Eliminador de ruido IA por $20/mes en CPU
Si alguna vez intentaste limpiar el audio de un video grabado en casa y usaste FFmpeg para sacarle el ruido de fondo, sabés exactamente cómo termina eso: el ruido sigue ahí, la voz suena metálica, y el resultado es peor que el original. Construir un eliminador de ruido IA funcional que corra en CPU y cueste USD 20/mes es posible hoy usando DeepFilterNet3, una red neuronal entrenada en speech que entiende la diferencia entre tu voz y el aire acondicionado de fondo.
En 30 segundos
- FFmpeg tiene dos filtros de ruido (afftdn y anlmdn) que funcionan solo con ruido constante; fallan con ruido real y variable.
- DeepFilterNet3 es una red neuronal open source entrenada específicamente en speech enhancement: suprime lo que no es voz.
- VidClean implementó esta solución sin GPU, solo CPU, y la mantiene por USD 20/mes siendo la segunda herramienta más usada del sitio.
- RNNoise es más liviano pero más viejo y menos preciso en ruidos complejos; Whisper no es un supresor de ruido, es transcripción.
- El modelo corre en instancias de CPU estándar con un pipeline de audio bien diseñado, sin infraestructura costosa.
El problema: FFmpeg no entiende la voz
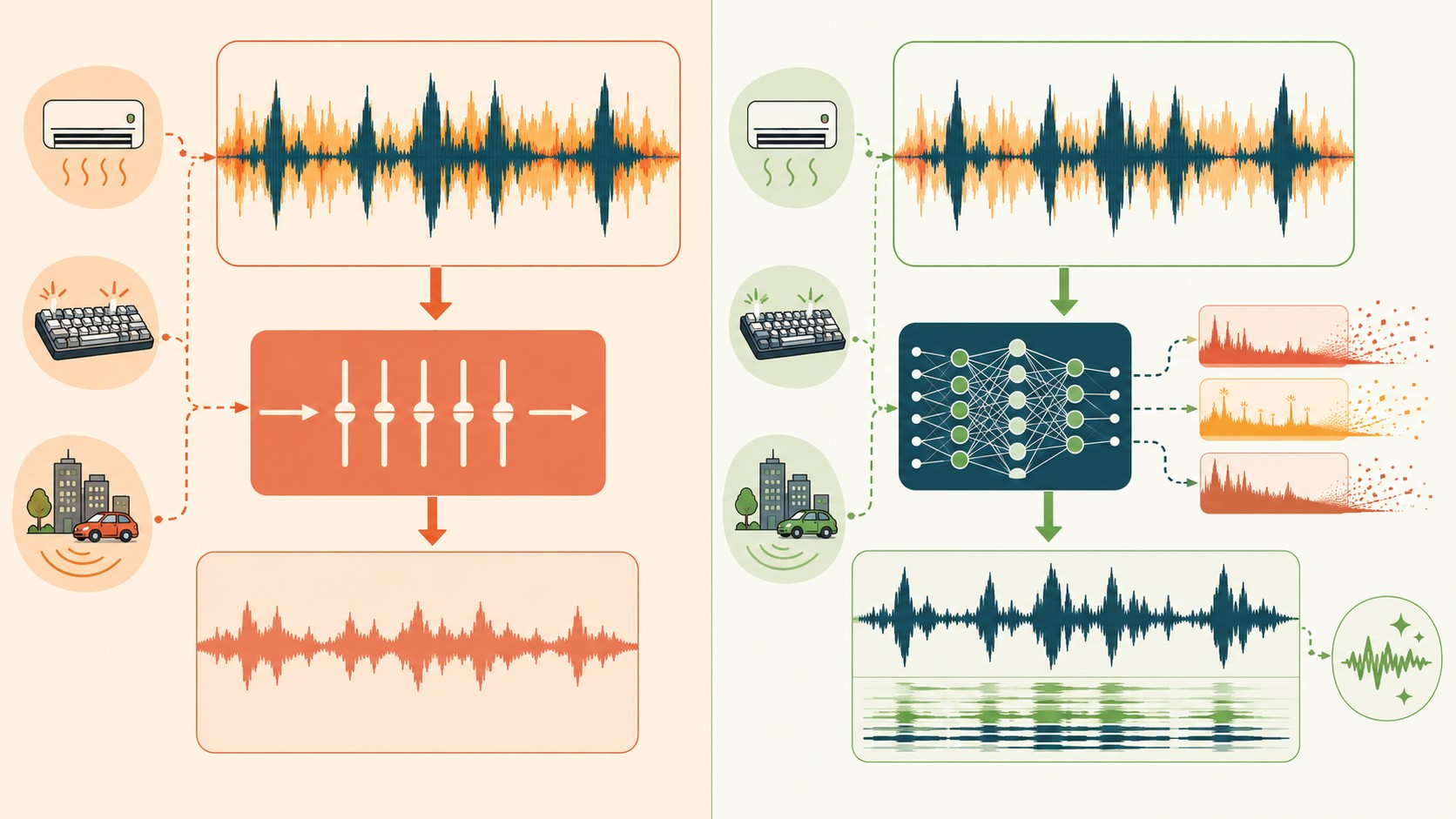
FFmpeg tiene dos filtros de reducción de ruido que vale la pena conocer: afftdn y anlmdn. Para ruido consistente, un hiss de cassette o un zumbido a frecuencia fija, funcionan. Aplicás el filtro, el ruido desaparece, listo.
