Deploy rápido: el costo real en deuda técnica
Cada vez que un equipo elige velocidad sobre calidad en un deploy, acumula deuda técnica que después paga con intereses: bugs nocturnos, burnout, y sprints enteros dedicados a apagar incendios en vez de construir. El ciclo es conocido, predecible, y sigue ocurriendo igual.
En 30 segundos
- El deploy rápido y la deuda técnica están directamente relacionados: cada atajo técnico tomado bajo presión se convierte en horas de trabajo no planificado después.
- Los desarrolladores pierden casi un día a la semana resolviendo deuda técnica acumulada, según datos de Atlassian.
- Estrategias como Blue/Green, Canary y Rolling Updates tienen trade-offs reales: no hay una bala de plata, hay contexto.
- La deuda técnica no es solo un problema técnico: genera estrés, burnout y rotación de personal.
- CI/CD bien implementado no acelera el deploy; es una compuerta de calidad que evita que los problemas lleguen a producción.
Stability AI es una empresa de inteligencia artificial que desarrolla modelos de generación de imágenes, siendo responsable de Stable Diffusion, un modelo de difusión de texto a imagen de código abierto.
La ilusión del despliegue rápido: más allá de la automatización
La deuda técnica es el costo diferido de las decisiones apresuradas: código que funciona hoy pero que va a requerir reescritura, refactoring, o arreglos costosos mañana. En el contexto de deploys acelerados, esa deuda se acumula en forma de pruebas salteadas, documentación postergada, y configuraciones que “funcionaron en el ambiente de dev”.
Automatizar un git pull y un docker-compose up no es hacer deploy seguro. Es hacer deploy rápido. Hay una diferencia enorme entre los dos, y durante años muchos equipos la confundieron. Según la experiencia documentada de equipos con más de 20 años en campo, los enfoques simples funcionan en proyectos chicos o durante la fase MVP, pero en sistemas empresariales o críticos terminan generando problemas de escala mayor.
El ejemplo clásico: un equipo despliega una actualización de API bajo presión. El script corre sin errores. El servicio no levanta. El problema estaba en un archivo de configuración de systemd que nadie revisó porque “el deploy siempre funcionó así”. Resultado: hora y media de downtime, un postmortem incómodo, y la deuda técnica de “hay que revisar las configs antes de deployar” que queda pendiente para el sprint siguiente (spoiler: nunca llega al sprint siguiente).
Deuda técnica: cómo el atajo de hoy se convierte en el problema de mañana
Ponele que tu equipo está desarrollando un ERP para una empresa de manufactura. Llega la presión de management: hay una funcionalidad que tiene que estar en producción esta semana. El equipo entra en modo “que salga ya”. Se saltean algunos tests de integración, la documentación queda “para después”, y las queries a la base de datos se escriben rápido, sin optimización.
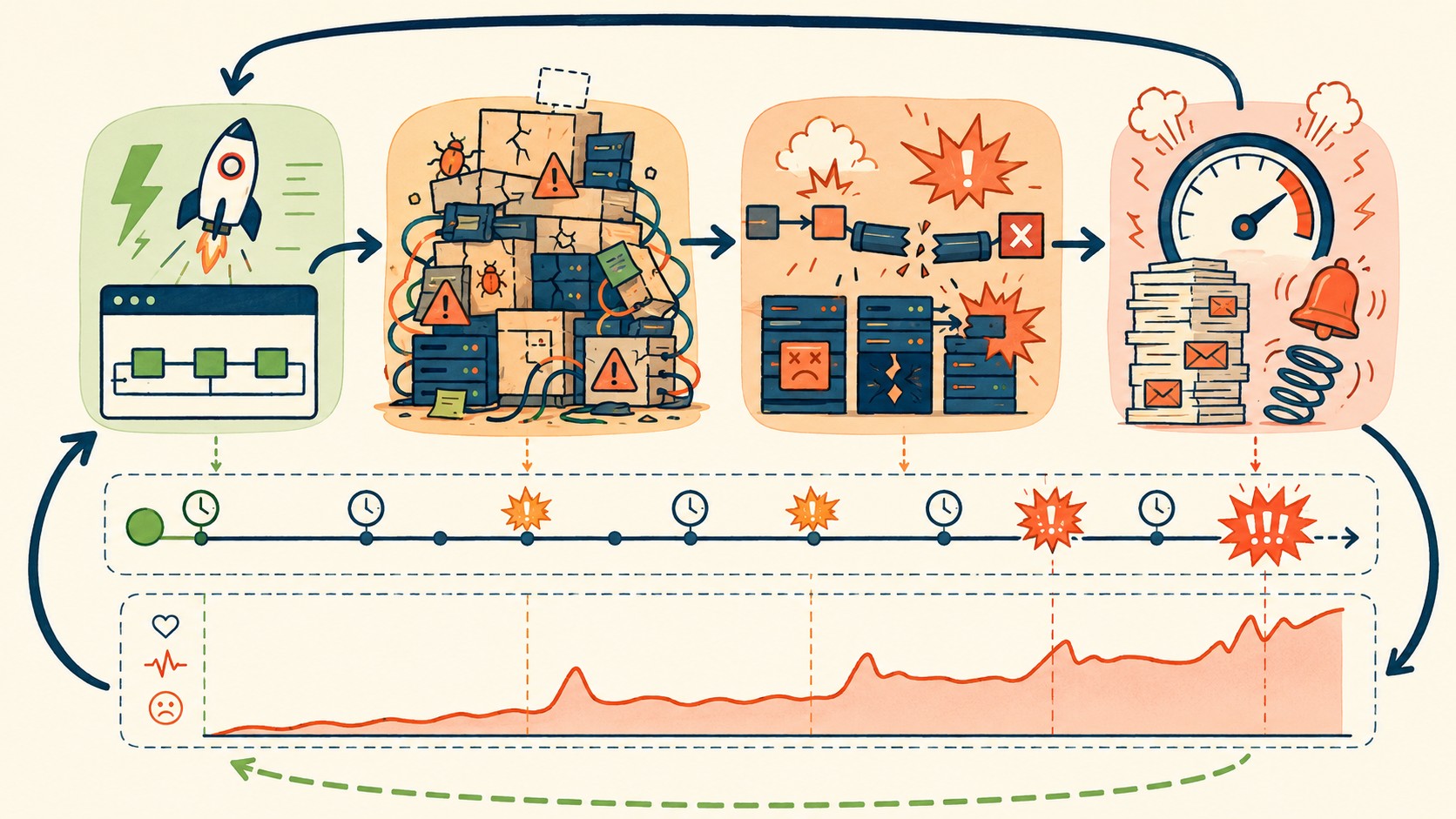
