Arquitectura escalable para startups en 2026
La arquitectura escalable para startups no es un lujo técnico: es la diferencia entre un sistema que aguanta el crecimiento y uno que te explota en la cara cuando llegás a 10.000 usuarios. Según el análisis publicado en mayo de 2026, el principio clave es construir para el próximo orden de magnitud, no para la próxima década.
En 30 segundos
- El cuello de botella más común en startups es la base de datos mal diseñada desde el inicio, no el servidor ni el código.
- Los monolitos escalan mucho más de lo que la mayoría cree: migrar a microservicios antes de tiempo destruye equipos pequeños.
- Servicios stateless + Redis para sesiones = capacidad de escala horizontal sin fricción.
- Monitoreo desde el día uno (Sentry, Datadog) no es burocracia, es la única forma de saber qué rompió y cuándo.
- Las llamadas sincrónicas a APIs externas son una bomba de tiempo: siempre usá colas asíncronas.
El dilema de las startups: escalar rápido vs escalar bien
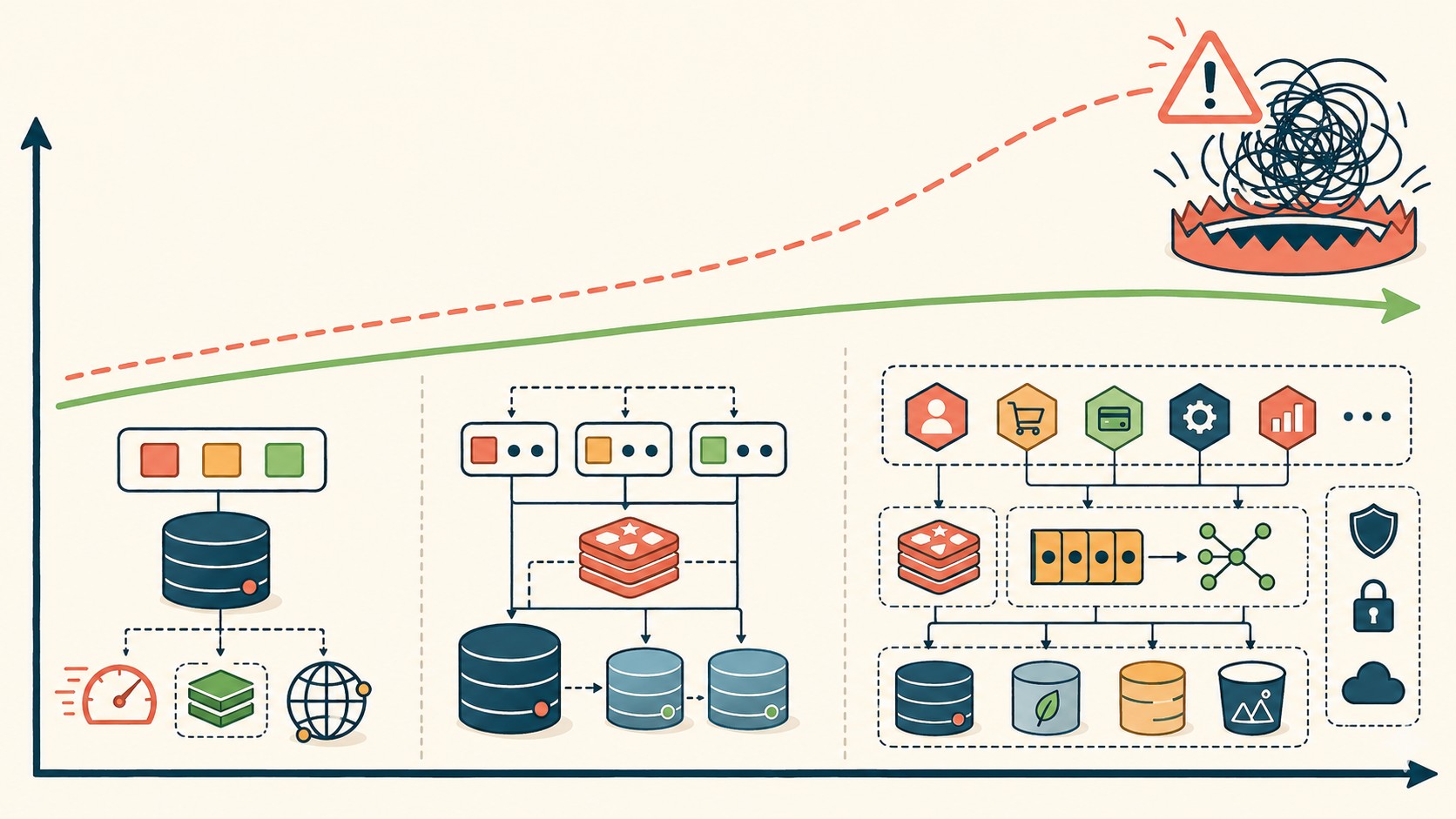
La arquitectura escalable para startups es el conjunto de decisiones técnicas que permiten a un sistema crecer en usuarios, tráfico y datos sin necesitar una reescritura completa cada vez que el volumen se multiplica. No es una tecnología específica ni un framework: es una forma de diseñar desde el inicio con crecimiento en mente.
