Plataformas cloud native escalables: guía 2026
Las plataformas cloud native escalables son sistemas de gestión de rendimiento construidos sobre microservicios, contenedores e infraestructura elástica que se adaptan automáticamente a la demanda, a diferencia de las aplicaciones tradicionales que simplemente se alojan en la nube. La diferencia no es menor: una cosa es levantar un monolito en AWS y otra muy distinta es diseñar desde cero para escalar horizontalmente, fallar con gracia y observar cada componente en tiempo real.
En 30 segundos
- Una plataforma cloud native de gestión de performance tiene cinco pilares: microservicios, contenedores, pipelines CI/CD, Infrastructure as Code y observabilidad distribuida.
- La observabilidad descansa en tres señales: logs, métricas y trazas distribuidas. Sin los tres, estás volando a ciegas en producción.
- El stack LGTM (Loki, Grafana, Tempo, Mimir) es hoy la combinación open source más usada para monitorear entornos Kubernetes a escala empresarial.
- El auto-escalado basado en métricas, combinado con circuit breakers, permite absorber picos de tráfico sin caídas y sin pagar por capacidad ociosa todo el año.
- Empresas que migraron a arquitecturas cloud native reportan despliegues en horas donde antes tardaban semanas, con visibilidad operacional en tiempo real.
Qué son las plataformas cloud native de gestión de performance
Una plataforma cloud native escalable es un sistema diseñado desde sus cimientos para vivir y crecer en la nube, no uno que se mudó ahí después. La distinción importa porque cambia todo: el modelo de despliegue, la forma de gestionar fallos, cómo escala y, sobre todo, cómo medís el rendimiento cuando tenés decenas o cientos de servicios corriendo a la vez.
Ponele que tu empresa gestiona incentivos de ventas para 500 vendedores distribuidos en cinco países. Un sistema monolítico típico te va a dar un solo punto de fallo, deploys que requieren parar todo y métricas agregadas que no te dicen nada cuando algo se rompe a las 2 de la mañana. Un diseño cloud native, en cambio, te da servicios independientes para cálculo de cuotas, reportes y pagos de comisiones, cada uno escalando según su propia demanda.
Según Cloud Native Now, las plataformas de gestión de performance (SPM, Sales Performance Management) son uno de los casos de uso más exigentes para arquitecturas cloud native porque combinan cálculos intensivos, datos en tiempo real y usuarios distribuidos globalmente.
