Brecha habilidades Kubernetes IA
Un agente de IA te genera una app completa (frontend, base de datos, rutas de API) en menos tiempo del que tardás en preparar un café. Lo subís a producción y todo funciona. Hasta que no funciona. El problema no está en el código que la IA escribió, está en la capa de abajo: Kubernetes. Y ahí la velocidad se frena de golpe. La brecha de habilidades Kubernetes IA es justamente eso: herramientas que producen código a lo loco, pero cero configuración operativa para que ese código sobreviva en producción. Según datos de 2026 (hasta junio 2026), el 82% de los entornos productivos containerizados usan Kubernetes, y el 66% de las organizaciones que hostean modelos de IA generativa también. Sin embargo, la profundidad operativa que pide Kubernetes —scheduling de GPU, autoscaling, manejo de sesiones stateful— no se genera junto con la aplicación.
La brecha de habilidades Kubernetes IA es la distancia entre lo que las herramientas de codificación asistida pueden generar automáticamente y lo que un clúster de Kubernetes exige para funcionar en producción sin romperse. Mientras Cursor, Copilot o Claude te escupen services y deployments en segundos, los objetos que de verdad importan —PodDisruptionBudget, ResourceQuota, LimitRange, tolerations, affinity rules— brillan por su ausencia. Y cuando hay GPUs de por medio, la cosa se pone peor: Kubernetes ni se entera de que un driver falló.
En 30 segundos
- El 82% de los entornos productivos containerizados corre en Kubernetes y el 66% de organizaciones con IA generativa lo usan, pero las herramientas de IA no generan configuraciones operativas reales.
- Las probes estándar de Kubernetes no detectan fallas de GPU: un contenedor puede reportarse “running” mientras el driver tira errores críticos y el modelo entrega output basura.
- Dynamic Resource Allocation (DRA) pasó a GA con Kubernetes 1.34 (lanzado en abril 2026) y es el avance más concreto para scheduling de GPU, aunque no reemplaza la necesidad de saber qué estás haciendo.
- Objetos como PodDisruptionBudget, ResourceQuota o LimitRange no aparecen en el YAML que genera la IA, y su ausencia causa caídas silenciosas en producción.
- Confundir liveness probe con readiness probe es uno de los errores más comunes y peligrosos que cometen equipos que arrancan con Kubernetes para IA.
El hosting es un servicio informático ofrecido por proveedores de alojamiento web, que permite almacenar y servir contenido de un sitio web en servidores siempre conectados a Internet. Su objetivo es garantizar disponibilidad y rendimiento del sitio.
¿Por qué las fallas de GPU no son detectadas por Kubernetes estándar?
Ponele que tenés un clúster corriendo inferencia con GPUs NVIDIA A100. Todo parece andar bien: los pods están en estado Running, las probes de liveness responden OK. Pero el driver de GPU está tirando errores hace veinte minutos y Kubernetes no tiene ni idea. ¿El resultado? Tu modelo de inferencia entrega predicciones corruptas y vos te enterás cuando un usuario reclama.
Esto pasa porque las probes estándar de Kubernetes —liveness y readiness— se diseñaron para cargas basadas en CPU. Chequean si el proceso principal está vivo, no si la GPU está procesando correctamente. Un contenedor puede estar técnicamente “corriendo” mientras la GPU escupe errores por temperatura, memoria corrupta o fallas del driver (sí, en serio). El paper original de Kubernetes no contemplaba GPUs como recurso de primera clase, y aunque hoy las soporta, la capa de health checking sigue siendo ciega a lo que pasa adentro del silicio.
En producción, los equipos que ya pasaron por esto están usando Node Problem Detector para vigilar los logs del driver de GPU y marcar nodos como unhealthy apenas detecta patrones de falla. También suman exporters de métricas a nivel GPU que exponen datos de cómputo y memoria que el monitoreo estándar de Kubernetes jamás capturó. Nada de esto es exótico —se está volviendo práctica estándar— pero tampoco existe por defecto cuando desplegás un contenedor con un simple request de GPU. Lo tenés que armar vos. Esto se conecta con lo que analizamos en nuestra guía de cloud hosting.
¿Qué herramientas existen para monitorear GPUs en Kubernetes en producción?
No hay una sola herramienta que resuelva todo. Lo que funciona en la práctica es una combinación de tres capas, y ninguna viene prendida por default. La buena noticia es que el ecosistema ya maduró lo suficiente como para que no estés improvisando desde cero.
