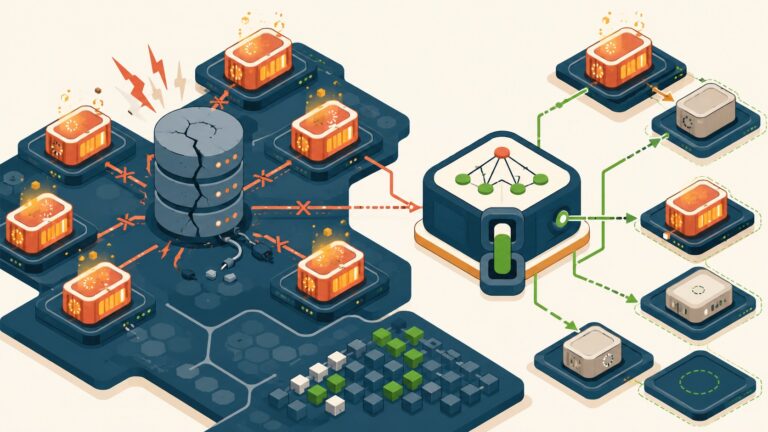
Sharding multinube con arquitectura hexagonal 2026
El sharding de datos multinube es la técnica de particionamiento horizontal que divide una base de datos en fragmentos (shards) distribuidos entre múltiples proveedores cloud y regiones geográficas, enrutando cada consulta según metadatos del tenante. No es replicación: cada shard tiene datos únicos, no copias. Y en 2026, con GDPR, LGPD y leyes de residencia de datos que proliferan en toda Latinoamérica y Europa, esta arquitectura dejó de ser un lujo para convertirse en requisito legal para cualquier SaaS que opere en más de un país.
En 30 segundos
- El sharding de datos multinube distribuye fragmentos de base de datos entre proveedores (AWS, Azure) según la jurisdicción del tenante, sin duplicar datos.
- La arquitectura hexagonal desacopla la lógica de negocio del almacenamiento: cambiás el proveedor sin tocar el dominio.
- Stack requerido: Terraform 1.8.0+, AWS Provider 5.45+, AzureRM 3.95+, Python 3.12, SQLAlchemy 2.0, Pydantic.
- GDPR (Europa) y LGPD (Brasil) obligan a que ciertos datos no crucen fronteras; el sharding por región es la solución técnica más limpia.
- Los desafíos reales son la consistencia entre shards, el agotamiento de connection pools y la visibilidad centralizada en entornos distribuidos.
Microsoft es una empresa de tecnología multinacional fundada por Bill Gates y Paul Allen en 1975 que desarrolla software, sistemas operativos y servicios en la nube. Sus productos principales son Windows, Office, Azure y Xbox.
Qué es el sharding de datos y por qué importa en multinube
Sharding es particionamiento horizontal: en vez de tener una tabla con 100 millones de filas, la dividís en 10 tablas de 10 millones cada una, cada una viviendo en un servidor (o cloud) diferente. Cada fila pertenece exactamente a un shard. Replicación, en cambio, copia los mismos datos en múltiples lugares para disponibilidad o performance de lectura. Son conceptos distintos y confundirlos lleva a arquitecturas que mezclan los dos sin resolver ninguno bien.
¿Por qué el sharding multinube se volvió urgente? Una base de datos centralizada en us-east-1 introduce dos problemas concretos cuando operás en múltiples países: latencia para usuarios que están a 15.000 km del servidor, y violación de leyes que dicen que ciertos datos no pueden salir del territorio. El costo de transferencia de datos cross-region en AWS o Azure no es trivial tampoco (ponele, entre 0.02 y 0.09 USD por GB según la ruta), y si cada consulta de un usuario en São Paulo viaja a Frankfurt ida y vuelta, eso se acumula.