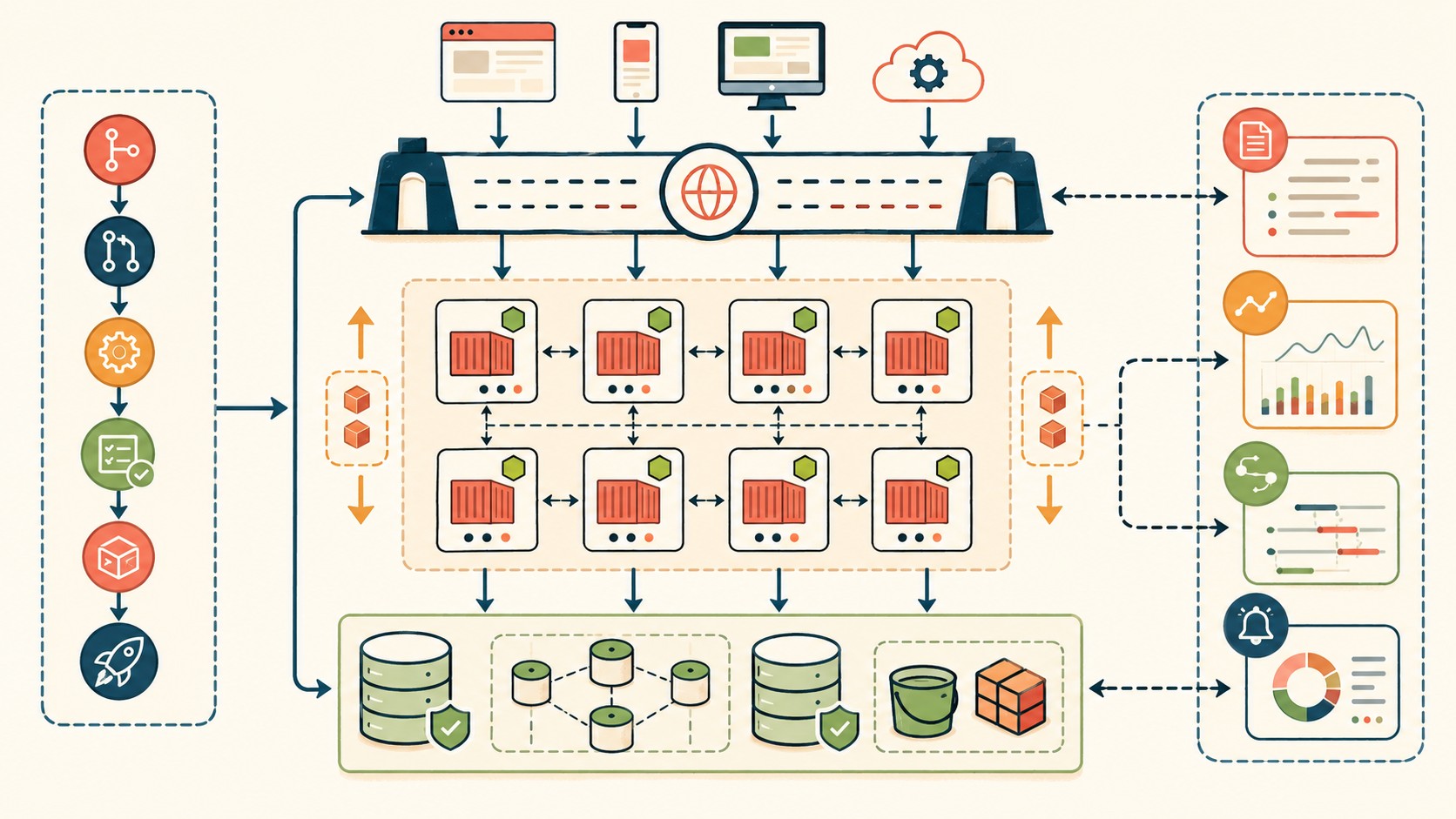
Arquitectura de microservicios: la base de la escalabilidad
La arquitectura de microservicios divide lo que antes era un sistema único en servicios pequeños, autónomos y desplegables de forma independiente. Cada servicio tiene su propia base de datos, su propio ciclo de deploy y su propia forma de fallar sin afectar al resto del sistema.
Suena bien en papel. El tema es que la complejidad operacional se multiplica. En un monolito tenés un solo log que revisar, una sola base de datos que monitorear. Con 40 microservicios, una request puede pasar por 15 servicios distintos antes de llegar al usuario, y si algo falla en el camino, necesitás poder seguir esa request desde el origen hasta el error específico. Para eso existe la observabilidad distribuida (que vemos en detalle más adelante).
Las ventajas concretas de separar en microservicios: podés escalar solo el servicio de cálculo de comisiones durante el cierre de trimestre sin tocar los demás, podés hacer deploy de una corrección en el módulo de reportes sin parar toda la plataforma, y podés usar el stack tecnológico más adecuado para cada servicio. Ya lo cubrimos antes en herramientas de CI/CD para automatizar deployments.
Los cinco pilares de escalabilidad
Según los principios de arquitectura cloud native documentados por Google Cloud, hay cinco elementos que no pueden faltar en una plataforma que pretenda escalar a nivel empresarial:
1. Microservicios
Servicios independientes, con responsabilidad única, comunicados via APIs bien definidas. El diseño API-first no es opcional: si los contratos entre servicios no están bien especificados desde el principio, terminás con acoplamiento encubierto que te explota cuando menos lo esperás.
2. Contenedores
Docker como unidad de empaquetado, Kubernetes como orquestador. Los contenedores garantizan que lo que funciona en local funciona en producción (spoiler: casi siempre, salvo variables de entorno mal configuradas). Kubernetes agrega la capa de scheduling, health checks automáticos y rolling deployments.
3. CI/CD Pipelines
Integración continua y despliegue continuo: cada commit puede llegar a producción en minutos si pasa los tests automáticos. El resultado práctico es pasar de deploys semanales o mensuales a deploys múltiples por día, con rollback automático si los health checks fallan.