Node Problem Detector (NPD) corre como un DaemonSet en cada nodo del clúster. Vigila los logs del kernel, del kubelet y —acá está lo interesante— los logs del driver de GPU. Cuando detecta un patrón de error conocido, puede taint el nodo automáticamente para que el scheduler deje de mandarle pods. Es bruto pero efectivo. Varios equipos lo combinan con reglas customizadas para GPUs NVIDIA y AMD.
DCGM Exporter (NVIDIA Data Center GPU Manager) expone métricas específicas de la GPU: uso de memoria, temperatura, errores ECC, throttling. Prometheus las scrapea y podés armar alertas sobre datos reales del hardware, no sobre si el proceso de Python sigue corriendo. La diferencia entre monitorear “el pod está vivo” y “la GPU está throttling al 40% por temperatura” es la diferencia entre enterarte del problema en segundos o en horas.
Kubernetes Event-driven Autoscaling (KEDA) no es específico de GPU, pero permite escalar basado en métricas custom —incluyendo las que exponen los exporters de GPU— en vez de depender solo de CPU y memoria. Si tu carga de inferencia se satura, KEDA puede disparar más pods usando datos de cola de requests o utilización real de GPU. ¿La contra? Configurarlo bien lleva su tiempo, y los manifiestos que genera una IA no incluyen ni un ScaledObject.
¿Cuáles son los objetos de API de Kubernetes que las herramientas de IA no generan automáticamente?
Le pedís a cualquier asistente de código que te arme el YAML para desplegar un modelo de inferencia. Te devuelve un Deployment, un Service y quizás un Ingress. Lindo, prolijo, compila. Pero cuando eso llega a producción, te encontrás con que un rollout mal planificado tumba todas las réplicas a la vez, no hay control de cuota de recursos entre namespaces y los pods de inferencia compiten por GPU con el frontend porque nadie configuró affinity rules. Cubrimos ese tema en detalle en solucionar problemas de hosting y dominio.
Estos son los objetos que sistemáticamente quedan afuera del código generado por IA, según la experiencia documentada por equipos que operan Kubernetes en producción:
| Objeto de API | Qué hace | Qué pasa si no está |
|---|---|---|
| PodDisruptionBudget | Limita cuántos pods pueden estar caídos durante un desalojo voluntario | Un drenaje de nodo por mantenimiento tumba todo el servicio de inferencia de golpe |
| ResourceQuota | Fija límites de recursos por namespace | Un equipo consume todas las GPUs disponibles y los demás namespaces se quedan en Pending |