Ponele que lanzás tu MVP con 50 usuarios. Todo anda perfecto. Llegás a 500 y hay alguna lentitud. A 5.000 el sistema empieza a hacer agua y a 50.000 te comés una noche de producción rota frente al cliente más importante que tuviste. No porque el código sea malo. Sino porque nadie pensó en ese momento qué pasaría cuando la carga se multiplicara por mil.
El problema es que también existe la trampa opuesta. Hay startups que construyeron microservicios, Kubernetes, event sourcing y una arquitectura digna de Netflix… con tres usuarios en beta. (Spoiler: el equipo colapsó de complejidad antes de llegar al lanzamiento real.)
Según el playbook publicado en 2026, el equilibrio está en construir para el próximo orden de magnitud, no para el siguiente lustro. Si tenés 100 usuarios, diseñá para aguantar 10.000. Cuando llegués a 10.000, empezá a prepararte para 100.000. Y así.
La base de datos: tu cuello de botella principal
El servidor aguanta. El CDN aguanta. Tu código probablemente aguanta. Lo que no aguanta casi siempre es la base de datos, y es lo primero que hay que diseñar bien.
Hay una regla simple que salva proyectos: normalizá hasta tener una razón concreta para denormalizar. Mucha gente denormaliza prematuramente porque “creen” que va a ser más rápido, sin haber medido nada. Después tienen datos inconsistentes y queries imposibles de mantener. El principio correcto es: normalizá primero, optimizá cuando los números te lo pidan.
Indexá los foreign keys y los patrones de query que ya sabés que vas a usar. Esto suena obvio pero 100 usuarios no te va a mostrar el problema: con 10.000 usuarios una tabla sin índice se convierte en una full scan que bloquea todo. El problema existe desde el día uno, solo que todavía no te duele. Más contexto en automatización de despliegues confiable.
Dos cosas que tenes que implementar antes de creer que las necesitás: connection pooling y planificación de read replicas. El connection pooling (PgBouncer para PostgreSQL, por ejemplo) evita que cada request abra y cierre conexiones a la DB, que es uno de los costos más silenciosos. Las read replicas no las necesitás hoy, pero si no diseñás para poder agregarlas, cuando las necesites vas a tener que refactorizar todo el acceso a datos.
Servicios sin estado: prepararse para crecer horizontalmente
Si tus application servers guardan estado en memoria, tenés un techo de escala. Cuando el tráfico sube y necesitás levantar una segunda instancia del servidor, ¿qué pasa con las sesiones activas? Si están en memoria del servidor 1, el usuario conectado al servidor 2 no las ve. Necesitás sticky sessions, que es básicamente parchar el problema en vez de resolverlo.
La solución es stateless: los servidores de aplicación no guardan nada. Las sesiones van a Redis. Las colas van a Redis o a un broker. Los archivos van a object storage (S3, equivalentes). Con eso podés levantar diez servidores adicionales en minutos sin que ningún usuario note nada, porque cualquier servidor puede atender cualquier request.
¿Y la penalización de performance por ir a Redis en cada request? Con Redis en la misma red privada, el round-trip es de menos de 1ms. No es un problema real.
Caching y CDN: optimizar sin infraestructura costosa
Antes de agregar servidores, cacheá. Es más barato, más rápido de implementar y resuelve el 80% de los problemas de performance.
Hay tres capas donde el caching tiene impacto real:
- Static assets: imágenes, CSS, JS con cache-control de 1 año. Si tu app sirve assets directamente desde el servidor de aplicación, estás desperdiciando recursos en tráfico que podría estar cacheado en el borde.
- CDN: mové los assets a un CDN. Cloudflare en su tier gratuito resuelve la mayoría de los casos para startups tempranas. El beneficio no es solo velocidad: también reduce dramáticamente el tráfico que llega a tu infraestructura.
- Application-level cache: Redis para queries frecuentes, resultados de operaciones costosas, o cualquier dato que se lee mucho y se escribe poco. La regla práctica: si la misma query aparece más de una vez por segundo, cacheála.
Ojo con el cache de base de datos: no es magia. Si cacheás datos que cambian seguido sin invalidar bien el cache, tenés usuarios viendo información desactualizada. Hay que pensar en la estrategia de invalidación desde el inicio. Relacionado: alcanza mercados internacionales sin duplicación.