El problema aparece con ruido real. El ruido de un aire acondicionado que sube y baja de volumen. Los clicks del teclado mientras alguien habla. El sonido de la calle que entra por la ventana. Una fan que acelera cada dos minutos. Nada de eso tiene frecuencia fija y FFmpeg no sabe qué hacer con eso.
El motivo de fondo es que los filtros de FFmpeg no fueron entrenados en speech. Aplican un análisis estadístico sobre toda la señal de audio y suprimen lo que se desvía de cierta línea base, esperando que eso sea el ruido. A veces funciona. Pero no distinguen si lo que está suprimiendo es tu voz o el aire del ambiente, y eso es el problema central.
¿Y qué pasa cuando el ruido varía dinámicamente? Exacto: el filtro pierde el hilo. La “línea base” que estableció hace 10 segundos ya no corresponde al estado actual de la señal, y el resultado es una mezcla rara donde la voz suena procesada y el ruido igual sigue ahí.
DeepFilterNet3: una red neuronal entrenada en speech
DeepFilterNet3 es una red neuronal open source diseñada para speech enhancement. La diferencia con FFmpeg no es de cantidad, es de naturaleza: DeepFilterNet3 fue entrenada para entender cómo suena el habla humana y suprimir todo lo que no lo sea.
En la práctica, eso significa que el modelo tiene una representación interna de la voz. Cuando procesa una señal de audio, no aplica un filtro estadístico global; evalúa cada segmento temporal y decide qué es speech y qué no. Si el aire acondicionado sube de volumen en el segundo 15, el modelo lo ve como ruido porque no coincide con los patrones de voz. Si el click del teclado aparece justo cuando alguien habla, lo suprime sin llevarse la consonante con él.
Las alternativas en este espacio son básicamente tres. RNNoise es más liviano y más rápido, pero fue desarrollado alrededor de 2020-2021 y pierde precisión con ruidos complejos o superpuestos. Whisper de OpenAI aparece seguido en estas conversaciones (me imagino que porque la gente lo busca en Google), pero Whisper es un modelo de transcripción, no de supresión de ruido: convertís audio a texto, no limpiás el audio. DeepFilterNet3 es hoy la mejor opción open source para este caso de uso según quien construyó VidClean: precisa, activamente mantenida, y diseñada para el problema exacto.
Por qué los filtros estadísticos fallan con ruido real
Ponele que grabás un webinar desde tu home office. Tenés el aire acondicionado prendido porque es verano. Los primeros segundos, el aire está en el ciclo bajo. El filtro de FFmpeg mide ese nivel y establece su línea base de ruido. Perfecto hasta acá.
A los dos minutos, el compresor del aire arranca y el nivel sube 6 dB. El filtro estadístico ya no sabe qué es ruido y qué es señal útil porque la referencia que tenía quedó desactualizada. Puede que empiece a cortar frecuencias medias que incluyen tu voz. O que deje pasar el ruido porque ya no supera el umbral relativo que estableció al principio.
Una red neuronal como DeepFilterNet3 no trabaja con líneas base estáticas. Evalúa frame a frame y decide en función del modelo de voz que internalizó durante el entrenamiento. El ruido variable no la confunde porque no está midiendo variaciones relativas, está reconociendo patrones.