| LimitRange | Define requests y límites por defecto para pods sin especificar | Contenedores sin requests compiten por recursos sin que el scheduler pueda planificar |
| HorizontalPodAutoscaler con métricas custom | Escala basado en uso de GPU o latencia de inferencia | Escalamiento a ciegas por CPU cuando el cuello de botella real es la memoria de GPU |
| Affinity/Tolerations | Asegura que los pods de GPU caigan en nodos con GPU y no en cualquier lado | Pods de inferencia aterrizan en nodos CPU-only y se quedan en Pending eternamente |
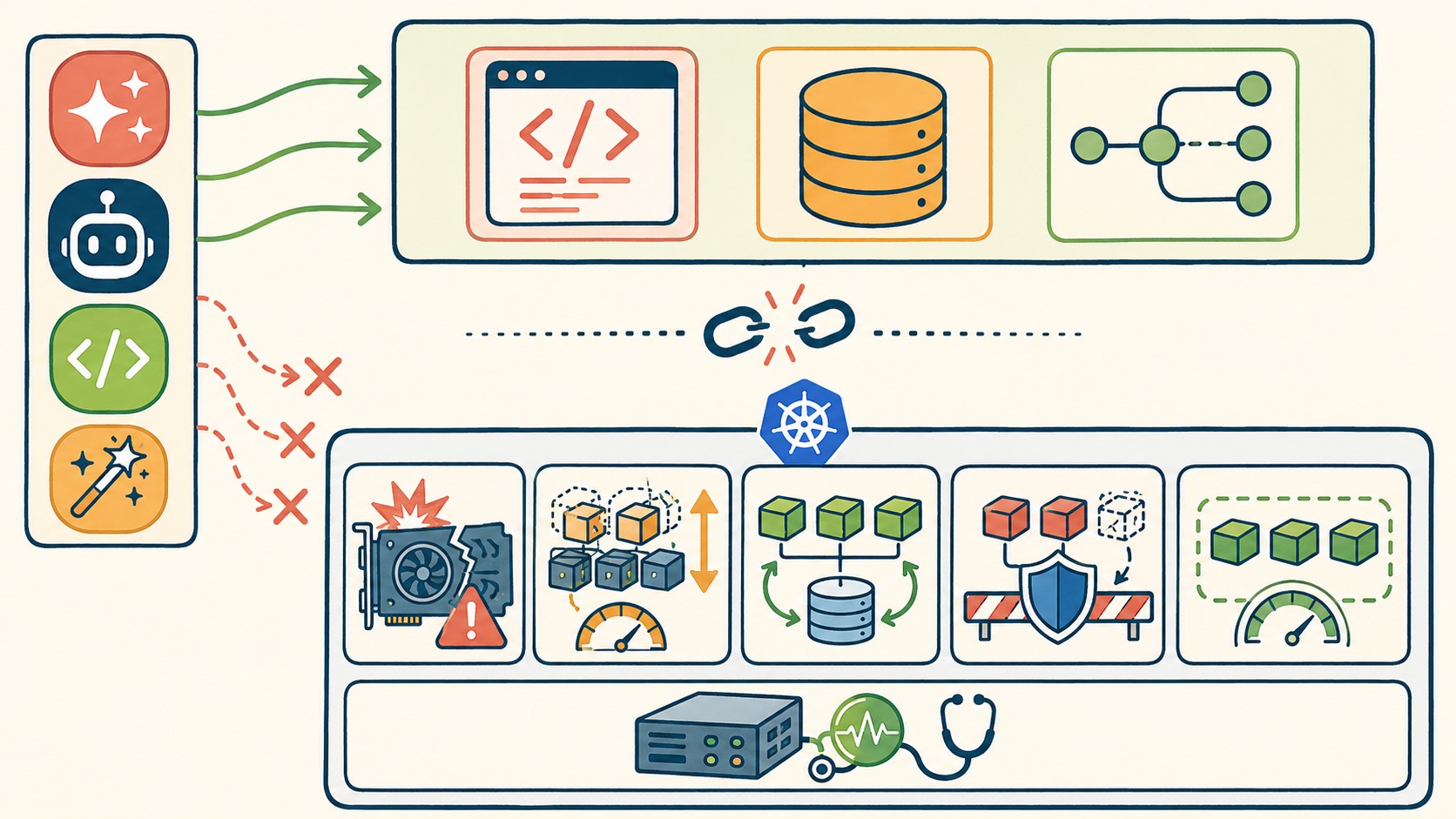
La ausencia de estos objetos no rompe el clúster inmediatamente. Lo va degradando de a poco, con fallas silenciosas que solo se notan cuando el sistema está bajo carga real. Ahí es donde la brecha de habilidades muerde.
¿Qué errores operativos comunes cometen los equipos al usar Kubernetes con IA?
Si alguna vez heredaste un clúster armado por un equipo que venía de Docker Compose, sabés exactamente de lo que hablo. Kubernetes no es un Docker Compose con esteroides, pero muchos equipos lo tratan como si lo fuera. Estos son los errores que veo una y otra vez:
Confundir liveness probe con readiness probe. Es el clásico. La liveness probe le dice a Kubernetes “si fallo, reiniciame”. La readiness probe dice “todavía no estoy listo para recibir tráfico, pero no me mates”. Cuando configurás mal una por la otra, terminás con pods reiniciándose en loop porque la readiness falló (y Kubernetes lo interpretó como crash) o con pods “ready” que reciben tráfico antes de que el modelo de IA haya terminado de cargarse en memoria de GPU. En modelos grandes, eso puede llevar minutos.
No definir requests y sí definir limits. El scheduler de Kubernetes usa los requests para decidir dónde ubicar un pod. Si no los definís, el scheduler trabaja a ciegas y puede meter veinte pods de inferencia en un nodo con dos GPUs. Después los limits —si son muy ajustados— disparan al OOMKiller y matan procesos de entrenamiento que llevaban horas corriendo. Perdés tiempo, plata y cordura. Más contexto en tal como detallamos en la guía de cloud hosting.
Usar Recreate como estrategia de deployment para servicios de inferencia. Recreate mata todos los pods viejos antes de crear los nuevos. En un workload de inferencia que recibe tráfico en vivo, eso implica downtime asegurado. RollingUpdate con maxUnavailable bien configurado es casi siempre la opción correcta, pero muchos equipos copian y pegan el YAML de un tutorial viejo sin revisar la estrategia.
