Kafka cloud-native 2026: diskless, Share Groups y más
La arquitectura cloud-native de Kafka está pasando por un cambio profundo en 2026: desde almacenamiento en disco local con capas (tiered storage, KIP-405) hacia un modelo completamente sin disco (diskless, KIP-1150), con clusters virtuales para multi-tenancia y Share Groups para escalar consumidores más allá del límite de particiones. Según el análisis publicado por InfoQ el 26 de mayo de 2026, estas cuatro evoluciones juntas redefinen cómo las plataformas de streaming manejan costos, operaciones y escala en la nube.
En 30 segundos
- KIP-1150 (Kafka diskless) fue aprobado en marzo de 2026 y ya tiene implementaciones en producción: WarpStream, AutoMQ y Aiven Inkless.
- Con tiered storage (KIP-405), equipos que implementaron KIP-405 en 2026 reportan reducciones de costo de hasta un 90% al mover datos fríos a S3/GCS en lugar de mantener disco local.
- Los Share Groups (GA en 2026) permiten escalar consumidores sin aumentar el número de particiones, resolviendo uno de los límites históricos de Kafka.
- KIP-848 (nuevo protocolo de rebalanceo) hace que el escalado en Kubernetes sea mucho menos doloroso: sin “stop-the-world” en el consumer group completo.
- El cambio de modelo económico de infraestructura fija a API calls por acceso hace que los patrones de consumo ineficientes se vuelvan caros, y obliga a más observabilidad por tenant.
Qué es Kafka cloud-native y por qué el modelo clásico ya no alcanza
Apache Kafka cloud-native es la evolución del broker de mensajería de streaming que desacopla el almacenamiento del cómputo para aprovechar los servicios managed de la nube (S3, GCS, Azure Blob) en lugar de depender de discos locales atados a cada broker. El Kafka clásico nació para correr en bare metal con discos NVMe dedicados. Cada partición vive en el disco del broker que la lidera. Eso funcionó bien cuando el hardware era el cuello de botella. El problema es que en un entorno cloud, ese modelo te obliga a sobredimensionar almacenamiento y cómputo juntos aunque necesites escalar solo uno de los dos.
Ponele que tenés un pico de ingesta de eventos a las 3 AM. Necesitás más throughput de procesamiento, pero el almacenamiento histórico está fijo en los brokers. No podés escalar uno sin el otro. Ahí está la fricción.
Los drivers principales que empujaron esta evolución son tres: costos operativos, escalabilidad elástica y complejidad operacional. En 2026, con KIP-405 maduro, KIP-1150 aprobado, KIP-848 disponible y Share Groups en GA, hay una respuesta concreta para cada uno.
Desagregación de almacenamiento: cuando el modelo económico cambia completamente
El cambio más importante no es técnico, es económico. Cuando Kafka usa almacenamiento local, el costo es fijo: pagás el hardware o la instancia cloud con disco, y ese costo existe independientemente de cuánto lo usés. Con la desagregación hacia S3 o GCS, el modelo pasa a ser por uso: pagás por cada llamada de API, por cada byte transferido, por cada request de lectura.
Eso suena bien hasta que un consumidor hace un replay masivo de eventos históricos. En el modelo viejo, ese replay no te costaba nada extra. Con APIs de object storage, podés generar un spike de factura importante con visibilidad casi nula (si no tenés observabilidad por consumer o tenant, no sabés de dónde vino el gasto).
El punto es que la desagregación cambia los incentivos. Los patrones de acceso ineficientes que antes eran un problema de performance ahora son un problema de factura. Las plataformas que adopten este modelo van a necesitar visibilidad de costos a nivel de consumer group, no solo a nivel de cluster.