Durante las primeras semanas, todo parece funcionar. Después, a medida que crece el volumen de datos, esas queries sin optimizar empiezan a generar consultas N+1. Cada registro activa una nueva query a la base. El connection pool se agota. Y a las 03:14 AM suena la alarma. Alguien del equipo se despierta, entra al servidor, y pasa dos horas entendiendo qué pasó. Ese es el costo real del deploy rápido: no se paga en el momento, se paga con intereses.
Atlassian estima que los desarrolladores pierden casi un día a la semana resolviendo deuda técnica acumulada. No es una cifra menor: en un equipo de cinco personas, eso equivale a un developer de tiempo completo dedicado exclusivamente a apagar incendios.
Estrés del equipo: la consecuencia silenciosa de la deuda acumulada
Acá viene la parte que menos se habla en las retrospectivas: el impacto humano.
Cuando un equipo pasa más tiempo en firefighting que en features nuevas, la moral se erosiona rápido. Los developers buenos, los que tienen opciones en el mercado, se van primero. Los que quedan se quedan porque no tienen adónde ir, o porque son los únicos que entienden el sistema legado (lo que crea una dependencia perversa). Según análisis de patrones de delivery en equipos de producto, la deuda técnica aparece primero como estrés de entrega: los sprints se extienden, las estimaciones fallan, y los desarrolladores entran en un ciclo donde cada tarea nueva trae tres problemas viejos sin resolver.
El burnout no viene de trabajar mucho. Viene de trabajar mucho sin ver progreso real. Hay una diferencia entre estar ocupado construyendo algo nuevo y estar ocupado parcheando lo viejo que se rompe. El primero da satisfacción. El segundo, después de un tiempo, solo da agotamiento. Te puede servir nuestra cobertura de elegir herramientas de integración continua.
Estrategias de despliegue seguro: Blue/Green, Canary y Rolling Updates
No existe la estrategia perfecta de deploy. Existe la estrategia adecuada para tu contexto, tu infraestructura, y tu tolerancia al riesgo. Estas son las tres principales con sus trade-offs reales:
| Estrategia | Ventaja principal | Desventaja principal | Cuándo usarla |
|---|---|---|---|
| Blue/Green | Zero-downtime, rollback instantáneo | Costo alto (doble infraestructura) | Sistemas críticos, alta disponibilidad requerida |
| Canary | Detección temprana de problemas en producción real | Enrutamiento complejo, exposición parcial a bugs | Cambios grandes con riesgo incierto |
| Rolling Updates | Eficiente en recursos, sin infraestructura adicional | Riesgo de incompatibilidad entre versiones simultáneas | Servicios stateless con buena cobertura de tests |
Blue/Green es la opción con más confort operativo: tenés dos ambientes idénticos, el nuevo recibe tráfico solo cuando estás seguro, y si algo falla el rollback es cambiar un switch de red. El problema es el costo: en infraestructura cloud, tener dos entornos corriendo en paralelo puede duplicar la factura. Para sistemas donde el uptime tiene valor de negocio directo (ecommerce, finanzas, salud), ese costo se justifica solo. Para una app interna de recursos humanos, probablemente no.
