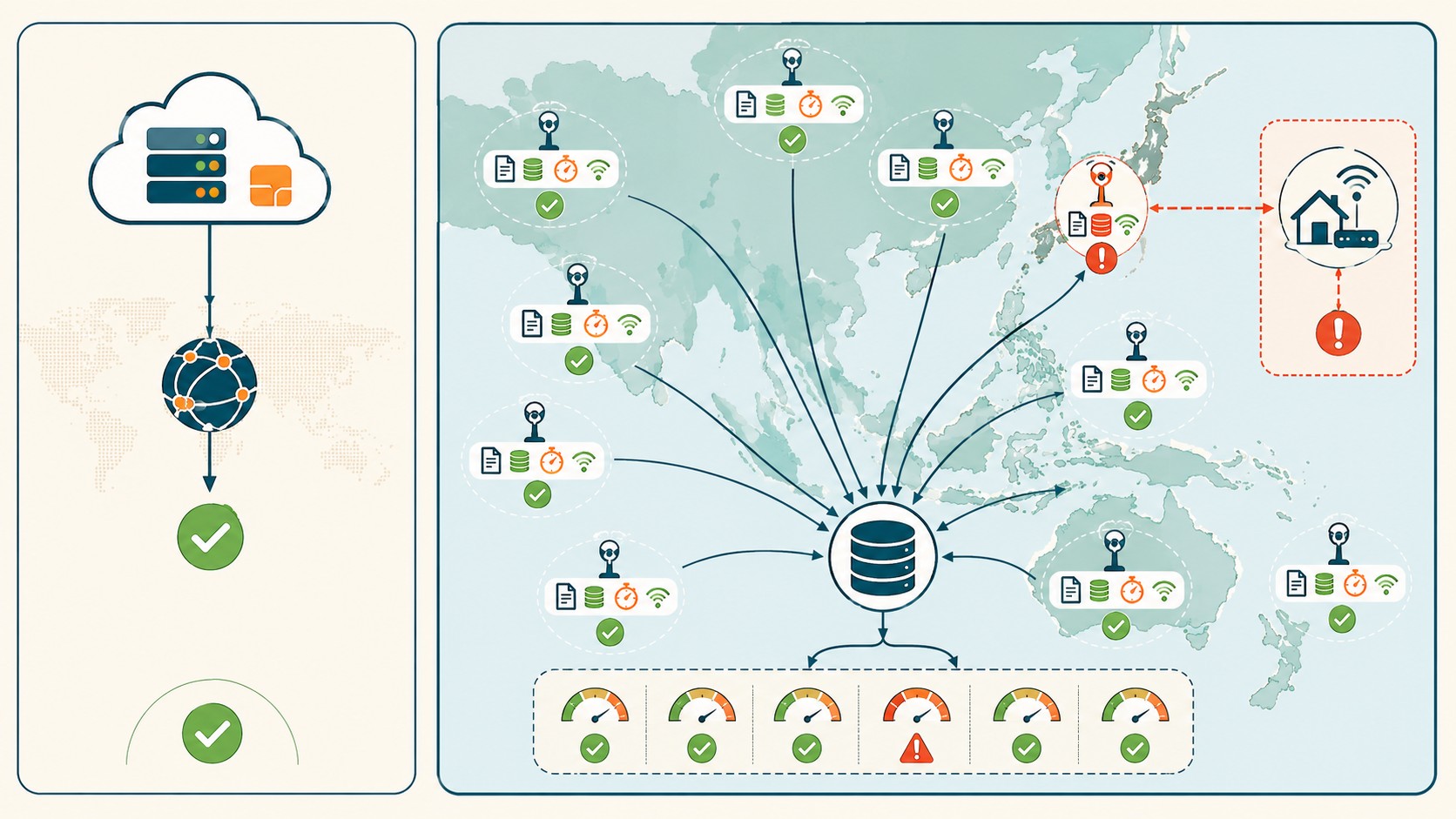
Un agregador de health checks multi-región es un sistema que prueba paths reales de CDN desde múltiples ubicaciones de red simultáneas, consolida los resultados en un almacenamiento centralizado y genera alertas basadas en anomalías por región, no en outages globales.
