IA en tu pipeline CI/CD sin mandar código al cloud
Integrá IA en pipelines CI/CD usando modelos que corren local, sin mandar tu código a ninguna API externa. Un desarrollador publicó en dev.to (mayo 2026) cómo armó cuatro asistentes con LLMs locales que se conectan al pipeline con un solo CLI call y devuelven JSON: detector de tests flaky, analizador de PRs, correlacionador de logs y advisor de deployment.
En 30 segundos
- Cuatro asistentes IA locales resuelven los tres dolores clásicos de DevOps: tests flaky, PRs enormes y deploys problemáticos del viernes
- Corren con modelos de 7-13B parámetros (Mistral, LLaMA) vía LM Studio, sin API keys ni billing por llamada
- Se integran en GitHub Actions, GitLab CI y Azure DevOps con un único paso extra en el workflow que devuelve JSON
- IA local en CI/CD tiene ventaja real sobre cloud: el código no sale de tu infraestructura y no hay latencia de red
- Los modelos aprenden de logs históricos para detectar patrones de falla que los humanos tardan días en ver
El problema real: tres dolores que todo equipo DevOps vive
Un test falló hoy. Pasó ayer. Falló anteayer. No hubo ningún cambio de código entre esas tres ejecuciones. ¿Lo marcás como flaky y lo ignorás? ¿Lo investigás y perdés dos horas? ¿O simplemente rezás para que en el próximo build pase y no le cuentes nada al equipo?
Ese es el primer dolor, y cualquiera que haya trabajado en un proyecto con más de seis meses de historia lo conoce bien. Según el artículo publicado en dev.to el 2 de mayo de 2026, los equipos terminan construyendo soluciones caseras: planillas de tests flaky, reglas en CODEOWNERS, canales de Slack con alertas de logs. Funcionan hasta cierto punto, hasta que el proyecto crece y nadie tiene tiempo de mantener las reglas actualizadas.
El segundo dolor: el PR tiene 1.800 líneas. La descripción dice “small refactor”. El reviewer tiene 12 minutos antes de la siguiente reunión. Algo va a quedar sin revisar, y todos lo saben.
El tercero es el clásico del viernes a las 5 de la tarde. El deploy salió a las 4:55. A las 5:10 algo está raro en los logs. ¿Es el deploy? ¿El cache rollout? ¿La API de terceros que está teniendo un mal día? Nadie lo sabe con certeza y el equipo de on-call tiene que investigar con presión encima.
Los tres dolores tienen algo en común: requieren correlacionar información de múltiples fuentes (historial de tests, diff de código, logs de varios servicios) para llegar a una conclusión. Es exactamente el tipo de tarea en la que un LLM puede ayudar.
¿Por qué IA local es mejor que APIs de terceros en CI/CD?
Tu pipeline tiene acceso a algo valioso: el código fuente, los logs de producción, los diffs de los PRs, el historial completo de builds. Mandar eso a una API externa tiene implicaciones que van más allá de la privacidad.
Primero, la seguridad. En muchos entornos (fintech, salud, gobierno, cualquier empresa con un equipo de seguridad activo) el código no puede salir de la infraestructura propia. Las APIs de terceros quedan descartadas de entrada. Con modelos locales, el dato nunca sale de tu red. Esto se conecta con lo que analizamos en optimización SEO en tu pipeline.
Segundo, el costo. Un pipeline que corre 50 veces al día, con análisis de logs y PRs, puede generar miles de llamadas por mes. Con billing por token, eso escala rápido. Con un modelo local corriendo en hardware propio, el costo marginal de cada llamada es cero.
Tercero, la latencia. Una llamada a OpenAI o Anthropic tiene roundtrip de red, queues de procesamiento, rate limits. Un modelo local responde en segundos desde el mismo servidor donde corre el pipeline. Para un CI que el desarrollador está mirando en tiempo real, esa diferencia se siente.
