RAG en PostgreSQL con pgEdge: búsqueda híbrida 2026
RAG en PostgreSQL dejó de ser un experimento de laboratorio. Con el pgEdge RAG Server, cualquier equipo puede montar un pipeline de recuperación aumentada directamente sobre su base de datos Postgres existente, sin infraestructura adicional, usando búsqueda híbrida que combina similitud vectorial y BM25 para respuestas con citas reales de documentación.
En 30 segundos
- pgEdge lanzó su RAG Server como servicio gestionado en pgEdge Cloud, deployable junto a tu base de datos existente sin infraestructura adicional.
- El servidor usa búsqueda híbrida (vector similarity + BM25) con Reciprocal Rank Fusion para combinar resultados, lo que mejora la precisión sobre búsqueda puramente vectorial.
- Es open source bajo licencia PostgreSQL, binario único en Go, compatible con PostgreSQL 14+ y pgvector, con soporte para OpenAI, Anthropic, Voyage y Ollama local.
- Ellie, el chatbot de documentación de pgEdge, corre sobre este mismo servidor y responde preguntas sobre replicación multi-master sin alucinar gracias al grounding en docs reales.
- Para la mayoría de los proyectos B2B en 2026, pgvector dentro de Postgres es suficiente. Bases de datos vectoriales separadas tienen sentido recién a partir de los 10 millones de vectores.
OpenAI es una empresa estadounidense de investigación en inteligencia artificial fundada en 2015 que desarrolla modelos de lenguaje grandes como GPT y ChatGPT para procesar y generar texto.
¿Qué es RAG en PostgreSQL y por qué tiene sentido en 2026?
RAG (Retrieval-Augmented Generation) es una técnica donde, antes de pedirle al LLM que genere una respuesta, recuperás fragmentos de texto relevantes desde tu propia base de datos y se los pasás como contexto. El modelo no alucina porque tiene las fuentes delante. RAG en PostgreSQL es eso, pero usando Postgres como almacén vectorial en vez de una base de datos especializada.
El cambio de paradigma en 2026 es claro: el bottleneck ya no está en la generación, está en la recuperación. GPT-4o genera texto en segundos. Lo que determina si la respuesta es útil o una invención es qué tan bien recuperaste los fragmentos correctos.
Ponele que armás un chatbot de soporte técnico para tu SaaS. Si el LLM no tiene acceso a tus docs, va a inventar procedimientos que no existen en tu producto (y los inventará con confianza). Con RAG, buscás los fragmentos de documentación más relevantes para la pregunta del usuario, se los pasás al modelo, y la respuesta cita las fuentes reales.
La pregunta que viene después: ¿necesitás una base de datos vectorial separada? En la mayoría de los casos, no. Si ya tenés Postgres corriendo, agregar pgvector es una extensión, no una infraestructura nueva. Para equipos con menos de 10 millones de vectores, pgvector dentro de PostgreSQL tiene todo lo que necesitás.