Requisitos regulatorios: GDPR, LGPD y residencia de datos
Residencia de datos y soberanía de datos no son lo mismo. Residencia de datos significa que los datos deben almacenarse físicamente en una ubicación geográfica específica. Soberanía de datos agrega la capa legal: qué jurisdicción tiene autoridad sobre esos datos. Podés tener datos alojados en Argentina pero bajo ley irlandesa, o datos en Alemania bajo ley alemana. Los contratos SaaS modernos mezclan los dos conceptos y eso suele ser origen de dolores de cabeza legales.
GDPR (Reglamento General de Protección de Datos, vigente en la Unión Europea) prohíbe transferir datos personales a países sin nivel de protección adecuado sin salvaguardias específicas. LGPD (Lei Geral de Proteção de Dados, Brasil) tiene requerimientos similares para datos de ciudadanos brasileños. Las multas del GDPR pueden llegar al 4% de la facturación global anual o 20 millones de euros (lo que sea mayor). LGPD permite sanciones de hasta 2% de la facturación en Brasil, con tope de 50 millones de reales.
El resultado práctico: una cooperativa de vivienda brasileña que usa tu SaaS necesita que sus datos residan en Azure South Brazil. Una empresa con sede en Frankfurt necesita sus datos en AWS eu-central-1. Con una base de datos centralizada, cumplir con ambos es prácticamente imposible sin hacer dos deployments completos de la aplicación. Con sharding multinube y arquitectura hexagonal, es un problema de routing, no de infraestructura duplicada.
Arquitectura hexagonal como solución de desacoplamiento
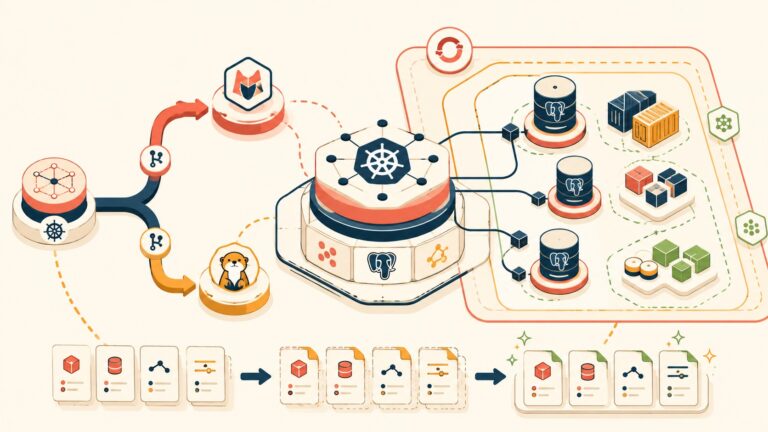
El patrón hexagonal (también conocido como puertos y adaptadores, propuesto por Alistair Cockburn) separa el núcleo de dominio de la aplicación de todo lo externo: bases de datos, APIs, UIs, mensajería. El dominio define puertos (interfaces abstractas de lo que necesita). Los adaptadores implementan esas interfaces para tecnologías específicas. Más contexto en pipelines de deployment con GitHub Actions.
En el contexto de sharding multinube, eso se traduce así: la lógica de negocio no sabe si los datos están en PostgreSQL Aurora de AWS o en Azure SQL Serverless. Le habla a un puerto abstracto llamado, por ejemplo, StorageRepository. Un router de sharding, que vive en la capa de adaptadores, lee los metadatos del tenante (región, entidad legal, país) y decide a qué adaptador concreto enviar cada operación.
Comparado con una arquitectura monolítica acoplada, donde el código de negocio tiene strings de conexión hardcodeadas o condiciones if proveedor == "aws" metidas en el medio del dominio: un horror de mantener, imposible de testear en aislamiento, y que explota en la cara cada vez que necesitás agregar un proveedor nuevo. (Spoiler: siempre necesitás agregar un proveedor nuevo.)
