Kubernetes Services: ClusterIP, NodePort y LoadBalancer
Los Servicios de Kubernetes son el mecanismo que permite exponer tus aplicaciones dentro y fuera del cluster, asignando un endpoint estable a un conjunto de Pods que pueden aparecer, desaparecer o cambiar de IP en cualquier momento. Sin un Service, tus Pods corren pero nadie puede hablarles.
En 30 segundos
- Un Kubernetes Service es un objeto que expone Pods con una IP y puerto fijos, aunque los Pods se reinicien o cambien de IP.
- Hay tres tipos principales: ClusterIP (interno), NodePort (acceso externo básico) y LoadBalancer (producción con cloud).
- Los Services no identifican Pods por IP sino por labels: si un Pod tiene el label correcto, el Service le envía tráfico.
- Si dos microservicios no se hablan, casi siempre el problema está en los selectores o en el tipo de Service equivocado.
- LoadBalancer genera automáticamente un ClusterIP y un NodePort internos, no es un tipo independiente.
El Problema: Por Qué los Pods de Kubernetes son Invisibles
Ponele que terminás de configurar tu primer Deployment en Kubernetes. Los Pods están corriendo, el dashboard verde, todo parece perfecto. Abrís el navegador, apuntás a la IP del nodo y… nada. Silencio total.
El motivo es sencillo pero tiene consecuencias importantes: según la documentación oficial de Kubernetes, cada Pod recibe una dirección IP interna al cluster que cambia cada vez que el Pod se reinicia, se reemplaza por una actualización rolling o el scheduler lo mueve a otro nodo. Esa IP no es accesible desde afuera, y ni siquiera es confiable dentro del cluster porque mañana puede ser otra.
Esto es por diseño. Los Pods son efímeros. No están pensados para vivir para siempre ni para tener identidad de red estable. El componente que pone orden en ese caos son los Services.
¿Qué es un Kubernetes Service? Los Tres Pilares
Un Kubernetes Service es un recurso del cluster que expone un conjunto de Pods bajo una IP y puerto fijos, independientemente de qué le pase a esos Pods por debajo. Lo define la spec oficial como “una abstracción que define un conjunto lógico de Pods y una política de acceso a ellos”.
Concretamente hace tres cosas: asigna una IP y puerto estables que no cambian, agrupa los Pods correctos usando labels, y redirige el tráfico automáticamente si un Pod cae y otro lo reemplaza. El cliente que llama al Service nunca sabe cuántos Pods hay ni dónde están. Eso es exactamente lo que querés.
Lo interesante es que el Service no manda tráfico al Pod que “conoce” de antes sino al Pod que en ese momento tiene el label correcto. Si reiniciás todos los Pods de un Deployment, el Service sigue funcionando sin tocar nada en la configuración.
ClusterIP: Comunicación Interna Entre Servicios
ClusterIP es el tipo por defecto. Cuando creás un Service sin especificar tipo, Kubernetes te da un ClusterIP. Para más detalles técnicos, mirá automatización del despliegue.
Asigna una IP virtual del rango interno del cluster (típicamente 10.96.0.0/12 en instalaciones por defecto) que solo es accesible desde dentro del cluster. Ningún cliente externo puede llegar ahí, lo cual en muchos casos es exactamente lo que querés para bases de datos, servicios de caché o APIs internas que no tienen que estar expuestas.
El DNS interno del cluster resuelve automáticamente nombre-servicio.namespace.svc.cluster.local a esa IP. En la práctica, dentro del mismo namespace alcanza con usar el nombre del Service directamente. Si tu aplicación Node.js necesita hablar con tu servicio de Redis, puede hacerlo como redis:6379 sin saber nada sobre IPs.
Limitación concreta: si necesitás que algo de afuera del cluster llegue a ese servicio, ClusterIP solo no alcanza.
NodePort: Exponiendo tu Aplicación al Mundo Externo
NodePort es el siguiente nivel. Además de crear un ClusterIP interno (sí, siempre lo crea), abre un puerto en el rango 30000-32767 en todos los nodos del cluster. Cualquier tráfico que llegue a ese puerto en cualquier nodo, Kubernetes lo redirige al Service y de ahí a los Pods.
Accedés con IP-del-nodo:30XXX. Funciona, pero tiene sus problemas: los puertos altos no son bonitos para producción, tenés que saber la IP de algún nodo (que puede cambiar), y si usás un proveedor cloud tenés que abrir esos puertos en el firewall manualmente.