Búsqueda híbrida: por qué combinar vectores y BM25
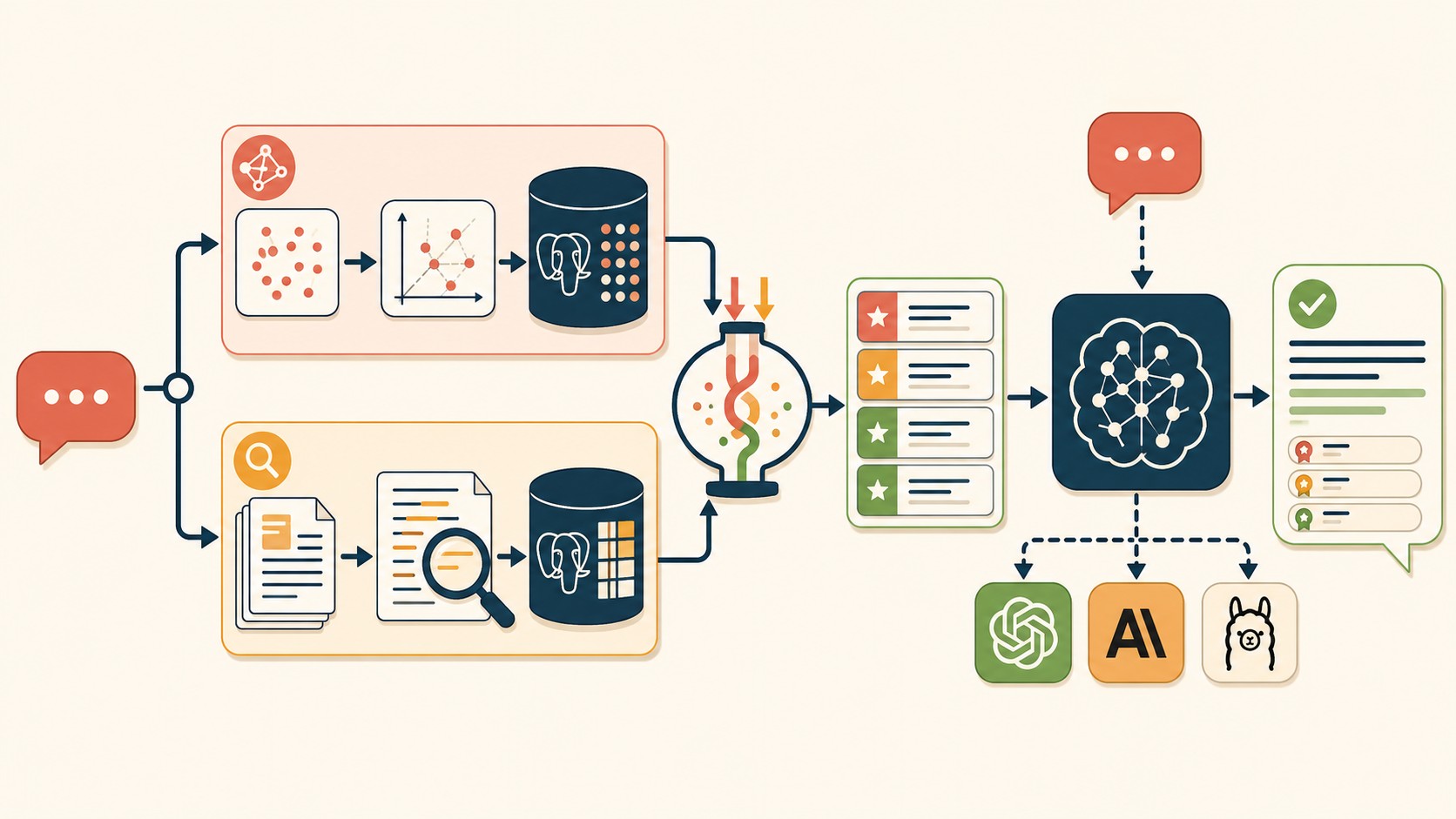
La búsqueda puramente vectorial encuentra documentos semánticamente similares. BM25 encuentra coincidencias exactas de términos. Ninguna de las dos es perfecta sola.
Buscás “cómo configurar la replicación en pgEdge” y la búsqueda vectorial te devuelve párrafos sobre replicación en general, algunos de otros sistemas. BM25 te devuelve resultados que contienen exactamente “pgEdge” y “replicación”. Combinadas con Reciprocal Rank Fusion, los resultados que aparecen bien rankeados en ambas búsquedas suben al tope de la lista. El contexto que llega al LLM es más preciso.
Esto no es nuevo en el mundo de la búsqueda enterprise, pero tenerlo integrado directamente en Postgres con pgvector y la extensión de texto completo de PostgreSQL sí es nuevo. Sin servicios externos, sin sincronización de índices, sin latencia de red a un sistema separado. Ya lo cubrimos antes en automatizar despliegues en producción.
pgEdge RAG Server y Ellie: arquitectura concreta
El pgEdge RAG Server es un API server escrito en Go, distribuido como binario único, que apuntás a cualquier base PostgreSQL 14+ con pgvector instalado. Configuración por YAML. Nada más.
