Blue-Green, Canary y Rolling: cuál usar y cuándo
Las estrategias de deployment seguro son técnicas para actualizar software en producción minimizando el riesgo de downtime y fallos. Blue-Green, Canary y Rolling son los tres patrones principales, cada uno con un perfil diferente de velocidad, costo y reversibilidad.
En 30 segundos
- Blue-Green: dos stacks paralelos (viejo y nuevo); el switch es instantáneo y el rollback también. Requiere el doble de infraestructura.
- Canary: la versión nueva recibe un porcentaje pequeño de tráfico real (5-20%) antes de expandirse. Detección temprana, rollback más lento.
- Rolling: los servidores se actualizan de a uno. Sin infra extra, pero sin versión anterior corriendo mientras actualizás.
- Ninguna estrategia sirve sin automatización, telemetría y runbooks reales. Sin eso, es teatro.
- La elección depende del riesgo del cambio: Blue-Green para cambios grandes, Canary para cambios riesgosos, Rolling para cambios menores.
Por qué importan las estrategias de despliegue seguro
Ponele que tu equipo lleva semanas desarrollando una feature. Llega el viernes, se hace el deploy, y a los diez minutos el servicio está caído para el 30% de los usuarios. Nadie sabe bien qué pasó, el rollback es manual y tarda 40 minutos, y hay un hilo de Slack con 80 mensajes de pánico. Ese escenario, según el análisis publicado recientemente en mayo de 2026, es exactamente lo que pasa cuando el proceso de deployment no está diseñado para la observabilidad y la seguridad automática.
Los síntomas son reconocibles: outages parciales transitorios, picos de errores ruidosos, rollbacks manuales en horario nocturno, y un miedo generalizado a desplegar que frena la entrega. PRs bloqueados por revisiones manuales interminables, equipos que evitan cambios de esquema de base de datos porque el rollback es frágil. Todo eso es consecuencia de no tener controles de tráfico, métricas automatizadas ni playbooks claros.
El objetivo es que los deployments sean aburridos. El código sale del pipeline, pasa las validaciones, el tráfico cambia, y si algo está mal se revierte antes de que los usuarios lo noten. Blue-Green, Canary y Rolling son herramientas para lograr esa predictibilidad. Pero sin automatización, son decoración cara.
Blue-Green Deployment: cambio instantáneo con rollback inmediato
Un Blue-Green deployment consiste en mantener dos stacks de producción en paralelo: el stack Blue (la versión actual) y el stack Green (la versión nueva). El router o el Service apunta a Blue mientras preparás Green. Cuando estás conforme con los tests y el warmup, switcheás el router a Green. Si algo falla, revertís el switch.
La ventaja principal es la velocidad de rollback: segundos, no minutos. El cambio es atómico desde el punto de vista del tráfico. No hay estados intermedios donde la mitad de los usuarios está en la versión vieja y la otra mitad en la nueva.
El costo es infraestructura duplicada. Durante el período de transición estás pagando (o provisionando) el doble de recursos. Para servicios que corren en cloud, eso se traduce en costos reales. El otro problema es con cambios de base de datos: si la versión nueva modifica el esquema, necesitás una estrategia de migración compatible con ambas versiones antes de hacer el switch. En integración de servicios externos profundizamos sobre esto.
Blue-Green tiene sentido cuando el cambio es grande, el riesgo de rollback parcial no es aceptable, o la ventana de downtime es cero. Para un cambio de configuración menor, es overkill.
Canary Deployment: prueba gradual con usuarios reales
El nombre viene de la práctica de los mineros que usaban canarios en las minas como indicador de peligro: si el pájaro moría, era señal de que había gas tóxico. Acá funciona igual: mandás la versión nueva a un porcentaje pequeño de tráfico, típicamente entre el 5% y el 20%, y monitoreás.
¿Y qué pasa si los errores suben en ese 5%? Tenés la señal antes de que el problema afecte a todos. El rollback no es tan inmediato como en Blue-Green, pero el blast radius está limitado mientras decidís.