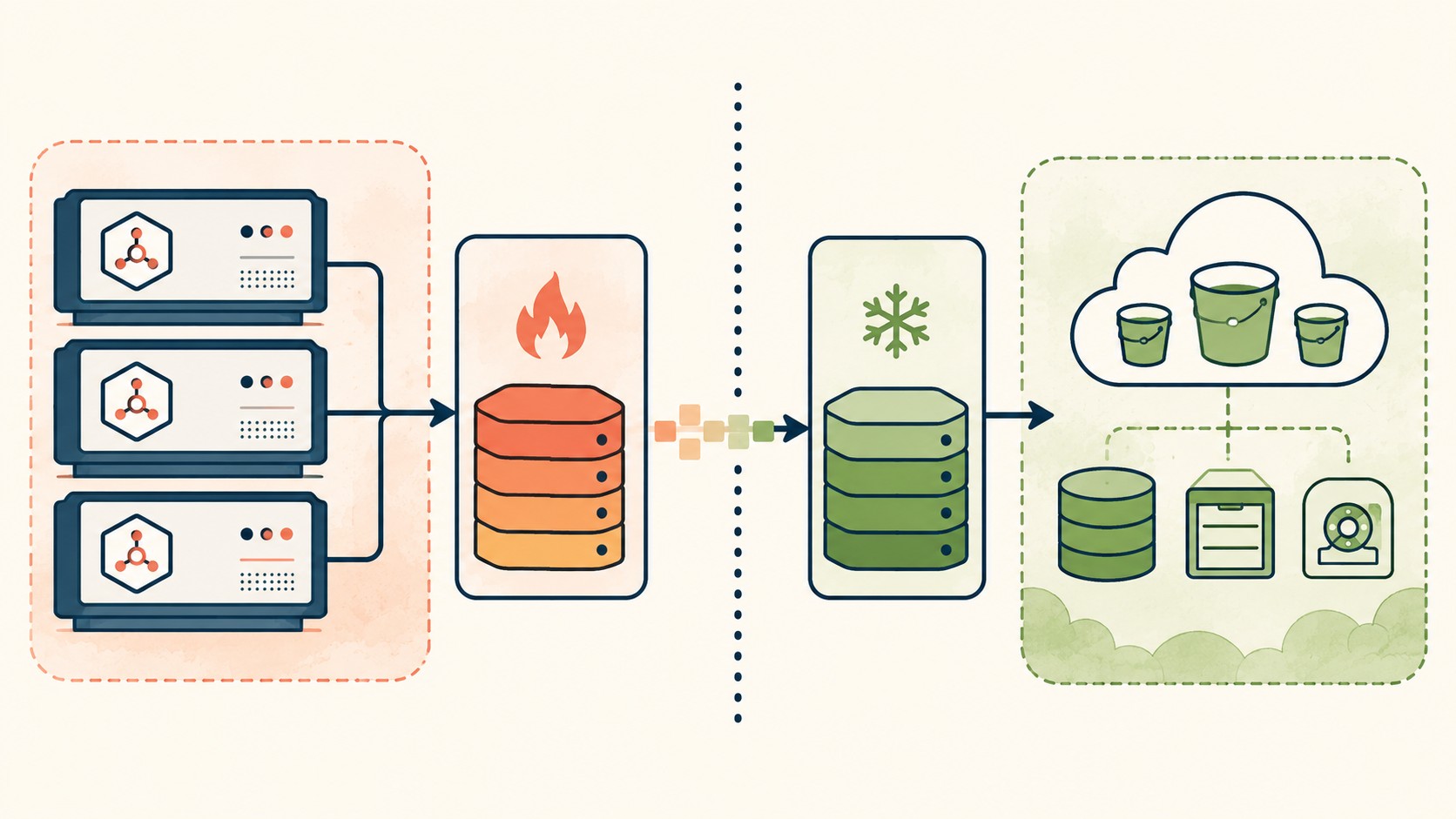
Almacenamiento en capas (KIP-405): tiered storage en la práctica
KIP-405 es la primera implementación de desagregación en Kafka mainstream. La idea es simple: los datos recientes (tier caliente) se mantienen en disco local del broker para acceso de baja latencia. Los datos históricos (tier frío) se mueven automáticamente a object storage como S3 o GCS.
La configuración define un tiempo de retención en el tier caliente y el resto va a S3. Para la mayoría de los workloads de streaming, los consumidores activos leen del tier caliente y nunca tocan el frío. Solo los replays históricos y los analytics van al tier frío.
Los números que reportan equipos que implementaron KIP-405 en 2026 son llamativos: reducciones de costo entre el 66% y el 90% comparado con mantener todo en disco local. La variación depende del ratio entre datos activos y datos históricos que tengas. Si tenés 7 días de retención activa pero guardás 90 días históricos, el ahorro es enorme.
Eso sí: la latencia de lectura del tier frío es mayor. Para replays ocasionales no es problema. Para consumidores que necesitan leer datos de hace 2 semanas regularmente, vas a sentir la diferencia.
