Despliegue automático con OPA: cero drift de config
Un motor de despliegue policy-driven es un sistema que genera infraestructura dinámicamente desde un manifiesto central, valida políticas de seguridad antes de ejecutar cualquier cambio, y se auto-repara cuando detecta desviaciones. SwiftDeploy, publicado en mayo de 2026, es un ejemplo concreto: un CLI que usa Open Policy Agent para bloquear despliegues no conformes antes de que un solo contenedor arranque.
En 30 segundos
- SwiftDeploy genera
docker-compose.ymlynginx.confautomáticamente desde unmanifest.yamlusandoyqyenvsubst, eliminando el drift de configuración. - Open Policy Agent actúa como guardia pre-despliegue: si una política falla, el deploy no arranca.
- El lenguaje Rego permite escribir reglas declarativas como “ningún contenedor puede correr como root” y aplicarlas antes de cada ejecución.
- El enfoque “Infrastructure as Logic” trata la infraestructura como output compilado, no como archivos YAML editados a mano.
- La tendencia para 2026 apunta a pipelines que se validan solos antes de llegar a producción, reduciendo incidentes por configuración incorrecta.
El problema real del despliegue automático DevOps con configuración estática
Ponele que tenés tres ambientes: dev, staging y producción. El docker-compose.yml de dev lo editaste el martes, el de staging lo tocó un compañero el jueves, y el de producción… bueno, nadie recuerda exactamente cuándo fue la última vez que alguien lo revisó. Eso es drift de configuración, y es la causa número uno de los “en mi local funciona” que todos conocemos de sobra.
La infraestructura estática basada en YAML tiene un problema estructural: los archivos viven separados del código que describen. Con el tiempo, divergen. Un servicio cambia de puerto, alguien actualiza una imagen base, se agrega una variable de entorno nueva, y el YAML queda viejo. El sistema sigue corriendo hasta que no.
¿Y qué pasa cuando eso rompe en producción a las 3 de la mañana? Exacto: alguien tiene que revisar manualmente qué cambió, dónde y cuándo.
Infrastructure as Logic: tratar la infraestructura como código compilado
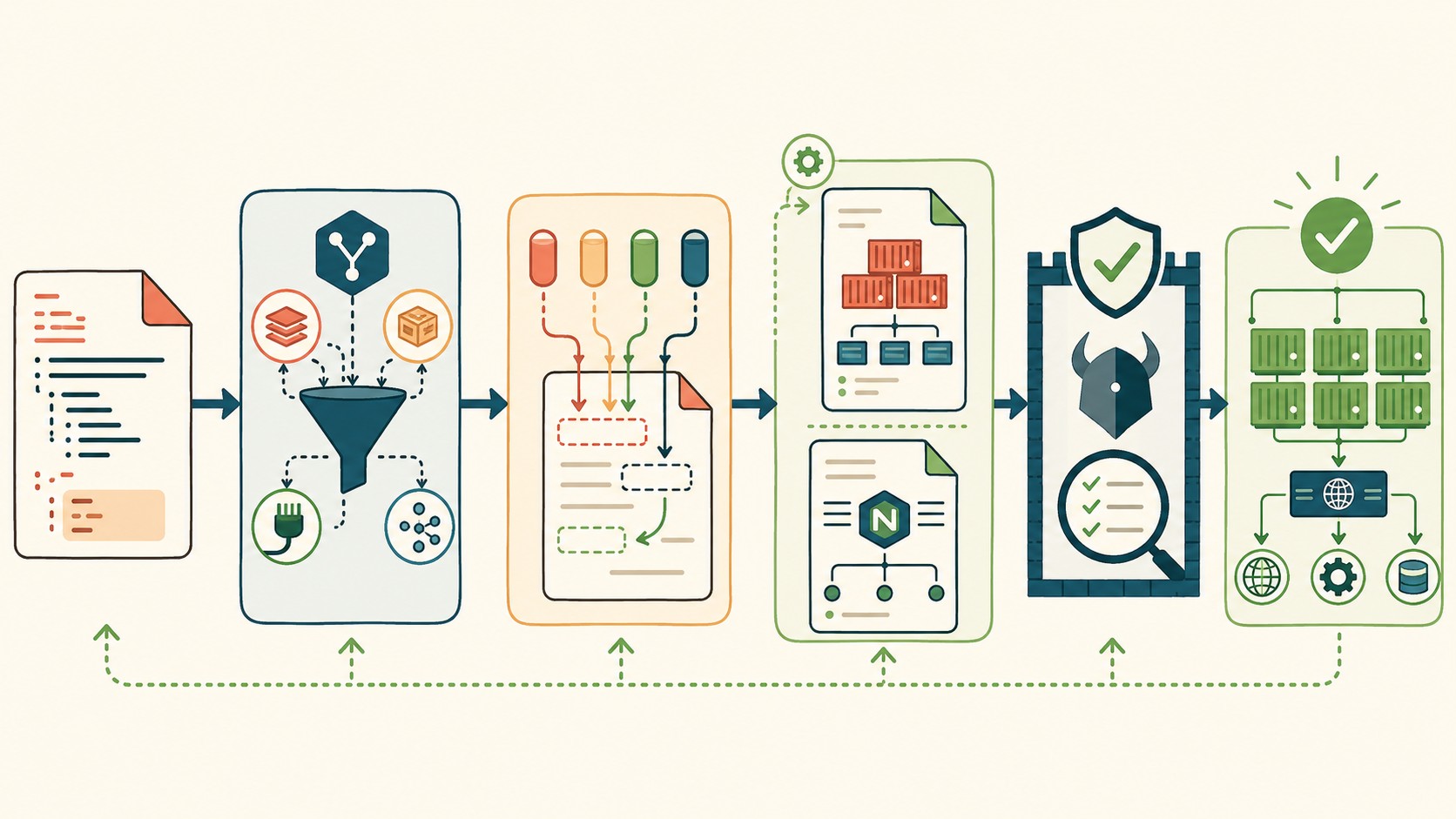
La propuesta de SwiftDeploy, publicada el 6 de mayo de 2026, es conceptualmente simple aunque técnicamente sólida: el manifest.yaml es la única fuente de verdad. Todo lo demás se genera.
Cuando ejecutás ./swiftdeploy init, el CLI hace lo siguiente:
- Parsea las definiciones de servicios (imágenes, puertos, variables de entorno) usando
yq. - Inyecta esas variables en archivos
.templateconenvsubst. - Genera un
