Laravel: arreglá los memory leaks en tus queue workers
Los workers de Laravel corriendo en modo daemon acumulan memoria con cada job que procesan: static variables, singleton instances, caches de Eloquent que nunca se liberan. Cuando el proceso llega al límite (típicamente 128MB o 256MB), se produce el fatal Allowed memory size exhausted y el worker cae sin aviso. La solución no es aumentar RAM sino configurar reinicios automáticos con --max-jobs, --max-time y Supervisor.
En 30 segundos
php artisan queue:workcorre como daemon: el proceso PHP nunca muere, lo que hace que la memoria suba con cada job procesado.- El flag
--max-jobs=500reinicia el worker cada 500 jobs;--max-time=3600lo reinicia cada hora. Usarlos juntos es lo correcto. - Supervisor en Ubuntu gestiona el reinicio automático: si el worker cae, Supervisor levanta un proceso nuevo limpio en segundos.
php artisan queue:restartes el comando que hay que correr en cada deploy para que los workers en curso terminen el job actual antes de reiniciarse.- Laravel Horizon es una alternativa visual a Supervisor, pero requiere Redis y agrega complejidad que no siempre vale la pena.
El problema silencioso de los workers en daemon
Ponele que tu plataforma B2B procesa importaciones de CSV, genera PDFs y manda miles de emails. Usás php artisan queue:work porque es mucho más rápido que queue:listen: el proceso PHP arranca una sola vez y se queda vivo procesando job tras job sin el overhead de reiniciar el framework cada vez.
El problema es que ese proceso que nunca muere también nunca libera memoria.
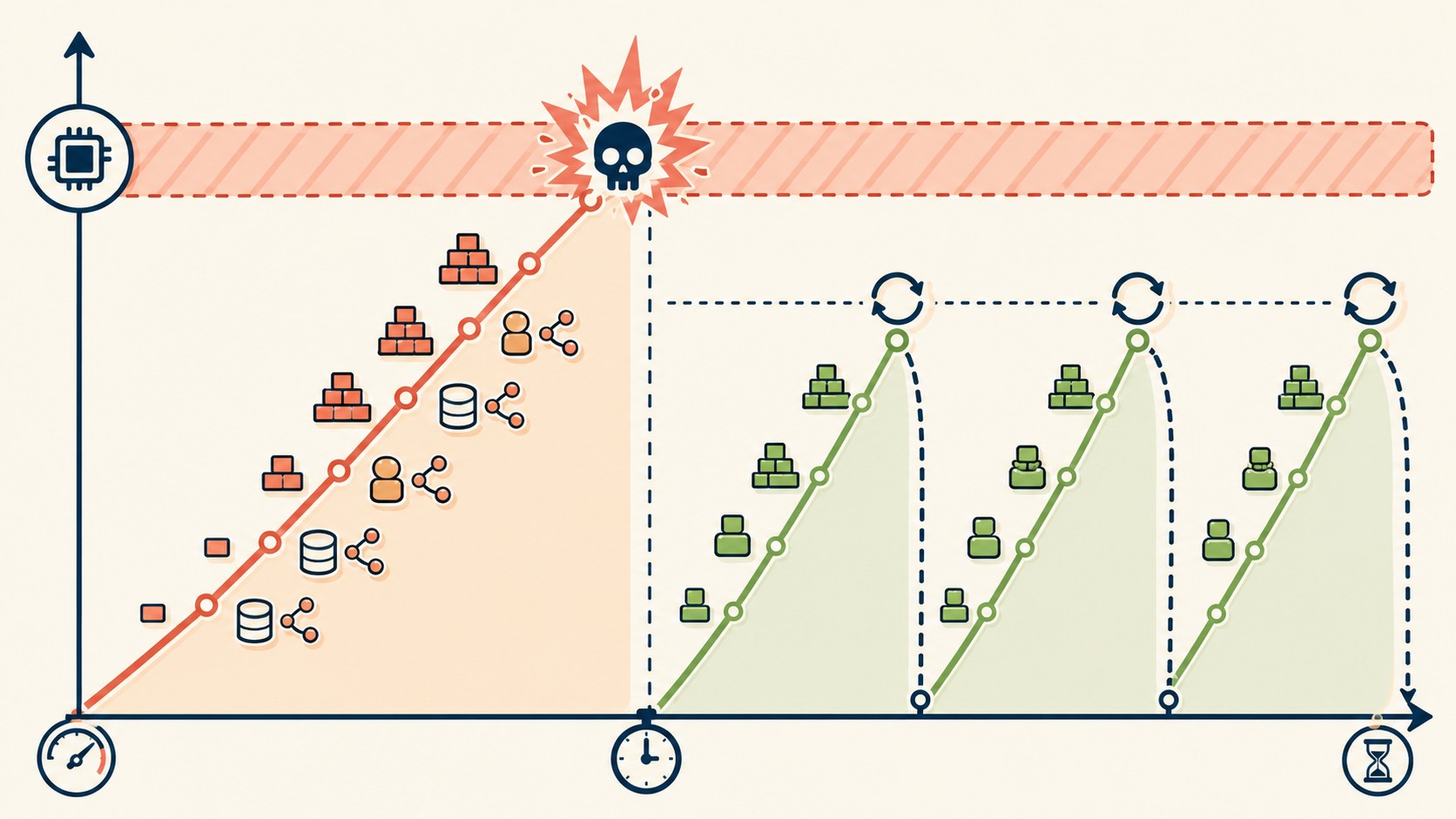
Cada job que procesás puede dejar rastros: variables estáticas que no se resetean, instancias de servicios registradas como singleton en el container, resultados cacheados por los modelos de Eloquent. Individualmente son pequeñeces. Acumulados durante horas o días de procesamiento continuo, eventualmente hacen que el proceso PHP toque el límite configurado en php.ini y explote con el mensaje más odiado de cualquier sysadmin: Allowed memory size of 134217728 bytes exhausted.
Lo peor es que no hay advertencia. El worker cae, los jobs quedan en la cola sin procesar, y si no tenés monitoreo, te enterás cuando un cliente llama porque su reporte no llegó.
Por qué aumentar RAM no resuelve nada
La reacción instintiva es cambiar memory_limit en el php.ini de CLI de 128MB a 512MB y asumir que el problema está resuelto. Zafa por un tiempo. Pero como documenta Mohamed Said, ex core team de Laravel, el memory leak en un daemon de larga vida es estructuralmente inevitable: no importa cuánta RAM le des, eventualmente la va a llenar.