Requisitos técnicos y stack necesario
Según el artículo técnico publicado el 13 de mayo de 2026, el stack mínimo para implementar esta arquitectura es:
- Terraform 1.8.0 o superior: para orquestar el estado cross-cloud de ambos proveedores en un solo plan. Versiones anteriores tienen limitaciones con el manejo de providers múltiples en un mismo módulo.
- AWS Provider 5.45+ y AzureRM Provider 3.95+: las versiones específicas importan porque el esquema de recursos cambió en estas versiones.
- Python 3.12 con SQLAlchemy 2.0 (para abstracción de base de datos) y Pydantic (para validación estricta de datos de tenantes).
- Bases de datos: PostgreSQL Aurora en AWS (lado Amazon) y Azure SQL Serverless en Azure (lado Microsoft).
- Credenciales aisladas por shard: IAM Roles con políticas mínimas para el shard AWS, Service Principals para el shard Azure. Nunca credenciales compartidas entre shards.
El requisito más subestimado: conocimiento avanzado de Domain-Driven Design para identificar correctamente las sharding keys. Si elegís mal la clave de particionamiento, terminás con hot spots donde el 80% de las consultas van a un solo shard, o con queries que necesitan join entre dos shards (que en multinube es una pesadilla de latencia). DDD te da el framework para identificar aggregates y bounded contexts, que en general mapean bien a sharding keys naturales.
Implementación paso a paso del sharding multinube
Paso 1: Definir la sharding key
La sharding key determina en qué shard termina cada registro. Para casos de compliance regulatorio, la clave natural es la combinación de tenant_id + legal_entity_country. Un tenante con entidad legal en Brasil siempre va al shard brasileño. Uno con entidad en Alemania, al shard europeo. El router consulta una tabla de metadatos de tenantes (que sí puede vivir en un storage centralizado, porque no tiene datos personales) para resolver el destino de cada operación.
Paso 2: Terraform para orquestar ambos proveedores
Con Terraform 1.8.0+, configurás dos providers en el mismo módulo:
provider "aws" {
region = "sa-east-1" # São Paulo
}
provider "azurerm" {
features {}
# South Brazil region
}El state de Terraform maneja ambos en un solo backend (recomendado: S3 con locking via DynamoDB, o Azure Blob Storage si preferís unificar ahí). Ojo con el chicken-and-egg problem: para crear el backend en S3 necesitás AWS configurado primero, para el backend en Azure necesitás Azure. Usá remote state o bootstrap manual para el primer deployment.
Paso 3: Router de consultas basado en metadatos
El router en Python 3.12 con SQLAlchemy 2.0 es el corazón del sistema. Recibe la operación, consulta los metadatos del tenante, y retorna la sesión de base de datos correcta:
class ShardRouter:
def get_session(self, tenant_id: str) -> Session:
metadata = self.tenant_registry.get(tenant_id)
if metadata.legal_country == "BR":
return self.azure_brazil_session
elif metadata.legal_country in EU_COUNTRIES:
return self.aws_frankfurt_session
raise UnsupportedRegionError(tenant_id)El dominio llama a router.get_session(tenant_id) y trabaja con la sesión. No sabe nada de Azure ni AWS. Sobre eso hablamos en SEO técnico multiidioma.
Desafíos comunes y cómo resolverlos
Acá viene lo bueno: la teoría es elegante, pero los problemas de producción son concretos.
Agotamiento de connection pools: cada shard necesita su propio pool de conexiones. Con 10 shards y SQLAlchemy configurado para 20 conexiones por pool, tu aplicación abre 200 conexiones simultáneas en picos. La solución es RDS Proxy del lado AWS (gestiona el pool y reutiliza conexiones) y Azure SQL Serverless con connection pooling habilitado del lado Azure. Sin esto, el primer pico de tráfico real deja tu aplicación sin conexiones disponibles.
