Cambiar de modelo IA sin redeploy: guía práctica
Cambiar modelo IA sin redeploy es posible, y en 2026 equipos de todo el mundo lo están haciendo: enviando el 70% del tráfico de sus agentes a DeepSeek R2 editando una variable de entorno. Sin tocar código. Sin bajar el servicio. Sin esperar un deployment pipeline.
En 30 segundos
- Con una capa de abstracción entre el agente y el proveedor LLM, cambiar de modelo es editar un config. Nada más.
- Feature flags y traffic splitting permiten migrar el 10%, el 50% o el 100% del tráfico sin downtime ni redeploy.
- DeepSeek R2 tiene API compatible con OpenAI: cambiar el endpoint y la API key es suficiente para que el agente lo use.
- Si algo falla, el rollback puede hacerse en menos de 5 minutos sin tocar el código base.
- Las herramientas clave del stack: LiteLLM, LaunchDarkly, AI Gateways de Databricks o Cloudflare.
DeepSeek es un modelo de lenguaje desarrollado por DeepSeek, una empresa china de inteligencia artificial, para procesamiento y generación de texto en sistemas de agentes.
¿Por qué el switching dinámico de modelos importa en producción?
Ponele que tu agente está corriendo con GPT-4o y de repente DeepSeek R2 aparece ofreciendo rendimiento comparable a una fracción del costo. ¿Qué hacés? En la mayoría de los equipos, la respuesta clásica era: “abrimos un ticket, coordinamos el deploy, hacemos rollout y rezamos”. Proceso que puede llevar días.
El problema es que cada hora de validación en staging no es lo mismo que validar en producción. Los patrones de uso real, los casos edge, los volúmenes de tokens inesperados: eso solo aparece cuando hay usuarios reales golpeando el sistema. Y si esperás a tener todo validado en staging antes de desplegar, siempre vas a estar un paso atrás.
Hay tres situaciones donde el switching dinámico cobra sentido: cuando querés probar un modelo nuevo sin comprometerte al 100%, cuando el modelo activo empieza a dar errores o latencia alta y necesitás un fallback rápido, o cuando simplemente querés rotar entre proveedores por costo. En los tres casos, la capacidad de cambiar sin redeploy es la diferencia entre un incidente de 30 minutos y uno de 3 horas.
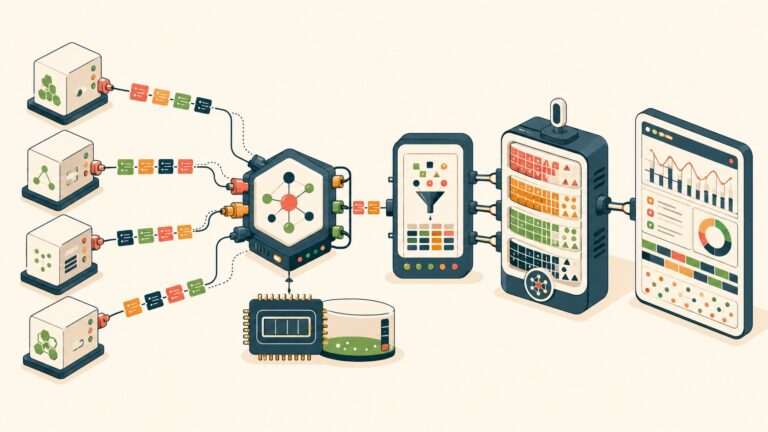
Arquitectura de abstracción: el agente no debería saber con qué modelo habla
Este es el punto de entrada. Si tu agente tiene hardcodeado model="gpt-4o" en el código, cada cambio de modelo requiere un redeploy. Es tan simple como eso.
La arquitectura que permite el switching dinámico tiene tres capas:
- Capa 1 — Lógica del agente: el agente construye el prompt, maneja el contexto, procesa la respuesta. No sabe nada del proveedor.
- Capa 2 — Gateway o capa de abstracción: recibe la request, resuelve qué modelo usar según la configuración activa, y despacha al proveedor correcto. Acá viven las herramientas como LiteLLM, o los AI Gateways de Databricks y Cloudflare.
- Capa 3 — Proveedores LLM: OpenAI, Anthropic, DeepSeek, lo que sea. Intercambiables desde la perspectiva del agente.
Con esta separación, cambiar de modelo es una operación de configuración. El código del agente no se toca. Complementá con estrategia de contenido para múltiples mercados.
Técnica 1: Feature Flags para switch instantáneo
La más simple. El gateway lee una variable: ACTIVE_MODEL=deepseek-r2. Cuando querés cambiar, editás el config (o toggleás un flag en LaunchDarkly o Unleash) y en el próximo request ya está usando el modelo nuevo.
¿Rollback? Cambiás el valor de vuelta. Menos de 2 minutos, sin tocar código, sin pipeline de deploy.
Según la documentación de LaunchDarkly sobre AI deployments, los feature flags para modelos son exactamente el mismo patrón que los feature flags para features de software: podés segmentar por usuario, por tenant, por porcentaje de tráfico. La diferencia es que el “feature” que estás toggleando es qué cerebro usa tu agente.
