Mantenimiento de BD en producción: root cause
El mantenimiento de base de datos en producción falla cuando se ejecuta por calendario en vez de por señal. Según el análisis publicado el 22 de mayo de 2026, la fragmentación de índices, las estadísticas obsoletas y la contención de locks son funciones de la carga de escritura, no de los días de la semana. Un índice fragmentado en una tabla con bajo tráfico puede esperar semanas; uno con escrituras intensas puede necesitar atención diaria.
En 30 segundos
- El mantenimiento por cron job ignora las tablas que más lo necesitan y dispara incidentes antes de que alguien note el problema.
- Los wait states (PAGEIOLATCH_*, LCK_M_*) son el punto de entrada universal para diagnóstico en SQL Server, PostgreSQL y MySQL.
- Fragmentación de índices: con 10-30% hacé REORGANIZE; con más del 30%, REBUILD.
- La corrupción silenciosa no tiene señal previa: requiere chequeos proactivos con DBCC CHECKDB, amcheck o CHECK TABLE.
- El flujo correcto: alerta de lentitud → wait states → síntoma → causa raíz → solución específica.
Microsoft es una empresa de tecnología fundada por Bill Gates y Paul Allen en 1975, que desarrolla software, sistemas operativos y servicios en la nube. Sus productos incluyen Windows, Office 365, Azure y otras soluciones empresariales.
Por qué el mantenimiento por calendario falla
El mantenimiento de base de datos en producción es la disciplina de identificar y corregir las causas raíz de degradación en motores relacionales (SQL Server, PostgreSQL, MySQL) usando señales observables del sistema en vez de horarios predefinidos.
Ponele que tenés un job que se ejecuta cada domingo a las 3 AM para reorganizar índices. Suena sensato. El problema es que la fragmentación no respeta fines de semana: si el viernes hubo un pico de inserciones masivas en la tabla de pedidos, el sábado esa tabla ya está degradada y el cron de mantenimiento llega tarde.
Según el análisis publicado el 22 de mayo de 2026, el problema de fondo es que la fragmentación, las estadísticas obsoletas, el crecimiento de logs y la contención de locks son funciones de la carga de escritura, no de semanas del calendario. El cron job omite exactamente las tablas que más lo necesitan, y el incidente se dispara antes de que alguien note la brecha.
Lo que propone el artículo en vez del cron job es un sistema de respuesta basado en síntomas: cuatro señales observables que cada una apunta a una causa raíz específica.
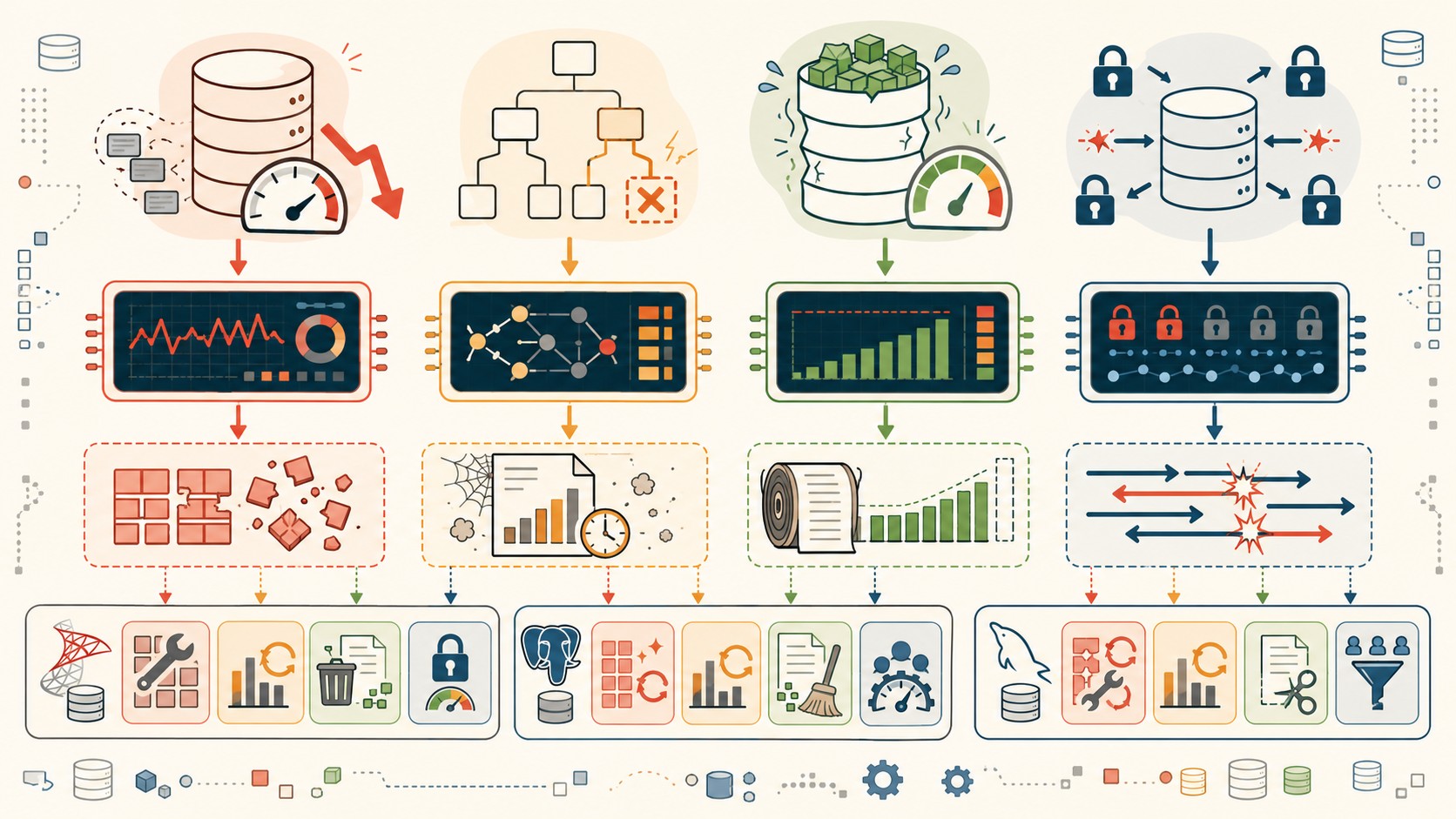
Los cuatro síntomas principales en producción