Según la documentación oficial de pgEdge, el servidor soporta cuatro proveedores de LLM: OpenAI, Anthropic, Voyage, y Ollama para correr modelos locales. Token budgets para controlar costos, streaming de respuestas, y tools MCP para el DBA Workbench están todos en el binario base.
Ellie es el caso de uso que pgEdge usa internamente. Le preguntás “¿en qué puerto escucha el MCP Server?” y Ellie recupera los fragmentos relevantes de la documentación, arma el contexto, y te da una respuesta con citas. No adivina. Según el propio equipo de pgEdge, esto es exactamente lo que el RAG Server hace: no genera desde cero, recupera primero.
Lo interesante es que ahora este mismo server está disponible como servicio gestionado en pgEdge Cloud. Lo deployás junto a tu base de datos, lo apuntás a tus tablas, y tu aplicación tiene el mismo pipeline que Ellie.
Instalación y configuración: lo que necesitás antes de arrancar
Requisitos mínimos: Go 1.22+, PostgreSQL 14 o superior, extensión pgvector instalada. Dos caminos:
- Self-hosted: descargás el binario de GitHub, creás un archivo YAML con las credenciales de tu base, tu API key del LLM provider, y los parámetros de búsqueda. Licencia PostgreSQL, 100% open source.
- Servicio gestionado: lo deployás directamente en pgEdge Cloud junto a tu instancia. Sin ops, sin actualizaciones manuales.
La configuración YAML básica define: conexión a la base, qué tablas contienen tu contenido, qué columnas son texto y cuáles son embeddings, parámetros del LLM (modelo, temperatura, token budget), y si querés búsqueda híbrida o solo vectorial.
Para embeddings, el servidor puede generarlos automáticamente usando Voyage o los providers configurados. Si ya tenés una columna de vectores en tu tabla, la usás directamente.
Opciones para armar tu pipeline: SQL, Python, o TypeScript
Hay tres enfoques principales, y cada uno tiene su lugar.
pgrag: RAG completo en SQL puro
Si tu equipo vive en psql, pgrag te permite armar un pipeline RAG completo sin salir de SQL. Sin lenguaje de programación adicional. Útil para scripts de enriquecimiento de datos o consultas ad hoc sobre tu propio contenido. Sobre eso hablamos en infraestructura global distribuida.
LangChain con Python y pgvector
El stack más documentado en 2026. LangChain tiene integración nativa con pgvector como vector store. Armás el retriever, definís el chain, conectás al LLM. Más flexible que SQL puro, más verboso que el binario de pgEdge. Si tu equipo ya usa Python para ML o automatización, este camino tiene sentido.
TypeScript con la API del RAG Server
Si tu aplicación es un backend Node/TypeScript, consumís el API REST del pgEdge RAG Server directamente. Mandás la query del usuario, recibís la respuesta con citas. El servidor maneja todo lo demás.
Casos de uso reales: documentación, soporte y sistemas agentic
El caso más directo: knowledge base de producto. Cargás tu documentación técnica en Postgres, indexás con pgvector, y tu chatbot de soporte responde con citas de las fuentes reales en vez de inventar procedimientos.
El caso que está creciendo en 2026 es RAG agentic: en vez de una sola query, el sistema hace múltiples recuperaciones encadenadas. El usuario pregunta algo, el agente recupera contexto inicial, genera una subpregunta, recupera más contexto, y recién entonces genera la respuesta final. Los MCP tools del DBA Workbench de pgEdge están diseñados para este patrón.