4. Infrastructure as Code (IaC)
Terraform, Pulumi o CloudFormation para definir la infraestructura como código versionable. Nada de configuraciones manuales que nadie documentó. Si necesitás levantar una réplica del ambiente de producción para testear, lo hacés con un comando. Toda la infraestructura para servicios cloud, VPS y entornos distribuidos, incluso la de proveedores como donweb.com, puede gestionarse así.
5. Observabilidad
El pilar que diferencia un sistema que reacciona a los problemas de uno que los anticipa. Sin observabilidad, los otros cuatro pilares te dan velocidad para desplegar pero no para diagnosticar.
Observabilidad distribuida: el corazón del monitoreo
Monitoreo tradicional y observabilidad no son lo mismo. El monitoreo te dice que el servidor está al 95% de CPU. La observabilidad te dice qué request específica, generada por qué usuario, ejecutando qué query en qué microservicio, causó ese pico.
La observabilidad distribuida descansa en tres señales complementarias:
- Logs: registros de eventos con timestamp. Son el “qué pasó” más básico. El problema es que los logs en sistemas con cientos de servicios generan volúmenes enormes que, sin correlación, son casi inútiles.
- Métricas: valores numéricos agregados en el tiempo (latencia p99, requests por segundo, tasa de errores). Son eficientes de almacenar y consultar, pero pierden el contexto de requests individuales.
- Trazas distribuidas: seguimiento de una request a través de todos los servicios que toca, con tiempos precisos en cada salto. Son el “dónde se rompió esto” cuando tenés 15 microservicios en el camino.
¿Alguien puede operar bien con solo dos de los tres? Técnicamente sí, pero tarde o temprano te falta el tercero en el momento más crítico. En estrategias para alcance global profundizamos sobre esto.
Según Qualoom, la observabilidad inteligente en entornos cloud native incluye alertas basadas en anomalías estadísticas, no solo umbrales fijos. La diferencia es que un umbral fijo de “alerta si CPU > 80%” puede dispararse mil veces por fluctuaciones normales, mientras que un sistema basado en anomalías aprende el comportamiento baseline y alerta solo cuando algo real se desvía.
Stack LGTM y herramientas open source
El stack LGTM se volvió el estándar de facto para observabilidad cloud native open source en 2026: Loki para logs, Grafana para dashboards y visualización, Tempo para trazas distribuidas y Mimir para métricas a largo plazo.
La ventaja de este stack es que Grafana unifica las cuatro dimensiones de observabilidad en una sola interfaz, con correlación entre señales: desde un log podés saltar a la traza correspondiente, desde una métrica podés ver los logs del período de anomalía. Esto que suena a detalle pequeño en la práctica corta dramáticamente el tiempo de diagnóstico.
Para entornos Kubernetes, Prometheus sigue siendo el estándar para recolección de métricas, especialmente con el Prometheus-Operator que simplifica la configuración via CRDs de Kubernetes. El recurso ServiceMonitor te permite declarar qué servicios monitorear sin tocar la configuración central del Prometheus. Junto con node-exporter (métricas del sistema operativo) y kube-state-metrics (estado de los recursos Kubernetes), cubrís los tres niveles: infraestructura, orquestador y aplicación.
| Herramienta | Señal | Licencia | Mejor para |
|---|---|---|---|
| Loki + Grafana + Tempo + Mimir (LGTM) | Logs, dashboards, trazas, métricas | Open Source (AGPLv3) | Equipos que quieren stack unificado self-hosted |
| Prometheus + Grafana | Métricas + dashboards | Open Source (Apache 2.0) | Kubernetes-native, sin trazas nativas |
| Elastic Observability | Logs, métricas, APM, trazas | Freemium / Enterprise | Equipos que ya usan Elasticsearch |
| Datadog | Todo en uno (SaaS) | SaaS (precio por host/mes) | Equipos que priorizan setup rápido sobre control |
| New Relic | APM, infraestructura, logs | SaaS (free tier + enterprise) | Empresas con foco en APM y user experience |
La elección entre stack self-hosted y SaaS no es trivial. El self-hosted te da control total y cero lock-in, pero requiere un equipo que lo opere. El SaaS (la “solución enterprise” de turno) resuelve la operación pero puede costarte cinco o seis cifras anuales cuando tu volumen de datos crece.
