El error clásico de escalar con configuración (caso Veltrix)
Limitar la concurrencia en el balanceador de carga para resolver un problema de escalabilidad causado por bottlenecks en la configuración de servidores no es una solución: es trasladar el cuello de botella de lugar. Eso aprendió el equipo de Veltrix en mayo de 2026, cuando un feature de alta demanda paralizó su sistema por tweaks de configuración que empeoraron exactamente lo que querían arreglar.
En 30 segundos
- El equipo lanzó un feature de “scavenger hunt” virtual con alto volumen de eventos simultáneos y el sistema empezó a colapsar.
- Intentaron bajar el límite de concurrencia en la capa de configuración de Veltrix, convencidos de que menos conexiones simultáneas reduciría la carga.
- El resultado fue el opuesto: crearon un bottleneck en el balanceador, que empeoró los timeouts.
- La solución real fue introducir una capa de service boundary separada entre el sistema event-driven y los load balancers.
- Lección: los problemas de capacidad no se resuelven limitando entradas, se resuelven rediseñando el flujo.
El caso real: cuando la escalabilidad horizontal no alcanza
Un bottleneck de escalabilidad es un punto en la arquitectura donde la capacidad de procesamiento se satura antes que el resto del sistema, causando que las solicitudes se acumulen, demoren o fallen. El equipo detrás de Veltrix lo vivió de cerca en mayo de 2026 cuando lanzaron una funcionalidad nueva: una búsqueda del tesoro virtual (virtual scavenger hunt) que otorgaba ítems y badges a los jugadores en tiempo real.
El diseño era event-driven, pensado justamente para manejar picos de tráfico. Ponele que todo funciona bien en staging, los tests pasan, el código se ve limpio. Lo mandás a producción y a las pocas horas el sistema empieza a colapsar: timeouts, requests que se acumulan, y nadie entiende por qué si la arquitectura “debería escalar”.
Eso fue exactamente lo que pasó. El volumen de eventos asociados al feature superó lo que el sistema podía manejar limpiamente, y el equipo buscó la causa en el lugar equivocado: la capa de configuración.
El primer intento fallido: bajar el límite de concurrencia
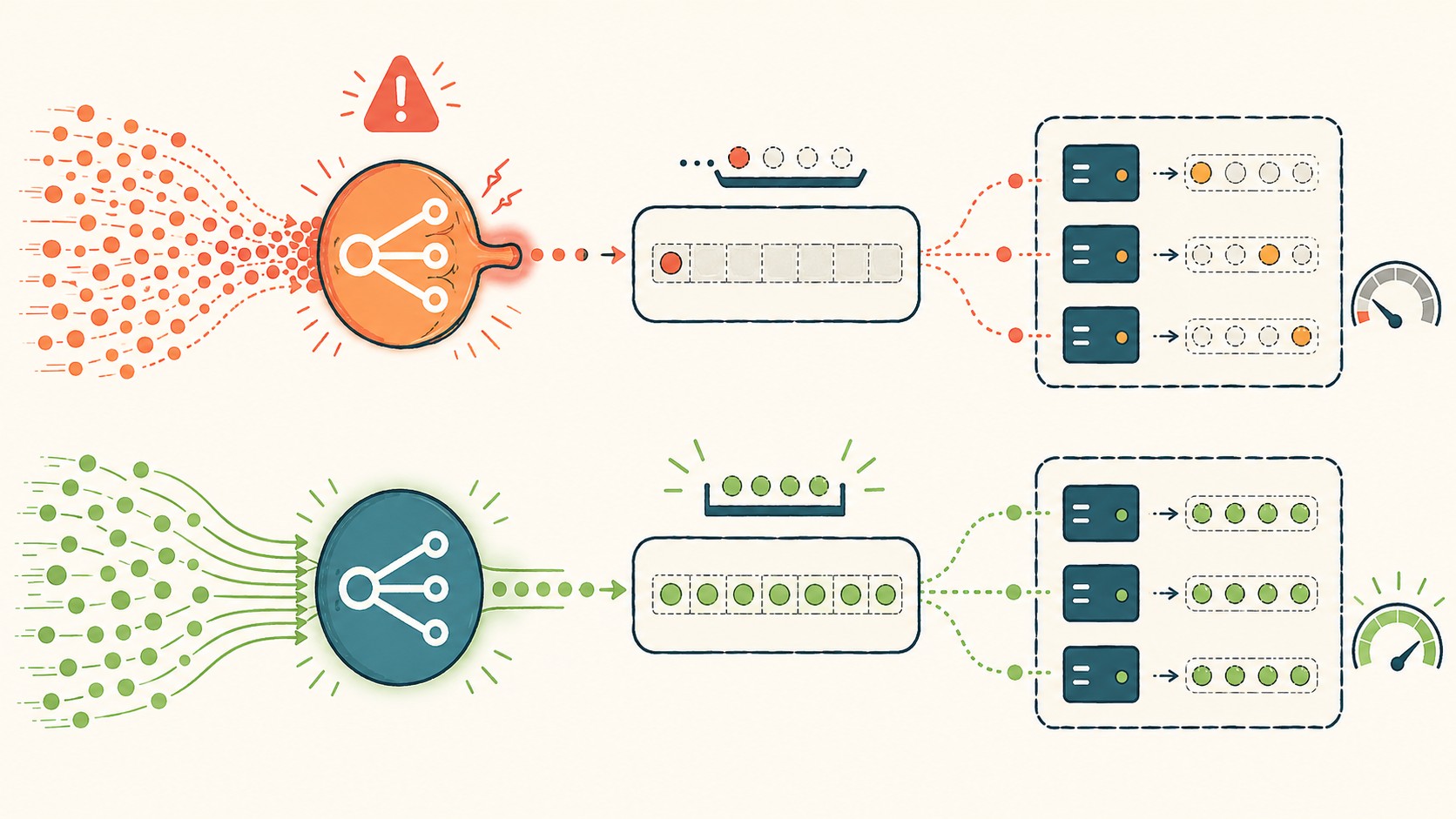
La lógica inicial parecía razonable: si los servidores se sobrecargan con demasiadas conexiones simultáneas, limitá la concurrencia. Menos requests en paralelo, menos presión sobre cada instancia. Según el postmortem publicado en Dev.to, el equipo se concentró en el parámetro “concurrency limit” de la capa de configuración que gobierna el comportamiento de los load balancers y los clusters de servidores.