Kafka sin disco (KIP-1150): el paso siguiente aprobado en 2026
KIP-1150 va más lejos que el tiered storage: elimina el disco local del broker completamente. Todo el almacenamiento vive en object storage desde el momento cero. El broker se convierte en un componente de cómputo puro que orquesta producers y consumers sin almacenar nada localmente.
Según el análisis de AutoMQ publicado en 2026, KIP-1150 fue aprobado formalmente en marzo de 2026. Las implementaciones que ya existían antes de la aprobación formal incluyen WarpStream (Confluent), AutoMQ y Aiven Inkless. Estas tres apostaron a la arquitectura diskless antes de que el KIP se aprobara oficialmente.
¿Y qué perdés con diskless? Latencia de escritura. El disco local de un broker bien configurado tiene latencias de microsegundos. S3 tiene latencias de decenas de milisegundos. Para workloads donde el P99 de latencia importa mucho, diskless puede no ser la elección correcta hoy.
| Característica | Kafka clásico | Tiered Storage (KIP-405) | Diskless (KIP-1150) |
|---|---|---|---|
| Almacenamiento | Solo disco local | Disco local + S3/GCS para histórico | Solo object storage (S3/GCS) |
| Latencia de escritura | Microsegundos | Microsegundos (tier caliente) | Decenas de milisegundos |
| Costo infraestructura | Alto (disco sobredimensionado) | Medio (66-90% reducción en almacenamiento) | Bajo (solo cómputo + API calls) |
| Escalado independiente | No | Parcial | Completo |
| Complejidad operacional | Alta | Media | Baja |
| Madurez en 2026 | Producción | Producción | GA en implementaciones específicas |
Multi-tenancia con clusters virtuales (KIP-1134): aislamiento sin duplicar infraestructura
La multi-tenancia en Kafka siempre fue un dolor. Tenés dos opciones históricas: un cluster dedicado por equipo (costoso, operacionalmente pesado) o un cluster compartido con aislamiento débil (namespaces via prefijos de topic, quotas que nadie termina de configurar bien).
KIP-1134 propone clusters virtuales: múltiples tenants sobre el mismo cluster físico, pero con aislamiento a nivel de metadatos, red y quotas que funciona como si cada tenant tuviera su propio cluster. Cada tenant ve sus propios topics, sus propios consumer groups, sus propias configuraciones. No ven los topics del tenant de al lado.
Según la implementación de Zilla para virtual clusters, la separación de namespaces permite que equipos diferentes operen su “Kafka” sin coordinación operacional entre ellos, pero sobre la misma infraestructura física. Las quotas de ancho de banda y storage se asignan por tenant virtual.
El caso de uso más claro es plataformas multi-equipo en empresas medianas y grandes. Antes tenías que elegir entre darle a cada equipo un cluster separado (3-5 brokers mínimo, un ZooKeeper o KRaft controller aparte, monitoreo separado) o meterlos a todos juntos y rezar para que nadie haga un bug que sature el cluster para todos.
Share Groups: escalado de consumidores más allá del límite de particiones
Si alguna vez configuraste Kafka y te encontraste con consumers idle porque el número de consumers superaba el número de particiones, sabés exactamente cuál es el problema que Share Groups resuelve.
El consumer group clásico de Kafka tiene una limitación de diseño: cada partición solo puede ser procesada por un consumer a la vez. Querés más paralelismo, tenés que aumentar las particiones. Eso tiene costos operacionales: rebalanceo, redistribución de liderazgo, impacto en producers.
Share Groups (GA en 2026 según el anuncio de Confluent) cambia eso: distribuye records individuales entre múltiples consumers sobre las mismas particiones. Es semántica de cola (queue semantics) sobre la infraestructura de Kafka. Varios workers pueden procesar mensajes de la misma partición en paralelo, con acknowledgment por record.
Los casos de uso donde esto brilla son procesamiento de tareas (task queues), pipelines de ML donde varios workers procesan inference en paralelo, y cualquier workload donde el throughput de procesamiento sea el cuello de botella pero no querés multiplicar particiones.
Lo que no cambia: el orden dentro de una partición deja de estar garantizado cuando múltiples consumers la acceden via Share Groups. Si el orden es crítico para vos, Share Groups no es la opción.
KIP-848: rebalanceo sin parar todo el mundo
El protocolo de rebalanceo clásico de Kafka era infame entre los que corrían consumer groups en Kubernetes. Cuando se añadía o removía un consumer, el grupo entero pausaba el procesamiento durante el rebalanceo. En un entorno de autoscaling donde los pods se añaden y quitan constantemente, eso generaba interrupciones frecuentes.