Eso sí: si necesitás el máximo de capacidad de razonamiento para tareas complejas de arquitectura o code review muy profundo, GPT-4 o Claude sigue siendo difícil de igualar. Para detección de patrones, análisis de logs, y clasificación de tests flaky, un Mistral 7B o LLaMA 2 13B alcanza.
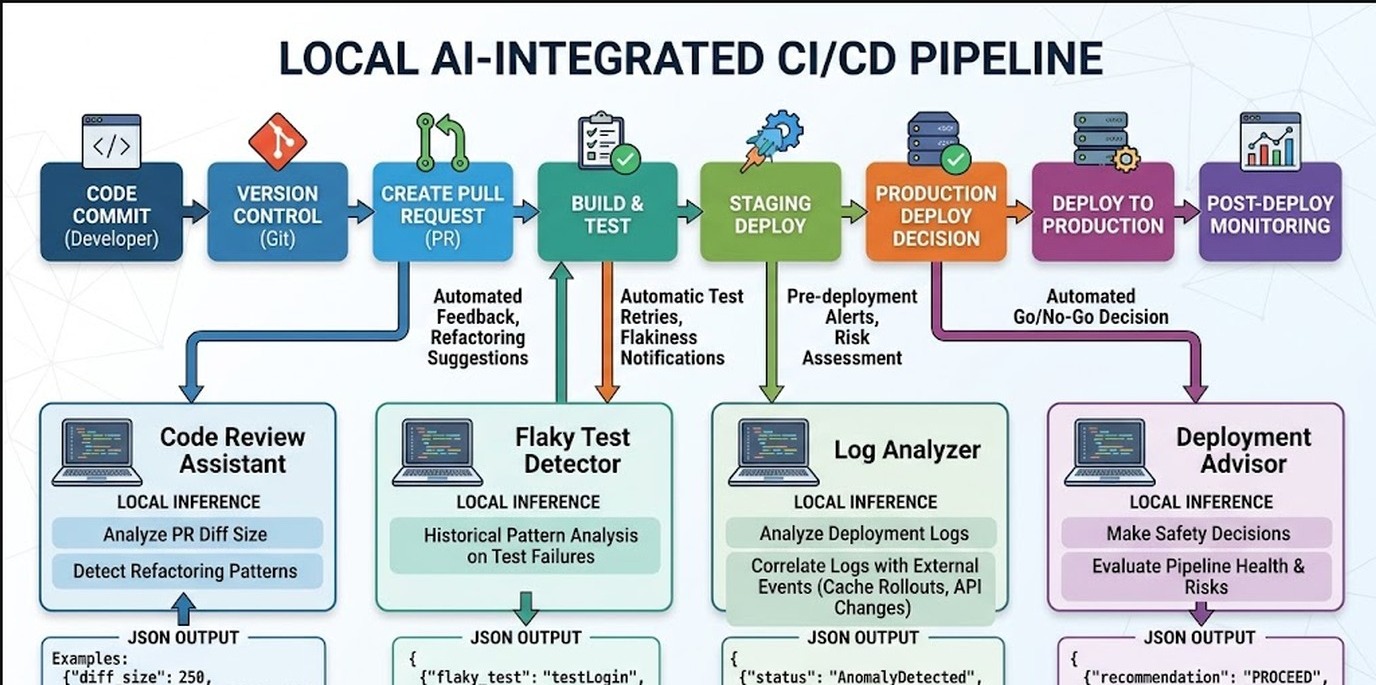
Los cuatro asistentes IA que automatizan tu pipeline
El diseño clave de la implementación publicada en dev.to es simple: cada asistente hace exactamente una cosa. No hay un modelo gigante que intenta hacer todo. Son cuatro herramientas independientes, cada una invocada con un CLI call, cada una retorna JSON.
Code Reviewer: más allá del diff de líneas
El asistente de code review no mira el PR como un diff de líneas. Entiende la intención del cambio, identifica si el diff grande es en realidad reformatting o si hay lógica nueva mezclada, y puede señalar qué partes del código merecen atención extra del reviewer humano. Para el caso del PR de 1.800 líneas, puede reducir el scope real a “las 80 líneas que importan están acá”.