El setup mínimo es una variable de entorno con el nombre del modelo, leída en el gateway en cada request (no en el startup de la app). Si la lees en startup, todavía necesitás reiniciar para que el cambio tome efecto. Si la lees en runtime, el switch es inmediato.
Técnica 2: Traffic Splitting gradual
Para casos donde querés validar el modelo nuevo antes de mandarlo al 100% del tráfico. El flujo típico:
- 5-10% de requests van al modelo nuevo durante 1-2 horas
- Monitoreás latencia, tasa de error, calidad de respuesta y costo por token
- Si los números están bien: subís a 25%, luego 50%, luego 100%
- Si algo rompe: volvés automáticamente al 0%
Herramientas como el AI Gateway de Databricks tienen este routing built-in con reglas configurables. No necesitás implementar la lógica de splitting vos mismo.
El canary deployment de modelos funciona igual que el canary de software, con una diferencia que hay que tener en cuenta: los modelos pueden degradar calidad de forma sutil sin que los errores HTTP lo detecten. Un modelo que devuelve respuestas con formato incorrecto o razonamiento inconsistente no va a tirar un 500. Por eso el monitoreo tiene que incluir métricas de calidad, no solo de disponibilidad.
Técnica 3: Blue-Green con modelos activos en paralelo
Mantenés dos endpoints activos: Blue (el modelo que está en producción ahora) y Green (el modelo nuevo, recibiendo tráfico de validación). Cuando Green está listo y los números te convencen, el switch es atómico: todo el tráfico pasa de Blue a Green en un segundo. Relacionado: cómo está construido DeepSeek internamente.
Si Green falla después del switch, el rollback es el mismo proceso inverso. Ningún request se pierde porque Blue sigue activo.
Este patrón es más caro en infraestructura (estás pagando por dos endpoints) pero da la garantía más fuerte de rollback instantáneo. Para agentes críticos de negocio, el costo extra del período de validación suele valer la pena.
DeepSeek R2 y la ventaja de las APIs compatibles con OpenAI
Acá viene lo bueno: DeepSeek implementa una API compatible con el formato de OpenAI. Mismo schema de request, mismo formato de response. Según la documentación técnica disponible, cambiar de GPT-4o a DeepSeek R2 requiere dos cambios: la URL base del endpoint y la API key. El código del agente no se modifica.
Esto es lo que hizo posible que equipos migraran el 70% del tráfico sin redeploy: no hubo que reescribir las llamadas API, no hubo que actualizar los parsers de respuesta, no hubo que cambiar el manejo de errores.
El contraste con proveedores no-compatibles es claro. Si quisieras migrar a un modelo con formato propietario, necesitarías adaptar cada llamada, validar cada parser, y actualizar los handlers de errores. Con un proveedor OpenAI-compatible, el cambio es de configuración, no de código.
| Aspecto | Migración a API compatible | Migración a API no-compatible |
|---|---|---|
| Cambios en código | Ninguno | Reescritura de llamadas API |
| Riesgo de regresión | Bajo | Alto |
| Tiempo de migración | Minutos (config) | Días-semanas (desarrollo) |
| Rollback | Instantáneo | Requiere redeploy |
| Testing requerido | Comportamiento del modelo | Comportamiento del modelo + integración |

Monitoreo durante el switching: qué alertas activar
Cambiar de modelo sin monitoreo es como hacer un deploy a ciegas. Los umbrales que hay que tener configurados antes de cualquier switching de modelos en producción:
- Latencia p99: si sube más del 20% respecto al baseline del modelo anterior, es señal de problema
- Tasa de error: cualquier cosa por encima del 1% de error rate en requests al modelo nuevo merece revisión inmediata
- Costo por token: si el modelo nuevo resulta más caro de lo esperado (por mayor usage de tokens), lo vas a ver rápido en las métricas de costo
- Calidad de respuesta: si tenés un evaluador automático o un LLM-as-judge, corre comparaciones entre el modelo viejo y el nuevo en las primeras horas
Herramientas como Datadog o New Relic tienen dashboards para este tipo de métricas. Lo importante es no hacer el switch y asumir que todo está bien. El monitoreo activo en las primeras 2 horas post-switch es lo que separa una migración prolija de un incidente que se detecta tarde. Te puede servir nuestra cobertura de infraestructura de hosting para aplicaciones de IA.
Rollback rápido: el plan B que tenés que tener antes de empezar
Regla: antes de hacer cualquier switching, definí exactamente cómo vas a revertir si algo sale mal. No en el momento del incidente. Antes.
Con feature flags: editar el valor de la variable y en el próximo request ya está resuelto. Con blue-green: redirigir el tráfico de vuelta a Blue. Con traffic split: bajar el porcentaje del modelo nuevo a 0%.
¿Y qué no funciona como rollback? Un git revert + redeploy manual. Si tardás 15 minutos en hacer un rollback, el switching dinámico no te compró nada. La velocidad de reversión es parte del diseño del sistema, no un detalle de implementación.
El objetivo es que cualquier persona del equipo pueda hacer el rollback en menos de 5 minutos, a las 3 de la mañana, con los ojos cerrados. Si no podés garantizar eso, el sistema no está listo para hacer switching de modelos en producción.