KIP-848 implementa un protocolo cooperative incremental donde solo los consumers afectados por el cambio reasignan particiones. El resto sigue procesando. Para escalado en Kubernetes con KEDA o HPA, esto cambia mucho: podés añadir consumers sin impactar a los que ya están corriendo.
La diferencia práctica: con el protocolo viejo, un deploy rolling que cambia 10 pods genera 10 rebalanceos con pausa global. Con KIP-848, cada pod que entra o sale genera una reasignación local sin afectar al resto del grupo.
El impacto económico: FinOps y observabilidad en arquitecturas cloud-native
La desagregación de almacenamiento convierte los patrones de acceso en costos variables. Eso es bueno si sos eficiente, y es un problema si no tenés visibilidad.
Cuando un equipo hace un replay de 30 días de eventos para debuggear un bug de producción, en el modelo clásico el costo ya estaba pagado (el disco estaba ahí). Con S3 como backend, ese replay genera miles de API calls y transfer costs. Sin observabilidad por consumer group o tenant, el bill llega a fin de mes y no sabés de dónde vino el gasto.
Las plataformas que adopten arquitectura cloud-native de Kafka en 2026 van a necesitar instrumentación a nivel de consumer: cuántos bytes lee cada consumer, desde qué offset, con qué frecuencia. Eso no era importante antes. Ahora es parte del FinOps de la plataforma.
Para equipos que corren su propia infraestructura de Kafka en cloud (en lugar de servicios managed), si usás VPS o servidores dedicados para los brokers, el modelo de costos cambia con diskless: necesitás menos almacenamiento local pero más ancho de banda hacia object storage. Proveedores como donweb.com ofrecen opciones de VPS que se pueden configurar específicamente para ese perfil de uso.
Qué está confirmado / Qué todavía no
- Confirmado: KIP-1150 (diskless) aprobado formalmente en marzo de 2026, según la documentación oficial de Apache Kafka.
- Confirmado: Share Groups en GA en 2026 (anunciado por Confluent).
- Confirmado: WarpStream, AutoMQ y Aiven Inkless tienen implementaciones diskless en producción.
- Confirmado: KIP-848 (nuevo protocolo de rebalanceo) disponible en versiones recientes de Kafka.
- No confirmado: KIP-1134 (virtual clusters) aún es un KIP en discusión en la comunidad, no está en el core de Apache Kafka todavía.
- No confirmado: Los benchmarks de reducción de costo del 90% son de implementaciones específicas (AutoMQ). Los resultados van a variar según el workload y el proveedor de object storage.
- Habría que ver: La adopción de diskless puro en workloads de alta frecuencia con requisitos de baja latencia P99. Los números de latencia en producción real son escasos.
Errores comunes al migrar a Kafka cloud-native
Ignorar la visibilidad de costos hasta que llega la factura
El error más frecuente: implementar tiered storage o diskless sin instrumentar qué consumer está haciendo qué accesos. Un solo job de replay o analytics sin throttling puede generar un spike de costos de S3 que duplica la factura mensual. Antes de habilitar tiered storage en producción, configurá alertas de costos por consumer group y entendé cuál es el patrón de acceso histórico de cada aplicación.
Asumir que Share Groups preservan el orden
Share Groups distribuyen records entre múltiples consumers de la misma partición. Eso rompe el orden de procesamiento que Kafka garantizaba en el consumer group clásico. Si tenés un pipeline donde el orden de eventos importa (transacciones financieras, eventos de estado que tienen dependencias causales), activar Share Groups sin pensar en esto va a generar bugs difíciles de reproducir en producción.
Migrar a diskless sin evaluar los requisitos de latencia
Diskless es excelente para workloads donde la latencia de escritura de decenas de milisegundos es aceptable. Pero si tenés producers que requieren ACK en menos de 5ms, el tier de object storage va a ser un cuello de botella. Medí los requisitos de latencia de tus producers antes de commitear a una arquitectura diskless. Para muchos casos de datos históricos y analytics está perfecto. Para event streaming de alta frecuencia financiero, todavía no.
