El bug de WireGuard en GKE que nadie veía venir
Un bug de concurrencia en anetd, la implementación de Cilium que usa Google en GKE, causó cerca de 120 reinicios por pod en seis días en la infraestructura de Lovable durante abril de 2026. El bug WireGuard Google Kubernetes afectó la capa de encriptación entre nodos, disparando timeouts, conexiones cortadas y fallos al abrir proyectos en una plataforma que genera más de 50 sandboxes por segundo.
En 30 segundos
- anetd, la implementación de Cilium de Google para GKE, tenía un bug de race condition que hacía crashear los pods de red casi una vez por hora.
- El equipo de Lovable usó un agente de IA con acceso a logs en Clickhouse para detectar el patrón, porque revisar millones de líneas a mano era inviable.
- Deshabilitar WireGuard resolvió el crash, pero expuso un segundo problema: MTU mismatch entre nodos (1420 bytes vs 1500 bytes) que rompió Valkey.
- La solución final fue hacer reroll de todos los nodos del cluster para sincronizar la configuración de MTU.
- Google parcheó el bug de concurrencia tras el reporte. Plataformas con alto volumen de creación/destrucción de pods son las más expuestas.
Google es una empresa multinacional estadounidense fundada en 1998 por Larry Page y Sergey Brin que opera principalmente un motor de búsqueda web y una plataforma de publicidad digital. Desarrolla también sistemas operativos, navegadores y servicios en la nube bajo Google Cloud.
El bug de concurrencia en WireGuard de Google Kubernetes Engine
anetd es la implementación de Google de Dataplane V2 para GKE, basada en Cilium, que gestiona toda la red de los clusters: asignación de interfaces a pods, políticas de red y, en este caso, encriptación WireGuard entre nodos. Cuando anetd cae, los pods nuevos no reciben interfaz de red. En una plataforma que gira sandboxes a velocidad constante, eso se traduce directo en errores para el usuario final.
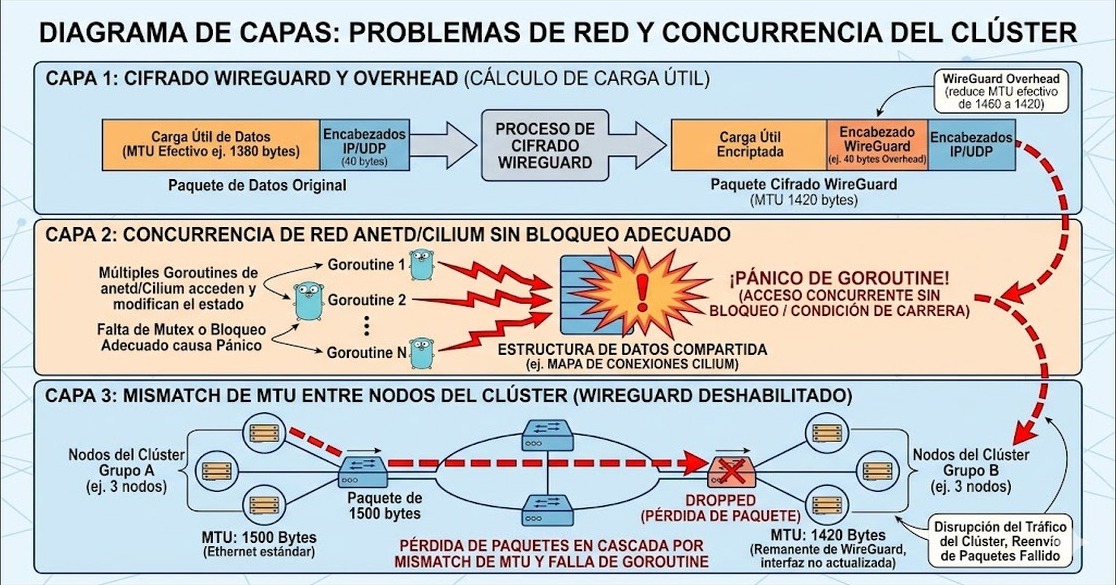
El bug específico era una race condition: múltiples goroutines accedían sin sincronización a la misma estructura de datos dentro de anetd. En clusters con bajo movimiento de pods esto podía pasar desapercibido durante meses. En una plataforma como Lovable, con decenas de pods creándose y destruyéndose por segundo, el conflicto se disparaba con frecuencia suficiente como para hacer crashear anetd una vez por hora.