¿Dónde sirve NodePort? En entornos de desarrollo local, en clusters on-premise sin balanceador de carga, o cuando querés hacer una prueba rápida sin configurar nada más. Para un demo o un entorno de QA, zafa perfectamente. Cubrimos ese tema en detalle en servir contenido en múltiples regiones.
LoadBalancer: La Solución para Producción
LoadBalancer hace todo lo que hacen ClusterIP y NodePort, más una cosa extra: le pide al proveedor de cloud que cree un balanceador de carga externo y le asigne una IP pública. En AWS sería un ELB, en Google Cloud un Network Load Balancer, en Azure un Azure Load Balancer.
Según la documentación de AKS de Microsoft, cuando creás un Service tipo LoadBalancer en Azure Kubernetes Service, el controlador del cloud crea automáticamente el recurso de Azure Load Balancer y le asigna una IP pública estática. Vos no tocás nada del balanceador manualmente.
El costo es real. Cada Service LoadBalancer en la mayoría de los clouds genera una IP pública y un balanceador que se factura por hora aunque no tenga tráfico. Si tenés 20 microservicios expuestos como LoadBalancer, estás pagando 20 balanceadores. Para eso existe Ingress, que es otra historia, pero conviene tenerlo en cuenta antes de exponer todo con LoadBalancer.
Para producción en cualquier cloud gestionado (AKS, GKE, EKS), LoadBalancer es el camino. Si tu infraestructura la montás en Argentina y buscás un proveedor local con soporte para Kubernetes, donweb.com tiene opciones de cloud y VPS donde podés correr clusters propios.
Tabla Comparativa de Tipos de Services
| Tipo | Acceso | Caso de uso | Crea ClusterIP | IP pública |
|---|---|---|---|---|
| ClusterIP | Solo interno al cluster | Comunicación entre microservicios | Sí (es el mismo) | No |
| NodePort | Externo vía IP del nodo | Dev, testing, on-premise sin cloud | Sí | No (usás IP del nodo) |
| LoadBalancer | Externo vía IP pública | Producción en cloud | Sí | Sí (asignada por el cloud) |
| ExternalName | Alias DNS externo | Acceder a servicios fuera del cluster | No | No aplica |
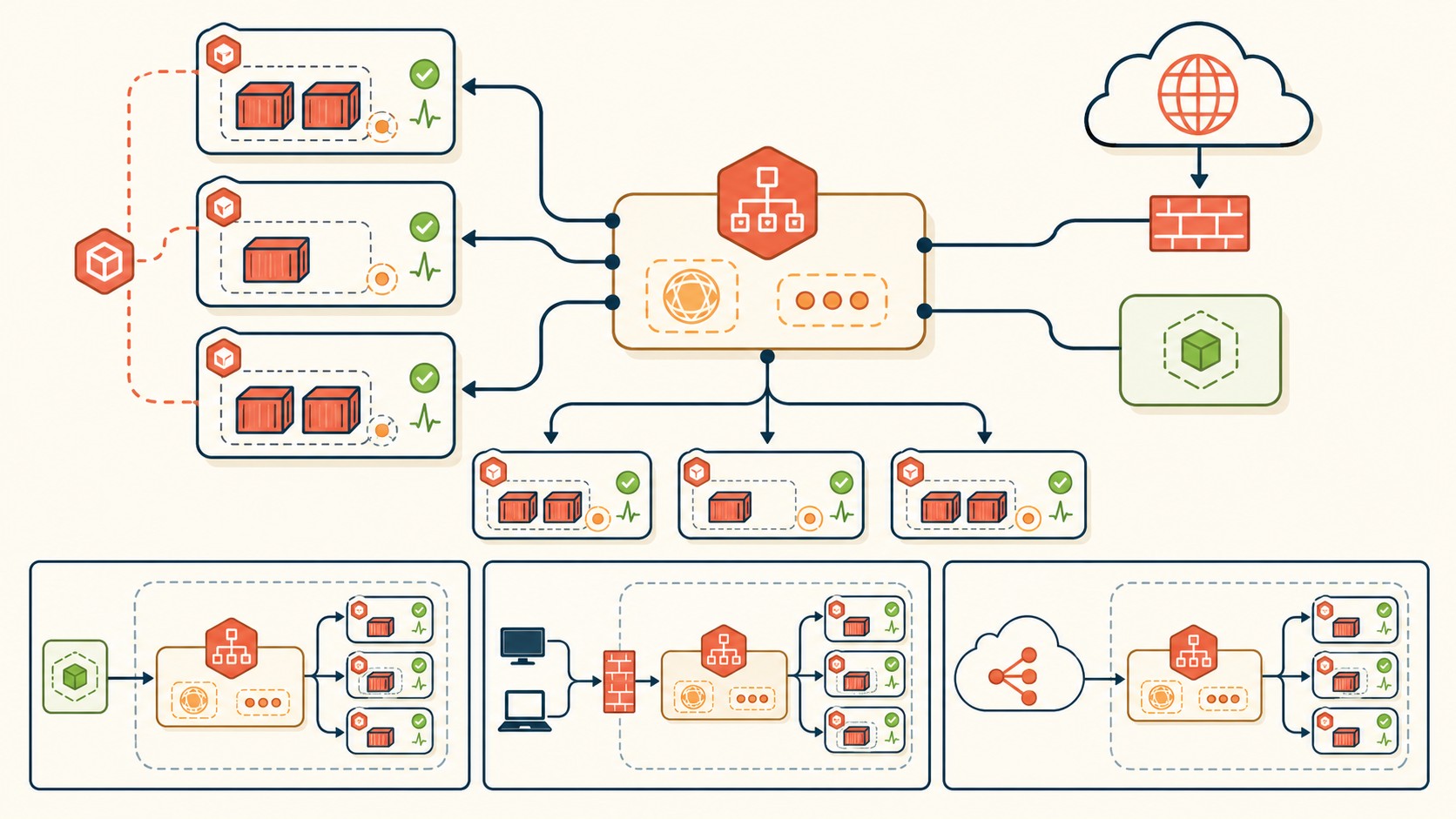
Cómo los Services Encuentran los Pods: Labels y Selectores
Este es el concepto que más confunde al principio. El Service no sabe las IPs de los Pods. No lleva una lista de direcciones. Lo que hace es mirar los labels de los Pods que hay corriendo en el cluster y enviar tráfico a los que coincidan con su selector.