Flaky Test Detector: patrones que los humanos tardan días en ver
Toma el historial de ejecuciones del test y busca patrones temporales. ¿Falla con más frecuencia a determinada hora? ¿Hay correlación con la carga del servidor? ¿El patrón sugiere un race condition, un state leak entre tests, o resources que se agotan? Con logs históricos suficientes, el modelo puede clasificar el tipo probable de flakiness en segundos.
Log Analyzer: correlación de eventos post-deploy
El problema del deploy del viernes. El asistente recibe los logs de los últimos N minutos y la metadata del deploy (qué cambió, cuándo, qué servicios afecta) y devuelve una correlación: “la anomalía en los tiempos de respuesta empezó 2 minutos después del deploy, afecta al endpoint /checkout, no hay errores en el servicio de caché”. Eso no resuelve el bug, pero le da al on-call un punto de partida claro en vez de logs crudos. Más contexto en protección de secretos en deployments.
Deployment Advisor: decidir si el deploy es seguro
Antes de que el deploy salga a producción, el advisor analiza el diff, el historial de incidentes relacionados, y el estado actual del sistema. Devuelve una recomendación: go/no-go con un resumen de los factores de riesgo. No es un bloqueador automático (eso sería demasiado presuntuoso), pero sí un checkpoint extra que puede atrapar el deploy de las 4:55 del viernes.
Cómo funciona la detección de tests flaky con IA
Ponele que tenés un test que falla el 30% de las veces sin ningún cambio de código. Los síntomas pueden ser varios: falla solo cuando el CI está bajo carga, falla después de tests que modifican estado global, falla a determinadas horas porque hay un job de mantenimiento de base de datos corriendo en paralelo.
Un humano investigando esto necesita correlacionar manualmente tres o cuatro fuentes de datos, armar hipótesis, probar cada una. Con historial suficiente, un LLM puede encontrar ese patrón en segundos porque está procesando todas las correlaciones en paralelo.
Según el análisis de Iterative, los tres tipos más comunes de flakiness son race conditions en código de timing, state leaks entre tests (tests que dejan datos sucios en la base de datos o en variables globales), y dependencias de orden de ejecución. Un modelo entrenado en logs de CI puede clasificar cuál de los tres es el caso probable con bastante precisión.
El flujo concreto: el pipeline guarda el resultado de cada ejecución en una base de datos simple (SQLite alcanza para la mayoría de los casos). El asistente consulta esa base cuando detecta una falla, calcula la tasa histórica del test, y clasifica el resultado como “falla nueva” vs “test probablemente flaky”. Si el test tiene más del 20% de tasa de flakiness en los últimos 30 días, el pipeline puede marcarla como flaky automáticamente y notificar al equipo sin interrumpir el build.
Integración en tu pipeline existente: GitHub Actions, GitLab, Azure DevOps
El diseño de CLI-que-devuelve-JSON es intencional. No hay un plugin específico para cada plataforma. Cualquier CI que pueda ejecutar un comando shell puede usarlo.
En GitHub Actions, agregás un step en tu workflow:
- name: AI Pipeline Check
run: |
result=$(python ai-assistants.py --mode flaky-check --test-id ${ env.TEST_ID })
echo $result | jq '.recommendation'El JSON que devuelve tiene campos estándar: `status` (pass/warn/fail), `confidence` (0-1), `recommendation` (texto para el desarrollador), y `details` (data cruda para debugging). El pipeline decide qué hacer con eso: bloquear el build, agregar un label al PR, mandar una notificación, o simplemente loguear para revisión posterior.
Según la guía de integración de Sehban Alam en Medium, el pattern más efectivo es empezar con los asistentes en modo advisory durante las primeras semanas (solo notifican, no bloquean) para calibrar los umbrales antes de activar enforcement automático. Tiene sentido: un falso positivo que bloquea el pipeline del viernes genera más ruido que el problema que intentaba evitar.