Cada síntoma que ves en producción tiene una causa raíz concreta. El error más común es tratar el síntoma sin identificar la causa, lo que lleva a soluciones temporales que vuelven a fallar.
- Degradación de I/O: las queries tardan más porque tienen que leer más páginas de disco de las necesarias. Causa raíz: índices fragmentados o buffer cache saturado.
- Regresión de query plan: el optimizer empieza a elegir planes ineficientes. Causa raíz: estadísticas desactualizadas que llevan a estimaciones de cardinalidad incorrectas.
- Presión de almacenamiento: el log de transacciones crece sin control. Causa raíz: transacciones de larga duración o mala configuración de truncado de log.
- Contención de locks: las operaciones se bloquean entre sí. Causa raíz: transacciones concurrentes necesitando los mismos recursos, o una operación de mantenimiento sosteniendo locks.
Para el usuario final, estos síntomas se traducen en timeouts, pantallas de carga, operaciones que no completan. No es magia negra, es matemática de I/O. Sobre eso hablamos en plataformas de versionado empresariales.
Wait states: el diagnóstico que funciona en cualquier motor
Cuando se dispara una alerta de query lenta, el primer paso es siempre el mismo sin importar el motor: revisá qué está esperando la query.
Los wait states son el punto de entrada universal para el triage de incidentes de base de datos. Te dicen si el problema está limitado por I/O, por locks o por CPU, y esa clasificación determina qué sección de tu runbook aplicar.
| Wait Type | Motor | Qué indica | Causa raíz probable |
|---|---|---|---|
| PAGEIOLATCH_EX / PAGEIOLATCH_SH | SQL Server | Query esperando que páginas se lean de disco al buffer pool | Fragmentación de índices o saturación del subsistema de storage |
| LCK_M_* | SQL Server | Contención de lock a nivel de fila o tabla | Transacción concurrente o mantenimiento sosteniendo locks |
| CXPACKET / CXCONSUMER | SQL Server | Skew de paralelismo | Query paralela desbalanceada, estadísticas incorrectas |
| lock:await | PostgreSQL | Espera por lock de fila o tabla | Transacciones concurrentes en conflicto |
| Innodb_row_lock_waits | MySQL | Contención de lock a nivel de fila InnoDB | Deadlock potencial o transacciones largas |
En SQL Server, PAGEIOLATCH_EX o PAGEIOLATCH_SH significa que la query está esperando que las páginas se lean de disco al buffer pool. Eso apunta a fragmentación de índices, presión sobre el buffer cache o saturación del storage. LCK_M_* indica contención de lock a nivel de fila o tabla desde una transacción concurrente, o peor, desde una operación de mantenimiento que está sosteniendo locks. CXPACKET señala skew de paralelismo, que generalmente se rastrea a estadísticas incorrectas.