Errores comunes al implementar model switching
Leer la variable de entorno en el startup, no en runtime
Si el gateway lee ACTIVE_MODEL cuando arranca la aplicación, cambiar la variable no tiene efecto hasta el próximo reinicio. El switch “sin redeploy” termina requiriendo un reinicio del proceso. La solución es leer la configuración del modelo en cada request, o usar un config store con hot-reload (etcd, Consul, o simplemente una tabla en la DB con TTL de 30 segundos).
No validar la calidad de respuesta, solo la disponibilidad
Un modelo puede estar respondiendo HTTP 200 y estar dando respuestas con formato incorrecto, razonamiento inconsistente o alucinaciones en tipos de queries específicos. Si tu monitoreo solo mide uptime y latencia, no vas a detectar este problema hasta que un usuario lo reporte. Sumá evaluadores automáticos o al menos logueo estructurado de respuestas para poder revisar muestras. Sobre eso hablamos en implementación de IA en fintech.
Asumir que “compatible con OpenAI” significa idéntico
La compatibilidad de API no garantiza comportamiento idéntico. Un modelo puede procesar el mismo prompt de maneras muy distintas: diferente nivel de literalidad en las instrucciones, diferente manejo de contexto largo, diferentes formatos de output cuando el prompt no es completamente explícito. Antes de mandar el 100% del tráfico, hacé una comparación de respuestas en un sample representativo de queries reales de producción.
Si te interesa, desarrollamos esto en Switched 70% of our agent traffic to DeepSeek R2 without a r.
Qué está confirmado / Qué no
Confirmado
- DeepSeek R2 implementa API compatible con el formato de OpenAI (endpoint + API key es todo lo que cambia)
- LiteLLM permite enrutar a múltiples proveedores desde una sola interfaz, con switching por config
- AI Gateways de Databricks tienen traffic splitting y routing rules configurables sin redeploy
- LaunchDarkly soporta feature flags para selección de modelos con rollout por porcentaje
Lo que habría que verificar antes de implementar
- Los benchmarks de rendimiento de DeepSeek R2 publicados son del propio equipo de DeepSeek. Validación independiente en tus casos de uso específicos es necesaria antes de migrar tráfico crítico
- Los costos exactos de R2 en escenarios de alto volumen dependen del mix de tokens de input/output de tu aplicación específica
- La latencia en regiones fuera de Asia puede variar según el proveedor de infraestructura que uses para acceder a la API
Preguntas Frecuentes
¿Cómo cambiar de modelo IA en producción sin redeploy?
Usando una capa de abstracción entre el agente y el proveedor LLM. El agente llama al gateway, el gateway lee una variable de configuración para saber qué modelo usar, y despacha al proveedor. Cambiar el modelo es cambiar esa variable en runtime. LiteLLM es la herramienta más usada para implementar este patrón en Python.
¿Es posible migrar tráfico a DeepSeek R2 sin downtime?
Sí, porque DeepSeek R2 tiene una API compatible con el formato de OpenAI. Con un gateway configurado para traffic splitting, podés empezar enviando el 5-10% de los requests a R2 y subir gradualmente. Si algo falla, el rollback es bajar el porcentaje de vuelta a 0% sin tocar código ni reiniciar servicios.
¿Qué herramientas permiten cambiar modelos dinámicamente?
LiteLLM es la más popular para Python, con soporte para más de 100 proveedores desde una interfaz unificada. Para feature flags con rollout por porcentaje, LaunchDarkly y Unleash son las opciones más maduras. Para AI Gateways con governance y observabilidad, Databricks y Cloudflare tienen productos específicos para este caso de uso.
¿Cómo implementar feature flags para switching de modelos?
La implementación mínima es leer el nombre del modelo desde una variable de entorno o config store en cada request (no en el startup de la app). Para control más granular, una plataforma de feature flags permite segmentar por tenant, usuario, o porcentaje de tráfico, y hacer rollback desde una UI sin tocar el servidor.
¿Cuál es la mejor práctica para rotar entre LLMs en agentes?
Separar la lógica del agente de la selección del modelo es el punto de partida. A partir de ahí, la mejor práctica es hacer rollouts graduales (canary deployments), con monitoreo de latencia, calidad y costo antes de subir el porcentaje. Siempre tener un rollback definido y probado antes de hacer el primer switch en producción.
Conclusión
El switching dinámico de modelos dejó de ser una técnica avanzada para ser una práctica operacional básica en equipos que corren agentes en producción. La combinación de APIs compatibles con OpenAI (como la de DeepSeek R2), gateways de abstracción y feature flags hace que cambiar el modelo sea una operación de minutos, no de días.
Lo que cambió en 2026 es que las herramientas llegaron a un punto de madurez donde implementar este stack no requiere infraestructura propia: LiteLLM, un config store y un sistema de feature flags básico alcanza para la mayoría de los casos. Si tu agente todavía tiene el modelo hardcodeado en el código, ese es el primer problema a resolver, independientemente de si estás pensando en migrar a DeepSeek o no. La flexibilidad para cambiar vale aunque hoy no la necesités.