docker-compose.ymly unnginx.confa medida, en el momento.
El resultado: si el manifest cambia, la infraestructura se regenera para que coincida. No hay forma de que el archivo de configuración diga una cosa y el servicio haga otra (al menos no por drift). Eso es lo que el proyecto llama “clinical environment” — un entorno donde todo es predecible porque todo sale del mismo origen. Para más detalles técnicos, mirá estrategia SEO para despliegues globales.
Lo interesante es que este patrón no es nuevo en concepto (Terraform y Pulumi hacen algo parecido a mayor escala), pero SwiftDeploy lo aplica en el nivel de contenedores locales y staging con herramientas de shell accesibles. No necesitás un stack de infraestructura enterprise para tener este grado de control.
Open Policy Agent: el guardia que para el deploy antes de que arranque
OPA es un motor de políticas open source que, en el contexto de SwiftDeploy, hace de “junta médica” antes de cada despliegue. Si algo no cumple las reglas, el proceso se corta ahí. Ningún contenedor levanta.
Las políticas se escriben en Rego, el lenguaje declarativo de OPA. La lógica es diferente a lo que estás acostumbrado si venís de Python o Bash: en Rego no describís cómo hacer algo, describís qué tiene que ser verdadero para que algo esté permitido. Por ejemplo:
- “Ningún contenedor puede correr con usuario root.”
- “Solo se permiten imágenes desde registries autorizados.”
- “Todos los puertos expuestos deben estar en el rango 8000-9000.”
- “Los filesystems de contenedores de producción deben ser read-only.”
Si alguna de esas condiciones falla, OPA devuelve un error con detalle de qué regla se violó. El deploy no sigue. Esto es lo que los pipelines de Kubernetes ya usan con OPA Gatekeeper para admission control, pero SwiftDeploy lo trae al nivel de CLI sin requerir un cluster.
La diferencia entre validación (admission) y auditoría es importante acá: admission bloquea antes de desplegar, auditoría revisa lo que ya está corriendo. Un sistema bien armado hace las dos cosas.
Cómo implementarlo: del manifest.yaml a la infraestructura generada
Un manifest básico de SwiftDeploy define servicios con imagen, puertos y variables de entorno. Algo como:
services.api.image: myapp:1.4.2services.api.port: 8080services.api.env.DATABASE_URL: ${DATABASE_URL}
El CLI toma eso, rellena los templates y genera los archivos de infraestructura. El archivo docker-compose.yml que termina en tu directorio no es algo que editaste a mano: es output del compilador. Más contexto en lecciones de los incidentes críticos.