¿La diferencia entre RAG simple y agentic RAG? En RAG simple, hacés una búsqueda y mandás los resultados al LLM. En agentic RAG, el LLM puede pedir más información, refinar la búsqueda, o combinar múltiples fuentes antes de responder. Más poderoso, más caro en tokens, más lento. Para documentación técnica, el RAG simple suele alcanzar.
pgvector vs. bases de datos vectoriales separadas: cuándo usar qué
| Criterio | pgvector en PostgreSQL | Base de datos vectorial (Pinecone, Qdrant, Milvus) |
|---|---|---|
| Volumen de vectores | Hasta ~10 millones | Decenas de millones o más |
| Infraestructura | Una sola base de datos | Sistema adicional a mantener |
| Búsqueda híbrida | Nativa con pgvector + FTS | Depende del proveedor |
| Consistencia transaccional | ACID con el resto de tus datos | Eventual, separada de tu base principal |
| Costo operacional | Bajo (una sola instancia) | Medio-alto (servicio adicional) |
| Latencia de sincronización | Ninguna (mismo sistema) | Requiere pipeline de sincronización |
| Curva de aprendizaje | Baja si ya usás Postgres | Nueva herramienta, nuevas APIs |
Para un proyecto B2B típico en 2026, con documentación interna, manuales de producto o un dataset de soporte técnico, pgvector alcanza con holgura. Pinecone o Qdrant tienen sentido si estás procesando millones de documentos en tiempo real o necesitás búsquedas con latencias sub-5ms a escala masiva. La “base de datos vectorial separada como paso obligatorio” es un mito que sirve más a los vendors que a los equipos de producto.
Costos y seguridad en producción
El ítem de costo más relevante en RAG no es la infraestructura, son los tokens del LLM. Cada query manda al modelo el texto del usuario más los fragmentos recuperados. Sin control, eso escala rápido. Cubrimos ese tema en detalle en elegir el modelo de IA.
El pgEdge RAG Server tiene token budgets configurables en el YAML: podés limitar cuántos tokens de contexto mandás por request. Si un documento es largo y el fragmento relevante es chico, el servidor trunca inteligentemente en vez de mandar el documento completo.
Para la parte de hosting e infraestructura, si estás buscando dónde correr tu instancia de PostgreSQL con pgvector en Argentina o Latinoamérica, donweb.com tiene opciones de VPS donde podés correr tu propio stack sin depender de servicios gestionados caros.
En cuanto a seguridad: el RAG Server soporta TLS/HTTPS, autenticación por API key, y rate limiting configurable. Si tu contenido es sensible (documentación interna, datos de clientes), asegurate de no exponer el endpoint público sin autenticación. El monitoreo está disponible vía AI DBA Workbench para ver qué queries hacen más retrievals y optimizar los índices en consecuencia.
Qué está confirmado / Qué todavía no es claro
Confirmado
- El pgEdge RAG Server está disponible como servicio gestionado en pgEdge Cloud, según el anuncio oficial.
- Es open source bajo licencia PostgreSQL, disponible en GitHub.
- Soporta OpenAI, Anthropic, Voyage y Ollama como proveedores de LLM.
- Usa búsqueda híbrida (vector similarity + BM25) con Reciprocal Rank Fusion.
- Ellie, el chatbot de docs de pgEdge, corre sobre esta misma infraestructura.
Lo que no queda claro
- Pricing del servicio gestionado en pgEdge Cloud: no hay cifras públicas al momento de escribir esto.
- Benchmarks comparativos independientes de la búsqueda híbrida vs. búsqueda vectorial pura no están disponibles todavía.
- Límites de escala del servicio gestionado (máximo de vectores, queries por segundo) no están documentados públicamente.
Errores comunes al implementar RAG en PostgreSQL
Cargar documentos completos como un solo chunk. El error más frecuente. Si cargás un PDF de 50 páginas como un único vector, la búsqueda va a recuperar el documento entero aunque solo el párrafo 37 sea relevante. El contexto que llega al LLM es ruidoso y el modelo tiene que filtrar internamente. Dividí los documentos en chunks de 300-500 tokens con overlap de ~50 tokens entre ellos.
Usar solo búsqueda vectorial y asumir que alcanza. La búsqueda vectorial falla con nombres propios, versiones específicas de software, o términos técnicos exactos. “pgEdge 5.2” semánticamente puede recuperar resultados sobre otras versiones porque los embeddings no distinguen números con precisión. BM25 sí. La búsqueda híbrida existe por esto.