La solución del mundo real no es infinita RAM. Es arquitectura de reinicios controlados.
En vez de dejar que el worker corra hasta que explote, le decís a Laravel que lo reinicie gracefully después de cierta cantidad de jobs o cierto tiempo de vida. Como hay un process monitor activo (Supervisor, en la mayoría de los casos), el momento en que el worker termina limpiamente, Supervisor levanta un proceso nuevo con memoria en cero. Sin downtime, sin jobs perdidos, sin alertas a las 3am.
Solución 1: --max-jobs y --max-time
Laravel tiene dos flags específicas para este problema, disponibles desde la versión 5.8:
--max-jobs=N: el worker procesa N jobs y después se termina limpiamente.--max-time=N: el worker corre por N segundos y después se termina limpiamente.
El comando completo en producción se ve así:
php artisan queue:work --max-jobs=500 --max-time=3600
¿Qué diferencia hay entre usar uno u otro? --max-jobs es útil cuando el volumen de jobs es predecible y sabés que 500 es un número razonable antes de que la memoria suba. --max-time es mejor cuando los jobs tienen tamaños muy variables (un job puede ser liviano, otro puede parsear un CSV de 10MB) y preferís basarte en tiempo de vida del proceso. Usarlos juntos cubre los dos escenarios: el que llega primero gana.
Lo que hacen internamente es registrar un flag para que el worker, al terminar el job actual, no tome el siguiente. Salida limpia, sin jobs a mitad de camino. Exactamente lo que querés.
Solución 2: Supervisor para reinicio automático en producción
El flag --max-jobs solo funciona si hay algo que levante el proceso de nuevo cuando termina. Ahí entra Supervisor, el gestor de procesos estándar en Ubuntu y Debian para este tipo de trabajos.
Un archivo de configuración típico en /etc/supervisor/conf.d/laravel-worker.conf:
[program:laravel-worker]
process_name=%(program_name)s_%(process_num)02d
command=php /var/www/html/artisan queue:work redis --max-jobs=500 --max-time=3600 --sleep=3 --tries=3
autostart=true
autorestart=true
numprocs=8
stdout_logfile=/var/www/html/storage/logs/worker.log
El parámetro numprocs=8 levanta 8 workers en paralelo (ajustalo según los cores de tu VPS). autorestart=true es la clave: cuando el proceso termina (ya sea por --max-jobs o por un crash inesperado), Supervisor lo reinicia automáticamente.