Usar prefijos de topic como sustituto de virtual clusters
El patrón de “team-a-topic-name” y “team-b-topic-name” con quotas manuales no es multi-tenancia real. Un consumer de team-a que tenga credenciales incorrectas puede acceder a topics de team-b. Las quotas por prefijo son frágiles y no se aplican de forma automática. Si tu caso de uso requiere aislamiento entre equipos, esperá la implementación de KIP-1134 o usá soluciones como Zilla para virtual clusters, no hacks de nombres.
Preguntas Frecuentes
¿Cómo funciona el almacenamiento en capas en Kafka?
El almacenamiento en capas (KIP-405) mantiene los datos recientes en disco local del broker para acceso de baja latencia (tier caliente) y mueve automáticamente los datos históricos a object storage como S3 o GCS (tier frío). Los consumidores activos leen del tier caliente sin diferencia de latencia. Los replays históricos y los jobs de analytics acceden al tier frío con latencia mayor pero costo de almacenamiento hasta un 90% inferior al mantener todo en disco local.
¿Cuánto puedo ahorrar con Kafka sin disco en AWS?
Depende del ratio entre datos activos e históricos que tengas. Implementaciones como AutoMQ reportan reducciones de costo entre el 66% y el 90% comparado con Kafka clásico con disco local. El ahorro viene de dos lados: el almacenamiento en S3 es mucho más barato que EBS, y podés escalar cómputo independientemente de almacenamiento. El costo variable (API calls a S3) puede subir si tenés patrones de acceso histórico frecuentes sin throttling.
¿Qué son los clusters virtuales y cómo se implementan en Kafka?
Los clusters virtuales (KIP-1134) son abstracciones de multi-tenancia que permiten que múltiples equipos operen su propio “Kafka” con aislamiento completo de topics, consumer groups y configuraciones, sobre la misma infraestructura física. Cada tenant ve solo sus propios recursos. En 2026, la implementación más madura está en Zilla (Aklivity), no en el core de Apache Kafka, donde KIP-1134 todavía está en proceso de adopción en la comunidad.
¿Cómo escalar consumidores más allá del número de particiones en Kafka?
Con Share Groups (GA en 2026), múltiples consumers pueden procesar records de la misma partición en paralelo, distribuyendo mensajes a nivel de record en lugar de a nivel de partición. Esto permite escalar el número de consumers independientemente del número de particiones. El tradeoff es que el orden de procesamiento dentro de una partición deja de estar garantizado, lo cual no es aceptable para todos los workloads.
¿Kafka sin disco funciona bien en Kubernetes?
Para la mayoría de los workloads, sí. La combinación de diskless con KIP-848 (nuevo protocolo de rebalanceo cooperative incremental) hace que el escalado automático en Kubernetes sea mucho más práctico que con Kafka clásico: podés usar KEDA o HPA para escalar pods según lag de consumer sin generar stop-the-world rebalanceos en el grupo completo. El cuello de botella sigue siendo la latencia de escritura hacia object storage, que no es apta para casos con requisitos de P99 de milisegundos.
Conclusión
En 2026, la arquitectura cloud-native de Kafka dejó de ser un roadmap para convertirse en opciones concretas disponibles en producción. KIP-405 para tiered storage ya está maduro. KIP-1150 (diskless) tiene implementaciones reales en WarpStream, AutoMQ y Aiven Inkless. Share Groups llegó a GA. KIP-848 hace que Kubernetes deje de ser un contexto hostil para Kafka.
¿Significa esto que tenés que migrar ahora? Depende. Si corrés Kafka clásico con disco y tu principal problema es el costo de almacenamiento de datos históricos, tiered storage con S3 es el cambio más fácil con el mejor ROI inmediato. Si construís algo nuevo y la latencia de escritura de decenas de milisegundos es aceptable para tu caso de uso, diskless tiene mucho sentido desde el día uno. Si tenés múltiples equipos sobre el mismo cluster, empezá a evaluar virtual clusters aunque aún no estén en el core de Apache Kafka.
Lo que sí tiene que cambiar ahora, independientemente de qué path tomés, es la observabilidad de costos. El modelo de API-per-access cobra caro la deuda de visibilidad.
Fuentes
- InfoQ – Architecting Cloud-Native Kafka: From Tiered Storage Towards a Diskless Future (mayo 2026)
- Apache Kafka – Tiered Storage Design (documentación oficial)
- Confluent – Share Consumer GA announcement 2026
- AutoMQ – Rise of Diskless Kafka: Industry Trend Analysis 2026
- Aklivity – Virtual Clusters en Zilla para multi-tenancia en Kafka