Distribución Linux eBPF: laptop vieja vuela en 2026
Un desarrollador presentó el 11 de junio de 2026 el diseño de una distribución Linux completamente nueva que usa eBPF como motor de telemetría y control. La promesa es concreta: una laptop de 5 años se siente rápida como si tuviera hardware recién comprado, y el usuario no necesita saber por qué. En vez de depender del scheduler fair-share del kernel, esta distro prioriza de forma agresiva la ventana activa y la UI, y castiga con throttling o congelamiento a los procesos que acaparan recursos en segundo plano.
Una distribución Linux eBPF-driven es un sistema operativo que incorpora eBPF (extended Berkeley Packet Filter) como capa de observabilidad y enforcement dentro del kernel, permitiendo que un daemon en userspace tome decisiones de scheduling en tiempo real sin tocar el código del kernel ni cargar módulos inseguros. Dicho más directo: es un Linux que se cura solo cuando algo se descontrola.
En 30 segundos
- Proyecto anunciado el 11 de junio de 2026: un arquitecto (Kritagya Jha) está validando el MVP de una distro que usa eBPF para auto-sanación del sistema en tiempo real.
- El scheduler es “injusto” a propósito: prioriza la UI y la ventana activa por encima de cualquier proceso en segundo plano, al revés de lo que hacen CFS o EEVDF.
- Telemetría con near-zero overhead: monitoreo de CPU wakeups, syscalls y page faults mediante kprobes y tracepoints, sin penalizar el rendimiento.
- Acciones automáticas: si un proceso se desboca, el sistema lo limita, lo pausa o lo congela sin intervención manual.
- Corre en kernel 6.0+ (mínimo recomendado para) y apunta a hardware de hace 5 años: no necesitás una máquina nueva para aprovecharlo.
¿Qué es eBPF y cómo puede acelerar una laptop de 5 años?
eBPF es una máquina virtual dentro del kernel de Linux que ejecuta pequeños programas en respuesta a eventos del sistema. Hablamos de syscalls, funciones del kernel, paquetes de red, tracepoints. Lo interesante es que estos programas corren en un sandbox aislado y verificado, sin necesidad de recompilar el kernel ni cargar módulos que puedan tirar abajo el sistema. eBPF ya está consolidado como la capa de extensibilidad segura del kernel, y en producción lo usan Netflix, Meta, Google y Cloudflare para tareas de red, seguridad y monitoreo.
El punto es que eBPF permite hacer dos cosas que en las distros tradicionales no existen juntas: telemetría de altísima granularidad y enforcement dinámico, todo con un overhead tan bajo que ni lo notás. En lugar de abrir top y matar un proceso manualmente cuando la máquina se arrastra —escena clásica—, un daemon userspace lee los mapas eBPF en tiempo real y decide por vos. Y lo hace antes de que el lag te saque de quicio.