La diferencia con los Feature Flags es el alcance: los flags controlan qué ven usuarios específicos dentro de una misma versión del binario. Canary expone una versión de código diferente a un subconjunto de tráfico a nivel de infraestructura. Podés combinarlos, de hecho muchos equipos lo hacen.
La desventaja es que necesitás igual la infraestructura dual (aunque sea parcial), y que el estado de tener dos versiones corriendo en simultáneo complica los logs y la depuración. Si tu servicio tiene sesiones de usuario largas o transacciones que cruzan versiones, hay que pensarlo bien.
Rolling Deployment: actualización progresiva servidor a servidor
El rolling deployment actualiza los nodos uno por uno (o en lotes pequeños). En Kubernetes el flujo es: sacás el pod del load balancer, actualizás la imagen, esperás que los health checks pasen, y recién entonces recibe tráfico de nuevo. Repetís para cada pod. Tema relacionado: migración de datos en producción.
La ventaja es que no necesitás infraestructura extra. Aprovechás los recursos que ya tenés. Para cambios menores que sabés que son seguros, es la opción más económica.
El trade-off es claro: mientras el rolling corre, los nodos se actualizan de a uno, por lo que algunos nodos corren la versión vieja mientras otros corren la nueva. Si necesitás revertir, tenés que hacer otro rolling hacia la versión anterior, y eso lleva tiempo. A diferencia de Blue-Green, el rollback no es un switch.
Rolling es ideal para cambios pequeños y seguros, hotfixes de bajo riesgo, o cualquier situación donde la velocidad del rollback no es crítica y querés minimizar el costo de infraestructura.
Tabla comparativa: cuándo usar cada estrategia
| Criterio | Blue-Green | Canary | Rolling |
|---|---|---|---|
| Velocidad de rollback | Instantáneo (segundos) | Gradual (minutos) | Lento (otro rolling) |
| Costo de infraestructura | Alto (doble stack) | Medio (stack parcial) | Bajo (recursos existentes) |
| Riesgo durante deploy | Bajo | Muy bajo | Medio |
| Complejidad de implementación | Media | Alta | Baja |
| Ideal para cambios grandes | Sí | No | No |