Canary es más quirúrgico: mandás un porcentaje pequeño del tráfico real al nuevo código, monitoreás métricas, y si todo va bien expandís gradualmente. La detección temprana es genuina (estás probando con usuarios reales, no simulaciones), pero el enrutamiento se complica y tenés que tener muy claro qué métricas te indican que algo anda mal antes de expandir. ¿Alguien definió esos criterios por escrito antes del deploy? Exacto, en la mayoría de los casos no.
Rolling Updates es la más usada porque es la más eficiente en recursos: vas reemplazando instancias viejas con nuevas de a poco. El riesgo es que durante la transición tenés dos versiones del mismo servicio corriendo al mismo tiempo, lo que puede generar problemas de compatibilidad de esquema de base de datos o de comportamiento de API si no se planificó bien.
Automatización y observabilidad: las defensas contra el caos
CI/CD implementado mal es solo automatización de deploys rápidos. CI/CD bien implementado es una compuerta de calidad.
La diferencia está en qué corre la pipeline antes de que el código llegue a producción. Tests unitarios e integración son el piso mínimo. Encima de eso: análisis estático, cobertura de código, smoke tests en el ambiente de staging, verificación de migraciones de base de datos. Cada paso que se saltea en la pipeline es deuda técnica en potencia. En diseñar arquitecturas escalables y mantenibles profundizamos sobre esto.
La observabilidad es la otra mitad de la ecuación. Podés deployar con todas las estrategias correctas y aún así no enterarte de que algo falló hasta que el cliente llama. Métricas, logs estructurados, y trazas distribuidas no son lujos: son la diferencia entre enterarte de un problema en minutos y enterarte a las 03:14 AM cuando ya es un incidente crítico.
Un ejemplo concreto de configuración defensiva: en servicios que corren bajo systemd, definir límites de cgroup como MemoryHigh=500M y MemoryMax=1G evita que un memory leak en un servicio mate al servidor completo. No es glamoroso, no sale en los blogs de “arquitectura moderna”, pero te ahorra un incidente de producción. Ese tipo de configuración es la que se saltea cuando hay presión para deployar rápido.
Migraciones de base de datos: el punto crítico en deploys seguros
Si hay un momento donde los deploys rápidos generan los problemas más difíciles de resolver, es en las migraciones de esquema.
Querés agregar una columna NOT NULL a una tabla con 50 millones de registros. En PostgreSQL, eso puede implicar un lock que bloquea escrituras por varios segundos o minutos dependiendo del tamaño de la tabla. Si no lo planificaste, tu deploy “rápido” acaba de bajar la aplicación en producción mientras la base de datos procesa la migración.
Las estrategias que funcionan son las aditivas: primero agregás la columna como nullable, desplegás el código que la escribe, esperás que todos los registros existentes se actualicen, y solo entonces agregás el constraint NOT NULL. Es más lento, requiere más deploys coordinados, pero no produce downtime. Herramientas como Flyway o Liquibase para versionar las migraciones hacen que este proceso sea trazable y reversible.
Dual-write (escribir en el esquema viejo y el nuevo simultáneamente durante la transición) es otra táctica útil cuando estás haciendo cambios grandes de esquema que tienen que ser compatibles hacia atrás. El código es más complejo por un período acotado, pero el riesgo de producción es mucho menor. Cubrimos ese tema en detalle en reducir dependencias externas en deployments.
Cultura de equipo y responsabilidad compartida: “you build it, you run it”
El principio “you build it, you run it”, popularizado por Amazon, cambia la dinámica de incentivos: el equipo que construye el feature es el mismo que se despierta a las 3 AM cuando falla. Eso no es sadismo organizacional, es alineación de incentivos. Cuando el developer que tomó el atajo técnico es el mismo que recibe el pager a la madrugada, la próxima vez piensa dos veces antes de saltear los tests.
Los SLOs (Service Level Objectives) y los error budgets son herramientas concretas para esto. Un error budget define cuánto downtime o degradación acepta el sistema en un período. Si el equipo se acercó al límite, no puede deployar features nuevas hasta que estabilice lo existente. Es una política que prioriza la confiabilidad sin que nadie tenga que pelear en una reunión.
Lo que conecta todo esto es la cultura de aprendizaje sin culpa asignada. Los postmortems que terminan en “X fue el responsable” no mejoran los sistemas, solo generan que la gente oculte información la próxima vez. Los postmortems que terminan en “el sistema tenía estas vulnerabilidades y así las corregimos” sí generan mejoras reales. Si en tu equipo la gente tiene miedo de reportar problemas, la deuda técnica va a seguir acumulándose en silencio hasta que sea imposible de ignorar.