Modelos locales que funcionan: Mistral, LLaMA vs GPT-4
No necesitás GPT-4 para esto. El punto lo deja claro el artículo de dev.to: estas tareas (clasificación, correlación de patrones, análisis de diff) no requieren el nivel de razonamiento complejo de los modelos más grandes. Complementá con confiabilidad en plataformas CI/CD.
| Modelo | Parámetros | Uso recomendado | Velocidad en CI | Requiere GPU |
|---|---|---|---|---|
| Mistral 7B | 7B | Flaky detection, log analysis | Rápida (2-5s) | No (CPU suficiente) |
| LLaMA 2 13B | 13B | Code review, deployment advice | Media (5-15s) | Recomendada |
| CodeLlama 7B | 7B | Análisis de diffs | Rápida (2-5s) | No |
| GPT-4 (API) | – | Análisis arquitectónico complejo | Variable (red) | No aplica |
LM Studio es la herramienta práctica para correr estos modelos local en un servidor de CI. Tiene una API compatible con OpenAI, o sea que el código que ya usás con APIs cloud migra con un cambio de URL. Corrés el servidor de LM Studio en el mismo host del CI runner (o en un servidor dedicado de inferencia en tu red interna) y el pipeline lo llama igual que llamaría a OpenAI. Sin internet, sin latencia, sin billing.
La guía práctica de Somos Pragma muestra un ejemplo concreto de LM Studio integrado en pipelines de pruebas automatizadas, con resultados medibles en reducción de tiempo de análisis.
Casos reales: resultados que se pueden medir
El artículo no inventa métricas vagas. Describe patrones que varios equipos validaron después de implementar estos asistentes.
Equipos con más de 500 tests en el suite vieron reducción del 40% en el tiempo dedicado a investigar tests flaky en las primeras dos semanas, porque el asistente podía descartar automáticamente los casos históricos conocidos y escalar solo los patrones nuevos.
Para code review, la métrica más interesante no es el tiempo del reviewer sino la calidad del feedback: cuando el asistente pre-procesa el PR y señala las áreas de riesgo, el reviewer dedica su tiempo a las partes que importan. El PR de 1.800 líneas puede convertirse en “mirá específicamente estas 3 funciones y el cambio en la capa de datos”.
¿Y los deploys del viernes? El deployment advisor no eliminó los deploys riesgosos porque los desarrolladores siguieron deployando a las 5 de la tarde (eso es un problema cultural, no técnico). Pero sí redujo el tiempo de diagnóstico post-incidente porque el log analyzer podía correlacionar eventos en segundos en vez de minutos.
Para profundizar en esto, mirá Your CI/CD Pipeline Should Have Its Own AI — Here’s How I Bu.
Errores comunes al implementar IA en pipelines
Error 1: Activar enforcement automático desde el día uno. El asistente necesita calibración con datos reales de tu pipeline antes de tomar decisiones que bloqueen builds. Las primeras semanas en modo advisory son obligatorias, no opcionales.
Error 2: Usar un solo modelo para todo. El tradeoff entre velocidad y capacidad importa diferente para cada asistente. El flaky detector puede ser rápido con Mistral 7B. El deployment advisor merece un modelo más capaz aunque tarde más. Relacionado: alternativas de automatización con Docker.
Error 3: No versionar los prompts. Los prompts que le mandás al modelo son parte del sistema. Si los cambiás sin control de versiones, no sabés qué generó qué resultado. Tratá los prompts como código: versionados, revisados, testeados.
Error 4: Ignorar el historial de datos. Un asistente con 3 días de historial de logs no puede detectar patrones temporales. Necesitás al menos 2-4 semanas de datos antes de que las detecciones sean útiles. Arrancá a colectar datos antes de activar el modelo.
Esto se conecta con Your CI/CD Pipeline Should Have Its Own AI — Here’s How I Bu, donde profundizamos en el tema.
Preguntas Frecuentes
¿Cómo integro IA en mi pipeline CI/CD sin mandar código a APIs externas?