Despliegue y escalado automático en tiempo real
Subís el código, el pipeline lo testa automáticamente, lo conteneriza, actualiza la imagen en el registry, Kubernetes hace rolling deployment sin downtime, los health checks confirman que el nuevo pod responde bien, el viejo pod se apaga. Todo esto puede tomar entre 3 y 8 minutos dependiendo del tamaño de los tests.
El auto-escalado en Kubernetes funciona en dos niveles: el Horizontal Pod Autoscaler (HPA) agrega o quita réplicas de un servicio según métricas como CPU, memoria o métricas custom (requests por segundo, latencia), y el Cluster Autoscaler agrega o quita nodos del cluster cuando los pods no caben en los existentes. Combinados, absorbés un pico de tráfico de 10x sin intervención manual y sin pagar por esa capacidad cuando no la necesitás.
Eso sí: el auto-escalado mal configurado puede hacer que Kubernetes intente escalar en respuesta a spikes momentáneos, generando más pods que luego se apagan inmediatamente. Los parámetros stabilizationWindowSeconds y scaleDown.policies existen exactamente para evitar ese comportamiento errático. Cubrimos ese tema en detalle en fundamentos de Linux en DevOps.
Los circuit breakers son el complemento indispensable: si el servicio de pago de comisiones empieza a fallar, el circuit breaker corta las llamadas al servicio antes de que los timeouts acumulados saturen toda la plataforma. Librerías como Resilience4j (Java) o Polly (.NET) implementan este patrón con configuración declarativa.
Implementación empresarial: de la teoría a producción
El caso más concreto que ilustra el valor de las plataformas cloud native escalables es la expansión geográfica. Una empresa con operaciones comerciales en Argentina que abre oficinas en Brasil, Colombia y México necesita que la plataforma de gestión de performance esté disponible para los nuevos vendedores desde el primer día, con datos de cuotas localizados, monedas correctas y reglas de compensación específicas por mercado.
Con una arquitectura cloud native bien diseñada, eso se logra en horas: levantás una instancia regional, la conectás al sistema de configuration management, aplicás el IaC para el nuevo entorno y el pipeline de CI/CD despliega automáticamente. Con un monolito bien configurado… buena suerte, necesitás semanas.
La visibilidad operacional en tiempo real cambia cómo los líderes comerciales toman decisiones. En lugar de esperar el reporte mensual, pueden ver en un dashboard cuántas oportunidades cerraron los vendedores de la región norte esta semana, qué tan cerca están de su cuota y si el pipeline de CI/CD introdujo alguna regresión en el cálculo de comisiones (que es exactamente el tipo de bug que nadie detecta hasta que los vendedores se quejan en el cierre de mes).
Errores comunes al diseñar plataformas cloud native
Empezar con microservicios sin haber definido los límites de dominio
El error más caro. Si dividís el sistema en microservicios antes de entender bien los dominios del negocio, terminás con servicios que se llaman entre sí constantemente para completar una sola operación. Eso no es microservicios, es un monolito distribuido con toda la complejidad de la distribución y sin las ventajas de la independencia. La regla: primero modelá el dominio (Domain-Driven Design), después extraé servicios.
Confundir “estar en la nube” con “ser cloud native”
Una aplicación monolítica corriendo en una VM de AWS no es cloud native. Cloud native implica diseño para la elasticidad, para los fallos parciales y para la observabilidad desde el principio. Si tu aplicación asume que la base de datos siempre está disponible y que el servicio de pagos nunca falla, no está diseñada para la nube. Tema relacionado: impacto de pruebas inestables en pipelines.
Implementar observabilidad como afterthought
La observabilidad instrumentada a posteriori siempre es incompleta. Si no diseñás los puntos de tracing y las métricas de negocio desde el inicio, vas a tener monitoring de infraestructura pero no visibilidad sobre lo que hace tu sistema. Cuántas requests por segundo procesa el servicio de cálculo de comisiones es útil. Cuántos cálculos fallaron por datos de entrada inválidos es lo que realmente necesitás saber.
Auto-escalar sin definir resource limits
Si los pods de Kubernetes no tienen resources.limits configurados, un servicio con un leak de memoria puede consumir todos los recursos del nodo y matar otros servicios. El auto-escalado sin límites bien definidos es una receta para gastar el doble en infraestructura sin resolver el problema original.