Ignorar el token budget y dejarlo en ilimitado. En desarrollo, no pasa nada. En producción con usuarios reales, el costo de los tokens del LLM puede multiplicarse por diez en una semana. Configurá límites desde el día uno y monitoreá el promedio de tokens por request antes de escalar.
No actualizar los embeddings cuando cambia el contenido. Subís la documentación, generás los embeddings, y después actualizás los docs pero olvidás regenerar los vectores. El buscador sigue apuntando a los vectores viejos. Si tus documentos cambian con frecuencia, automatizá la regeneración de embeddings como parte del pipeline de actualización de contenido.
Si querés llevar agentes IA a producción, mirá Antony Pegg: From Managed PostgreSQL to Production RAG: Buil.
Preguntas Frecuentes
¿Cómo puedo construir mi propio servidor RAG con PostgreSQL?
Instalás PostgreSQL 14+ con la extensión pgvector, descargás el binario del pgEdge RAG Server desde GitHub, y configurás un archivo YAML con las credenciales de tu base y tu API key del LLM provider. El servidor expone una API REST que recibe queries y devuelve respuestas con citas. Para correrlo localmente con modelos propios, configurás Ollama como provider en el YAML. Para más detalles técnicos, mirá agentes locales sin APIs.
¿Qué es la búsqueda híbrida en PostgreSQL y cómo funciona?
Combina dos tipos de búsqueda: similitud vectorial (encuentra documentos semánticamente parecidos a la query) y BM25 (encuentra documentos con coincidencias exactas de términos). Los resultados de ambas búsquedas se fusionan con Reciprocal Rank Fusion, que prioriza los documentos bien rankeados en las dos listas. El resultado es más preciso que cualquiera de las dos técnicas sola, especialmente para términos técnicos o nombres propios.
¿Cuál es la diferencia entre pgvector y una base de datos vectorial separada?
pgvector es una extensión que agrega capacidades vectoriales a tu PostgreSQL existente. Las bases de datos vectoriales como Pinecone o Qdrant son sistemas independientes especializados. Para la mayoría de los proyectos (menos de 10 millones de vectores), pgvector dentro de Postgres es suficiente y evita mantener infraestructura adicional. Las bases de datos vectoriales separadas tienen ventaja en escala masiva y búsquedas con latencias sub-5ms a millones de consultas por segundo.
¿Cómo integro OpenAI o Anthropic en un pipeline RAG con PostgreSQL?
Con el pgEdge RAG Server, la integración es por configuración YAML: especificás el provider (openai, anthropic, voyage) y tu API key. Sin código adicional. Si preferís más control, podés usar LangChain con Python que tiene integración nativa con pgvector como vector store y soporta ambos providers como LLM backends. El servidor maneja el envío de los fragmentos recuperados como contexto al LLM automáticamente.
¿Puedo correr un RAG Server localmente con Ollama?
Sí. El pgEdge RAG Server soporta Ollama como provider de LLM en el archivo de configuración YAML. Con Ollama corriendo localmente y un modelo descargado (Llama 3, Mistral, o similares), el pipeline completo funciona sin mandar datos a APIs externas. Útil para contenido sensible, desarrollo sin costos de API, o entornos sin acceso a internet. El rendimiento depende de tu hardware local.
Conclusión
Lo que cambió en 2026 no es que RAG sea nuevo, es que dejó de requerir infraestructura especializada. El pgEdge RAG Server, disponible como binario open source o como servicio gestionado, demuestra que podés tener búsqueda híbrida, grounding en documentación real y soporte para múltiples LLM providers arriba de tu PostgreSQL existente.
Ellie, el chatbot de pgEdge que responde preguntas sobre replicación multi-master sin inventar respuestas, corre sobre este mismo stack. No es un demo de laboratorio: es lo que el equipo usa en producción para su propia documentación.
Si estás evaluando si vale la pena la complejidad de agregar una base de datos vectorial separada a tu arquitectura, la respuesta para la mayoría de los proyectos B2B en 2026 es no. Empezá con pgvector y el RAG Server. Si en algún momento llegás a los 10 millones de vectores con requisitos de latencia extremos, ahí revisás.