| Ideal para cambios riesgosos | Sí | Sí (detección temprana) | No |
| Ideal para cambios menores | Overkill | Overkill | Sí |
| Soporte nativo en Kubernetes | Con config extra | Con config extra | Nativo (RollingUpdate) |
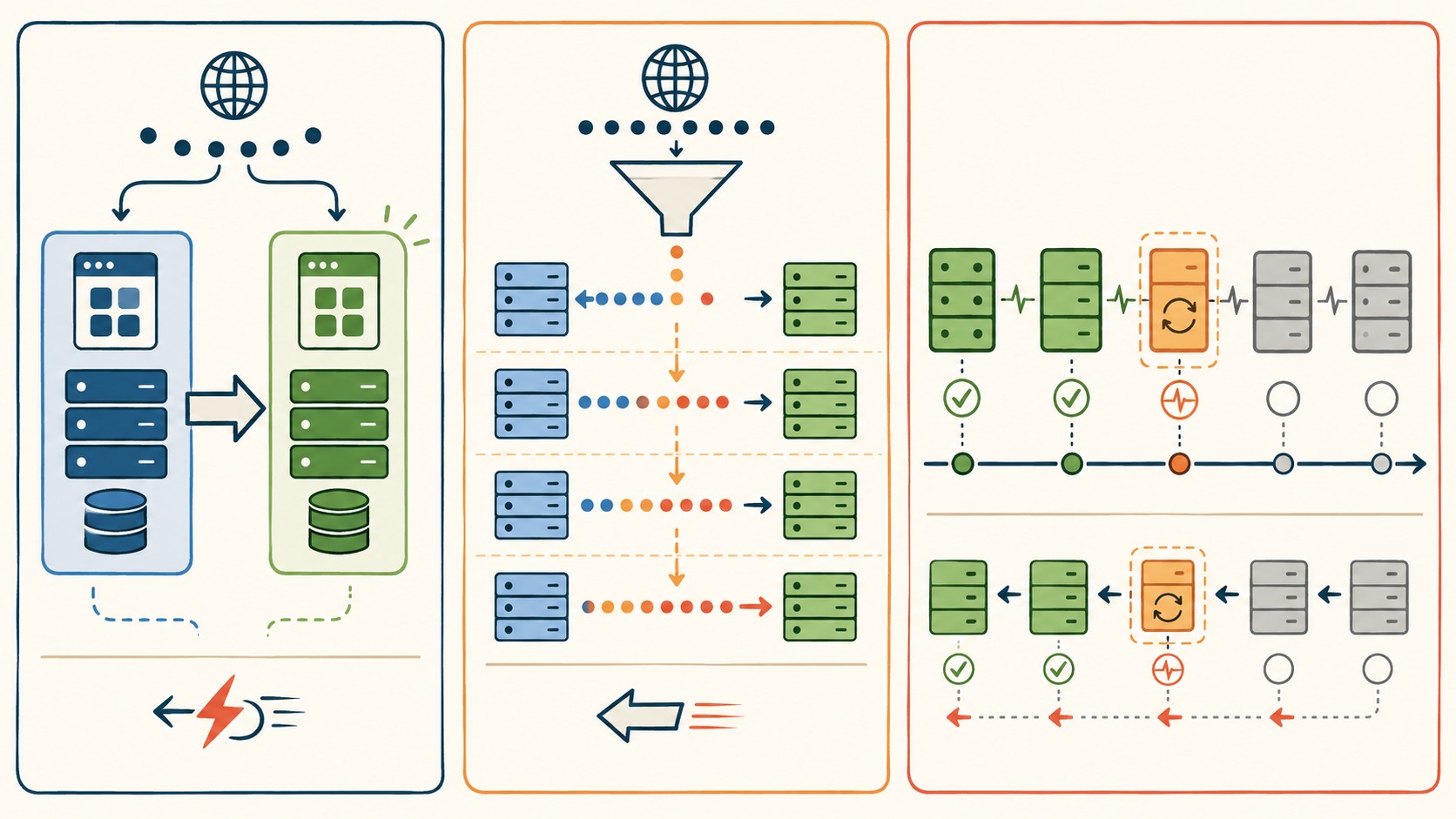
Automatización, observabilidad y guardrails: lo que separa teatro de ingeniería
Acá viene lo importante. Cualquiera de las tres estrategias, sin automatización real, es teatro caro. Podés tener un setup Blue-Green perfecto y aun así terminar con un rollback manual a las 3 de la mañana si no hay métricas automatizadas que disparen la reversión.
Los elementos no negociables son cuatro. Primero, tests automatizados en el pipeline antes de que llegue tráfico real. Segundo, métricas monitoreadas en tiempo real: latencia de respuesta, tasa de errores 5xx, throughput. Tercero, puertas de validación automáticas (no humanas), que pasen o frenen el avance del deploy según esas métricas. Cuarto, circuit breakers que corten el tráfico si los umbrales se superan.
La diferencia entre una puerta manual y una automática es lo que decidís cuando estás cansado, con presión, y convencido de que “ese error es ruido”. Las puertas automáticas no tienen ese sesgo. Si la tasa de error superó el 1% durante el canary, el deploy se frena, sin discusión. Ya lo cubrimos antes en herramientas de CI/CD para automatizar.
Para quienes están armando esta infraestructura desde cero, la elección del proveedor de cloud o hosting importa. Los servicios gestionados de AWS, GCP o Azure tienen soporte nativo para estas estrategias. Si tu stack está en servidores propios o VPS, donweb.com ofrece opciones de infraestructura donde podés implementar estos patrones con Kubernetes o Docker Compose según la escala del proyecto.
Rollbacks, runbooks y recuperación ante fallos
El problema con los runbooks no es que no existan. Es que existen pero están desactualizados, son ambiguos, o nadie los practica hasta que hay un incidente. Un runbook que dice “revisar los logs del servidor” no sirve si no especifica qué servidor, qué logs, y qué buscás.