¿Y si la query espera en CPU? Ahí el diagnóstico cambia: ya no es mantenimiento, probablemente sea una query mal escrita o un plan que explota en cardinalidad.
Fragmentación de índices: cuándo reorganizar y cuándo reconstruir
La fragmentación ocurre cuando las páginas de un índice quedan físicamente desordenadas respecto al orden lógico de las claves. Resultado: el motor tiene que leer más páginas para obtener el mismo resultado. Más I/O, más lento, más caro.
El threshold estándar, que mencionan los docs de Microsoft sobre reorganización de índices, es:
- 5-30% de fragmentación: REORGANIZE. Operación online, sin bloquear lecturas ni escrituras.
- Más del 30%: REBUILD. Reconstruye el índice desde cero. En SQL Server puede ser online (Enterprise) u offline (Express/Standard, bloquea la tabla).
Por motor:
- SQL Server:
sys.dm_db_index_physical_statste da la fragmentación por índice. Un REBUILD completo en una tabla grande puede tomar entre 5 y 30 minutos. - PostgreSQL:
REINDEXreconstruye el índice.REINDEX CONCURRENTLY(PostgreSQL 12+) lo hace sin bloquear lecturas. - MySQL:
OPTIMIZE TABLEreorganiza el tablespace y reconstruye índices. En InnoDB equivale a un recreate de la tabla.
Eso sí: ejecutar un REBUILD en horario pico en SQL Server Standard es un error clásico que bloquea la tabla completa durante minutos (o más). Siempre en ventana de bajo tráfico, o usá la variante online si tenés licencia Enterprise. Relacionado: sistemas de integración continua y deployment.
Estadísticas obsoletas: cuando el optimizer se equivoca de plan
El query optimizer de cualquier motor relacional necesita estadísticas actualizadas para elegir el plan de ejecución correcto. Si las estadísticas dicen que una tabla tiene 1.000 filas y en realidad tiene 10 millones, el optimizer va a tomar decisiones que tienen sentido para 1.000 filas y van a ser un desastre para 10 millones (nested loops donde debería ir un hash join, por ejemplo).
Estadísticas viejas llevan a estimaciones de cardinalidad incorrectas, que llevan a planes subóptimos, que llevan a movimiento innecesario de datos. La cadena causa-efecto es directa.
Soluciones por motor:
- SQL Server:
UPDATE STATISTICS tablaosp_updatestatspara toda la base. El tiempo varía: desde 30 segundos para tablas chicas hasta 5 minutos para tablas de decenas de millones de filas. - PostgreSQL:
ANALYZE tabla. PostgreSQL tiene autovacuum con autoanalyze habilitado por defecto, pero en tablas con writes muy frecuentes puede no alcanzar. - MySQL:
ANALYZE TABLE tabla. InnoDB actualiza estadísticas automáticamente, pero la frecuencia depende deinnodb_stats_auto_recalc.
La frecuencia correcta depende del workload. Una tabla con inserciones masivas diarias necesita actualización de estadísticas diaria o más seguido. Una tabla casi estática puede aguantar semanas.
Contención de locks y deadlocks: detección y prevención
La contención de locks ocurre cuando múltiples transacciones necesitan acceso a los mismos recursos al mismo tiempo y una tiene que esperar a la otra. Hasta cierto punto es normal. El problema es cuando la espera se acumula y empieza a impactar tiempos de respuesta.
Un deadlock es el caso extremo: dos transacciones se esperan mutuamente y ninguna puede avanzar. El motor resuelve matando una de las dos (la “víctima”), que recibe un error y tiene que reintentar.
Estrategias de prevención:
- Orden consistente de acceso: si la transacción A siempre accede primero a la tabla Clientes y después a Pedidos, y la B hace lo mismo, no hay deadlock. Si A va Clientes→Pedidos y B va Pedidos→Clientes, estás generando el ciclo.
