IA + Chaos Proxy: monitoreo sin riesgo en producción
Un ingeniero publicó el 29 de abril de 2026 en dev.to cómo construyó un agente de IA para monitorear servidores bare-metal y, para probarlo sin destruir nada en producción, construyó un proxy de caos que le miente: intercepta las llamadas Redfish y devuelve datos falsos de temperatura a 95°C, memoria agotada o CPU al 99%. El resultado es un entorno de entrenamiento seguro para ingeniería del caos de monitoreo sin tocar infraestructura real.
En 30 segundos
- El chaos proxy intercepta llamadas a la API Redfish y devuelve respuestas mutadas para simular fallos reales sin riesgo.
- El agente de IA recibe esos datos falsos y aprende a diagnosticar: memory leaks, thermal throttling, procesos desbocados.
- Redfish es el estándar DMTF para telemetría de servidores físicos (Dell iDRAC, HPE iLO, SuperMicro); devuelve JSON vía REST.
- El esquema separa el entrenamiento del agente de la infraestructura real: el proxy actúa como middleware transparente en producción.
- Herramientas similares ya existen: Toxiproxy (Shopify), Gremlin, Chaos Toolkit. La novedad acá es meter IA en el loop de decisión.
El problema: telemetría sin inteligencia accionable
Son las 3 AM. Tu Grafana parece un cuadro hecho con pintura roja al azar. Una CPU en algún servidor está al 99%. ¿Y ahora qué hacés?
Ese es el problema que describe el artículo original en dev.to: no falta telemetría, sobra. Los pipelines modernos bombean petabytes de métricas Redfish a bases de datos de series temporales, y el destino final de esa data es una alerta de Slack que todo el mundo silencia a la semana de haberla configurado. El cuello de botella no es la cantidad de datos, es que esos datos no te dicen qué hacer.
La diferencia entre datos y inteligencia accionable es enorme. Saber que la memoria está al 94% no te sirve de nada si no sabés qué proceso la consume, si es un leak o un spike normal, y si conviene matar el proceso o reiniciar el servidor. Un agente de IA en el loop puede cerrar ese gap, pero para entrenarlo necesitás servidores rotos. Y nadie quiere explicarle a su proveedor de hosting por qué funde deliberadamente un bare-metal.
Ahí nace la idea del chaos proxy.
¿Qué es un chaos proxy y cómo funciona en ingeniería del caos de monitoreo?
La ingeniería del caos es la práctica de introducir fallos controlados en un sistema para evaluar su resiliencia. Netflix la formalizó en 2011 con Chaos Monkey, que apagaba instancias al azar en producción para forzar a los equipos a diseñar sistemas tolerantes a fallos. Desde entonces evolucionó hacia algo mucho más quirúrgico.
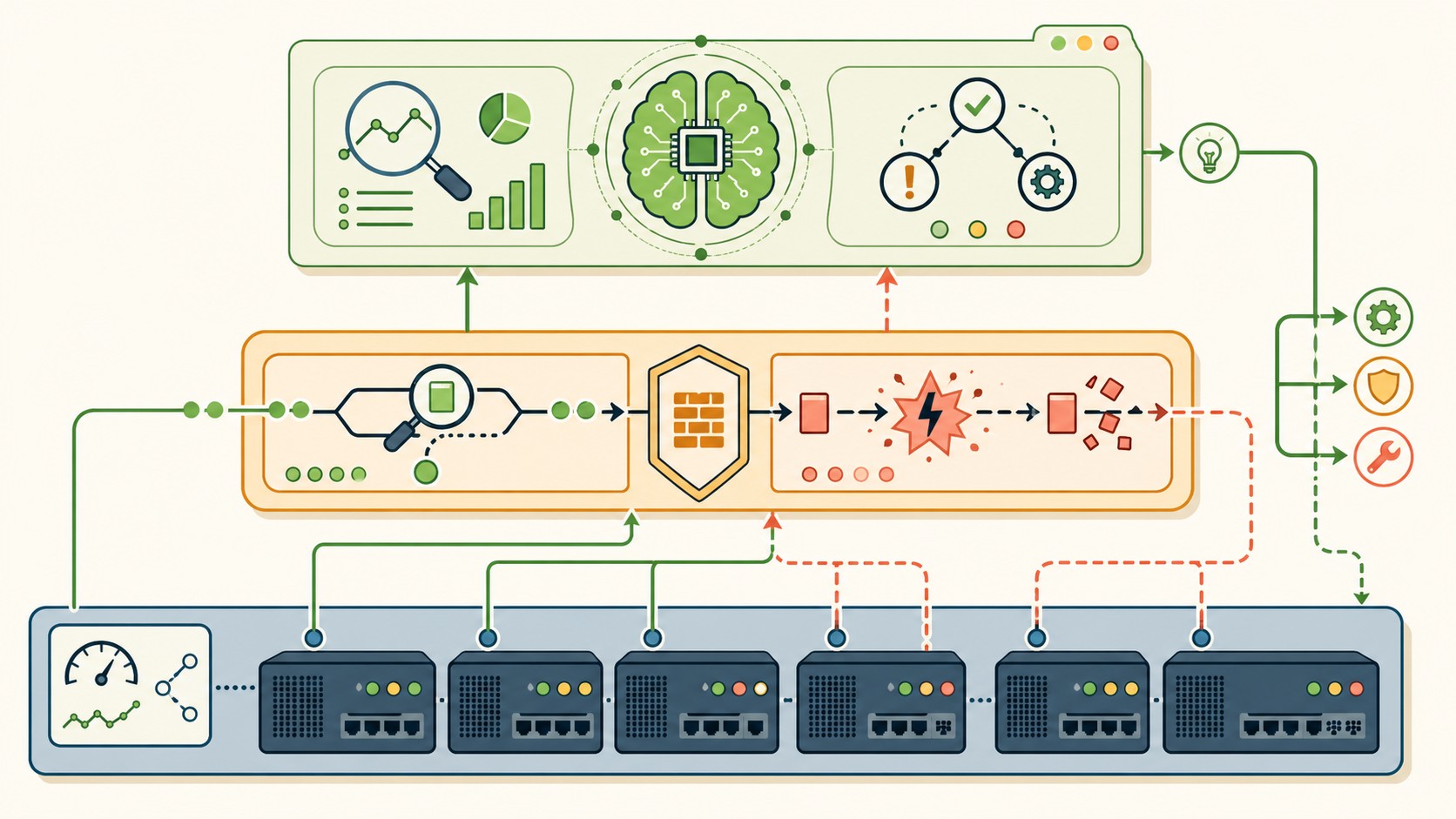