La laptop de 5 años no se acelera por arte de magia. Lo que pasa es que el sistema deja de tratar a todos los procesos como iguales. Si hay un proceso en segundo plano que acapara CPU o genera page faults a lo loco, la distro lo detecta y lo pone en caja. La UI respira. Esa es la diferencia. Más contexto en en nuestra comparativa de CI/CD 2026.
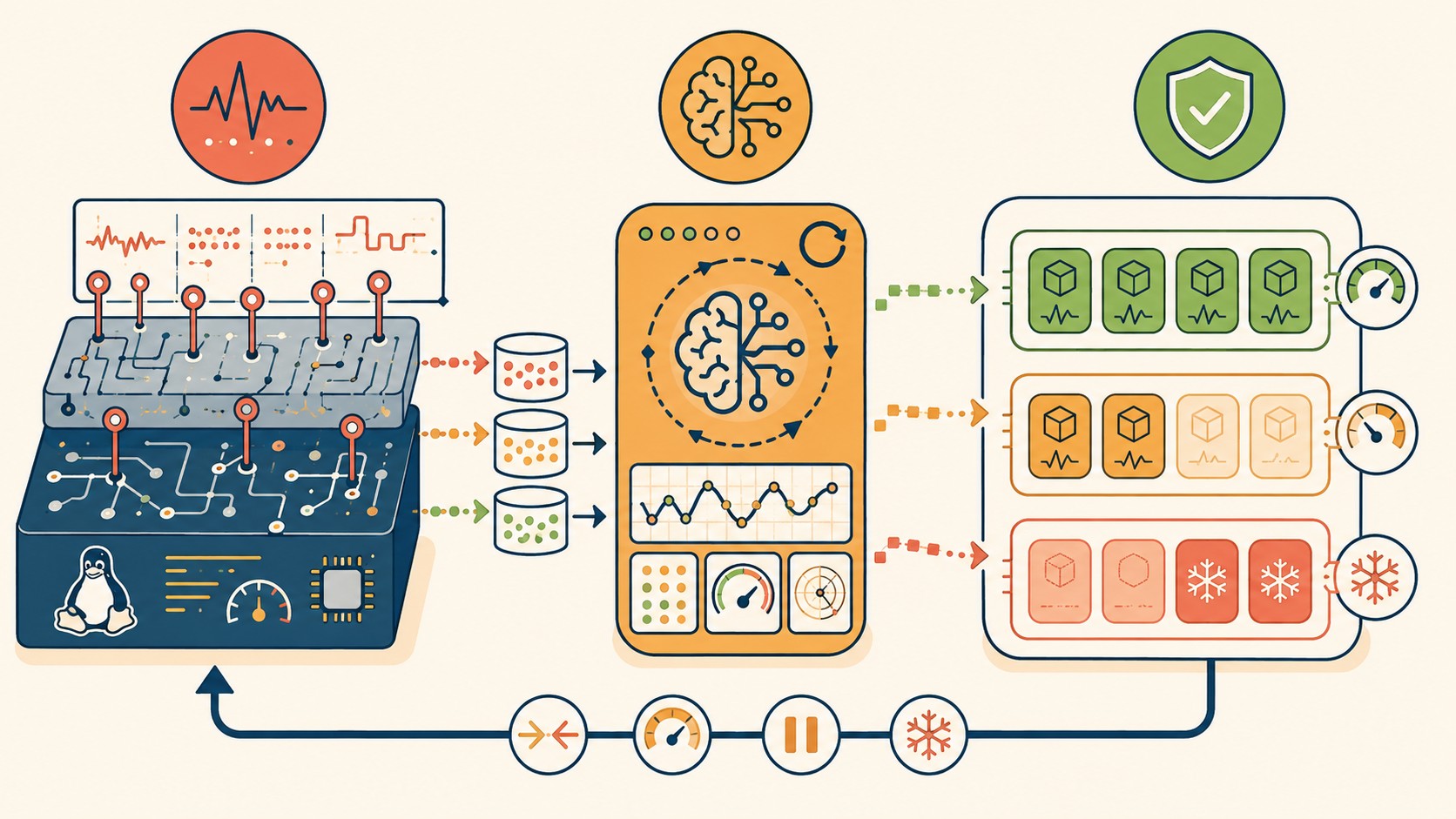
¿Cómo funciona el modelo de auto-sanación con eBPF?
El diseño de esta distro, según el artículo del arquitecto en dev.to, descansa sobre tres pilares que laburan en conjunto. No es un truco de uno solo.
- Telemetría explicable: usan eBPF kprobes y tracepoints para capturar CPU wakeups, syscalls y page faults con overhead casi nulo. En vez de mostrarte “CPU alta”, el sistema sabe contextualmente qué está causando el cuello de botella. Si un proceso hace wakeups agresivos, lo identifica y lo asocia con una causa concreta.
- Cerebro en userspace: un daemon controlador rápido consulta los mapas eBPF en tiempo real. Básicamente actúa como un SRE autónomo para tu máquina local. No es un script que corre cada 5 minutos; está constantemente evaluando el estado del sistema.
- Enforcement dinámico: si un daemon de fondo o una pestaña del navegador empieza a despertar la CPU sin control o a hacer thrashing de memoria, el sistema no se queda en el log. Actúa: aplica throttling, freeza el proceso vía cgroups, o reduce drásticamente su prioridad. Todo automático.
Subís un proceso pesado, el daemon lo detecta, chequea si está en primer plano o no, y si no lo está lo frena sin que tengas que abrir una terminal. ¿Funcionará siempre perfecto? Probablemente no en el MVP, pero el concepto es sólido.
¿Qué ventajas tiene una distro eBPF frente a las distribuciones tradicionales?
Las distros mainstream todavía resuelven problemas del 2010, como dice el propio desarrollador. Tenemos estabilidad a prueba de balas y buenos gestores de paquetes, pero cuando el sistema empieza a laggear, el SO se comporta como víctima pasiva. Abrís top, ves un proceso random comiendo CPU, y lo matás a mano. Eso es todo lo que ofrece.
La distro eBPF-driven cambia el paradigma del scheduler de fair-share a un modelo unfair por diseño. El scheduler tradicional (CFS o EEVDF) trata de repartir los recursos de forma equitativa entre todos los procesos. Esta distro dice: “el que está en frente del monitor manda, el resto espera”.