- Minimizá la duración de las transacciones: cuanto menos tiempo tenga un lock, menos chance de colisión.
- Granularidad de locks: usá locks a nivel de fila cuando podés, no de tabla.
- Isolation level: READ COMMITTED SNAPSHOT en SQL Server puede reducir contención sin cambiar lógica de aplicación.
Para detectarlos, Microsoft recomienda Extended Events en SQL Server (el trace de deadlock_graph). En PostgreSQL, el log registra deadlocks automáticamente con el detalle de las transacciones involucradas. En MySQL, SHOW ENGINE INNODB STATUS muestra el último deadlock detectado.
Corrupción silenciosa: el único síntoma que no avisa
Acá viene lo que diferencia a este análisis de la mayoría de los artículos de mantenimiento: la corrupción silenciosa. Más contexto en documentación técnica multiidioma.
A diferencia de los otros cuatro síntomas, la corrupción silenciosa no produce señal previa. No hay wait state que te avise, no hay degradación de I/O gradual. Simplemente, los datos están mal y no lo sabés hasta que alguien lo nota (o hasta que un backup que pensabas que estaba bien resulta corrupto también).
La única estrategia es detección proactiva:
- SQL Server:
DBCC CHECKDB. Revisa la integridad de toda la base. En bases grandes puede tomar horas. Corrélo fuera de horario pico y monitoreá la salida. - PostgreSQL: extensión
amcheckpara verificar integridad de índices B-tree. Disponible desde PostgreSQL 10. - MySQL:
CHECK TABLE tabla. Para InnoDB, también existeinnochecksumpara chequear tablespaces offline.
¿Con qué frecuencia? Depende del SLA. Para sistemas críticos, semanalmente como mínimo. Para sistemas de alta disponibilidad, algunos equipos lo corren diariamente en réplicas de solo lectura para no impactar la primaria.
De la alerta al root cause: el flujo completo
Con todos los síntomas mapeados, el flujo de respuesta queda así:
- Alerta de lentitud dispara → revisá wait states en el motor correspondiente
- PAGEIOLATCH_* dominante → verificá fragmentación con
sys.dm_db_index_physical_stats→ si >30%, REBUILD; si 10-30%, REORGANIZE - LCK_M_* dominante → revisá transacciones activas, identificá la que sostiene el lock, evaluá isolation level
- CXPACKET / paralelismo → revisá estadísticas, actualizá con UPDATE STATISTICS, evaluá MAXDOP
- Query plan regresó sin cambio de datos obvio → estadísticas obsoletas, actualizá y forzá recompilación
- Sin señal pero datos inconsistentes → corrupción silenciosa, corré DBCC CHECKDB / amcheck / CHECK TABLE
Los tiempos típicos de ejecución: un REBUILD de índice en una tabla mediana toma entre 5 y 30 minutos. Un UPDATE STATISTICS va desde 30 segundos hasta 5 minutos. Un DBCC CHECKDB en una base de 100 GB puede tomar 2 horas. Planificá ventanas de mantenimiento con estos números en mente, no con “lo hago rápido”.
Errores comunes en el mantenimiento de base de datos en producción
1. Reconstruir todos los índices sin discriminar fragmentación. El error más frecuente: correr un script que hace REBUILD de todos los índices de la base cada domingo, independientemente del porcentaje de fragmentación. Un índice con 3% de fragmentación no necesita rebuild y estás desperdiciando recursos (y tiempo de bloqueo en Standard). Medí primero con sys.dm_db_index_physical_stats, decidí después.
2. Actualizar estadísticas sin considerar el workload. El autoanalyze de PostgreSQL o la actualización automática de SQL Server están bien para casos promedio. Para tablas con inserciones masivas en periodos cortos (ETL nocturno que inserta millones de filas), la actualización automática puede no dispararse a tiempo y el optimizer opera con información vieja durante horas. Agendá actualizaciones manuales después de cargas masivas.
3. Correr DBCC CHECKDB en la base primaria en horario pico. DBCC CHECKDB es intensivo en I/O. Correrlo en la primaria mientras hay usuarios conectados impacta directamente los tiempos de respuesta (ironía máxima: el chequeo de salud degrada el servicio). Si tenés réplica de lectura, corrélo ahí. Si no, ventana de bajo tráfico obligatoria. Lo explicamos a fondo en agentes de monitoreo sin dependencias externas.