Un runbook útil tiene tres cosas: los comandos exactos para ejecutar el rollback en cada estrategia, los umbrales que deberían dispararlo (tasa de error > X%, latencia > Y ms), y un propietario claro para cada paso. Si necesitás coordinar con tres personas antes de poder revertir un deploy, eso es un problema de diseño.
La diferencia práctica entre estrategias en un escenario de fallo es concreta. Con Blue-Green, revertir es cambiar un puntero; lo hace una persona en 30 segundos. Con Canary, si el problema está en el 10% de tráfico, podés cortar ese 10% y evaluar antes de decidir. Con Rolling, si ya actualizaste 8 de 10 pods y los 8 están fallando, el rollback implica otro ciclo completo que puede llevar entre 5 y 20 minutos dependiendo del tamaño del cluster.
¿Cuándo conviene practicar rollbacks en ambientes no productivos? Siempre. Los equipos que hacen simulacros de rollback tienen tiempos de recuperación medidos en minutos; los que no, en horas.
Checklist preflight y comandos listos para usar
Basado en la guía de referencia publicada recientemente en mayo de 2026, estos son los pasos de validación antes de cualquier deploy en producción:
Preflight (antes del deploy)
- Tests unitarios e integración en verde en el pipeline
- Verificar compatibilidad hacia atrás si hay cambios de esquema de BD
- Confirmar que los health checks del nuevo stack responden correctamente
- Notificar al equipo de guardia (on-call) del horario del deploy
- Tener el runbook de rollback abierto y listo
Blue-Green: switch y rollback
- Switch hacia Green:
kubectl patch service myapp -p '{"spec":{"selector":{"version":"green"}}' - Rollback a Blue:
kubectl patch service myapp -p '{"spec":{"selector":{"version":"blue"}}' - Verificar tráfico activo:
kubectl get endpoints myapp
Canary: ajuste de porcentaje de tráfico
- En Nginx Ingress: ajustar
nginx.ingress.kubernetes.io/canary-weight: "10"para 10% de tráfico - Monitorear tasa de errores durante al menos 10 minutos antes de escalar
- Para rollback: setear el weight a “0” o borrar el ingress canary
Rolling: pausar y reanudar en Kubernetes
- Pausar un rolling en curso:
kubectl rollout pause deployment/myapp - Retomar:
kubectl rollout resume deployment/myapp - Rollback a versión anterior:
kubectl rollout undo deployment/myapp - Ver estado actual:
kubectl rollout status deployment/myapp
Errores comunes al implementar estas estrategias
Hacer Blue-Green sin pensar en la base de datos
El stack Green está listo, el switch es cuestión de segundos, pero nadie revisó que la migración de BD del nuevo esquema rompió la compatibilidad con el stack Blue. El rollback instantáneo al que apostabas ahora no funciona porque Blue no puede leer los datos que Green ya modificó. La regla es simple: cualquier migración de BD debe ser compatible con la versión anterior del código antes del switch.
Usar Canary sin definir qué métrica decide el avance
El canary está al 10%, los números parecen bien, alguien decide escalar a 50% porque “se ve bien”. ¿Qué es “verse bien”? Si no tenés umbrales definidos previamente (p99 de latencia < 200ms, error rate < 0.5%), la decisión de avanzar o no es subjetiva y se lleva por el optimismo del momento. El equipo de guardia tiene que poder automatizar esa puerta. Complementá con proveedores de infraestructura en la nube.
Rolling con lotes demasiado grandes
Configurar un rolling update que reemplaza el 50% de los pods en paralelo anula parte del beneficio de la estrategia. Si esos pods fallan, la mitad del servicio está caída antes de que los health checks disparen el rollback. El maxSurge y maxUnavailable en Kubernetes deben ser valores conservadores, típicamente 25% o menos, ajustados según la criticidad del servicio.