Si en el Service definís selector: app: mi-api, el Service va a encontrar todos los Pods que tengan el label app: mi-api, sin importar cuántos sean ni cuándo fueron creados. Cuando un Pod nuevo arranca con ese label, el Service empieza a mandarle tráfico automáticamente. Cuando un Pod cae, deja de recibir tráfico (hay un endpoint controller que actualiza esa lista en tiempo real).
Esto tiene una consecuencia práctica importante: dos Deployments con el mismo label son indistinguibles para el Service. Si por accidente dos apps diferentes comparten el label que el Service busca, el Service les va a mandar tráfico a las dos. Eso genera bugs muy raros que cuestan horas de debugging (spoiler: el servicio “a veces funciona y a veces no” es casi siempre este problema).
Balanceo de Carga Automático y Recuperación de Fallos
Cuando un Service tiene tres Pods detrás, Kubernetes distribuye el tráfico entre los tres usando round-robin por defecto. No es un balanceo sofisticado con pesos o afinidad de sesión, pero para la mayoría de las APIs stateless alcanza. Ya lo cubrimos antes en sin necesidad de orquestación.
La recuperación de fallos es automática: el endpoint controller monitorea los Pods y actualiza la lista de endpoints del Service. Si un Pod falla el health check o se reinicia, sale de rotación en segundos. Tus usuarios van a notar un error ocasional durante el restart, pero no una caída sostenida.
Esto se complementa bien con los liveness y readiness probes de los Pods. El Service solo manda tráfico a Pods que pasen el readiness probe, lo cual significa que un Pod que arrancó pero todavía está inicializando no recibe tráfico hasta que esté listo. Es un detalle que ahorra muchos 503 en despliegues rolling.
Errores Comunes y Cómo Evitarlos
1. Selectores que no coinciden con los labels de los Pods
El error más frecuente. Creás el Service con selector: app: backend pero el Deployment tiene los Pods con app: backend-api. El Service queda con cero endpoints y nunca llega tráfico. La solución: kubectl describe service nombre-service y fijate si en “Endpoints” aparece algo o dice <none>. Si está vacío, el problema son los selectores.
2. Usar ClusterIP cuando necesitás acceso externo
Si necesitás que algo de afuera del cluster llegue a tu aplicación y creaste un ClusterIP, no va a funcionar nunca. Revisá el tipo antes de debuggear otra cosa.
3. Pensar que la IP del Pod es estable
Cualquiera que haya hardcodeado la IP de un Pod en la configuración de otro servicio ya vivió esto. El Pod se reinicia, la IP cambia, y la conexión queda rota. Siempre usá el nombre del Service, nunca la IP del Pod.