Si querés aprender a rastrear estos incidentes en producción, mirá nuestro artículo sobre Database Maintenance: Tracing Production Incidents to Their.
Esto se conecta con Database Maintenance: Tracing Production Incidents to Their, donde cubrimos el tema en detalle.
Preguntas Frecuentes
¿Cómo diagnosticar por qué mi base de datos va lenta en producción?
El primer paso es revisar los wait states del motor: en SQL Server usá sys.dm_exec_requests o sys.dm_db_wait_stats para ver qué espera cada query activa. El tipo de espera dominante (I/O, lock, CPU) determina la dirección del diagnóstico. Si ves PAGEIOLATCH_*, es I/O y probablemente fragmentación; si ves LCK_M_*, es contención de locks. En PostgreSQL, pg_stat_activity con el campo wait_event_type y wait_event da la misma información.
¿Qué son los wait states y cómo usarlos para troubleshooting?
Los wait states son métricas que registra el motor de base de datos sobre qué recurso está esperando cada operación activa. En SQL Server y Azure SQL, sys.dm_db_wait_stats muestra acumulativos desde el último reinicio. Para triage de incidente agudo, preferís las DMVs de sesiones activas (sys.dm_exec_requests) que muestran el wait_type en tiempo real de cada query corriendo ahora mismo.
¿Cada cuánto debo hacer mantenimiento a mis índices?
Depende del workload de escritura, no de un calendario fijo. Tablas con pocas inserciones pueden aguantar semanas sin fragmentación significativa. Tablas con inserciones masivas diarias pueden necesitar mantenimiento diario o incluso más seguido. Medí la fragmentación con sys.dm_db_index_physical_stats (SQL Server) regularmente y construí el calendario a partir de esos datos reales, no al revés.
¿Cómo evitar deadlocks y contención de locks?
La estrategia más efectiva es mantener un orden consistente de acceso a tablas en todas las transacciones de tu aplicación: si siempre accedés primero a tabla A y después a tabla B, eliminás el ciclo que genera deadlocks. Combiná eso con transacciones lo más cortas posible y, en SQL Server, evaluá habilitar READ COMMITTED SNAPSHOT ISOLATION (RCSI) que permite lecturas sin bloquear escrituras usando versioning de filas.
¿Cuál es la diferencia entre fragmentación de índices y estadísticas obsoletas?
Son dos problemas distintos con síntomas parecidos (queries lentas) pero causas diferentes. La fragmentación de índices es física: las páginas del índice están desordenadas en disco y el motor hace más I/O para leerlas. Las estadísticas obsoletas son informacionales: el optimizer tiene datos incorrectos sobre la distribución de datos y elige planes ineficientes. Podés tener un índice perfectamente desfragmentado con estadísticas viejas que genere un plan horrible, y viceversa. El wait state te ayuda a distinguirlos: I/O apunta a fragmentación, plan subóptimo sin I/O apunta a estadísticas.
Conclusión
El análisis publicado el 22 de mayo de 2026 cambia el framing del mantenimiento de base de datos: de tarea de calendario a sistema de respuesta basado en señales. Cuatro síntomas observables (I/O, regresión de plan, presión de storage, contención de locks), cada uno trazable a una causa raíz específica, cada uno con una solución concreta por motor.
Lo que lo hace práctico es el punto de entrada único: los wait states. Si arrancás cada investigación de lentitud leyendo qué está esperando la query antes de tocar cualquier otra cosa, ya estás haciendo triage de forma más sistemática que la mayoría de los equipos.
Y si tu infraestructura de base de datos corre en servidores propios o en la nube, donweb.com tiene opciones de hosting y cloud que podés evaluar para el ambiente donde vive tu instancia.
Fuentes
- Damaso Sanoja en DEV.to — Database Maintenance: Tracing Production Incidents to Their Root Cause (2026-05-22)
- Microsoft Learn — sys.dm_db_wait_stats (Azure SQL Database)
- Microsoft Learn — Reorganizar y recompilar índices
- Microsoft Learn — Solución de problemas de consultas lentas en SQL Server
- Microsoft Learn — Analizar y prevenir deadlocks en Azure SQL