Síntomas que los usuarios empezaron a ver
Ponele que abrís un proyecto en Lovable y simplemente no carga. O que un clone de GitHub se corta a la mitad. O que aparece el clásico “Connection reset by peer” sin ningún motivo aparente. Eso fue lo que reportaron los usuarios de Lovable durante la semana del incidente: errores intermitentes, sin patrón obvio, que aparecían y desaparecían.
El impacto era grave: 120 reinicios por pod en seis días, según el postmortem publicado por el equipo. Casi una caída por hora, sostenida durante días. En una plataforma que genera más de 50 sandboxes por segundo en pico, incluso un porcentaje chico de fallos se multiplica rápido en volumen absoluto de usuarios afectados.
Cómo se detectó: agentes de IA sobre logs de Clickhouse
Sascha, ingeniero de infraestructura en Lovable, arrancó por donde arranca todo buen debugging: los logs. El problema era que había millones de líneas para revisar y el patrón no saltaba a la vista. Entonces hizo algo que no siempre se ve en postmortems de este tipo: configuró un agente de IA con acceso directo a la base de logs en Clickhouse y le empezó a hacer preguntas.
El agente encontró lo que el análisis manual no había podido: los pods de anetd estaban reiniciando a un ritmo anómalo, distribuido de forma uniforme en todos los nodos del cluster. Ese detalle, que los reinicios no estaban concentrados en un nodo sino que afectaban a todos por igual, fue la primera pista de que el problema era en el código de anetd mismo, no en hardware ni en configuración de un nodo particular.
¿Y qué pasó cuando profundizaron en los crash logs? Exacto: aparecieron las trazas de la race condition. Múltiples goroutines compitiendo por la misma estructura de datos sin ningún mecanismo de sincronización. (Spoiler: esto es el tipo de bug que no aparece en staging porque staging no tiene el volumen de producción.)
La complicación oculta: MTU mismatch después del primer fix
Una vez identificado el bug de concurrencia, la decisión táctica fue deshabilitar WireGuard en el cluster para estabilizar la situación mientras Google trabajaba en el parche. WireGuard en GKE se usa para encriptación node-to-node: agrega overhead al paquete, lo que reduce el MTU efectivo de 1500 bytes (Ethernet estándar) a 1420 bytes.
Acá viene lo bueno: al deshabilitar WireGuard, algunos nodos del cluster quedaron configurados con MTU 1420 y otros con 1500. Distintos momentos de provisioning, distintas versiones de configuración aplicada. El resultado fue que los paquetes grandes que viajaban entre nodos con MTU diferente se empezaban a fragmentar mal o directamente se descartaban.
Esto rompió Valkey (el sistema de caché que antes era Redis), que empezó a ver conexiones cortadas en operaciones con payloads grandes. El primer fix había resuelto el crash de anetd, pero expuso una inconsistencia de configuración que ya existía y que WireGuard, al forzar un MTU uniforme más bajo, había estado enmascarando sin querer. Dos bugs por el precio de uno (si es que eso cuenta como descuento).
Resolución: reroll de todos los nodos del cluster
No había forma elegante de sincronizar la configuración de MTU sin tocar los nodos. La solución fue hacer reroll completo del cluster, es decir, reemplazar todos los nodos uno a uno para que los nuevos levantaran con configuración consistente desde cero.
