Failover Aurora DSQL: qué demostró el demo de AWS
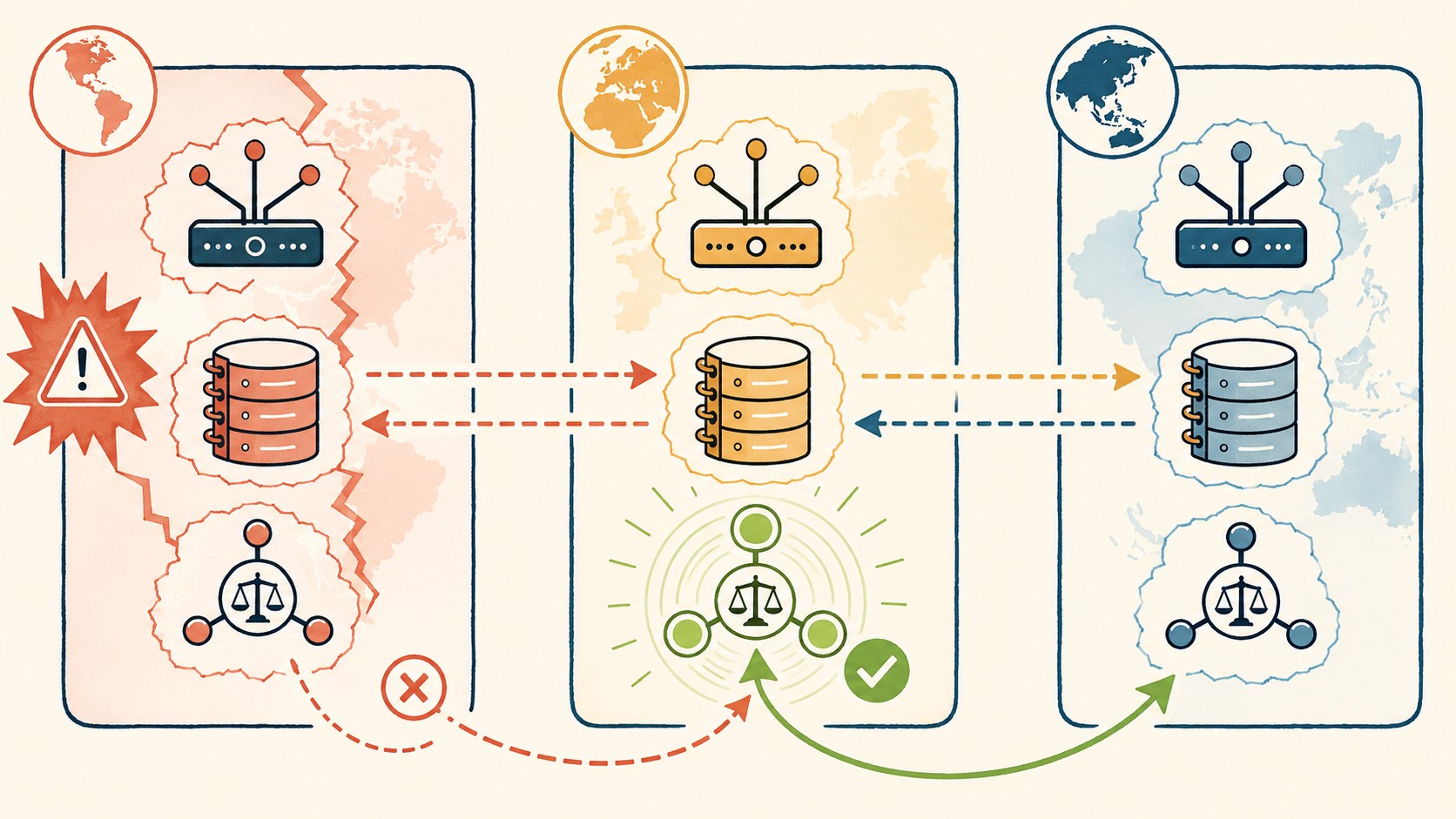
En junio de 2026, el equipo de AWS —con Marc Brooker a la cabeza— mostró un demo de failover en Aurora DSQL que dejó a más de uno con la boca abierta: cortaron una región entera y la base de datos siguió funcionando sin perder una sola transacción. El failover de Aurora DSQL logró un RPO sub-segundo y redirigió el tráfico automáticamente en menos de lo que tardás en pestañear, demostrando que la arquitectura con Adjudicator y Journal no es humo.