Un chaos proxy es un middleware que se posiciona entre tu herramienta de monitoreo y la infraestructura real. En modo normal, deja pasar todo sin modificar. En modo caos, intercepta las respuestas y las muta: cambia valores, simula latencias, devuelve errores HTTP 503, reporta temperaturas imposibles. Lo explicamos a fondo en qué modelo de IA elegir.
Lo concreto del proyecto descripto: el proxy intercepta llamadas a la API Redfish y, según reglas configurables, devuelve respuestas falsas. Un request a GET /chassis/1/sensors puede devolver temperatura 95°C en vez de los 42°C reales. El agente de IA recibe esa respuesta, la procesa y decide qué hacer (sugerir un reboot, alertar al equipo, cambiar el balanceo de carga). Sin ningún servidor real sufriendo.
Redfish: el estándar que no todo el mundo conoce
Si trabajás con servidores físicos y nunca usaste Redfish, te estás perdiendo algo útil. Redfish es el estándar abierto del DMTF para gestión de infraestructura de servidores vía REST/JSON. Funciona en Dell iDRAC, HPE iLO, SuperMicro BMC, y prácticamente cualquier servidor de gama empresarial fabricado desde 2015.
Con un simple GET a la dirección del BMC podés obtener estado de CPU, uso de memoria, temperatura de componentes, estado de discos, logs del sistema y hasta encender o apagar el servidor. Todo en JSON estándar, sin agentes propietarios ni protocolos raros.
Eso lo hace ideal para un agente de IA: estructura predecible, protocolo HTTP, respuestas parseables. El chaos proxy aprovecha exactamente eso, ya que si las respuestas son JSON estándar, mutar esos JSON para simular fallos es relativamente simple de implementar.
Arquitectura: dos capas que se complementan
La arquitectura del sistema tiene dos componentes principales que conviene entender por separado antes de verlos juntos.
El agente de IA
Monitorea los servidores consultando Redfish periódicamente. Cuando detecta una anomalía, no solo la reporta: analiza el contexto, cruza métricas y sugiere una acción concreta. La idea descripta en el proyecto es que el agente pueda decir algo así como “Server 3 tiene un memory leak activo. Sugiero reboot graceful. ¿Confirmo?” en vez de simplemente tirar una alerta roja en un dashboard que nadie mira. En herramientas inteligentes para automatizar profundizamos sobre esto.
El Chaos Management Proxy
Se interpone entre el agente y los servidores reales. En producción, actúa como proxy transparente: pasa todo sin tocar nada. En modo testing, aplica reglas configurables que determinan qué respuestas mutar y cómo. Podés definir: “cada 5 requests al sensor de temperatura, devolvé 95°C”, “simular un spike de CPU al 99% en el servidor 2”, “reportar memoria disponible en 2% para el servidor 1”.