Microservicios vs monolito: cuándo está listo tu crecimiento
Los monolitos escalan más de lo que la mayoría cree. Este punto es probablemente el más contraintuitivo del playbook de 2026, pero tiene décadas de evidencia detrás.
Stack Exchange manejó millones de requests diarios con nueve servidores y un monolito durante años. Shopify fue un monolito Rails hasta que procesó miles de millones en GMV. El monolito no es el enemigo. El monolito mal diseñado, sí.
Los microservicios tienen sentido cuando se cumplen condiciones específicas: equipo de más de diez personas donde diferentes grupos necesitan desplegar independientemente, módulos con necesidades de escala radicalmente distintas (por ejemplo, el módulo de procesamiento de video necesita diez veces más recursos que el de autenticación), o dominios que evolucionan a velocidades muy diferentes.
Antes de eso, los microservicios te generan complejidad operativa que un equipo chico no puede absorber: service discovery, distributed tracing, eventual consistency, gestión de versiones de APIs internas. Todo eso tiene un costo real en tiempo de ingeniería que no estás invirtiendo en features.
La transición no es todo o nada. Podés empezar extrayendo servicios específicos del monolito cuando el dolor es real y medible, manteniendo el core como monolito. Eso es mucho más manejable que reescribir todo de cero.
Monitoreo desde el primer día: observabilidad como inversión
Mucha gente trata el monitoreo como algo para “cuando tengamos usuarios de verdad”. Error. Complementá con distribución global de tu contenido.
Si instalás Sentry cuando ya tenés errores en producción, no sabés qué estaba pasando antes de que el problema se volviera visible. Si instalás Datadog cuando el sistema ya está lento, no tenés baseline para comparar. El monitoreo sin datos históricos vale la mitad.
El stack mínimo que tiene sentido desde el día uno:
- Error tracking: Sentry. Gratis hasta cierto volumen, fácil de integrar en cualquier stack. Cada excepción no capturada en producción llega a tu inbox.
- Performance monitoring: Datadog o New Relic para medir latencia, throughput y saturación. Las alertas en métricas de latencia te avisan antes de que el usuario note algo.
- Uptime monitoring: Pingdom o UptimeRobot verifican cada pocos minutos que tu servicio responde. Básico pero imprescindible.
- Log aggregation: LogRocket o Datadog Logs para centralizar logs de múltiples servicios. Sin esto, debuguear un problema que involucra más de un componente es una pesadilla.
El costo de esto para una startup early-stage ronda los USD 50-100/mes. El costo de no tenerlo cuando algo falla en producción es incalculable.
Anti-patrones que destruyen startups
Hay errores que aparecen siempre, en equipos de todos los tamaños, y que según el análisis de over-engineering en startups tech son los responsables de la mayoría de los problemas de escalabilidad.
Microservicios prematuros
Ya lo discutimos, pero vale repetirlo: dividir en microservicios antes de entender los límites naturales del dominio garantiza que vas a cortar por lugares incorrectos. Después tenés servicios fuertemente acoplados que son peor que el monolito original, con toda la complejidad operativa encima.
Falta de índices en la base de datos
Con 100 usuarios una tabla sin índice tarda 2ms. Con 10.000 usuarios tarda 2 segundos. Con 100.000 usuarios, tu app está caída. El problema existía desde el principio, solo se volvió visible con escala. Revisá el plan de ejecución de las queries principales antes de lanzar, no después.
Llamadas sincrónicas a APIs externas
Ponele que tu app llama a una API de pagos en el medio del flujo de checkout. Si esa API tiene un spike de latencia de 3 segundos, tu servidor mantiene el thread bloqueado durante ese tiempo. Con suficiente tráfico, agotás el thread pool y tu app empieza a rechazar requests. La solución es siempre la misma: poné esa llamada en una cola asíncrona y respondé al usuario inmediatamente.
Sin rate limiting
Un usuario haciendo scraping o un bot mal configurado puede generar suficiente tráfico para tirar tu app. Rate limiting a nivel de IP y de usuario autenticado no es paranoia, es higiene básica. Y se puede implementar en Nginx o en el API gateway sin tocar código de aplicación. Ya lo cubrimos antes en infraestructura de borde para baja latencia.
Ignorar cold starts en serverless
Si usás funciones serverless (Lambda, Cloud Functions), el cold start puede agregar 500ms-2000ms a las primeras requests después de períodos de inactividad. Para algunos casos de uso eso es aceptable. Para otros, destruye la experiencia de usuario. Hay que tener estrategias de warm-up o considerar si serverless es la elección correcta para ese componente.