Aurora DSQL es la base de datos SQL distribuida y serverless de AWS que permite escrituras multi-región con consistencia fuerte ACID y failover automático ante la caída de una región completa. A diferencia de Aurora Global Database —que usa réplicas de solo lectura en regiones secundarias—, DSQL replica las transacciones de forma síncrona entre todas las regiones activas, garantizando que el RPO sea cercano a cero incluso en escenarios de desastre total.
En 30 segundos
- RPO sub-segundo confirmado: el demo de AWS en 2026 mostró cero pérdida de datos al tumbar una región entera; las escrituras síncronas entre regiones lo garantizan.
- Arquitectura con tres componentes: Router (enruta conexiones), Journal (WAL distribuido para durabilidad) y Adjudicator (consenso global para atomicidad) trabajan juntos para que el failover sea transparente.
- Latencia de escritura multi-región: entre 0 y 50 ms según la distancia, con transacciones complejas que son de 2 a 5 veces más lentas que en Aurora estándar —no es magia, es física.
- No necesita intervención manual: a diferencia de Aurora Global Database, donde tenés que promover réplicas manualmente (o configurar automatización), DSQL se encarga solo de detectar la falla y redirigir.
¿Qué demostró exactamente el demo de failover de Aurora DSQL?
El demo que presentó Marc Brooker en la AWS re:Inforce de 2026 fue brutalmente simple en su planteamiento y demoledor en su ejecución. Dos regiones activas —us-east-1 y eu-west-1— recibiendo escrituras simultáneas desde aplicaciones en producción. En un momento dado, el equipo de AWS simuló la caída total de us-east-1. Lo que pasó después es lo que hace que DSQL sea distinto a todo lo que existía antes en el portfolio de AWS.
Las escrituras que iban a la región caída se redirigieron automáticamente a eu-west-1. El Router —el componente que acepta las conexiones de los clientes— detectó la falla y reencaminó el tráfico sin que las aplicaciones tuvieran que reconectarse ni reintentar. Mientras tanto, el Journal confirmó que cada transacción ya estaba replicada y durada en la región sobreviviente, y el Adjudicator resolvió cualquier posible conflicto de atomicidad en tiempo real. El resultado: cero transacciones perdidas, cero inconsistencias, y un tiempo de recuperación medido en milisegundos.
¿Y las aplicaciones? Ni se enteraron. Los clientes siguieron escribiendo y leyendo como si nada. Eso es lo que separa un failover de verdad de esos failovers “automáticos” que en realidad requieren que alguien despierte al DBA a las tres de la mañana.
¿Cómo logra Aurora DSQL un failover sin pérdida de datos?
Acá es donde la arquitectura se pone interesante. Aurora DSQL no es una base de datos tradicional con réplicas —es un sistema distribuido desde el día cero, diseñado con tres componentes que se reparten la responsabilidad de mantener los datos vivos pase lo que pase. Tema relacionado: nuestra comparativa de CI/CD 2026.
El Router es la puerta de entrada. Acepta conexiones de los clientes, las autentica, y las enruta a la región adecuada. Cuando una región cae, el Router es el primero en detectarlo y redirigir el tráfico. No necesita un balanceador de carga externo ni DNS magic —está integrado en la arquitectura de DSQL y toma decisiones en tiempo real basándose en la salud de cada región.
El Journal es un WAL (Write-Ahead Log) distribuido que garantiza la durabilidad. Cada escritura se registra en el Journal antes de confirmarse al cliente, y ese Journal se replica síncronamente entre regiones. Si una región desaparece, las demás ya tienen copia de cada transacción confirmada. No hay “ventana de pérdida” porque la replicación es síncrona, no asíncrona —el cliente no recibe el OK hasta que los datos están a salvo en múltiples ubicaciones físicas.