Cómo construir un eliminador de ruido IA: la arquitectura de VidClean
El autor de VidClean publicó el caso el 21 de mayo de 2026 detallando cómo esta herramienta se convirtió en la segunda más usada del sitio. El stack usa DeepFilterNet3 corriendo en CPU, sin GPU, con un pipeline de audio que incluye queue system para manejar la carga.
El proceso general es:
- El usuario sube el video o audio al servicio.
- El sistema extrae el track de audio (FFmpeg sigue siendo útil para esto, solo no para el filtrado).
- El audio se procesa por DeepFilterNet3 en CPU.
- El audio limpio se reinserta en el video o se entrega como archivo de audio.
- El trabajo entra en una cola para no sobrecargar el servidor.
La parte interesante es que el modelo corre bien en CPU. No necesita una GPU cara ni una instancia especializada. Eso es lo que hace posible el costo de USD 20/mes: instancias de CPU estándar con buen manejo de la cola de trabajos.
Costos de infraestructura: USD 20/mes en CPU
Este número llama la atención. ¿Cómo se mantiene un servicio público de procesamiento de audio por 20 dólares al mes?
La clave está en dos cosas: primero, DeepFilterNet3 no requiere GPU. Muchos modelos de IA de audio asumen que vas a tener aceleración por hardware. DeepFilterNet3 está diseñado para correr eficientemente en CPU, lo que abre la puerta a instancias mucho más baratas.
Segundo, la cola. Si el sistema procesara cada pedido en tiempo real sin cola, necesitaría escalar horizontalmente para manejar picos de demanda. Con una cola bien implementada, una instancia de CPU maneja el trabajo secuencialmente. El usuario espera un poco más, pero el costo de infraestructura se mantiene bajo. Lo explicamos a fondo en ejecutar agentes de IA sin depender de APIs externas.
Para quienes trabajan con hosting propio, esto también significa que podés montar algo similar en un VPS estándar. Si ya tenés un servidor en donweb.com, una instancia con 4 vCPU y 8 GB de RAM puede manejar el procesamiento sin problema para uso propio o de equipo pequeño.
Tabla comparativa: opciones para eliminar ruido de audio
| Herramienta | Tipo | Requiere GPU | Calidad en ruido variable | Open Source | Costo estimado |
|---|---|---|---|---|---|
| DeepFilterNet3 | Red neuronal (speech) | No | Alta | Sí | Bajo (CPU) |
| RNNoise | Red neuronal (antigua) | No | Media | Sí | Muy bajo |
| FFmpeg afftdn/anlmdn | Filtro estadístico | No | Baja | Sí | Nulo |
| Whisper | Transcripción (no supresión) | Recomendado | N/A | Sí | Variable |
| Servicios cloud de audio | API propietaria | Manejado | Alta | No | Alto |
Cómo implementar DeepFilterNet3 en tu propio proyecto
El modelo está disponible como herramienta open source. Hay proyectos como DeepDenoiser en GitHub que envuelven el modelo en interfaces más fáciles de integrar.
Para integrarlo en un servicio propio, el camino básico es: instalás las dependencias del modelo, lo cargás en tu aplicación (Python es el camino más directo), y procesás los archivos de audio pasándolos por el pipeline de inferencia. El modelo toma un archivo de audio como entrada y devuelve la versión limpia.
La integración con FFmpeg tiene sentido en las etapas de preprocesamiento y postprocesamiento: usás FFmpeg para extraer audio del video, lo procesás con DeepFilterNet3, y usás FFmpeg de nuevo para reinsertarlo. Cada herramienta hace lo que sabe hacer bien.
Si querés ver cómo funciona sin instalación, fal.ai tiene DeepFilterNet3 disponible como API para pruebas. También podés ver VidClean en acción en vidclean.net.
Casos de uso donde la diferencia es notable
Hay escenarios donde FFmpeg zafa y donde no vale la pena el overhead de un modelo neuronal. Grabás en una sala silenciosa con un micrófono decente y solo hay un leve hiss de fondo: FFmpeg lo saca bien.
Pero si grabás conferencias de Zoom donde cada participante tiene su propia mezcla de ruido ambiente, podcasts grabados en home offices con ventilación encendida, videos en espacios semipúblicos, o cualquier grabación donde el ruido no es constante, ahí DeepFilterNet3 hace una diferencia concreta que se escucha.
