Tu base de datos lenta: el problema del hot data
Si tu base de datos empezó lenta después de años funcionando bien, el problema casi nunca es el hardware ni el código. El problema es que mezclás datos que se usan todo el tiempo con datos que nadie toca hace meses, y el motor los trata igual. Todo queda “hot” en memoria, los índices crecen sin control, y el sistema colapsa bajo su propio peso.
En 30 segundos
- Las bases de datos se ralentizan cuando datos históricos (“cold”) conviven con datos activos (“hot”) en la misma tabla, forzando al motor a cargar todo en memoria.
- Los índices que al principio mejoran las queries terminan pesando en cada INSERT/UPDATE y ocupando RAM que no rinde nada.
- Las dos estrategias que resuelven el problema son archivado de datos históricos y particionamiento por fecha.
- Antes de agregar más hardware, identificá qué porcentaje de tus datos se accedió en los últimos 6 meses: en la mayoría de sistemas, es menos del 20%.
- El particionamiento permite que una query a datos de 2026 no toque ni analice registros de 2022.
Una base de datos “hot” es aquella donde todos los datos, sin importar su antigüedad o frecuencia de acceso, ocupan los mismos recursos de memoria y procesamiento. El concepto, popularizado en el contexto de ingeniería de software, describe el estado en que un sistema no distingue entre un registro de hace tres años y uno de hace tres minutos, y los trata con el mismo costo operacional.
El problema: por qué las bases de datos se ralentizan cuando crecen
Ponele que trabajás en un sistema de e-commerce. Al principio, la tabla orders tiene 10.000 filas. Los queries son instantáneos. El DBA es un héroe.
Después pasan dos años.
La tabla tiene 50 millones de registros. La mitad son órdenes de 2022 y 2023 que nadie consulta, pero están ahí. Cuando alguien hace una consulta sobre órdenes del último mes, el motor igual tiene que navegar índices que apuntan a datos de hace años, cargar páginas de datos en memoria que incluyen registros viejos, y mantener en caché estructuras que nadie usa.
Según el análisis publicado en dev.to el 16 de mayo de 2026, el ciclo es siempre el mismo: consultas lentas, se agrega un índice, mejora temporalmente, aparecen nuevos patrones de consulta, se agregan más índices, y eventualmente la performance de escritura colapsa porque cada INSERT actualiza cinco índices distintos. El cache se satura. Los backups empiezan a tomar horas. El RAM “se ve ofensivo”, como lo pone el artículo original.
Conceptos clave: datos HOT vs COLD en tu base de datos
La distinción es simple pero ignorada sistemáticamente:
| Tipo | Características | Frecuencia de acceso | Dónde debería vivir |
|---|---|---|---|
| Hot data | Registros recientes, activos, en uso | Múltiples veces por día | Tabla principal, índices en RAM |