Otra ventaja es que eBPF es mucho más seguro que los módulos de kernel tradicionales. Un programa eBPF pasa por un verificador antes de ejecutarse; si no es seguro, no corre. Y se puede cargar y descargar en caliente, sin reiniciar. El análisis de portabilidad de BPF explica que con BPF CO-RE (Compile Once, Run Everywhere), el mismo bytecode funciona en distintos kernels sin recompilar. Eso simplifica el despliegue masivo.
| Aspecto | Distro tradicional (CFS/EEVDF) | Distro eBPF-driven |
|---|---|---|
| Modelo de scheduler | Fair-share (equitativo) | Unfair (prioriza UI activa) |
| Telemetría | Herramientas externas (top, htop) | Integrada en kernel vía eBPF, overhead mínimo |
| Auto-sanación | No tiene | Throttling, freeze, cgroups automático |
| Seguridad de extensión | Módulos de kernel con riesgo de crash | Programas eBPF verificados, sandbox |
| Reinicio necesario | Sí, para cargar módulos | No, carga y descarga en caliente |
| Portabilidad del código | Depende del kernel exacto | BPF CO-RE: un bytecode, múltiples kernels |
¿Qué requisitos de kernel y hardware necesita esta distro?
Acá no hay trampa. El propio artículo del proyecto aclara que la laptop objetivo es una máquina de 5 años. No están apuntando a hardware de última generación. Todo lo contrario: la gracia es que justamente ese hardware modesto se sienta rápido. Ya lo cubrimos antes en como analizamos al elegir entre Jenkins y GitHub Actions.
El requisito de kernel es 6.0 o superior, sobre todo si se quiere aprovechar BPF CO-RE para portabilidad. En 2026, kernel 6.0 es el mínimo recomendado en cualquier distro moderna —Ubuntu 22.04 LTS ya lo traía, y las actuales van por 6.x— así que no debería ser un problema. Hay herramientas que permiten verificar los requerimientos mínimos de kernel de un programa eBPF antes de desplegarlo.
En criollo: si tu laptop tiene 5 años, corre kernel 6.0+ y puede con esta distro. No hay excusa de hardware.
¿Cómo se programa y despliega el código eBPF en esta distro?
Si alguna vez tocaste eBPF, sabés que no es escribir un script bash. Los programas eBPF se escriben típicamente en C o Rust usando frameworks como Aya o cilium/ebpf, y se compilan a bytecode eBPF con Clang/LLVM. También existen herramientas de más alto nivel como bcc o bpftrace para scripting rápido de observabilidad, pero para la lógica de auto-sanación de esta distro se necesita algo más robusto.
El flujo es más o menos así: escribís el código que hookea un kprobe o tracepoint, lo compilás a bytecode, lo cargás en el kernel con una syscall bpf(), y el programa queda corriendo en respuesta a eventos. Los datos que recolecta van a mapas eBPF, que son estructuras de datos compartidas entre el kernel y el userspace. El daemon userspace —el “cerebro”— lee esas estructuras y decide si hay que throttlear, freezar o matar algo. Todo en tiempo real. Esto se conecta con lo que analizamos en según la guía de hreflang para SEO multilingüe.
Lo bueno de eBPF es que si el programa pasa el verificador, no puede crashear el kernel. Lo malo es que el verificador tiene sus mañas, y a veces te rechaza código que para vos es perfectamente válido. La guía de eBPF en Linux cubre bien esos dolores de cabeza y cómo sortearlos.
¿Qué casos de uso concretos tiene esta tecnología?
Ponele que estás renderizando un video en Blender y al mismo tiempo tenés 40 pestañas abiertas en Firefox. En una distro tradicional, el scheduler reparte CPU entre Blender, las pestañas y el compositor de la UI. Si una pestaña se vuelve loca con JavaScript, la UI se traba y el mouse se arrastra. Con esta distro, el daemon detecta que la pestaña está en segundo plano y que está haciendo wakeups excesivos; le aplica un límite, y el puntero del mouse sigue respondiendo.
Otro escenario: se está corriendo un backup automático en segundo plano que, sin querer, está generando page faults a lo pavote y metiendo presión en el subsistema de memoria. El cerebro eBPF lo identifica y le reduce la prioridad o lo pausa momentáneamente hasta que termine lo que estás haciendo en primer plano.
Estos ejemplos no son teóricos. El proyecto plantea exactamente estos mecanismos: monitoreo de CPU wakeups, syscalls y page faults. Y empresas como Meta y Cloudflare llevan años usando eBPF en producción (aunque más para red y seguridad, no tanto para scheduling de escritorio). La novedad es llevarlo al usuario común.