Consistencia entre shards: si una operación de negocio necesita escribir en dos shards (raro pero posible en transfers entre tenantes de distintas regiones), tenés un problema de transacciones distribuidas. Dos opciones viables: el patrón Saga (orquestás pasos compensatorios si algo falla) o Two-Phase Commit (más robusto pero mucho más lento y con más puntos de falla). La mayoría de los casos reales se pueden rediseñar para evitar escrituras cross-shard. Si no podés, Saga es el camino menos doloroso.
Visibilidad centralizada: con datos distribuidos en múltiples shards y nubes, hacer un query de auditoría “dame todos los registros de hoy” se vuelve una operación fan-out. Necesitás un data warehouse centralizado (que SÍ puede estar en una región, porque agrega datos anonimizados/agregados) o una capa de observabilidad como OpenTelemetry que trace cada operación con su shard de origen.
| Problema | Solución AWS | Solución Azure |
|---|---|---|
| Connection pool exhaustion | RDS Proxy | Azure SQL Serverless pooling |
| Transacciones cross-shard | Saga Pattern + SQS | Saga Pattern + Service Bus |
| Latencia de lecturas | ElastiCache (caché local) | Azure Cache for Redis |
| Visibilidad centralizada | CloudWatch + Athena | Azure Monitor + Log Analytics |
| Disaster recovery | Aurora Global Database | Azure SQL Geo-replication |
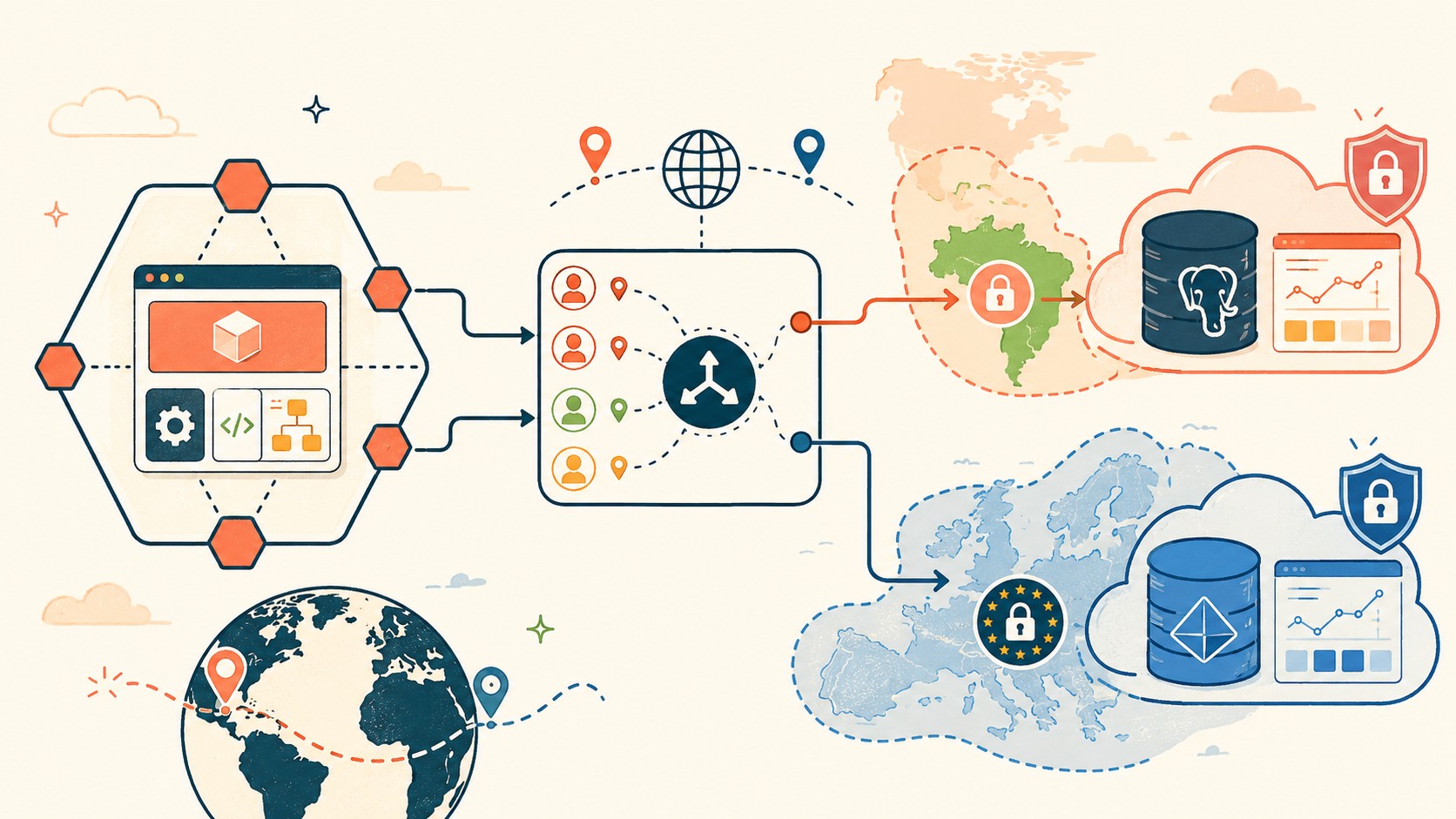
Casos de uso reales y ejemplos concretos
Cooperativa de vivienda en Brasil con sucursales en Europa
El caso que describe la fuente técnica es exactamente este: una cooperativa con operaciones en Brasil necesita que todos los datos de sus socios brasileños residan en Azure South Brazil (por LGPD). Sus socios europeos, en AWS Frankfurt (por GDPR). Sin sharding, tendrían que deployar dos instancias completas de la aplicación, con bases de código separadas o con flags de configuración que convierten el mantenimiento en un calvario. Con la capa de sharding hexagonal, es una sola codebase, un solo pipeline de CI/CD, y el router maneja el desvío transparentemente.