| Warm data | Registros del último año, consultas ocasionales | Semanal o mensual | Tabla principal con partición propia |
| Cold data | Histórico, cumplimiento, auditoría | Rara vez o nunca | Cold storage, tabla de archivo |
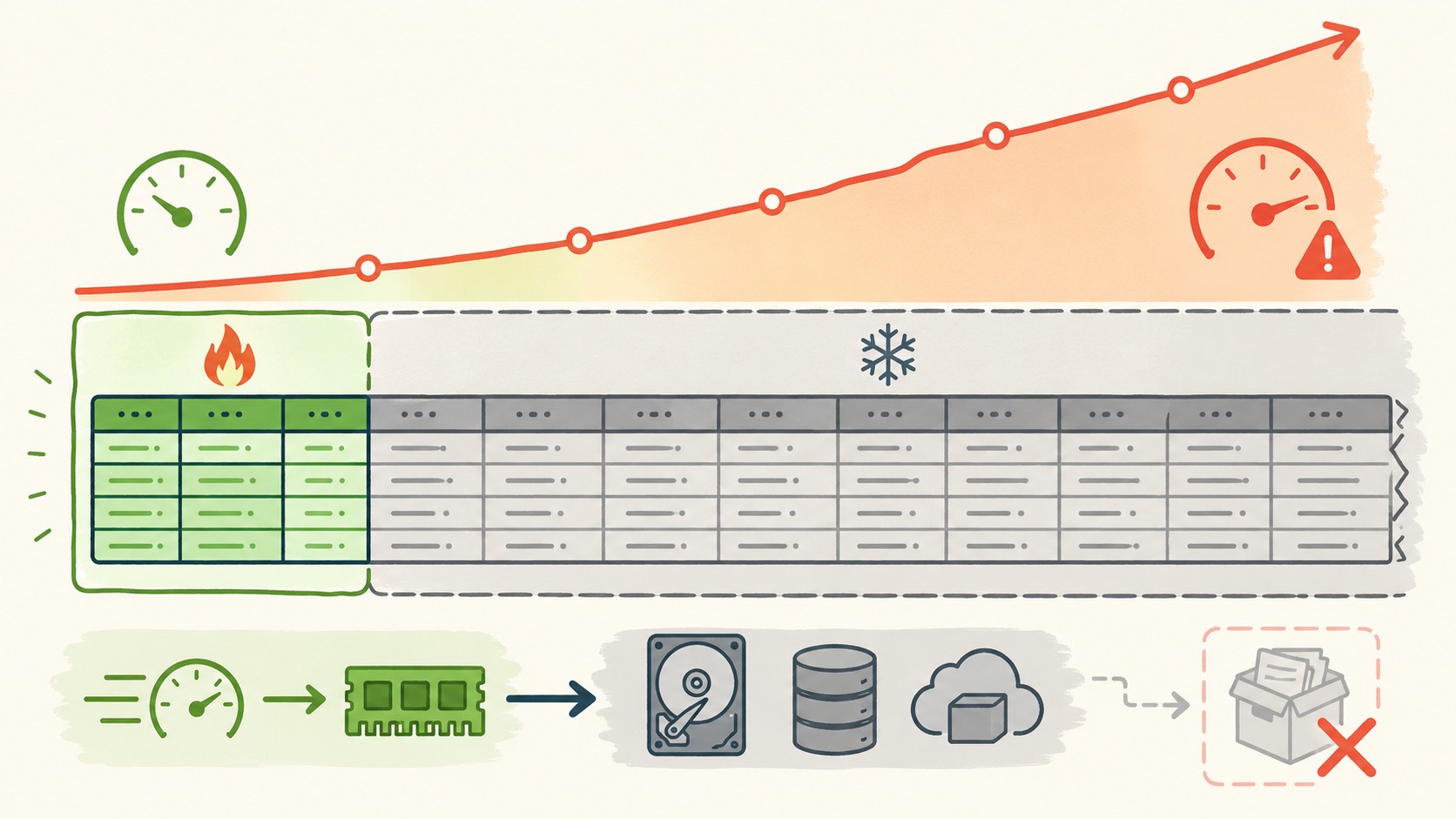
El problema concreto: cuando mezclás cold y hot en la misma tabla, el motor de base de datos no puede optimizar. No sabe que esos 30 millones de registros de 2022 son irrelevantes para el 99% de las queries actuales. Los trata igual.
¿Y cuánto de tu data es realmente cold? En sistemas de producción típicos, entre el 70% y el 85% de los datos nunca se accede después de los primeros 90 días. Estás pagando en RAM, I/O y tiempo de backup por datos que nadie usa. Esto se conecta con lo que analizamos en automatizar deploys sin impactar la BD.
El ciclo de vida de los índices: cómo se vuelven el problema
Tomemos el ejemplo del artículo original. Tenés una tabla de órdenes y agregas:
idx_orders_created_at
Funciona. Las queries por fecha vuelan. La vida es buena, por ahora.
Seis meses después, un desarrollador nuevo agrega queries que filtran por user_id y status. Se agrega otro índice. Después aparece un reporte que filtra por region y created_at. Otro índice compuesto. Un año después tenés 8 índices en esa tabla.
Cada uno de esos índices se actualiza en cada INSERT, UPDATE y DELETE. Con 50 millones de filas, eso significa que una operación de escritura simple termina tocando 8 estructuras de árbol distintas. Las escrituras que antes tardaban 2ms ahora tardan 40ms. (Spoiler: nadie lo midió hasta que el sitio empezó a fallar bajo carga.)
El otro problema: los índices se fragmentan. Microsoft documenta en su guía de SQL Server que la fragmentación superior al 30% empieza a degradar la performance de lectura de forma medible. Un índice fragmentado es peor que no tener índice, porque el motor lo usa igual pero con overhead extra.
Impacto en cascada: RAM, backups y escrituras
Cuando la tabla crece sin separar hot de cold, el impacto no se limita a las queries. Se ramifica en todos lados:
- RAM: El buffer pool del motor intenta cachear las páginas más accedidas. Pero si la tabla tiene 50M registros mezclados, “las más accedidas” incluye páginas con datos de hace 3 años que están cerca (en el árbol B+) de datos recientes. La hit rate del caché cae.
- Backups: Un backup de 200GB que antes tardaba 40 minutos ahora tarda 3 horas. No porque el proceso cambió, sino porque hay 150GB de cold data que se respalda igual.
- Monitoreo: Las alertas de performance se disparan con más frecuencia, los query plans cambian, y el tiempo que el equipo dedica a investigar problemas de performance aumenta semana a semana.
- Writes lentos: Cada INSERT en una tabla con muchos índices y muchas filas es más lento que en una tabla chica y limpia.
El problema de “todo es hot” no es un solo problema. Es cinco problemas simultáneos que se refuerzan entre sí.