Para el bug de concurrencia en anetd, fue necesario soporte de Google. El equipo de Lovable reportó el problema con los datos del análisis, Google confirmó el bug y liberó un parche para GKE. Sin el análisis detallado de los logs, y particularmente sin la identificación de que los reinicios eran uniformes en todos los nodos, hubiera sido mucho más difícil convencer al soporte de que el problema estaba en el código de anetd y no en la configuración del cluster.
Qué enseña este caso sobre debugging en capas
El error más común en infraestructura compleja es asumir que el primer fix resolvió todo el problema. En este caso, deshabilitar WireGuard estabilizó los crashes de anetd, pero reveló un estado inconsistente que ya existía. El stack tiene capas: encriptación, networking de pods, configuración de nodos, servicios de aplicación. Un fix en una capa puede exponer problemas en otra que estaban ocultos.
Bajás WireGuard, se estabilizan los pods, pero de repente Valkey empieza a fallar en operaciones específicas, los logs muestran conexiones cortadas en payloads de más de cierto tamaño, y ahí te das cuenta de que el MTU no era consistente en todo el cluster. El debugging terminó siendo una cadena: crash de anetd lleva a race condition lleva a WireGuard como vector lleva a MTU mismatch como estado subyacente.
El rol de la IA en este proceso fue concreto y acotado: acelerar la búsqueda de patrones en un volumen de logs que no era manejable a mano. No reemplazó el criterio de Sascha para interpretar los resultados ni para decidir los pasos siguientes. Fue una herramienta de búsqueda, no un debugger autónomo.
Quiénes están más expuestos en GKE
El bug de concurrencia en anetd se manifiesta con mayor intensidad cuando hay alto volumen de creación y destrucción de pods. En clusters con carga de trabajo estable y pocos cambios de pods, el problema puede pasar desapercibido o generar solo errores esporádicos. Los perfiles más expuestos son:
- Plataformas serverless que giran contenedores efímeros por request (como Lovable con sus sandboxes)
- Sistemas de CI/CD intensivos con muchos jobs paralelos de corta duración
- Labs de IA que crean entornos de entrenamiento o inferencia on-demand
- Plataformas de desarrollo cloud con workspaces por usuario
Si tu plataforma usa GKE con Dataplane V2 (que habilita anetd) y WireGuard activado, y tenés síntomas de conexiones cortadas o timeouts intermitentes, vale revisar los reinicios de anetd en los logs. El parche de Google ya está disponible para versiones recientes de GKE.
Para equipos que manejan infraestructura propia en servidores dedicados o VPS y quieren evitar este tipo de dependencias de networking gestionado, donweb.com tiene opciones de cloud privado donde vos controlás la configuración de red completa.
Errores comunes al debuggear networking en Kubernetes
Asumir que el problema está en la aplicación cuando es de red
Los “Connection reset by peer” y los timeouts intermitentes se investigan primero en el código de la aplicación. Si el patrón no tiene lógica desde la app (el mismo request a veces funciona, a veces no, sin cambios de carga obvios), el problema probablemente está en la red. Revisá los logs de los pods de networking (anetd, kube-proxy) antes de perder tiempo en la aplicación.
Ignorar los reinicios de pods del plano de control de red
Los pods de anetd o kube-proxy corriendo en cada nodo raramente se revisan en el monitoreo estándar. Si tenés alertas para tu aplicación pero no para los componentes de networking, podés tener un pod de red reiniciando una vez por hora sin que ninguna alerta se dispare. Agregá métricas de restart count para estos pods al dashboard de infra.
No verificar MTU después de cambios en la capa de encriptación
Cada vez que habilitás o deshabilitás WireGuard, IPSec u otro túnel de encriptación en Kubernetes, el MTU efectivo cambia. Si algunos nodos del cluster estuvieron operando con WireGuard y otros no, pueden quedar con MTU inconsistente. Verificá con ip link show en cada nodo que el MTU sea uniforme después de cualquier cambio en la configuración de encriptación.