No es un ping checker. No es UptimeRobot con múltiples ubicaciones. La diferencia está en qué se prueba: en vez de verificar si un dominio responde, verificás si el manifest HLS en el PoP de Osaka tiene las variant URLs correctas, si el cache hit ratio en Singapur está por encima del umbral, si el TTFB desde Seúl para un path de video específico está dentro del rango esperado.
Cloudflare, YouTube y Twitch lidian con este problema a escala. Para operadores más chicos con audiencia en APAC, la diferencia entre tenerlo y no tenerlo es la diferencia entre enterarte del problema a las 3 AM o cuando ya perdiste el 40% del watch time de esa noche. Lo explicamos a fondo en pipelines automatizados para despliegues distribuidos.
Diferencia crítica: monitoreo global vs. regional
Ponele que tu TTFB promedio global es 80ms. Buen número. Pero si ese promedio esconde 45ms en US-East y 210ms en APAC, el dato global no te sirve de nada para los usuarios japoneses.
Según datos de infraestructura de CDN para streaming (2025-2026), la latencia en APAC puede ser el doble que en US sin que ninguna métrica global lo muestre. Los ISPs en islas del Pacífico agregan hasta un 35% adicional en resolución DNS. Y los usuarios residenciales en Japón frecuentemente experimentan comportamientos de caché distintos a los de un datacenter en la misma ciudad.
| Aspecto | Monitoreo global tradicional | Agregador multi-región |
|---|---|---|
| Unidad de medida | Disponibilidad global (boolean) | Estado por PoP/región |
| Qué testea | Si el dominio responde | Si el contenido en ese PoP es correcto |
| Detecta caché stale | No | Sí |
| Detecta fallas ISP-específicas | No | Sí (probes en redes residenciales) |
| Latencia de alerta | Cuando el outage es global | Cuando 1-2 regiones muestran anomalía |
| Falsos negativos | Alto (incidente Osaka: 0 alertas) | Bajo |
| Infraestructura requerida | Baja (1 nodo) | Alta (9+ nodos distribuidos) |
La columna de falsos negativos lo dice todo. El incidente de Osaka generó cero alertas en el monitoreo global. Con el agregador multi-región, hubiera disparado alerta en minutos.
Arquitectura técnica: los cuatro componentes del agregador
El sistema que describe el equipo tiene cuatro bloques concretos:
1. Probes distribuidos en 9 regiones APAC
Cada probe corre en una ubicación de red real (no un datacenter simulando usuarios finales) y testea paths específicos de CDN. No el apex domain, sino las URLs de manifest HLS, las variant streams, los segmentos de video. Los probes verifican tres cosas: que el manifest existe, que las URLs dentro del manifest son válidas, y que el TTFB está dentro del umbral esperado para esa región.
2. Store centralizado en SQLite
Todos los resultados de los 9 probes van a un SQLite centralizado. La decisión de usar SQLite en vez de algo más pesado (Postgres, InfluxDB) es interesante: para el volumen de datos de health checks regionales, SQLite alcanza y evita operaciones costosas. El schema almacena por probe: región, timestamp, path testeado, TTFB, cache hit/miss, resultado de validación del manifest.
3. Lógica de alertas por región, no global
Acá viene lo diferenciador. El sistema no alerta si “el sitio está caído” globalmente. Alerta si una o más regiones muestran anomalías que el resto no muestra. Si Osaka tiene un TTFB 3x mayor que Tokio para el mismo path, eso dispara alerta aunque el promedio global sea normal. Si el manifest en Seúl tiene una variant URL que retorna 404 pero en Singapur está bien, eso es un incidente regional.
4. Dashboard de anomalías comparativas
El output final no es un semáforo verde/rojo global. Es una vista por región que muestra desviaciones respecto al baseline de esa misma región y respecto a las otras regiones en el mismo momento. Un PoP que siempre tiene 150ms de TTFB no es una alerta. Un PoP que tiene 150ms cuando el resto está en 45ms, sí. Esto se conecta con lo que analizamos en herramientas para orquestar despliegues automatizados.