El Adjudicator es el que cierra la jugada. Maneja el consenso global para garantizar atomicidad y aislamiento en transacciones que tocan datos en distintas regiones. Imaginate que tenés jugadores en Tokio, São Paulo y Londres escribiendo puntuaciones al mismo tiempo en tu juego online, y justo cuando la región de Tokio se va a pique porque hubo un corte de fibra masivo, las escrituras de esos jugadores no solo no se pierden sino que el Router las redirige automáticamente a la región más cercana, el Journal confirma la durabilidad en cuestión de milisegundos y el Adjudicator resuelve cualquier conflicto de atomicidad sin que nadie en producción se entere de que media infraestructura acaba de desaparecer.
Según el artículo técnico del equipo de AWS en español, esta arquitectura es lo que permite que el RPO sea consistentemente sub-segundo en todos los escenarios. No es un “depende” ni un “en condiciones ideales” —es por diseño.
¿Cuál es la diferencia entre failover en Aurora DSQL y Aurora Global Database?
Si alguna vez configuraste Aurora Global Database, sabés que el failover no es exactamente “automático” como te lo venden. Tenés una región primaria que acepta escrituras y una o más regiones secundarias que solo leen. Cuando la primaria cae, alguien —o algún script— tiene que promover una secundaria a primaria. Y durante ese proceso, las escrituras que no llegaron a replicarse se pierden. El RPO típico va de segundos a minutos, dependiendo de la carga y la latencia entre regiones.
Aurora DSQL rompe ese molde porque todas las regiones son primarias. No hay promoción, no hay rol que cambiar, no hay ventana de pérdida. La diferencia es tan grande que merece una tabla para dejarlo claro. Esto se conecta con lo que analizamos en el análisis entre Jenkins y GitHub Actions.
| Característica | Aurora DSQL | Aurora Global Database |
|---|---|---|
| Escrituras multi-región | Sí, todas las regiones aceptan escrituras | No, solo la región primaria escribe |
| Replicación | Síncrona entre todas las regiones | Asíncrona desde primaria a secundarias |
| RPO en failover | Sub-segundo (cercano a cero) | Segundos a minutos (depende del lag) |
| Tipo de failover | Automático y transparente | Manual o automatizado con scripts |
| Necesita promoción | No, todas las regiones son activas | Sí, hay que promover una secundaria |
| Consistencia global | Fuerte (ACID) | Eventual en secundarias |
La “automatización” del failover en Global Database existe, ojo. Podés configurar un evento de CloudWatch que dispare la promoción. Pero eso no cambia el hecho de que la replicación es asíncrona y siempre vas a tener un RPO mayor a cero. DSQL elimina ese problema de raíz.
¿Qué requisitos de latencia y consistencia tiene Aurora DSQL en failover?
El precio de la consistencia fuerte multi-región se paga en latencia. No existe el almuerzo gratis. Según las mediciones publicadas, una escritura simple entre regiones cercanas (ponele, us-east-1 y us-east-2) anda entre 0 y 15 ms. Cuando las regiones están en continentes distintos, la latencia sube a 30-50 ms. Son números predecibles: la velocidad de la luz manda, y ningún paper de arquitectura distribuida puede violar la relatividad.
Para transacciones complejas —joins pesados, escrituras con múltiples filas, constraints que requieren validación cruzada— la cosa cambia. Ahí hablamos de 2 a 5 veces la latencia de Aurora estándar en una sola región. Si tu app es sensible a la latencia y no necesita despliegue multi-región, DSQL probablemente no es para vos (ni debería serlo).
Lo que sí es consistente —valga la redundancia— es el modelo de consistencia en sí. Aurora DSQL garantiza ACID a nivel global, algo que muy pocas bases de datos distribuidas pueden decir sin letra chica. No hay eventual consistency, no hay “leé tu propia escritura solo si pegás en la misma réplica”. El Adjudicator asegura que todas las lecturas vean el estado más reciente de los datos, sin importar desde qué región consultes. Eso es un golazo para aplicaciones que no pueden permitirse inconsistencias temporales.