Tratar Kubernetes como si fuera Docker Compose. Esto va más allá de un error puntual: es una mentalidad. En Compose, reiniciar un servicio es trivial y barato. En Kubernetes, reiniciar un pod que forma parte de un deployment grande puede disparar un efecto cascada si no hay PodDisruptionBudget, anti-affinity o presupuesto de recursos. La pregunta no es “¿funciona en local?” sino “¿qué pasa cuando tres nodos se caen al mismo tiempo mientras corre un rollout?”.
¿Qué está cambiando en Kubernetes para mejorar el soporte de cargas de IA?
No todo es queja. Recientemente, Kubernetes movió fichas importantes para cargas de IA generativa. El cambio más relevante es la graduación a GA de Dynamic Resource Allocation (DRA), que reemplaza el modelo rígido de “contar dispositivos” por uno donde los recursos —incluyendo GPUs— se pueden solicitar con parámetros específicos: modelo de GPU, cantidad de memoria, tipo de conectividad entre dispositivos. Antes de DRA, pedir una GPU significaba “dame una GPU, la que haya”. Ahora podés especificar “necesito dos A100 con NVLink”, y el scheduler entiende la diferencia.
También avanzó el autoscaling basado en métricas custom con madurez en KEDA y el metrics server, y mejoraron los sidecar containers nativos (init containers que corren durante toda la vida del pod), útiles para sidecars de monitoreo de GPU que antes requerían trucos con entrypoints custom.
¿Alcanza con esto para decir que Kubernetes es “el sistema operativo de la IA”, como titulan algunos medios en 2026? La verdad es que no. Kubernetes se está adaptando, pero la complejidad operativa no desapareció. Se movió de lugar. Ahora en vez de pelear con el device plugin de GPU, peleás con la configuración de DRA. Sigue habiendo una capa de expertise necesaria que ninguna herramienta de IA va a escribir por vos. Relacionado: al comparar self-hosting con servicios gestionados.
¿Cuándo tiene sentido usar Kubernetes para cargas de IA y cuándo sobra?
Kubernetes no es la respuesta para todo, por más que el ecosistema cloud te lo venda como la navaja suiza definitiva. Para cargas de IA, la decisión de usarlo o no debería basarse en necesidades operativas reales, no en FOMO.
| Factor | Tu plataforma actual probablemente alcanza | Kubernetes se justifica |
|---|---|---|
| Cantidad de servicios | Menos de 5 microservicios independientes | 10+ servicios con ciclos de deploy independientes |
| Scheduling de GPU | Una sola GPU o GPU dedicada a un solo workload | Múltiples workloads compitiendo por GPUs, necesidad de bin packing |
| Multi-tenancy | Un solo equipo, un solo proyecto | Varios equipos compartiendo el mismo parque de GPUs |
| Disponibilidad del equipo | Equipo sin experiencia en Kubernetes ni ganas de aprenderlo | Equipo con al menos una persona que ya operó Kubernetes en producción |
| Escalamiento | Carga estable, predecible, sin picos | Inferencia con picos de demanda, necesidad de scale-to-zero overnight |
Si la mayoría de tus respuestas caen en la columna de la izquierda, probablemente un VPS con GPU dedicada o un servicio managed de inferencia te resuelva mejor. Y si estás en Argentina o la región, opciones como donweb.com tienen soluciones cloud que cubren ese espectro sin la complejidad operativa de armar un clúster desde cero.
¿Qué habilidades operativas de Kubernetes deberían priorizar los equipos de IA?
Armé esta lista pensando en los postmortems reales que vi en equipos que cruzaron el puente de “corre en mi máquina” a “corre en producción con usuarios reales”. No es exhaustiva, pero si tu equipo domina estos siete puntos, ya están mejor parados que el 80% de los que arrancan.
- Requests vs Limits: entendé la diferencia y nunca despliegues a producción sin requests definidos. El scheduler los necesita. Los limits protegen al nodo. No son opcionales.
- Liveness vs Readiness probes: sabé exactamente qué mide cada una y cómo se comporta Kubernetes cuando fallan. Probá escenarios de falla a propósito antes de ir a producción.
- Estrategias de deploy: RollingUpdate no es lo mismo que Recreate. Sabé cuándo usar cada una y qué implica maxUnavailable y maxSurge en un clúster con recursos limitados.
- Comandos de debugging esenciales: kubectl describe pod, kubectl get events, kubectl rollout status, kubectl top. Si tu debugging empieza y termina en kubectl logs, estás en bolas.