Implementación: qué medir y cómo estructurarlo
Si te interesa implementar algo similar, el equipo identifica tres capas de medición esenciales para una flota de video CDN:
Manifest correctness: el probe descarga el manifest HLS y parsea cada URL de variant stream. Hace un HEAD request a cada una. Si alguna retorna 404 o 410, el manifest está roto aunque el archivo en sí sirva con 200. Este fue exactamente el problema en Osaka.
TTFB por región y por tipo de asset: no todo el TTFB importa igual. El del manifest es crítico (bloquea el inicio de reproducción). El de los segmentos de video es importante pero con más tolerancia. Medís ambos por separado con umbrales diferentes.
Cache hit ratio por PoP: si un PoP está sirviendo todo desde origen en vez de desde caché, algo está mal aunque la latencia parezca aceptable. Un cache hit ratio por debajo del 85% en un PoP de producción activo es señal de problema.
Conceptualmente, cada probe funciona así: se conecta a la red del PoP objetivo (o lo simula vía VPN residencial), hace el request al path de CDN real, registra TTFB, headers de caché (CF-Cache-Status, Age), y si es un manifest, parsea y valida el contenido. Todo eso va al SQLite con timestamp preciso para correlación posterior.
Casos de uso reales: cuándo necesitás esto
Video streaming es el caso obvio, pero no el único. SaaS con APIs distribuidas geográficamente, plataformas de gaming en vivo, e-commerce con inventarios sincronizados por región — todos tienen el mismo problema: una falla regional puede ser invisible desde el monitoreo central.
Para APAC específicamente, los números justifican la inversión. Según datos de monitoreo de CDN para streaming, 100ms menos de latencia en reproductores de video se correlaciona con aproximadamente 7% más de watch time completado. Si tu audiencia japonesa es significativa, ese 7% vale mucho más que el costo de correr 9 probes distribuidos.
Hay un escenario específico que vale la pena marcar: los usuarios en ISPs residenciales de Japón y Corea frecuentemente reciben rutas de CDN distintas a las que ven los requests desde datacenters. Ponele que todos tus health checks corren en AWS ap-northeast-1: estás testeando la ruta datacenter-a-CDN, no la ruta usuario-real-a-CDN. Son diferentes. (Sí, en serio. El incidente de Osaka lo demostró.) Tema relacionado: soluciones de protección en la capa edge.
Alertas por región: el umbral que evita el próximo Osaka
El equipo diseñó sus alertas con esta lógica: si 2 o más regiones muestran una caída de 30%+ en watch time sostenida por más de 5 minutos respecto al baseline de la misma hora del día anterior, alerta inmediata. Si solo 1 región muestra la anomalía, alerta de warning para investigación manual.
¿Por qué el umbral de 2 regiones para alerta crítica? Porque una sola región puede tener fluctuaciones naturales (mantenimiento de ISP, evento local de tráfico). Cuando dos regiones distintas muestran el mismo patrón al mismo tiempo, casi siempre es un problema en el CDN o en el origen.
La clave está en alertar sobre desviaciones respecto al propio baseline regional, no respecto a un valor absoluto global. Una región que “siempre” tiene 200ms no debería alertar cuando llega a 210ms. Pero sí debería alertar si sube a 600ms aunque ese valor sea “normal” para otra región con peor conectividad.
Con este sistema, según el post, el equipo detectó el siguiente incidente similar al de Osaka en 4 minutos desde el inicio del problema. Antes, ese incidente hubiera pasado desapercibido por horas.
Errores comunes al implementar health checks de CDN
Testear solo el apex domain: pingar example.com y ver que responde no dice nada sobre si los assets de CDN están bien. Tenés que testear los paths reales que usan tus usuarios.
Correr todos los probes desde el mismo proveedor cloud: si todos tus probes están en AWS, estás midiendo la experiencia de alguien conectado a AWS, no la de un usuario residencial en Osaka. La diferencia de ruta puede ser significativa.
Alertas basadas en umbrales absolutos: “alerta si TTFB supera 500ms” es un umbral global que ignora que distintas regiones tienen distintas baselines. Una región que normalmente está en 400ms debería alertar a los 600ms, no a los 500ms. Ya lo cubrimos antes en optimización global con infraestructura distribuida.