4. No definir targetPort correctamente
El port del Service es lo que escucha el Service. El targetPort es el puerto donde escucha el container. Si tu app escucha en el puerto 8080 pero el Service tiene targetPort: 80, el tráfico no llega. Son campos distintos con propósitos distintos. Tema relacionado: despliegue de APIs en AWS.
5. Ignorar las Network Policies
Si tu cluster tiene Network Policies activas y los Pods no se comunican aunque el Service esté bien configurado, puede que una policy esté bloqueando el tráfico. Primero descartá los selectores mal configurados, después revisá las policies.
Preguntas Frecuentes
¿Qué es un Kubernetes Service?
Un Kubernetes Service es un objeto del cluster que expone un conjunto de Pods bajo una dirección IP y puerto fijos, independientemente de que esos Pods se reinicien o cambien de IP. Actúa como una capa de abstracción de red que desacopla a los clientes del ciclo de vida de los Pods. Sin un Service, los Pods son inaccesibles desde otras partes del sistema.
¿Cuál es la diferencia entre ClusterIP, NodePort y LoadBalancer?
ClusterIP expone el servicio solo dentro del cluster, sin acceso externo. NodePort abre un puerto en el rango 30000-32767 en todos los nodos del cluster, permitiendo acceso externo vía IP del nodo. LoadBalancer crea un balanceador de carga externo en el proveedor de cloud y le asigna una IP pública. Cada tipo incluye al anterior: NodePort crea un ClusterIP, LoadBalancer crea un NodePort y un ClusterIP.
¿Cómo hago que mi aplicación Kubernetes sea accesible desde afuera?
En un cluster cloud (AKS, GKE, EKS), usá un Service tipo LoadBalancer: Kubernetes crea automáticamente un balanceador con IP pública. En un cluster on-premise o local, usá NodePort y accedé con la IP del nodo más el puerto asignado. Para múltiples servicios en producción, Ingress con un solo LoadBalancer es más eficiente en costos.
¿Cómo encuentran los Services a los Pods en Kubernetes?
Por labels, no por IPs. El Service tiene un campo selector con uno o más labels, y envía tráfico a todos los Pods que tengan esos labels en el momento de la consulta. Kubernetes mantiene automáticamente una lista de endpoints actualizada a medida que los Pods arrancan o caen.
¿Por qué mis Pods de Kubernetes no se comunican entre sí?
Las causas más comunes son: selectores del Service que no coinciden con los labels de los Pods (verificá con kubectl describe service), usar IPs de Pods hardcodeadas en vez de nombres de Services, Network Policies que bloquean el tráfico, o un targetPort incorrecto en la definición del Service. Empezá revisando los endpoints: si kubectl get endpoints nombre-service devuelve <none>, el problema son los selectores.
Conclusión
Los Services de Kubernetes resuelven un problema concreto: los Pods son efímeros y sus IPs cambian, pero las aplicaciones necesitan endpoints estables para comunicarse. La elección entre ClusterIP, NodePort y LoadBalancer no es una cuestión de gusto sino de contexto: comunicación interna, acceso externo sin cloud, o producción en cloud.
Lo que te va a salvar más tiempo en la práctica es entender bien los labels y selectores. Todos los problemas de “el Service no llega a los Pods” tienen la misma raíz: un selector que no coincide con los labels del Deployment. Antes de buscar problemas de red complejos, revisá siempre eso primero.
Si estás armando tu primer cluster y necesitás infraestructura para correrlo, los conceptos que vimos acá aplican igual en cualquier entorno donde tengas Kubernetes disponible.
¿Cuál es la diferencia entre ClusterIP, NodePort y LoadBalancer?
ClusterIP expone el servicio solo dentro del cluster con una IP fija interna. NodePort abre un puerto en todos los nodos (rango 30000-32767) para acceso externo. LoadBalancer es la combinación de ambos más una IP pública asignada por el cloud, ideal para producción.
¿Cuándo debería usar ClusterIP en Kubernetes?
Usá ClusterIP cuando tus servicios se comunican dentro del cluster: bases de datos, caches, APIs internas. Es el tipo por defecto, asigna una IP estable solo visible dentro del cluster y no requiere abrir puertos en el firewall.
¿Para qué sirve NodePort y cuándo usarlo?
NodePort expone tu aplicación a clientes externos abriendo un puerto en todos los nodos. Sirve para desarrollo, testing y ambientes on-premise sin balanceador de carga. En producción con cloud gestionado (AKS, GKE, EKS), usá LoadBalancer en su lugar.