Errores comunes al pensar en eBPF para el escritorio
- Creer que eBPF es solo para redes: eBPF arrancó para filtrar paquetes, pero hoy en día puede hookear casi cualquier parte del kernel. Syscalls, tracepoints, LSM, scheduler… El abanico es enorme.
- Pensar que hace falta hardware nuevo: la distro está pensada para hardware de 5 años. Si tenés kernel 6.0+, estás. eBPF no pide GPU cara ni RAM extravagante.
- Asumir que es lo mismo que un módulo de kernel: no, un módulo de kernel mal escrito te tira abajo la máquina. Un programa eBPF pasa por un verificador que garantiza que no va a crashear el kernel. Es más seguro por diseño.
- Ignorar el overhead de la telemetría: está bien, eBPF tiene near-zero overhead, pero no es cero. Si ponés 500 kprobes en funciones calientes del kernel, algo vas a notar. La distro usa unos pocos puntos estratégicos, no un ejército de hooks.
Preguntas Frecuentes
¿Qué es una distribución Linux basada en eBPF?
Es un sistema operativo que integra eBPF como capa de monitoreo y control del kernel, permitiendo que un daemon en userspace ajuste el rendimiento del sistema en tiempo real. Prioriza la experiencia del usuario activo por sobre los procesos en segundo plano usando telemetría de bajo overhead y acciones automáticas como throttling o congelamiento de procesos. Sobre eso hablamos en tal como vimos en la guía de agentes locales con OpenClaw.
¿Cómo mejora eBPF el rendimiento de una laptop vieja?
No acelera mágicamente el hardware. Lo que hace es dejar de tratar todos los procesos como iguales: identifica cuál está en primer plano y le asigna más recursos, mientras limita o pausa los procesos que acaparan CPU o memoria en segundo plano. El resultado es que la UI se siente mucho más fluida, incluso en máquinas con varios años encima.
¿Qué es la auto-sanación con eBPF en Linux?
Es un mecanismo que combina telemetría de kernel vía eBPF con un daemon userspace que toma decisiones automáticas. Si un proceso se desboca, el sistema no solo lo registra sino que actúa: aplica límites de CPU, lo congela con cgroups o reduce su prioridad, todo sin intervención del usuario.
¿Cómo funciona la telemetría con eBPF en el kernel?
Los programas eBPF se enganchan a puntos específicos del kernel (kprobes, tracepoints) para capturar eventos como CPU wakeups, syscalls o page faults. Los datos recolectados se almacenan en mapas eBPF, que son leídos por el daemon userspace. Todo con un overhead tan bajo que el impacto en el rendimiento es prácticamente imperceptible.
Si querés meterte más en el tema, revisá nuestro artículo sobre eBPF optimizar rendimiento.
Si querés profundizar en esto, tenemos un artículo sobre Building an eBPF-Driven Linux Distro: Making a 5-Year-Old La.
¿Qué requisitos de kernel necesita eBPF?
Se necesita kernel Linux 6.0 o superior para aprovechar características como BPF CO-RE (Compile Once, Run Everywhere). En 2026, ese kernel es el piso mínimo recomendado para cualquier distribución moderna, así que no representa una barrera para la mayoría de las máquinas.
Conclusión
El proyecto de esta distribución eBPF-driven todavía está en fase MVP —y ojalá pase las validaciones de la comunidad—, pero la idea es de las más frescas que vi en el ecosistema Linux de escritorio en 2026. Cambiar el scheduler fair-share por uno que prioriza al usuario activo no es una pavada técnica, y usar eBPF como capa de telemetría y enforcement es exactamente el tipo de arquitectura que aprovecha lo que el kernel ya ofrece sin payloads invasivos.
Para el usuario de a pie, la promesa es tentadora: hardware modesto que se comporta como si tuviera un par de años menos. Para el que viene del palo técnico, es un caso de uso de eBPF que va mucho más allá de los firewalls y los balanceadores de carga. Habrá que ver cómo evoluciona el proyecto y si el modelo unfair no genera efectos secundarios en cargas de trabajo mixtas (spoiler: probablemente algunos aparezcan). Pero si sale bien, podría cambiar la forma en que pensamos el scheduling en el escritorio.
Fuentes
- Building an eBPF-Driven Linux Distro – Artículo original del arquitecto (11 de junio de 2026)
- eBPF 2026: Guía completa en Linux – Panorama actualizado de eBPF
- eBPF en 2026: la máquina virtual oculta dentro de Linux – Análisis técnico
- Análisis de portabilidad de BPF – Optimización del despliegue de eBPF en Linux