Estrategias de solución: archivado y particionamiento
Hay dos caminos principales, y en la mayoría de los casos terminás usando ambos:
Archivado: los datos cold se van, pero no del todo
La idea es mover datos históricos a una tabla o base de datos separada, optimizada para almacenamiento barato y lectura ocasional. No los borrás (compliance, auditoría, lo que sea), pero los sacás del camino del tráfico productivo.
Las estrategias documentadas incluyen archivado a tablas separadas en la misma base, archivado a bases distintas (incluso en otro servidor), y archivado a object storage tipo S3 para datos que se necesitan rarísimo. La elección depende de con qué frecuencia necesitás acceder a esos datos históricos y cuánto tolerás en tiempo de respuesta cuando lo hacés.
Para la mayoría de sistemas OLTP, la regla práctica es: todo lo que no se consultó en los últimos 12 meses es candidato a archivo. Tema relacionado: usar IA para analizar logs de rendimiento.
Particionamiento: dividir la tabla por fecha
El particionamiento no mueve datos a otro lugar, sino que divide la tabla en particiones físicas que el motor puede tratar de forma independiente. Una query a órdenes de mayo de 2026 solo toca la partición de ese mes, sin escanear los registros de 2022.
AWS documenta en su guía de archivado con MySQL cómo combinar particionamiento con archivado: particionás por rango de fechas y después “droppeás” o archivás particiones viejas completas. Es mucho más rápido que hacer DELETE de millones de filas individuales.
Ejemplo básico en MySQL para particionar por año:
PARTITION BY RANGE (YEAR(created_at)) (PARTITION p2023 VALUES LESS THAN (2024), PARTITION p2024 VALUES LESS THAN (2025), PARTITION p2025 VALUES LESS THAN (2026), PARTITION p2026 VALUES LESS THAN (2027), PARTITION pmax VALUES LESS THAN MAXVALUE);
Cómo implementar: identificar qué es cold, partición, archivo
Antes de tocar nada, medí. Específicamente, necesitás saber qué porcentaje de tus datos se accede activamente. Una forma directa:
SELECT COUNT(*) as total, SUM(CASE WHEN created_at >= DATE_SUB(NOW(), INTERVAL 6 MONTH) THEN 1 ELSE 0 END) as hot_last_6m FROM orders;
Si el resultado muestra que el 15% de los registros representan el 100% de las consultas del negocio, el 85% restante es cold.
El proceso típico de migración a particionamiento:
- Crear la tabla nueva con particionamiento definido
- Migrar datos en batches (nunca de golpe, el lock es catastrófico en producción)
- Redirigir el tráfico a la nueva tabla
- Verificar que los query plans usan partition pruning (EXPLAIN muestra qué particiones toca)
- Archiva o droppeá las particiones viejas
Ojo: el particionamiento no es mágico. Si tus queries no incluyen la columna de partición en el WHERE, el motor igual escanea todo. El diseño de particiones tiene que alinearse con cómo consultás los datos. Lo explicamos a fondo en herramientas inteligentes para debugging.
Monitoreo continuo: cómo detectar el problema antes de que explote
El problema de hot data no aparece de un día para el otro. Se acumula durante meses. Las señales tempranas que podés monitorear:
En PostgreSQL, pg_stat_user_indexes muestra los índices por número de scans. Si tenés índices con cero scans en los últimos 30 días, son candidatos a eliminación. En SQL Server, sys.dm_db_index_usage_stats da la misma información. Un índice que no se usa en reads pero que sí se actualiza en writes es puro costo sin beneficio.
Métricas a seguir semanalmente:
- Tamaño de tabla vs hace 30 días (¿está creciendo más rápido de lo esperado?)
- Tiempo promedio de queries frecuentes (tendencia al alza es la señal)
- Buffer hit rate (si cae del 95%, algo raro pasa con el caché)
- Duración de backups (un buen proxy del tamaño real de datos activos)
Si tenés tu base en una VPS o servidor dedicado, el monitoreo de I/O de disco también cuenta: una base que lee datos fríos constantemente genera I/O que podría evitarse. En ese contexto, donweb.com ofrece planes de hosting con acceso completo a métricas de servidor que facilitan este tipo de análisis.
Errores comunes al encarar este problema
Error 1: Agregar más RAM como solución. Más memoria posterga el problema, no lo resuelve. Si tenés 200GB de cold data mezclada con hot data, necesitás 200GB de RAM para cachear todo eficientemente, lo cual es absurdo. La solución es separar los datos, no escalar el hardware.
Error 2: Hacer el archivado con DELETE masivos en producción. Ejecutar DELETE FROM orders WHERE created_at < '2023-01-01' en una tabla de 50 millones de filas genera un lock larguísimo, llena el transaction log y puede tumbar el sistema. Siempre hacé archivado en batches pequeños, fuera de horario pico, o con particionamiento que permite DROP PARTITION (mucho más rápido).