Esto se conecta con Our agent found a bug with WireGuard in Google Kubernetes En, donde cubrimos el tema en detalle.
Si querés saber más, mirá nuestro análisis sobre Our agent found a bug with WireGuard in Google Kubernetes En.
Profundizamos sobre esto en Our agent found a bug with WireGuard in Google Kubernetes En.
Preguntas Frecuentes
¿Qué fue el bug de WireGuard en Google Kubernetes Engine?
Era una race condition en anetd, la implementación de Cilium que Google usa en GKE para Dataplane V2. Múltiples goroutines accedían sin sincronización a la misma estructura de datos cuando WireGuard procesaba tráfico entre nodos. Esto causaba crashes periódicos del pod de anetd, dejando nodos sin capacidad de asignar interfaces de red a pods nuevos.
¿Qué es anetd y cuándo causa problemas?
anetd es el agente de red que Google corre en cada nodo de GKE cuando usás Dataplane V2. Gestiona la asignación de interfaces a pods, políticas de red y encriptación WireGuard entre nodos. Los problemas aparecen con mayor frecuencia en clusters con alto volumen de creación y destrucción de pods, porque cada operación implica accesos concurrentes a las estructuras de datos que anetd gestiona.
¿Cómo afecta el MTU mismatch a WireGuard en Kubernetes?
WireGuard agrega overhead a cada paquete, lo que reduce el MTU efectivo de 1500 bytes a 1420 bytes. Si algunos nodos del cluster tienen MTU 1420 y otros 1500 (por haber sido provisionados en distintos momentos o con distintas configuraciones), los paquetes grandes se fragmentan mal o se descartan al cruzar entre nodos con MTU diferente. El síntoma típico son fallos en operaciones con payloads grandes, como Valkey con objetos de cierto tamaño.
¿Se puede usar IA para debuggear infraestructura?
Sí, con usos concretos y acotados. En el caso de Lovable, un agente con acceso a logs en Clickhouse permitió identificar el patrón de reinicios de anetd en millones de líneas de logs que eran inmanejables a mano. El agente aceleró la fase de búsqueda de patrones; la interpretación de resultados y las decisiones de remediation las tomó el ingeniero. No es un debugger autónomo, es una herramienta de búsqueda a escala.
¿Cómo sé si mi cluster de GKE está afectado por este bug?
Revisá el restart count de los pods de anetd en todos tus nodos con kubectl get pods -n kube-system | grep anetd. Si ves decenas o cientos de reinicios en los últimos días, y tu cluster usa Dataplane V2 con WireGuard habilitado y alto volumen de pods efímeros, es probable que estés en el rango afectado. Google tiene el parche disponible para versiones recientes de GKE; actualizar el cluster debería resolver el problema.
Conclusión
El incidente de Lovable expone algo que cualquiera que haya operado Kubernetes a escala reconoce: los bugs más difíciles de encontrar son los que no tienen un patrón obvio, aparecen intermitentemente y viven en una capa del stack que nadie monitorea de cerca. Un pod de anetd reiniciando una vez por hora no activa alertas de aplicación, no aparece en los dashboards de latencia, y si no revisás explícitamente el estado de los componentes de red del plano de datos, podés tener el problema activo durante días sin saberlo.
Lo que cambió con este caso es doble: Google tiene que reforzar el testing de concurrencia en anetd bajo cargas de alto turnover de pods, y el equipo de Lovable documentó un workflow de debugging asistido por IA que puede replicarse. Tener un agente que haga queries sobre tus logs cuando el volumen hace inviable el análisis manual no es un lujo, es una herramienta operacional concreta. Ahora bien, el fix real requirió soporte de vendor y un reroll completo del cluster, lo que muestra que hay límites claros para lo que la IA puede resolver sola. El debugging lo aceleró; la remediación la hizo un ingeniero.