- Node affinity y tolerations: tus pods de GPU tienen que caer en nodos con GPU. Parece obvio, pero sin affinity rules el scheduler puede mandarlos a cualquier lado.
- ResourceQuota y LimitRange: si hay más de un equipo en el clúster, configuralos desde el día uno. Arreglar un clúster sin cuotas cuando ya está en producción es un dolor de cabeza.
- Monitoreo de GPU: sumá Node Problem Detector y DCGM Exporter (o equivalentes para AMD) antes de que el primer modelo llegue a producción. Después es tarde.
Preguntas Frecuentes
¿Qué problemas de Kubernetes aparecen al usar IA generativa?
El problema principal es que las herramientas de IA generan código de aplicación y YAML básico, pero no configuran objetos operativos críticos como PodDisruptionBudget, ResourceQuota o affinity rules. Además, las probes estándar de Kubernetes no detectan fallas de GPU, lo que resulta en modelos entregando output corrupto sin que nadie se entere. La velocidad de generación de código no se traduce a velocidad operativa.
¿Cómo manejar fallas silenciosas de GPU en Kubernetes?
La práctica estándar en 2026 es combinar Node Problem Detector para vigilar logs del driver de GPU y taint nodos con fallas, junto con exporters como DCGM Exporter que exponen métricas de hardware (temperatura, errores ECC, throttling) a Prometheus. Estas métricas permiten armar alertas sobre el estado real de la GPU, no solo sobre si el proceso del contenedor sigue corriendo.
¿Qué es Dynamic Resource Allocation en Kubernetes?
Dynamic Resource Allocation (DRA) es una feature de Kubernetes que pasó a GA con Kubernetes 1.34 (lanzado en abril 2026) y permite solicitar recursos como GPUs con parámetros específicos —modelo, cantidad de memoria, conectividad— en vez de simplemente contar dispositivos. Reemplaza el modelo rígido de device plugins con un sistema donde el scheduler puede tomar decisiones basadas en atributos detallados del hardware disponible.
¿Las herramientas de IA pueden generar configuraciones de Kubernetes?
Pueden generar Deployments, Services e Ingress básicos, pero fallan sistemáticamente con los objetos operativos que importan en producción: PodDisruptionBudget, ResourceQuota, LimitRange, HPA con métricas custom, affinity rules y tolerations. Estos objetos requieren decisiones contextuales sobre carga, equipos y recursos que ninguna IA puede inferir solo mirando el código de la aplicación.
¿Qué objetos de Kubernetes son críticos para cargas de IA?
Los cinco objetos que más se extrañan en configuraciones de IA generativa son: PodDisruptionBudget (evita caídas totales durante mantenimiento), ResourceQuota (reparte GPUs entre equipos), LimitRange (fija defaults de requests/limits), HorizontalPodAutoscaler con métricas custom (escala por uso real de GPU), y affinity/tolerations (asegura que los pods de GPU caigan en nodos con GPU).
Conclusión
La brecha de habilidades Kubernetes IA existe porque las herramientas que escriben código no escriben operaciones. Y operar Kubernetes para cargas de IA —con GPUs, inferencia en tiempo real y múltiples equipos— sigue pidiendo expertise humano. Dynamic Resource Allocation y las mejoras de scheduling son avances reales, pero no reemplazan saber qué probe va dónde, cómo se configura un ResourceQuota o por qué tu clúster necesita Node Problem Detector.
Para equipos en Latinoamérica, el desafío es doble: hay menos oferta de talento con experiencia operativa real en Kubernetes, y el costo de las GPUs en cloud pega más fuerte. La decisión inteligente es evaluar si realmente necesitás Kubernetes o si una infraestructura más simple —con cloud local y soporte en español, como la que ofrecen proveedores regionales— te alcanza para lo que estás haciendo. Porque Kubernetes mal configurado no es escalabilidad: es una máquina de generar incidentes a las tres de la mañana.
Fuentes
- 8080.ai – The Kubernetes skills gap AI coding tools don’t talk about — artículo original de junio 2026 con datos sobre fallas de GPU y Dynamic Resource Allocation.
- Juanchi.dev – Lo que las entrevistas de trabajo me enseñaron sobre Kubernetes — matriz de decisión y objetos de API críticos ausentes en configuraciones generadas por IA.
- Blog Sied – Kubernetes y la automatización de recursos — análisis sobre la desconfianza de equipos en ajustes automáticos de CPU y memoria en 2026.
- CloudMagazin – Kubernetes como sistema operativo por defecto de IA — discusión sobre el rol de Kubernetes en cargas de IA generativa en 2026.