El agente no sabe que está recibiendo datos falsos (que es exactamente el punto). Aprende a responder a esas condiciones como si fueran reales, y cuando lleguen a producción, ya tiene el entrenamiento. Tomalo con pinzas: esto no reemplaza pruebas con hardware real, pero cubre un porcentaje alto de escenarios sin el riesgo.
Escenarios de fallo que podés simular
Ponele que querés entrenar al agente para responder a un memory leak progresivo. Configurás el proxy para que cada request de memoria devuelva un valor 3% más alto que el anterior, hasta llegar al 98%. El agente ve el incremento gradual, correlaciona con los procesos corriendo, y en algún punto decide actuar. Podés ver exactamente dónde del proceso de decisión el agente se queda corto o sobre-reacciona.
Otros escenarios útiles que el proxy puede simular: thermal throttling donde el servidor baja el clock de CPU por temperatura, un RAID degradado (un disco del array reporta errores de lectura), latencia alta en red interna, o una fuente de poder que reporta voltaje fuera de rango. Cada uno dispara una respuesta diferente del agente, y vos podés evaluar si esa respuesta tiene sentido antes de que el fallo real aparezca.
¿El agente va a responder perfectamente a todos los casos la primera vez? No. Eso es exactamente por qué necesitás el proxy. Relacionado: configurar infraestructura multiidioma.
Herramientas de chaos engineering que ya existen en 2026
El proyecto de dev.to construye su proxy a medida, pero el ecosistema de herramientas de chaos engineering ya está bastante maduro. Vale la pena conocer qué hay disponible antes de reinventar la rueda, según el relevamiento de Paradigma Digital.
| Herramienta | Tipo de fallo | Casos de uso | Licencia |
|---|---|---|---|
| Toxiproxy (Shopify) | TCP/HTTP: latencia, errores, desconexiones | Testing de microservicios y dependencias de red | Open source (MIT) |
| Gremlin | Multi-infraestructura: CPU, memoria, red, disco | Kubernetes, VMs, bare-metal | SaaS comercial |
| Chaos Toolkit | Framework Python extensible | Kubernetes, serverless, APIs | Open source (Apache 2.0) |
| Litmus | Fallos en pods Kubernetes | CI/CD pipelines, cloud-native | Open source (Apache 2.0) |
| Chaos Proxy custom | Redfish / protocolos específicos | Servidores bare-metal con BMC | Depende de la implementación |
Toxiproxy de Shopify es probablemente la opción más directa para empezar: open source, bien documentado, y permite simular latencia, timeouts y cortes de red entre componentes. El problema es que opera a nivel TCP/HTTP, no específicamente sobre el protocolo Redfish. Para telemetría de servidores físicos, un proxy a medida como el del proyecto tiene más sentido.
Qué significa esto para equipos que gestionan infraestructura
Si administrás servidores bare-metal para e-commerce, SaaS, o cualquier carga de trabajo sensible, el patrón descripto acá tiene implicaciones prácticas. Primero, podés entrenar y evaluar herramientas AIOps antes de ponerlas en contacto con tus servidores reales. Segundo, podés documentar la respuesta esperada del sistema ante cada tipo de fallo, que es exactamente lo que te va a pedir un auditor de seguridad o un SLA enterprise.
Para infraestructura hosteada en Argentina, donde muchos equipos trabajan con servidores dedicados de proveedores como donweb.com o con hardware propio en datacenter, el acceso a Redfish depende del BMC del hardware. Si tu servidor lo soporta (la mayoría de los Dell y HPE de los últimos ocho años lo hacen), el patrón es implementable sin cambios de infraestructura.
El tema es que construir el agente de IA que tome decisiones correctas lleva tiempo y requiere datos de entrenamiento que no tenés si nunca rompiste nada en producción. El chaos proxy resuelve exactamente ese problema: generá los datos de entrenamiento en un entorno controlado, sin sudar frío a las 3 AM.
Errores comunes al implementar chaos engineering
Hacer chaos engineering directamente en producción sin blast radius definido
Chaos engineering no significa romper cosas al azar. Netflix define el “radio de explosión” antes de cualquier experimento: qué porcentaje de tráfico puede afectar, en qué horario, con qué métricas de abort. Si empezás inyectando fallos en producción sin esos límites, no es un experimento, es un incidente.
Confundir el proxy con el agente
El chaos proxy y el agente de IA son componentes separados con responsabilidades distintas. Un error frecuente es meterle lógica de decisión al proxy (“si temperatura mayor a X, entonces…”). El proxy muta datos. Las decisiones las toma el agente. Mantener esa separación es lo que hace que el sistema sea testeable: podés cambiar el agente sin tocar el proxy, y viceversa.