Errores comunes al implementar supresión de ruido
Usar Whisper como supresor de ruido. Aparece seguido en foros y tutoriales, y la lógica tiene cierta intuición: si Whisper transcribe bien a pesar del ruido, debe estar “entendiendo” el audio de alguna forma. No funciona así. Whisper hace transcripción, no devuelve audio limpio. Si lo usás para preprocesar antes de pasar a otro pipeline, solo estás perdiendo el paso de audio original.
Correr DeepFilterNet3 en modo síncrónico sin cola. Si cada request espera que el modelo procese en tiempo real antes de responder, el servidor se satura rápido con tráfico moderado. El sistema de queue es lo que hace viable el modelo de USD 20/mes; sin él, necesitás escalar horizontalmente.
Esperar que el modelo limpie audio con problemas de clipping o saturación. DeepFilterNet3 suprime ruido de fondo, no arregla distorsión. Si el audio tiene clipping porque grabaste con el micrófono a gain máximo, el modelo no puede reconstruir las muestras perdidas. Eso va antes, en la etapa de grabación o en el preprocesamiento.
Podés ver cómo lo hacemos en How I built a free AI background noise remover that runs on.
Si te interesa el tema, mirá How I built a free AI background noise remover that runs on nuestra nota.
Esto está conectado con un artículo que tenemos sobre How I built a free AI background noise remover that runs on .
Recordá este caso de uso cuando leas How I built a free AI background noise remover that runs on.
Preguntas Frecuentes
¿Cómo funciona DeepFilterNet3 para eliminar ruido?
DeepFilterNet3 es una red neuronal entrenada en speech enhancement que analiza cada segmento de audio y suprime lo que no coincide con patrones de voz humana. A diferencia de los filtros estadísticos, tiene un modelo interno del habla y puede distinguir la voz del ruido ambiente incluso cuando ese ruido varía en volumen o frecuencia.
¿Qué diferencia hay entre FFmpeg y DeepFilterNet3 para eliminar ruido de fondo?
FFmpeg aplica filtros estadísticos (afftdn, anlmdn) que funcionan con ruido constante y de frecuencia fija. DeepFilterNet3 usa aprendizaje profundo entrenado en speech y puede suprimir ruido dinámico y variable. Para hiss de cassette o zumbido constante, FFmpeg alcanza. Para ruido real de home office o espacio público, DeepFilterNet3 da mejores resultados.
¿Puedo construir mi propia herramienta de eliminación de ruido con DeepFilterNet3?
Sí. El modelo es open source y hay implementaciones disponibles en GitHub como DeepDenoiser. El stack más directo es Python para el procesamiento con DeepFilterNet3, y FFmpeg para extracción e inserción de audio en video. Con una instancia de CPU y una cola de trabajos bien implementada, el costo de infraestructura puede quedar por debajo de USD 20/mes.
¿Cuánto cuesta mantener un servicio de eliminación de ruido en CPU?
VidClean opera su eliminador de ruido con DeepFilterNet3 en CPU por USD 20/mes. Esto es posible porque el modelo no requiere GPU y el sistema procesa trabajos con una cola en lugar de en tiempo real. El costo varía según el volumen de uso: para uso personal o de equipo pequeño, una instancia de VPS estándar con buena CPU es suficiente.
¿Por qué FFmpeg no funciona bien con ruido variable?
FFmpeg establece una línea base estadística de ruido al analizar la señal. Si el ruido cambia de nivel o frecuencia (un aire acondicionado que acelera, una fan que sube), esa línea base queda desactualizada y el filtro pierde efectividad o empieza a procesar también la señal de voz. Los filtros estadísticos no tienen modelo de lo que es voz humana; solo trabajan con diferencias relativas en la señal.
Conclusión
El caso de VidClean muestra algo que vale la pena tener en cuenta: las herramientas de audio disponibles hoy, en particular DeepFilterNet3, permiten construir servicios de procesamiento de audio con calidad real a un costo que hace tres años hubiera parecido absurdo. No necesitás GPU, no necesitás infraestructura cara, y el modelo está disponible de forma abierta.
FFmpeg sigue siendo la base para mover y convertir audio. Pero cuando el ruido es real y dinámico, necesitás algo que entienda la voz humana, no solo que aplique un filtro estadístico. Si estás construyendo algo que procesa audio con gente hablando en condiciones reales, DeepFilterNet3 es el punto de partida que tiene sentido hoy.
![I built a [FREE] plugin to help my sites get picked up by AI crawlers - ilustracion](https://donweb.news/wp-content/uploads/2026/04/plugin-crawlers-ia-gratuito-hero-768x429.jpg)