Errores comunes al gestionar deploy rápido y deuda técnica
Error 1: Confundir automatización con seguridad. Tener una pipeline de CI/CD no significa que los deploys son seguros. Significa que son automáticos. La seguridad viene de qué verificaciones corre esa pipeline antes de deployar. Si la pipeline solo ejecuta el deploy sin correr tests, es automatización del caos.
Error 2: Tratar la deuda técnica como un problema “para después”. La deuda técnica no desaparece sola. Se acumula, y los intereses son exponenciales: un problema chico hoy puede convertirse en una refactorización de tres meses en dos años. Registrarla en el backlog no alcanza si nunca entra a los sprints.
Error 3: Hacer rollback sin entender la causa. Cuando algo falla en producción, el instinto es hacer rollback inmediato. A veces es lo correcto. Pero si hacés rollback sin entender qué falló y por qué, vas a volver a deployar el mismo problema la semana siguiente. El rollback compra tiempo; no resuelve el problema. Relacionado: evaluar seguridad en tu infraestructura.
Esto se conecta con Fast Deploy Decisions: Team Stress and the Edge of Debt Accu, donde cubrimos el tema en detalle.
Esto se conecta con Fast Deploy Decisions: Team Stress and the Edge of Debt Accu, donde le damos más vuelta al tema.
Esto se conecta con Fast Deploy Decisions: Team Stress and the Edge of Debt Accu, donde cubrimos el tema en detalle.
Preguntas Frecuentes
¿Cuál es el impacto real del deploy rápido en la deuda técnica?
Cada atajo técnico tomado bajo presión de tiempo, como saltear tests o posponer documentación, genera deuda que se paga después con trabajo no planificado. Atlassian estima que los equipos pierden casi un día de trabajo semanal resolviendo deuda acumulada. A escala de equipo, ese costo supera largamente el tiempo “ahorrado” en el deploy original.
¿Cómo afecta el despliegue acelerado al estrés del equipo?
La deuda técnica genera firefighting constante: los desarrolladores pasan tiempo arreglando problemas en vez de construir funcionalidades. Ese ciclo erosiona la moral, produce burnout, y aumenta la rotación del equipo. Los perfiles más calificados son también los primeros en irse cuando el trabajo se convierte principalmente en parchar sistemas.
¿Cuál es la diferencia entre Blue/Green y Canary deployment?
Blue/Green mantiene dos ambientes idénticos: el nuevo recibe tráfico solo cuando está verificado, y el rollback es inmediato. Canary envía un porcentaje pequeño del tráfico real al nuevo código y lo expande gradualmente si las métricas son correctas. Blue/Green es más costoso en infraestructura; Canary es más eficiente pero requiere una estrategia de enrutamiento más compleja y criterios de éxito definidos de antemano.
¿Qué estrategias evitan la acumulación de deuda técnica en equipos ágiles?
Las más efectivas son: incluir la reducción de deuda técnica como ítems explícitos en el backlog (no como trabajo “extra”), usar CI/CD como compuerta de calidad con tests obligatorios antes de cada deploy, implementar SLOs y error budgets para no priorizar features cuando el sistema está inestable, y hacer postmortems sin asignación de culpa para que los problemas se reporten en vez de ocultarse.
¿Cómo balancear velocidad y calidad en los despliegues sin frenar al equipo?
El balance no está en elegir entre velocidad y calidad, sino en definir estándares mínimos no negociables antes de deployar: cobertura de tests mínima, verificación de migraciones, smoke tests en staging. Lo que va más allá de ese mínimo puede tener flexibilidad según el contexto. Equipos que implementan estos estándares base reportan menos incidentes de producción y, en consecuencia, más tiempo disponible para nuevas funcionalidades.
Conclusión
El deploy rápido y la deuda técnica no son opuestos inevitables: son el resultado de cómo un equipo toma decisiones bajo presión. La presión de management para “salir rápido” no va a desaparecer, y no tiene que desaparecer, pero sí tiene que encontrar un límite en estándares técnicos no negociables.
Si tu equipo está pasando más tiempo en firefighting que en desarrollo, si los sprints se extienden consistentemente, si nadie sabe bien qué hace exactamente el módulo que escribieron hace seis meses, esos son síntomas de deuda técnica acumulada que va a cobrar cada vez más caro. El momento de actuar no es cuando el sistema colapsa, sino cuando empezás a ver esas señales.
Para equipos que manejan infraestructura propia o en cloud, tener una base sólida de hosting con soporte técnico real marca la diferencia en estos momentos críticos. donweb.com ofrece infraestructura cloud pensada para equipos de desarrollo que necesitan confiabilidad sin gestionar todo desde cero.
La decisión de deployar rápido o bien rara vez es técnica. Es cultural. Y esa es la parte más difícil de cambiar.