Error 3: Crear particiones sin revisar los query plans. Particionás por fecha y das el trabajo por hecho. Pero si una query frecuente no incluye created_at en el WHERE, el motor escanea todas las particiones igual. Los problemas de performance de bases de datos más comunes incluyen exactamente este tipo de optimización mal aplicada por falta de validación posterior.
¿Y si el problema ya es tan grave que los queries tardan minutos? Exacto, hay que actuar, pero con urgencia quirúrgica. Primero identificá las 3-5 queries más lentas con EXPLAIN, ponele índices específicos para esas queries si no existen, y después encarás el archivado/particionamiento de forma planificada. No hagas los dos pasos a la vez bajo presión.
Esto se conecta directamente con Your Database Is Slow Because Everything Is Hot, donde profundizamos en por qué las bases de datos andan lentas.
Para profundizar en esto, revisá nuestro artículo sobre rendimiento de bases de datos.
Preguntas Frecuentes
¿Por qué mi base de datos es lenta si antes era rápida?
El crecimiento de datos sin estrategia de separación hot/cold es la causa más frecuente. A medida que la tabla crece, los índices se fragmentan, el caché del motor se satura con datos poco usados, y cada operación de escritura actualiza más índices. El sistema no se rompió: simplemente está manejando más datos de los que su diseño original contemplaba. Para más detalles técnicos, mirá diagnosticar problemas más rápidamente.
¿Qué son datos hot y cold en bases de datos?
Datos "hot" son los registros que se acceden con frecuencia, típicamente los más recientes. Datos "cold" son los históricos que rara vez se consultan pero que se mantienen por cumplimiento o auditoría. Mantenerlos mezclados en la misma tabla obliga al motor a tratarlos con el mismo costo de recursos, aunque el 80% de los datos nunca se use en producción.
¿Cómo archivar datos históricos sin afectar el rendimiento actual?
La forma más segura es hacer el archivado en batches pequeños (1.000 a 10.000 registros por vez) fuera de horario pico, moviendo datos a una tabla o base separada. Si la tabla tiene particionamiento por fecha, podés archivar particiones completas con DROP PARTITION o ALTER TABLE... EXCHANGE PARTITION, lo cual es prácticamente instantáneo comparado con DELETE masivos.
¿Cuándo necesito particionar mi base de datos?
Cuando las tablas superan los 10-20 millones de filas y las queries frecuentes siempre filtran por un rango de fechas u otra columna de alta cardinalidad. También cuando los backups empiezan a tomar más de 1-2 horas o cuando el crecimiento proyectado indica que en 12 meses la tabla será 3-5 veces más grande. El particionamiento no es solo para tablas ya grandes: implementarlo antes de alcanzar ese punto es más fácil y menos riesgoso.
¿Los índices siempre mejoran la performance de una base de datos?
No, y esta es una de las confusiones más caras en producción. Los índices aceleran las lecturas pero ralentizan las escrituras, porque cada INSERT/UPDATE/DELETE tiene que actualizar todas las estructuras de índice. Una tabla con 8-10 índices puede tener writes hasta 10 veces más lentos que una bien diseñada con 2-3 índices. Los índices que no se usan en queries son puro costo. Auditarlos con pg_stat_user_indexes o el equivalente de tu motor es una tarea que vale la pena hacer trimestralmente.
Conclusión
El diagnóstico de "claude your database es lenta porque todo es hot" no es nuevo, pero sigue siendo el más ignorado en sistemas en crecimiento. La razón es que el problema se acumula despacio: primero un índice, después otro, después datos que se quedan donde no deben, hasta que en algún momento las queries que tardaban 20ms empiezan a tardar 2 segundos y el equipo entra en modo pánico.
La buena noticia es que el diagnóstico es directo y las herramientas existen. Medí qué porcentaje de tus datos se usa activamente, auditá tus índices para encontrar los que nadie usa, y definí una política de archivado antes de que el problema te explote en la cara. El particionamiento por fecha es casi siempre la primera medida de largo plazo que vale implementar en tablas de eventos, logs, órdenes o cualquier entidad que crezca linealmente con el tiempo.
Dicho esto, ninguna de estas estrategias reemplaza el monitoreo continuo. Un sistema que hoy funciona bien puede estar a seis meses de tener exactamente este problema si no hay nadie mirando las métricas correctas.
Fuentes
- Your Database Is Slow Because Everything Is Hot - Dev.to (2026)
- Reorganizar y recompilar índices - Microsoft SQL Server Docs
- Estrategias de archivo de datos en bases de datos relacionales - AppMaster
- Archivado de tablas MySQL con particionamiento - AWS Prescriptive Guidance
- 5 problemas de performance en bases de datos y cómo resolverlos - LoadView