Esto tiene una ventaja que no es obvia al principio: podés hacer code review de la infraestructura. Si alguien modifica el manifest, ves exactamente qué cambió en el PR. Sin archivos YAML sueltos dispersos en el repo que nadie sabe quién tocó.
La combinación de yq para parseo y envsubst para inyección de variables mantiene el stack de dependencias bajo. No hace falta instalar un framework complejo para tener este flujo.
Observabilidad y auditoría: saber qué pasó y cuándo
Un deploy automático sin trazabilidad es un problema esperando ocurrir. SwiftDeploy plantea incluir un dashboard de estado en vivo y un audit trail que registra qué se desplegó, qué políticas se validaron y quién ejecutó el comando.
Para equipos que necesitan compliance (fintech, salud, cualquier cosa con auditorías externas), esto no es un nice-to-have. Sin audit trail, no podés demostrar que el despliegue siguió el proceso correcto. Con Prometheus podés exponer métricas del proceso de despliegue: duración, tasa de fallos por política, número de rollbacks.
Lo que no queda claro en la implementación actual de SwiftDeploy es si el audit trail persiste en un sistema externo o solo en logs locales. Para producción real, necesitás que esos logs lleguen a algún sistema centralizado (un SIEM, CloudWatch, Loki, lo que uses). Los logs que viven solo en la máquina que ejecutó el deploy tienen vida útil corta. Cubrimos ese tema en detalle en containerizar con Docker.
Infraestructura dinámica vs estática: comparativa directa
| Aspecto | YAML estático (tradicional) | Infraestructura dinámica (SwiftDeploy) |
|---|---|---|
| Fuente de verdad | Múltiples archivos YAML | Un solo manifest.yaml |
| Riesgo de drift | Alto (edición manual) | Bajo (generación automática) |
| Validación de políticas | Manual o en CI/CD externo | Integrada pre-despliegue con OPA |
| Code review de infra | Difícil (archivos separados) | Claro (cambios en manifest) |
| Curva de aprendizaje | Baja | Media (Rego requiere práctica) |
| Escala recomendada | Proyectos pequeños/medianos | Equipos con múltiples ambientes |
| Dependencias | Solo Docker | Docker + yq + envsubst + OPA |
Qué está confirmado y qué no en este enfoque
Confirmado
- SwiftDeploy existe y está documentado públicamente con código funcional (publicado 6 mayo 2026).
- OPA es un proyecto CNCF maduro con adopción real en producción, especialmente en Kubernetes.
- La generación de infraestructura desde templates con yq y envsubst es técnicamente sólida y reproducible.
- Rego es el lenguaje oficial de OPA y tiene documentación amplia.
Pendiente de validación
- El rendimiento del motor de políticas OPA en deploys de alta frecuencia (muchos servicios simultáneos) no está benchmarkeado en el proyecto original.
- La persistencia del audit trail en sistemas externos no está detallada en la documentación actual.
- La experiencia de depuración cuando una política Rego falla con un error críptico puede ser frustrante; no está claro qué tan bueno es el mensaje de error que devuelve SwiftDeploy.
Errores comunes al implementar despliegue automático DevOps con políticas
Escribir políticas Rego demasiado restrictivas desde el arranque
El error clásico: bloqueás todo lo que no sea perfecto, y el primer deploy en un ambiente nuevo falla por una regla de puerto que no aplica a ese contexto. Empezá con políticas en modo “audit” (solo reportan, no bloquean) y pasalas a “enforcement” cuando las hayas probado en todos tus ambientes. OPA soporta los dos modos.
Tratar el manifest.yaml como otro YAML editable a mano
Si alguien empieza a editar el docker-compose.yml generado directamente (porque “es más rápido”), el modelo entero se rompe. El archivo generado se sobreescribe en el próximo init. Necesitás poner en el equipo la regla de que el manifest es lo único que se toca, y quizás hasta agregarlo al CI para que falle si detecta cambios en los archivos generados que no pasaron por el manifest.
Ignorar la gestión de datos persistentes
Los contenedores son efímeros; los datos no deberían serlo. Si generás automáticamente el docker-compose pero no definís bien los volúmenes persistentes en el manifest, un recreate del servicio puede llevarse datos. El manifest tiene que ser explícito sobre qué directorios persisten y cuáles no.