¿Qué casos de uso se benefician del failover multi-región de Aurora DSQL?
Ponele que tenés un juego online con jugadores en Asia, Europa y América. Todos escriben puntuaciones, compran items, actualizan rankings. Con una base de datos tradicional, elegís una región primaria y el resto del mundo sufre latencia. Con Global Database, si la primaria cae perdés las últimas escrituras (y posiblemente unos cuantos usuarios). Con DSQL, si Tokio se va a pique, los jugadores japoneses se reconectan automáticamente a la región más cercana sin perder una partida. Eso no es un “nice to have”, es la diferencia entre retener usuarios y perderlos para siempre.
En fintech el panorama es parecido pero con plata de por medio. Sistemas de pago que operan en múltiples países necesitan garantías de que una transacción confirmada está confirmada en serio —no “confirmada salvo que la región se caiga en los próximos 30 segundos”. DSQL te da esa garantía con RPO sub-segundo. Lo mismo para IoT industrial, donde sensores en fábricas de distintos continentes escriben datos críticos que no pueden duplicarse ni perderse. Te puede servir nuestra cobertura de la guía sobre etiquetas hreflang.
Ojo: esto no significa que DSQL reemplace a Aurora estándar para todo. Si tu app es single-region y la latencia importa más que la tolerancia a desastres regionales, quedate con Aurora común. DSQL es para cuando el negocio no tolera perder datos aunque se caiga un data center entero (y hay industrias donde eso es un requisito regulatorio, no una preferencia).
¿Cómo se planifica un failover en Aurora DSQL?
La respuesta corta: no se planifica. Eso es justamente lo que cambia. En Aurora Global Database tenías que definir regiones, configurar réplicas, establecer políticas de promoción, probar el runbook de failover cada tres meses (si es que alguien se acordaba). En DSQL, a diferencia de lo que requiere Global Database, la detección de fallas y la redistribución del tráfico son automáticas y no requieren intervención manual.
Dicho esto, hay cosas que sí tenés que hacer de tu lado. La aplicación tiene que ser tolerante a reconexiones —aunque el Router maneje la redirección, tu código debería implementar lógica de reintento con backoff exponencial. También necesitás pensar la distribución de las regiones activas en función de dónde están tus usuarios. No sirve de nada tener multi-región con failover automático si las dos regiones que elegiste están a 50 km de distancia y las afecta el mismo desastre natural.
El equipo de infraestructura tampoco se puede dormir: monitorear la latencia entre regiones, entender los costos de transferencia de datos (que con replicación síncrona global no son triviales), y tener un plan de capacity planning distinto al de una base de datos tradicional. La buena noticia es que el failover en sí —el momento de pánico en que todo depende de que alguien ejecute un comando a tiempo— desaparece del runbook.
Errores comunes al trabajar con failover en Aurora DSQL
He visto equipos cometer estos errores una y otra vez, incluso después de leer la documentación. Acá van tres que duelen particularmente.
Asumir que DSQL es un drop-in replacement de Aurora PostgreSQL
DSQL habla dialecto PostgreSQL, pero no es PostgreSQL. Tiene limitaciones en extensiones, en ciertos tipos de queries, y en el comportamiento de algunas funciones. Si migrás una app que usa extensiones como PostGIS o pg_cron sin revisar la compatibilidad, te vas a estrellar. Probá en staging antes de emocionarte. Relacionado: cómo ejecutar agentes sin API.
No medir la latencia real entre tus regiones
Los 50 ms que publica AWS son bajo condiciones controladas. Si tus regiones están en lados opuestos del planeta y tu aplicación hace tres round-trips por request, la experiencia del usuario se degrada rápido. Medí con datos reales, no con benchmarks ajenos. Y si tu frontend está hosteado en un solo lugar, el failover de la base de datos no te salva de la latencia que siente el usuario —ahí necesitás un proveedor que te dé infraestructura distribuida, como donweb.com para el hosting de la aplicación.