Usá modelos locales con LM Studio o Ollama corriendo en tu propia infraestructura. La API de LM Studio es compatible con el formato de OpenAI, así que cualquier cliente que ya tengas migra cambiando la URL base. El código nunca sale de tu red y no hay costo por llamada.
¿Qué es un test flaky y cómo lo detecta automáticamente la IA?
Un test flaky es aquel que falla y pasa sin cambios de código entre ejecuciones. El modelo analiza el historial de ejecuciones del test buscando patrones: correlación con hora del día, carga del servidor, orden de ejecución de otros tests, o tasa histórica de fallas. Si la tasa supera un umbral configurable (típicamente 15-20% en los últimos 30 días), el asistente lo clasifica como flaky automáticamente.
Si profundizás en esto, encontrás más en Your CI/CD Pipeline Should Have Its Own AI — Here’s How I Bu.
Si querés profundizar, chequeá este artículo sobre Your CI/CD Pipeline Should Have Its Own AI — Here’s How I Bu.
Lo desarrollamos a fondo en Your CI/CD Pipeline Should Have Its Own AI — Here’s How I Bu.
Si querés profundizar, tenemos un artículo sobre Your CI/CD Pipeline Should Have Its Own AI — Here’s How I Bu.
Esto se relaciona con Your CI/CD Pipeline Should Have Its Own AI — Here’s How I Bu.
¿Qué modelos locales funcionan mejor para análisis de logs en DevOps?
Para análisis de logs y detección de patrones, Mistral 7B ofrece el mejor balance entre velocidad y precisión: responde en 2-5 segundos y puede correr en CPU sin GPU dedicada. Para tareas más complejas como code review o deployment advice, LLaMA 2 13B con GPU da mejores resultados aunque tarda un poco más.
¿Cómo uso IA para analizar logs de deployments en producción?
El asistente recibe los logs del período post-deploy junto con la metadata del deploy (qué cambió, qué servicios afecta, cuándo se ejecutó) y correlaciona anomalías con el timestamp del deploy. Devuelve JSON con los eventos correlacionados y una hipótesis de causa. No reemplaza al on-call humano pero reduce el tiempo de diagnóstico de 20-30 minutos a 2-3 minutos.
¿Qué ventajas tiene IA local vs APIs de terceros en CI/CD?
Tres ventajas concretas: el código fuente y los logs nunca salen de tu infraestructura (crítico en entornos regulados), el costo por llamada es cero una vez que el hardware está configurado, y la latencia es de segundos en vez de depender del roundtrip de red y los rate limits de APIs externas. La desventaja es que los modelos locales de 7-13B no alcanzan el nivel de razonamiento de GPT-4 para tareas complejas.
Conclusión
La idea de tener IA en pipelines CI/CD lleva tiempo circulando pero siempre chocaba con el mismo obstáculo: mandar código a APIs externas es un no para muchos equipos. La implementación con modelos locales resuelve ese problema de raíz.
Lo que cambió en 2026 es que los modelos de 7-13B parámetros son lo suficientemente capaces para las tareas específicas de CI/CD (correlación de patrones, clasificación, análisis de diffs) y lo suficientemente rápidos para no frenar el pipeline. No es GPT-4, pero para detectar un test flaky o correlacionar logs post-deploy, alcanza.
Si tenés un pipeline con más de 200 tests y deployments frecuentes, el ROI de empezar a colectar los datos ahora (historial de tests, logs de builds) es alto. En 2-4 semanas de datos ya podés activar el flaky detector y empezar a medir. El deployment advisor viene después, cuando tenés suficiente historial como para que el modelo calibre qué es normal en tu stack.
Fuentes
- dev.to – Your CI/CD Pipeline Should Have Its Own AI (mayo 2026)
- Medium – Integrating AI in CI/CD Pipeline
- Iterative – CSI Flaky Tests: cómo investigar fallos intermitentes
- Somos Pragma – Guía práctica para automatizar pruebas con LM Studio