No probar el rollback hasta que falla en producción
El runbook existe. Los comandos están. Pero nadie los ejecutó nunca en un ambiente real. Cuando llegue el incidente, van a descubrir que el comando de rollback depende de una variable de entorno que no está seteada en el servidor de producción, que el script asume un nombre de deployment que cambió hace tres meses, o que requiere permisos que el usuario de guardia no tiene. Simulacros de rollback en staging son la única forma de saber si el procedimiento funciona de verdad.
Si querés conocer las estrategias de deployment más seguras, tenemos Safe Deployment Strategies: Blue-Green, Canary, and Rolling.
Si querés profundizar en esto, tenemos un artículo sobre estrategias de despliegue.
Preguntas Frecuentes
¿Cuál es la diferencia entre Blue-Green y Canary deployment?
Blue-Green corre dos stacks completos en paralelo y cambia todo el tráfico de golpe con un switch. Canary expone la versión nueva a un porcentaje pequeño del tráfico (5-20%) y lo incrementa gradualmente según métricas. Blue-Green permite rollback en segundos; Canary limita el impacto de un error a un subconjunto de usuarios antes de expandirse.
¿Cómo hago un deployment sin downtime?
Las tres estrategias permiten deploys sin downtime si están bien implementadas. Blue-Green lo logra manteniendo el stack actual funcionando hasta que el nuevo está validado y el switch es instantáneo. Rolling lo logra actualizando de a un servidor a la vez, siempre con al menos parte del servicio disponible. Canary lo logra enviando solo un porcentaje del tráfico a la nueva versión mientras el resto sigue en la versión estable.
¿Cómo funciona un Rolling deployment en Kubernetes?
Kubernetes reemplaza los pods uno por uno (o en lotes según la configuración de maxSurge y maxUnavailable). Cuando un pod nuevo pasa los readiness probes, el viejo se termina y el tráfico se redirige al nuevo. El deployment se puede pausar con kubectl rollout pause y revertir con kubectl rollout undo. El tipo RollingUpdate es el default en Kubernetes.
¿Cuándo debo usar cada estrategia de despliegue?
Blue-Green para cambios grandes donde necesitás rollback garantizado en segundos. Canary para cambios de lógica de negocio con riesgo desconocido, donde querés validar con tráfico real antes de exponerlo a todos. Rolling para cambios menores y seguros donde el costo de la infraestructura extra no se justifica. Para servicios críticos con millones de usuarios, Canary casi siempre es la opción más prudente.
¿Se pueden combinar estas estrategias?
Sí, y es común. Un patrón habitual es usar Canary dentro de un setup Blue-Green: el stack Green empieza recibiendo el 5% del tráfico (canary), y si las métricas son buenas, se hace el switch completo a Green. Esto da lo mejor de los dos mundos: validación gradual con rollback instantáneo disponible en todo momento.
Conclusión
Blue-Green, Canary y Rolling no son opciones intercambiables que se eligen por gusto. Cada una tiene un perfil de riesgo, costo y velocidad de rollback diferente, y la elección correcta depende del cambio específico que estás desplegando. Un cambio de esquema de base de datos en un servicio crítico no tiene el mismo perfil que un ajuste de CSS en un microservicio secundario.
Lo que sí es común a todas es que sin automatización, sin métricas en tiempo real y sin runbooks probados, ninguna te va a salvar de un incidente de madrugada. La estrategia de deployment es la última línea de defensa, no la primera. El trabajo real está en el pipeline, los tests y los umbrales que deciden cuándo parar.
Si tu equipo todavía hace deploys con ssh directo al servidor y un rollback que implica coordinar a tres personas, cualquiera de estas tres estrategias es una mejora. Empezá por Rolling en Kubernetes si ya usás contenedores: es nativo, simple, y te va a dar el músculo para entender qué necesitás de Blue-Green o Canary cuando el servicio crezca.
Fuentes
- dev.to — Safe Deployment Strategies: Blue-Green, Canary, and Rolling (2026)
- GeekFlare — Blue-Green vs Canary Deployment: comparativa técnica
- SleakOps — Cero downtime en Kubernetes con estrategias de deployment
- TNEcom — Despliegue automatizado: Blue-Green, Canary y Rolling Updates
- AWS Builders — Mastering Deployment Strategies on AWS