Después de modificar la configuración:
sudo supervisorctl reread
sudo supervisorctl update
sudo supervisorctl start laravel-worker:*
Si usás un VPS en donweb.com con Ubuntu, esta configuración funciona out-of-the-box. Supervisor viene en los repos estándar con apt install supervisor.
Solución 3: queue:restart en cada deploy
Acá hay un error común que vale la pena nombrar: la gente configura Supervisor y se olvida de que también hay que reiniciar los workers en cada deploy.
¿Por qué? Porque los workers que están corriendo ahora tienen el código viejo en memoria. Si desplegás un cambio en un Job class y el worker sigue vivo con la versión anterior, va a procesar jobs con código desactualizado (y potencialmente roto).
El comando php artisan queue:restart no mata los workers de golpe. Lo que hace es escribir un timestamp en el cache de la aplicación. Cada worker, al terminar el job actual, chequea ese timestamp. Si el timestamp cambió desde que el worker arrancó, el worker se termina limpiamente. Supervisor lo reinicia con el código nuevo.
El flujo correcto en cada deploy:
- Desplegás el código nuevo (git pull, composer install, lo que sea)
- Corrés
php artisan queue:restart - Los workers terminan sus jobs actuales y se reinician solos con el código nuevo
- Si además querés forzar un reinicio inmediato:
sudo supervisorctl restart laravel-worker:*
La diferencia entre queue:restart y supervisorctl restart es sutil pero importante: queue:restart espera que el job actual termine (graceful); supervisorctl restart mata el proceso inmediatamente, lo que puede dejar jobs a mitad de camino si no configuraste bien el manejo de señales SIGTERM.
Laravel Horizon: cuándo vale la pena y cuándo no
Horizon es una capa de abstracción sobre los workers que viene con un dashboard visual y configuración centralizada en config/horizon.php. Tiene soporte nativo para maxJobs y maxTime por environment:
'environments' => [
'production' => [
'supervisor-1' => [
'maxProcesses' => 10,
'maxJobs' => 500,
'maxTime' => 3600,
],
],
]
El dashboard te muestra jobs procesados por minuto, tiempo de procesamiento, jobs fallidos, tamaño de la cola en tiempo real. Para equipos que no quieren meterse con Supervisor manualmente, es una mejora considerable en visibilidad. Para proyectos con Redis ya configurado, Horizon vale la pena por el dashboard de monitoreo en tiempo real.
Eso sí: Horizon requiere Redis obligatoriamente. Si tu cola corre sobre database driver (lo que es muy común en proyectos chicos o medianos), no podés usar Horizon. Y si ya tenés Supervisor configurado y funcionando bien, agregar Horizon es complejidad extra sin beneficio técnico real, solo el dashboard (que zafa, la verdad).
Diagnóstico: cómo saber si tenés un leak antes del crash
Monitorear el consumo de memoria de los workers antes de que exploten es más fácil de lo que parece. Con Supervisor activo, podés ver el estado de los procesos:
sudo supervisorctl status
Para el consumo de memoria en tiempo real, ps aux | grep queue:work te da el RSS (Resident Set Size) de cada proceso. Si ves que un worker subió de 50MB a 180MB en pocas horas, tenés un leak activo.
En los logs del worker (stdout_logfile), podés agregar logging de memoria al principio de cada job:
Log::info('Memory usage', ['mb' => round(memory_get_usage(true) / 1048576, 2)]);
¿Alguien lo hace en producción? Casi nadie. Y después se preguntan por qué el worker se cayó a las 3am.
Un patrón común de leak son los listeners de eventos que quedan registrados globalmente, los logs que se acumulan en memoria antes de flushear, o los servicios de terceros (SDKs de email marketing, por ejemplo) que cachean tokens internamente en variables estáticas. Si identificás cuál es el culpable, podés limpiarlo manualmente en el método failed() del job o en un middleware de queue.
Tabla comparativa: opciones de gestión de workers
| Opción | Redis requerido | Dashboard visual | Complejidad setup | Reinicio graceful | Ideal para |
|---|---|---|---|---|---|
| Supervisor + flags | No | No | Baja | Sí (con –max-jobs) | Mayoría de proyectos |
| Laravel Horizon | Sí (obligatorio) | Sí | Media | Sí (nativo) | Equipos con Redis ya configurado |
| queue:listen | No | No | Ninguna | Sí (reinicia en cada job) | Desarrollo local solamente |
| Sin process monitor | No | No | Ninguna | No | Nunca en producción |
Errores comunes (y cómo evitarlos)
Error 1: usar --daemon explícito con queue:listen
queue:listen reinicia el proceso PHP en cada job, lo que elimina el problema de memory leaks pero agrega el overhead del bootstrap de Laravel por cada job. En producción con alto volumen, esto es lento. La diferencia puede ser de 2x-5x en throughput según el tamaño del job. Usá queue:work en producción y gestioná los reinicios con Supervisor.