SaaS multinacional con clientes en múltiples regiones
Ponele que tenés un SaaS de recursos humanos con clientes en Argentina, Colombia, España y Alemania. Cada país tiene regulaciones distintas sobre retención de datos de empleados (desde 5 años hasta indefinido dependiendo del tipo de dato). Con sharding por tenant_country, podés aplicar políticas de retención diferentes por shard sin complicar el código de la aplicación: la política de retención vive en la configuración del shard, no en el dominio.
¿Y qué pasó cuando equipos sin esta arquitectura intentaron escalar globalmente? Exacto: migraciones de datos dolorosas, auditorías fallidas, y en algunos casos multas regulatorias que salieron más caras que haber diseñado bien desde el principio. Esto se conecta con lo que analizamos en tests confiables en CI/CD.
Qué significa para empresas y equipos en Latinoamérica
Si tenés un SaaS con clientes en Brasil y en Europa (o si planeás tenerlos), la LGPD y el GDPR no son problemas que podés patear para después. Brasil es el mercado de software más grande de América Latina y la LGPD tiene dientes: la Autoridade Nacional de Proteção de Dados (ANPD) viene siendo más activa desde 2025.
Para equipos que recién están arquitectando su producto, el momento de incorporar sharding multinube es antes de tener 100.000 usuarios, no después. La migración de una base de datos monolítica a sharding cuando ya tenés datos en producción es uno de los proyectos más riesgosos que puede encarar un equipo de ingeniería. Si estás evaluando infraestructura para este tipo de proyecto, donweb.com tiene opciones de cloud en la región que pueden funcionar como punto de partida para la capa de orquestación o para staging environments.
Qué está confirmado / Qué todavía no está claro
- Confirmado: El stack técnico completo (Terraform 1.8.0+, Python 3.12, SQLAlchemy 2.0, Pydantic) según la documentación técnica publicada en mayo de 2026.