No validar el contenido del manifest, solo su disponibilidad: el incidente de Osaka era exactamente esto. El manifest respondía 200 OK, así que todos los monitores lo marcaban como healthy. Pero el contenido adentro tenía una URL rota. Un health check que solo chequea el status code no lo detecta.
Ignorar los headers de caché en el diagnóstico: el header CF-Cache-Status y el campo Age te dicen si estás viendo contenido fresco o stale, y desde qué PoP. Sin revisar esos headers, estás volando a ciegas sobre el estado real del caché.
Esto se conecta con Building a Multi-Region Health-Check Aggregator for Our Vide, donde cubrimos el tema en detalle.
Esto se conecta con Building a Multi-Region Health-Check Aggregator for Our Vide, donde cubrimos la solución en detalle.
Esto se conecta con el health check aggregator, donde cubrimos el tema en detalle.
Preguntas Frecuentes
¿Cómo saber si mi CDN tiene problemas solo en una región?
Necesitás probes que corran desde esa región específica y testéen los paths reales de tu CDN, no solo el dominio principal. Si el único monitoreo que tenés corre desde una ubicación única (por ejemplo, un servidor en US-East), no vas a detectar problemas específicos de un PoP en Asia. Herramientas como sistemas de monitoreo multi-punto o la construcción de probes propios en múltiples regiones son los dos caminos principales.
¿Por qué el monitoreo muestra verde pero los usuarios reportan fallas?
El caso más común es caché stale: tu CDN está sirviendo contenido viejo que tiene URLs o referencias ya inválidas. El archivo en sí existe y responde 200, así que el monitor lo ve bien. Pero el contenido adentro está roto. Otro caso frecuente es que los probes de monitoreo usen rutas de red distintas a las de usuarios residenciales reales, especialmente en ISPs de APAC.
¿Cómo implementar un agregador de health checks multi-región?
Los bloques básicos son: probes en múltiples ubicaciones reales que testean paths de CDN reales (no solo pings), un store centralizado para los resultados (SQLite alcanza para empezar), y lógica de alertas basada en desviaciones por región respecto al baseline de esa misma región. La parte más costosa es conseguir nodos de probe en redes residenciales reales de las regiones objetivo, no en datacenters.
¿Qué diferencia hay entre monitoreo global y regional de CDN?
El monitoreo global responde “¿está el sitio arriba?” con un booleano. El regional responde “¿está el contenido correcto sirviendo correctamente en este PoP específico para usuarios en esta red específica?” La diferencia es crítica para cualquier servicio con audiencia distribuida: un outage global es fácil de detectar, pero una falla en un único PoP que afecta a una región entera puede pasar desapercibida por horas.
¿Cómo detectar problemas de caché stale en ubicaciones específicas?
Revisá los headers de respuesta: CF-Cache-Status te dice el estado del caché en Cloudflare (HIT, MISS, STALE, EXPIRED), y el header Age indica cuántos segundos tiene ese objeto en caché. Si tu probe descarga un manifest HLS, también tenés que parsear el contenido y validar que las URLs de variant streams retornan status codes válidos (200 o 206). Un manifest que responde 200 con contenido inválido adentro es el escenario del incidente de Osaka.
Conclusión
El incidente de Osaka cambió cómo este equipo piensa el monitoreo. No como una pregunta booleana global, sino como una matriz de estados por región, por path, por tipo de contenido. La herramienta que construyeron, un agregador de health checks multi-región corriendo probes en 9 ubicaciones APAC con alertas basadas en anomalías regionales, es la respuesta directa a una clase de falla que el monitoreo tradicional no puede ver.
Si tu servicio tiene audiencia en APAC o en cualquier región donde los ISPs residenciales crean rutas de CDN distintas a las de los datacenters, el monitoreo desde un único punto es insuficiente. No porque sea malo, sino porque no mide lo que importa. Y cuando el pager suena a las 3 AM con una caída del 38%, ya es tarde para aprender eso.
Para quien quiera empezar sin construir todo desde cero, el primer paso es agregar validación de contenido a los health checks existentes: no solo verificar que el manifest responde 200, sino que las URLs adentro son válidas. Eso solo hubiera detectado Osaka antes del primer reporte de usuario.