Asumir que pasar el testing con chaos proxy garantiza comportamiento en producción
El proxy simula respuestas Redfish mutadas, pero no simula la complejidad real de un servidor físico que se está descomponiendo. Un memory leak real puede tener firmas más sutiles que un valor al 98% de golpe. Los resultados del agente entrenado en el proxy son un punto de partida, no un certificado. Combinalo con staging en hardware real cuando sea posible. Esto se conecta con lo que analizamos en incidentes reales en plataformas.
Preguntas Frecuentes
¿Qué es un chaos proxy y por qué necesito uno?
Un chaos proxy es un middleware que intercepta comunicaciones entre sistemas y muta las respuestas para simular fallos. Lo necesitás cuando querés evaluar cómo responde tu sistema de monitoreo o tu agente de IA ante condiciones críticas (memoria agotada, CPU al 99%, temperaturas extremas) sin poner en riesgo infraestructura real. Es una capa de indirección que convierte el riesgo de un fallo real en un experimento controlado.
¿Cómo funciona Redfish para monitorear servidores con IA?
Redfish es el estándar DMTF para gestión de servidores físicos vía REST/JSON, disponible en el BMC del hardware (Dell iDRAC, HPE iLO, SuperMicro). Un agente de IA consulta los endpoints Redfish periódicamente para obtener métricas de CPU, memoria, temperatura y estado de componentes. Al recibir JSON estructurado, el agente puede correlacionar métricas y tomar decisiones: sugerir reinicios, identificar procesos problemáticos, o escalar alertas con contexto real.
¿Cómo hacer testing del caos sin afectar producción?
La estrategia más segura es usar un proxy entre tu herramienta de monitoreo y los servidores reales, configurado para inyectar fallos solo en entornos de testing. En producción, el proxy opera como passthrough transparente. Alternativas open source como Toxiproxy (para TCP/HTTP) o Chaos Toolkit (para Kubernetes y APIs) permiten hacer lo mismo a nivel de red. La clave es definir el blast radius antes: qué porcentaje de requests mutás, con qué frecuencia, y qué métrica dispara el abort del experimento.
¿Qué herramientas de chaos engineering existen para servidores bare-metal?
Para servidores físicos con BMC, las opciones son más limitadas que en Kubernetes. Toxiproxy (open source, Shopify) maneja fallos de red. Gremlin soporta bare-metal además de cloud y containers, con una interfaz más completa pero modelo SaaS de pago. Para Redfish específicamente, un proxy a medida tiene más control sobre las métricas que querés mutar. Chaos Toolkit tiene conectores para varios protocolos y se puede extender con Python para cubrir Redfish si ninguna de las opciones anteriores cubre el caso de uso exacto.
¿Qué es la inteligencia accionable en DevOps y en qué se diferencia del monitoreo tradicional?
El monitoreo tradicional te dice qué está pasando: CPU al 94%, memoria en 97%, temperatura en 88°C. La inteligencia accionable te dice qué hacer: “este proceso específico tiene un leak progresivo desde hace 20 minutos, el patrón coincide con el que tuviste en octubre pasado, y la acción que funcionó entonces fue matar el proceso Y y reiniciar el servicio Z”. La diferencia no es de datos sino de contexto, correlación y recomendación. Un agente de IA en el loop puede cerrar ese gap si tiene suficiente historial de incidentes para reconocer patrones.
Esto se conecta con I Built an AI to Monitor Servers. Then I Built a Chaos Proxy, donde cubrimos el tema en profundidad.
Esto se conecta con I Built an AI to Monitor Servers. Then I Built a Chaos Proxy, donde cubrimos el tema en detalle.
Conclusión
El proyecto descripto por Ajay Agrawal en dev.to resuelve un problema concreto: cómo entrenar un agente de IA para tomar decisiones sobre infraestructura crítica sin arriesgar esa infraestructura en el proceso. La combinación de agente que consulta Redfish más un proxy que muta esas respuestas crea un entorno de simulación con el nivel de realismo suficiente para que el entrenamiento sea útil.
Lo que me parece más valioso de este approach no es la tecnología sino el principio: separar el entrenamiento del entorno real mediante una capa de indirección. Eso aplica más allá de Redfish, ya sea para APIs de cloud, métricas de aplicaciones, o cualquier sistema donde querés que un agente aprenda a responder a condiciones que no podés reproducir fácilmente sin consecuencias.
Si administrás infraestructura bare-metal, el patrón vale la pena explorar. El tooling existe (Toxiproxy, Gremlin, Chaos Toolkit), la API Redfish está en hardware que probablemente ya tenés, y el costo de implementar un proxy básico es mucho menor que el costo de un incidente de producción que tu sistema de monitoreo no supo manejar.