- Confirmado: Las versiones específicas de providers (AWS 5.45+, AzureRM 3.95+) son requisitos mínimos, no recomendaciones.
- Confirmado: PostgreSQL Aurora (AWS) y Azure SQL Serverless (Azure) como bases de datos recomendadas para cada cloud respectivamente.
- No confirmado: Benchmarks concretos de performance (latencia promedio, throughput) para la implementación descrita. El artículo fuente no publica números propios y los datos de Microsoft Azure Sharding Pattern son genéricos.
- No confirmado: Soporte nativo para más de dos providers cloud simultáneos en el mismo router. El ejemplo cubre AWS + Azure; GCP requeriría un adaptador adicional no documentado aún.
Errores comunes al implementar sharding multinube
Error 1: Elegir la sharding key por performance, no por compliance. Muchos equipos eligen el tenant_id más “balanceado” para distribuir carga, y después se dan cuenta de que varios tenantes de la misma región legal terminan en shards distintos. El resultado: violaciones de residencia de datos involuntarias. La sharding key para arquitecturas reguladas debe derivar de la jurisdicción legal, no del hash del ID.
Error 2: Compartir credenciales entre shards. Si tu router usa las mismas credenciales para acceder al shard de Brasil y al de Frankfurt, perdiste el aislamiento de seguridad. Una fuga de credenciales compromete todos los shards simultáneamente. IAM Roles separados por shard en AWS y Service Principals distintos en Azure son el mínimo indispensable.
Error 3: No testear el router en aislamiento. La arquitectura hexagonal te da la herramienta para esto: el router es un adaptador, tiene que ser testeable sin levantar bases de datos reales. Si tus tests de router requieren conectividad a AWS y Azure para correr, el diseño tiene un problema. Mockeá los adaptadores de storage en los tests del router; guardá los tests de integración para el pipeline de CI con credenciales reales.
Error 4: Ignorar el metadata store. La tabla de metadatos de tenantes (que mapea tenant_id a shard) es un single point of failure crítico. Si ese store no está disponible, el router no puede enrutar nada. Necesita alta disponibilidad, caché en memoria con TTL razonable, y un circuit breaker para fallar gracefully en vez de colgar threads esperando respuesta.
Mejores prácticas y gobernanza de datos
La gobernanza no termina cuando el router funciona. Necesitás un inventario actualizado de dónde residen los datos de cada tenante, auditable por reguladores. Cifrado en tránsito (TLS 1.3 mínimo) y en reposo (AES-256 en ambas nubes) para todos los shards. Políticas de retención configuradas por shard y automatizadas: si la ley alemana requiere retener datos de empleados por 6 años y la brasileña por 5, eso se configura en la capa de infraestructura de cada shard, no en el código de la aplicación.
Tenés que tener, además, un playbook de disaster recovery que cubra la pérdida de un shard completo. Aurora tiene Global Database para failover cross-region; Azure SQL Serverless tiene geo-replication activa-pasiva. Ambos necesitan tests periódicos de failover, no solo configuración inicial. Complementá con estrategias de arquitectura multi-cloud.
Esto se conecta con Implementing Multicloud Data Sharding with Hexagonal Storage, donde cubrimos el tema en profundidad.
Preguntas Frecuentes
¿Cómo puedo implementar sharding de datos en un entorno multinube?
Necesitás tres componentes: un metadata store con el mapeo tenant→shard, un router que lea esos metadatos y seleccione el adaptador correcto, y adaptadores concretos para cada proveedor cloud. El stack documentado para 2026 usa Terraform 1.8.0+ para infraestructura, Python 3.12 con SQLAlchemy 2.0 para el router, y bases de datos específicas por cloud (Aurora en AWS, Azure SQL Serverless en Azure). La clave es que el dominio de la aplicación solo habla con interfaces abstractas; el router decide el destino en tiempo de ejecución según los metadatos del tenante.