Comparativa de etapas de escala
| Etapa | Usuarios aproximados | Prioridad técnica | Qué evitar |
|---|---|---|---|
| MVP | 0 – 1.000 | DB bien diseñada, monitoreo básico, stateless desde el inicio | Microservicios, over-engineering |
| Early growth | 1.000 – 10.000 | Caching, CDN, read replicas, rate limiting | Reescrituras prematuras |
| Scale | 10.000 – 100.000 | Extraer servicios de mayor carga, sharding, auto-scaling | Monolito sin modularización interna |
| Hypergrowth | 100.000+ | Arquitectura de microservicios con equipos dedicados | Mantener un solo punto de deployment |
Qué significa esto para equipos en Latinoamérica
El contexto local agrega una capa de complejidad: los costos de infraestructura en dólares pesan más para startups que generan ingresos en pesos o reales. Eso hace que la eficiencia arquitectónica no sea solo un tema de performance, sino directamente un tema de costos operativos.
La buena noticia es que la mayoría de los principios de este playbook son gratis de implementar: stateless services no cuesta nada, buenos índices tampoco, y herramientas como Sentry tienen tiers gratuitos que cubren el early stage. Para hosting y cloud en la región, donweb.com tiene infraestructura argentina con latencia local, que para apps B2C con usuarios en Argentina hace diferencia real.
Si querés profundizar en esto, tenemos Scalable Architecture for Startups: Build for Growth Without que trata el tema en detalle.
Si querés ver cómo escala todo esto, mirá nuestro artículo sobre Scalable Architecture for Startups: Build for Growth Without.
Podés encontrar más sobre esto en Scalable Architecture for Startups: Build for Growth Without, donde detallamos la arquitectura.
Esto se conecta directamente con Scalable Architecture for Startups: Build for Growth Without, donde cubrimos la escalabilidad en detalle.
Preguntas Frecuentes
¿Cómo construir una arquitectura escalable desde el inicio sin sobre-complicar?
Empezá con un monolito bien estructurado internamente, base de datos normalizada con índices correctos, servicios stateless y monitoreo desde el día uno. Esas cuatro decisiones cubren el 90% de los problemas de escala hasta los 100.000 usuarios. Agregás complejidad solo cuando tenés datos concretos que la justifican, no antes.
¿Cuándo tiene sentido pasar de monolito a microservicios?
Cuando el equipo supera las 10 personas y diferentes grupos necesitan deployar independientemente, cuando hay módulos con necesidades de recursos radicalmente distintas, o cuando el monolito tiene cuellos de botella específicos que no se resuelven con optimización. Antes de esas condiciones, los microservicios generan más problemas de los que resuelven.
¿Cuáles son los errores de arquitectura más comunes en startups early-stage?
Microservicios prematuros, tablas sin índices (que no duelen con 100 usuarios pero destruyen la performance con 10.000), llamadas sincrónicas a APIs externas dentro del flujo crítico, y ausencia de rate limiting. Según el análisis de 2026, estos cuatro patrones son responsables de la mayoría de las crisis de escala.
¿Qué herramientas de monitoreo recomienda el playbook de 2026?
Sentry para error tracking, Datadog o New Relic para performance monitoring, Pingdom o UptimeRobot para uptime, y LogRocket o Datadog Logs para centralización de logs. El costo combinado para early-stage ronda los USD 50-100/mes, con opciones gratuitas que cubren los primeros meses.
¿Por qué los servicios stateless son importantes para escalar horizontalmente?
Si el servidor guarda estado en memoria, agregar una segunda instancia requiere sticky sessions o sincronización de estado entre servidores, lo que crea complejidad y fragilidad. Con servicios stateless (sesiones en Redis, archivos en object storage), cualquier instancia puede atender cualquier request y podés agregar o quitar servidores sin afectar a los usuarios.
Conclusión
El playbook de arquitectura escalable para startups publicado en 2026 no trae ideas nuevas: trae orden en decisiones que muchos equipos postergan hasta que el dolor es real. Base de datos bien diseñada, servicios stateless, caching por capas, monitoreo desde el inicio y resistencia a los microservicios prematuros. Eso es todo.
Lo que cambia en 2026 es el costo de ignorarlo. Con más competencia, más usuarios exigentes y costos de infraestructura presionados, una noche de producción caída por un índice que faltaba o un thread pool agotado tiene consecuencias que antes tardaban meses en llegar y ahora llegan en horas.
Si estás arrancando hoy, la inversión es mínima: implementar estos principios desde el MVP cuesta pocas horas de diseño y te ahorra semanas de refactoring bajo presión. Si ya tenés un sistema funcionando, el diagnóstico más útil es revisar los anti-patrones de la lista y ver cuántos aplican. Probablemente más de los que esperás.
Fuentes
- Dev.to – Scalable Architecture for Startups: Build for Growth Without Over-Engineering (2026)
- Ecosistema Startup – Over-engineering: riesgos y mejores prácticas en startups tech
- Startups Españolas – Scaling: qué es la escalabilidad y cómo aplicarla en startups
- Microsoft Azure – Guía de arquitectura para startups