Preguntas Frecuentes
¿Cómo diseñar una plataforma cloud native escalable para empresas?
Empezá por modelar los dominios del negocio antes de pensar en tecnología. Identificá qué funciones necesitan escalar de forma independiente y definí contratos API claros entre ellas. Después implementá los cinco pilares: microservicios, contenedores con Kubernetes, pipelines CI/CD, Infrastructure as Code y observabilidad con los tres tipos de señales (logs, métricas, trazas). El orden importa: la observabilidad va desde el día uno, no al final.
¿Qué es la observabilidad distribuida y por qué es importante?
La observabilidad distribuida es la capacidad de entender el estado interno de un sistema complejo a partir de sus salidas externas, usando logs, métricas y trazas distribuidas como señales correlacionadas. Es importante porque en arquitecturas con múltiples microservicios, el monitoreo tradicional basado en umbrales de CPU o memoria no alcanza para diagnosticar fallos que atraviesan varios servicios. Con trazas distribuidas podés ver exactamente en qué servicio y en qué línea de código falló una request específica.
¿Qué herramientas de monitoreo debo usar para microservicios?
Para entornos Kubernetes open source, el stack LGTM (Loki + Grafana + Tempo + Mimir) cubre las cuatro dimensiones de observabilidad con una interfaz unificada. Prometheus con Prometheus-Operator es el estándar para recolección de métricas en Kubernetes. Si tu equipo no tiene capacidad para operar el stack self-hosted, herramientas SaaS como Datadog o New Relic reducen la fricción operacional a cambio de un costo mensual por host que crece con la infraestructura.
¿Cuáles son los pasos para escalar una aplicación cloud native?
El escalado automático en Kubernetes opera en dos capas: el Horizontal Pod Autoscaler (HPA) ajusta las réplicas de cada servicio según métricas de CPU, memoria o métricas custom definidas por la aplicación, y el Cluster Autoscaler ajusta el número de nodos del cluster. Para implementarlo: definí resource requests y limits para cada pod, configurá el HPA con umbrales y ventanas de estabilización adecuadas, y complementá con circuit breakers para manejar fallos en cascada cuando un servicio downstream no responde.
¿Cómo implementar gestión de rendimiento en entornos cloud?
La gestión de rendimiento en entornos cloud nativo combina métricas de negocio con métricas de infraestructura. Define primero los SLOs (Service Level Objectives) del sistema: latencia máxima aceptable para el percentil 99, tasa de error máxima, disponibilidad objetivo. Implementá esos SLOs como alertas en tu stack de observabilidad. Los dashboards operacionales deben mostrar tanto el estado técnico (latencia de servicios, tasa de errores) como el estado de negocio (transacciones procesadas, cálculos completados) en tiempo real.
Conclusión
Las plataformas cloud native escalables dejaron de ser una aspiración técnica para convertirse en infraestructura operacional concreta para empresas que necesitan velocidad de despliegue y visibilidad en tiempo real. Los cinco pilares (microservicios, contenedores, CI/CD, IaC y observabilidad) no son un checklist de tendencias, son las piezas que determinan si tu sistema puede absorber crecimiento sin romperse.
Lo que diferencia las implementaciones exitosas de las que quedan a mitad de camino es la observabilidad bien instrumentada desde el inicio y los límites de dominio bien definidos antes de empezar a cortar servicios. Podés arrancar con un monolito modular y extraer servicios cuando el negocio lo justifica, siempre que hayas diseñado para la separación desde el principio. El stack LGTM con Prometheus te da todo lo necesario sin atarte a ningún vendor, y el auto-escalado de Kubernetes maneja los picos sin que tengas que estar de guardia a las 3 de la mañana.
Fuentes
- Cloud Native Now – Designing Cloud-Native Performance Management Platforms That Scale Across the Enterprise
- Google Cloud Blog – 5 Principles for Cloud-Native Architecture
- Qualoom – Observabilidad en entornos cloud native: métricas y alertas inteligentes
- Observa Sistemas – Prometheus para la monitorización de microservicios
- Silicon.es – 5 retos de observabilidad en aplicaciones cloud native