¿Qué es la arquitectura hexagonal para almacenamiento de datos?
La arquitectura hexagonal (puertos y adaptadores) separa el núcleo de dominio de la aplicación de las implementaciones concretas de infraestructura. En el contexto de storage multinube, el dominio define un puerto abstracto como StorageRepository; cada cloud provider tiene su adaptador concreto que implementa ese puerto. Cambiás de PostgreSQL Aurora a Azure SQL sin modificar una línea del dominio. Es la diferencia entre un sistema mantenible y uno donde toda migración de proveedor se convierte en una reescritura parcial.
¿Cómo cumplir GDPR y LGPD con datos distribuidos en la nube?
La clave es que los datos de cada jurisdicción nunca salgan de su región asignada. Con sharding por legal_entity_country, todos los datos de tenantes brasileños se almacenan en Azure South Brazil (LGPD) y los datos europeos en AWS Frankfurt o similar dentro de la UE (GDPR). El router de sharding garantiza el enrutamiento correcto en cada operación de escritura y lectura. Adicionalmente, necesitás cifrado en reposo en cada shard, políticas de retención por región, y un inventario auditable de dónde residen los datos de cada tenante.
¿Cuál es la diferencia entre sharding y replicación de datos?
Sharding divide los datos: cada registro existe en exactamente un shard, no hay duplicados. Replicación copia los mismos datos en múltiples lugares para disponibilidad o performance de lectura. Con sharding, un usuario brasileño consulta el shard Brasil y solo ve datos de tenantes brasileños; no existe ese registro en el shard europeo. Con replicación, el mismo dato está en múltiples regiones simultáneamente. Para cumplimiento regulatorio de residencia de datos, el sharding es la solución correcta: la replicación cross-región puede violar GDPR si copia datos europeos fuera de la UE.
¿Cuáles son los desafíos principales de una estrategia multinube para datos?
Los tres más frecuentes en producción son: agotamiento de connection pools (solucionable con RDS Proxy en AWS y connection pooling en Azure SQL), inconsistencia de estado en operaciones cross-shard (requiere Saga Pattern o Two-Phase Commit), y falta de visibilidad centralizada para auditoría (necesitás OpenTelemetry o un data warehouse de agregados). El desafío menos visible pero más impactante es elegir mal la sharding key al inicio: una vez que tenés datos en producción, remapear tenantes entre shards es una operación de migración costosa y riesgosa.
Conclusión
El sharding de datos multinube con arquitectura hexagonal no es una tendencia de 2026: es la respuesta técnica a un problema regulatorio que existe desde que GDPR entró en vigor en 2018 y que se aceleró con LGPD en Brasil. Lo que cambió en 2026 es que el stack para implementarlo es más maduro: Terraform maneja el estado cross-cloud con menos fricción, SQLAlchemy 2.0 simplifica la abstracción de bases de datos heterogéneas, y los proveedores cloud tienen servicios de proxy y pooling que resuelven los problemas operativos más comunes.
Si estás construyendo un SaaS con clientes en más de un país, la pregunta no es si vas a necesitar esto, sino cuándo. Diseñarlo desde el inicio con arquitectura hexagonal es infinitamente más barato que migrar una base de datos monolítica de 50 millones de filas cuando un cliente nuevo te pide compliance regional. El código del dominio no debería saber dónde viven los datos. Ese conocimiento pertenece al router, y el router pertenece a la capa de adaptadores.
Fuentes
- dev.to / sertaoseracloud – Implementing Multicloud Data Sharding with Hexagonal Storage Adapters (2026)
- Microsoft Azure – Patrón de particionamiento (Sharding Pattern) en arquitecturas cloud
- AWS – Hexagonal Architecture en Cloud Design Patterns
- AWS Blog en español – Particionamiento horizontal (sharding) con Amazon RDS
- Microsoft Azure Well-Architected Framework – Guía de particionamiento de datos