Error 2: no correr queue:restart en el deploy
Desplegás código nuevo y no avisás a los workers. Los workers siguen corriendo con el código viejo en memoria durante horas, hasta que se reinician solos por --max-jobs o --max-time. Dependiendo del valor de esos flags, podés tener workers procesando jobs con código desactualizado durante bastante tiempo. En el pipeline de deploy, php artisan queue:restart es tan obligatorio como php artisan migrate.
Error 3: poner numprocs muy alto sin medir
Ver numprocs=8 en un ejemplo y ponerlo igual sin pensar. Si tu VPS tiene 2 cores y cada worker consume 80MB en pico, con 8 workers estás usando 640MB solo para queues. Arrancá con 2-4 workers, monitoreá el consumo con ps aux, y escalá según lo que realmente necesitás. Más workers no siempre significa más throughput; si los jobs son I/O bound (esperando respuesta de una API), podés poner más. Si son CPU bound (parsing pesado), limitarte a los cores disponibles.
Si te interesa profundizar, tenemos un artículo sobre Stop Worker Crashes: Fixing Laravel Queue Memory Leaks in Pr.
Para profundizar en este tema, mirá Stop Worker Crashes: Fixing Laravel Queue Memory Leaks in Pr.
Si querés profundizar en esto, tenemos un artículo sobre Stop Worker Crashes: Fixing Laravel Queue Memory Leaks in Pr.
Preguntas Frecuentes
¿Cómo evitar que el queue worker se caiga por falta de memoria?
Usá los flags --max-jobs=500 y --max-time=3600 al correr queue:work. Estos le dicen al worker que se termine limpiamente después de N jobs o N segundos, lo que evita que la memoria siga acumulándose indefinidamente. Combinalo con Supervisor para que el proceso se reinicie automáticamente.
¿Qué diferencia hay entre --max-jobs y --max-time en Laravel?
--max-jobs reinicia el worker después de procesar N jobs, independientemente del tiempo. --max-time reinicia el worker después de N segundos, independientemente de cuántos jobs procesó. Usarlos juntos es lo recomendado: el que se cumpla primero dispara el reinicio. Son complementarios, no alternativos.
¿Cómo configurar Supervisor para reiniciar automáticamente los workers?
Creá un archivo en /etc/supervisor/conf.d/laravel-worker.conf con autorestart=true y el comando completo incluyendo --max-jobs y --max-time. Después corré sudo supervisorctl reread && sudo supervisorctl update. Con esta configuración, cada vez que el worker termina (por los flags o por un crash), Supervisor levanta un proceso nuevo automáticamente.
¿Es mejor usar Horizon o Supervisor para gestionar queues en producción?
Supervisor es suficiente para la mayoría de los proyectos y no requiere Redis. Horizon agrega un dashboard visual útil y configuración más limpia, pero obliga a usar Redis como driver de colas. Si ya tenés Redis, Horizon vale la pena. Si no, Supervisor con los flags correctos resuelve el problema sin agregar dependencias.
¿Por qué se agotan los límites de memoria en un queue worker daemon?
El proceso PHP del worker arranca una sola vez y procesa múltiples jobs sin reiniciarse. Con cada job, pueden quedar residuos en memoria: variables estáticas, instancias de servicios registradas como singleton, caches de modelos Eloquent. Este patrón de acumulación es estructural en daemons de larga vida y no tiene que ver con bugs de código sino con la arquitectura del proceso.
Conclusión
El crash del worker por memoria no es un bug que se parchea una vez. Es un problema estructural de los daemons de larga vida que requiere una solución de arquitectura: reinicios controlados, configurados de antemano, gestionados por un process monitor.
La combinación --max-jobs=500 --max-time=3600 más Supervisor con autorestart=true es el estándar de producción. No es compleja, no requiere cambios en el código de los jobs, y elimina los crashes nocturnos. Agregale queue:restart en tu pipeline de deploy y tenés el 90% de los problemas cubiertos.
Si querés más visibilidad sobre qué está pasando en la cola, Horizon agrega el dashboard sin cambiar la lógica subyacente. Pero si Supervisor ya funciona bien, no lo toques.