No implementar lógica de reintento en la aplicación
El Router de DSQL redirige el tráfico automáticamente, sí, pero tu aplicación tiene que saber qué hacer cuando una conexión se corta abruptamente. Si no tenés reintentos con backoff, vas a ver errores intermitentes en producción cada vez que haya un failover —y el usuario final va a pensar que la app “anda mal”, aunque la base de datos haya funcionado perfecto.
Si te interesa el tema, acá tenemos un artículo sobre Aurora DSQL failover.
Preguntas Frecuentes
¿Aurora DSQL soporta escrituras multi-región durante un failover?
Sí. A diferencia de Aurora Global Database —donde solo la región primaria acepta escrituras—, DSQL mantiene todas las regiones activas para lectura y escritura todo el tiempo. Cuando una región cae, las demás continúan aceptando escrituras sin interrupción. El tráfico de la región caída se redirige automáticamente a las regiones sobrevivientes.
¿Cuánto tiempo tarda el failover en Aurora DSQL?
Según el demo presentado por AWS en junio de 2026, la detección de la falla y la redirección del tráfico ocurren en milisegundos. No hay un número oficial único porque depende de la latencia de red entre regiones y de la configuración del cliente, pero el RTO (Recovery Time Objective) es consistentemente menor a un segundo en escenarios de falla total de región.
¿El failover de Aurora DSQL requiere intervención manual?
No. El Router detecta la falla de una región y redirige el tráfico automáticamente. No hay que promover réplicas, cambiar endpoints ni ejecutar comandos de failover. Esto contrasta con Aurora Global Database, donde la promoción de una región secundaria requiere acción manual o un script automatizado que alguien tiene que haber configurado previamente.
¿Qué pasa con los datos que estaban en tránsito cuando cae una región?
Las escrituras que no fueron confirmadas al cliente antes de la caída se reintentan automáticamente en otra región gracias al Journal distribuido. Las escrituras que sí fueron confirmadas ya están replicadas síncronamente en al menos otra región, así que no hay pérdida de datos. El RPO sub-segundo que mostró el demo de 2026 confirma que no se perdió ninguna transacción confirmada durante la prueba de failover.
¿Aurora DSQL es más cara que Aurora Global Database?
DSQL tiene un modelo de precios diferente, basado en unidades de capacidad (Aurora Capacity Units) que escalan automáticamente. Para despliegues multi-región con escrituras activas en todas las regiones, el costo de transferencia de datos entre regiones puede ser significativo porque la replicación es síncrona. AWS no publicó una comparativa de precios directa entre ambos servicios, pero la factura de DSQL tiende a ser más alta en escenarios de alta escritura multi-región debido a la replicación síncrona y al consenso global.
Conclusión
Aurora DSQL cambia la conversación sobre failover en bases de datos cloud. Hasta ahora, la disyuntiva era: o tolerás pérdida de datos con replicación asíncrona y failover “medio automático” (Global Database), o asumís la complejidad operativa de una base distribuida que requiere un equipo dedicado para mantenerla. DSQL demuestra que se puede tener consistencia fuerte, escrituras multi-región y failover transparente en un servicio gestionado, sin que el DBA tenga que despertarse a las 3 AM.
La contracara —porque siempre hay una— es la latencia y el costo. No es para cualquier aplicación. Si tu app es single-region y funciona bien con Aurora estándar, migrar a DSQL sería overkill caro. Pero si estás diseñando un sistema global donde perder transacciones no es una opción —fintech, gaming, IoT industrial—, DSQL es probablemente la mejor noticia que recibiste en 2026.
Fuentes
- Surviving the region you run in: failover on Aurora DSQL – Marc Brooker en dev.to — Artículo original con el análisis detallado del demo de failover y la arquitectura de DSQL.
- AWS Docs – Recuperación de desastres de Aurora Global Database — Documentación oficial sobre el failover en Global Database para contraste.
- El camino hacia Amazon Aurora DSQL – AWS Español en dev.to — Contexto técnico sobre el desarrollo y la arquitectura de Aurora DSQL.
- Aurora DSQL: cómo controlar el tiempo – CloudHastaEnLasOpa — Mediciones de latencia y análisis de performance en despliegues multi-región.