No versionar las políticas OPA junto con el código
Las políticas Rego que viven en una carpeta separada del repo, sin tag de versión, son un problema futuro garantizado. Cuando en seis meses cambiás la política y un deploy viejo falla, vas a querer saber qué regla aplicaba en ese momento. Commiteá las políticas al mismo repo, con el mismo versionado que el manifest.
Qué significa esto para equipos en Latinoamérica
Muchos equipos en Argentina y la región todavía manejan el despliegue con scripts de shell o pipelines de CI que copian archivos YAML a mano. El gap entre eso y un sistema como SwiftDeploy no es enorme en términos técnicos, pero sí en términos de hábito. Esto se conecta con lo que analizamos en herramientas de automatización sin código.
La barrera más real es Rego: es un lenguaje declarativo con una curva que puede desanimar en las primeras horas. La recomendación práctica es arrancar con las políticas de ejemplo que OPA provee en su documentación oficial y adaptarlas antes de escribir las propias.
Para equipos que hospedan sus stacks en infraestructura propia o en proveedores como donweb.com, este tipo de herramienta es especialmente relevante porque reduce la dependencia de un CI/CD externo complejo para tener validación de políticas básica.
Si querés profundizar en el tema, mirá nuestro artículo sobre automatización de deployments.
Preguntas Frecuentes
¿Qué es un motor de despliegue policy-driven?
Es un sistema que genera la infraestructura dinámicamente desde una fuente de verdad central (un manifest) y valida reglas de negocio y seguridad antes de ejecutar cualquier despliegue. A diferencia de los pipelines estáticos, no trabaja con archivos YAML fijos que se editan a mano: los genera en tiempo de ejecución. Si una política falla (por ejemplo, un contenedor intentando correr como root), el proceso se detiene antes de que arranque.
¿Cómo funciona Open Policy Agent (OPA) para validar despliegues?
OPA recibe una consulta con el contexto del despliegue (imagen, puerto, configuración) y evalúa ese contexto contra políticas escritas en Rego, su lenguaje declarativo. Si todo cumple, devuelve “allow: true” y el proceso continúa. Si algo falla, devuelve el detalle de qué regla se violó y el deploy se cancela. En Kubernetes esto se llama admission control; en herramientas como SwiftDeploy opera como un pre-flight check de CLI.
¿Cuál es la diferencia entre infraestructura estática y dinámica en DevOps?
La infraestructura estática son archivos YAML o de configuración que alguien escribe y edita a mano, y que con el tiempo divergen del estado real del sistema (drift). La infraestructura dinámica se genera desde un manifest o definición central en cada ejecución, garantizando que lo que dice el código es exactamente lo que corre. El segundo enfoque elimina el drift estructuralmente, no por disciplina manual.
¿Qué herramientas necesito para implementar este sistema?
Para replicar el stack de SwiftDeploy necesitás: Docker (para los contenedores), yq (para parsear YAML), envsubst (para inyección de variables en templates), y OPA (para validación de políticas). Todas son open source y disponibles en Linux, macOS y Windows. La curva más pronunciada es aprender Rego para escribir las políticas, pero OPA tiene ejemplos documentados que cubrn los casos más comunes.
¿Cómo evitar errores de configuración en despliegues automáticos?
Tres cosas concretas: primero, un manifest como única fuente de verdad (nada se edita a mano en los archivos generados). Segundo, políticas OPA que validen la configuración antes de cada deploy, especialmente permisos de contenedor, imágenes permitidas y exposición de puertos. Tercero, audit trail de cada despliegue con qué políticas se evaluaron y el resultado. La combinación de generación automática más validación pre-ejecución reduce los errores de configuración a una fracción de lo que ocurre con YAML editado manualmente.
Conclusión
SwiftDeploy resuelve un problema concreto que cualquiera que haya gestionado múltiples ambientes conoce: la infraestructura definida a mano diverge de la infraestructura real, y eventualmente eso rompe algo en el peor momento. Tratarla como output compilado desde un manifest centralizado es conceptualmente limpio y técnicamente reproducible.
La integración de OPA agrega la capa que la mayoría de los pipelines básicos ignoran: validación de políticas antes de ejecutar, no después de que algo falló. Eso cambia el modelo de reacción por el de prevención.
El punto débil es la curva de Rego y la falta de benchmarks en deploys de alta carga. Para equipos pequeños o medianos con stacks de contenedores y ganas de formalizar el despliegue automático DevOps sin meterse en Kubernetes todavía, este es un punto de partida sólido. Para setups más complejos, el mismo patrón (manifest + policies + generated infra) escala hacia herramientas como Terraform con OPA o Pulumi con policy as code.