Tunearon ese parámetro convencidos de que la solución estaba ahí.
No funcionó (spoiler: empeoró).
Por qué crear un bottleneck no resuelve otro bottleneck
Acá viene lo bueno: al reducir el límite de concurrencia, lo que hicieron fue introducir un cuello de botella deliberado en el balanceador de carga mismo. Las requests que antes llegaban al backend ahora se quedaban esperando en el load balancer, que tiene su propio límite de capacidad para manejar colas. Lo explicamos a fondo en pipelines de CI/CD escalables.
El resultado fue que el colapso y los timeouts que querían mitigar se volvieron más frecuentes, no menos. El balanceador empezó a acumular conexiones en espera, lo cual generaba presión adicional justo en el punto que se supone que distribuye la carga, dejando de distribuirla de forma efectiva.
Cualquiera que haya configurado un nginx o un HAProxy sabe que la relación entre concurrencia permitida, tamaño de cola y timeout no es lineal. Bajás uno, sube otro. Si el problema es de capacidad en el backend, limitando la entrada del balanceador solo desplazás el punto de falla, no lo eliminás.
El principio es simple pero fácil de ignorar cuando estás apagando incendios: no podés resolver un problema de capacidad limitando la entrada sin rediseñar el flujo. Si el backend no puede procesar N requests por segundo, impedir que lleguen más de M al balanceador simplemente mueve la cola de N a M.
La solución arquitectónica: una service boundary separada
Después de varias iteraciones, el equipo de Veltrix llegó a una decisión más estructural: introducir una capa intermedia entre el sistema event-driven y los load balancers, creando un service boundary separado.
Este patrón es conocido en arquitecturas de alto volumen. La idea es que el sistema de eventos no interactúe directamente con el balanceador de carga, sino con una capa que puede absorber picos, controlar el flujo, y liberar trabajo hacia el backend a una tasa que este puede procesar. Las ventajas son concretas: Ya lo cubrimos antes en distribuir servidores globalmente.
- Desacoplamiento entre la tasa de entrada de eventos y la capacidad de procesamiento del backend
- Control granular sobre el flujo: podés priorizar tipos de eventos, descartar duplicados, o aplicar rate limiting por tipo de operación
- Los load balancers vuelven a hacer lo que saben hacer: distribuir carga estable, no gestionar picos erráticos
- El backend recibe trabajo a una tasa que puede manejar, reduciendo timeouts a casi cero
Dicho esto, implementar esta capa tiene un costo: complejidad operativa adicional, un componente más que monitorear, y latencia incrementada para eventos que antes eran síncronos. Hay que evaluar si el tradeoff vale para el caso de uso específico.
Errores comunes en tuning de balanceadores
El caso Veltrix no es aislado. Estos patrones de error aparecen seguido:
Confundir síntoma con causa
El colapso y los timeouts son síntomas. El bottleneck real puede estar en la base de datos, en una query lenta, en locks de concurrencia, en el garbage collector de la aplicación, o en el propio balanceador. Antes de tocar parámetros, medí dónde está realmente la saturación.
Tuning reactivo sin carga real
Si no hiciste load testing antes de deployar, cualquier ajuste de configuración es una apuesta. El equipo de Veltrix no tenía datos de cuántas requests por segundo empezaba a fallar su configuración. Con herramientas como wrk, ab, o JMeter, eso se puede saber antes de que sea un problema de producción.
Asumir que menos concurrencia es siempre más estable
Menos concurrencia reduce la presión en el backend, sí, pero también reduce el throughput y desplaza la saturación hacia el balanceador. En sistemas event-driven con picos cortos e intensos, es casi siempre mejor tener colas con backpressure que limitar artificialmente la entrada.
No medir la distribución del problema
¿El bottleneck está en el 5% de las requests más lentas o en el 50%? ¿Es una operación específica o todo el sistema? Sin percentiles (p95, p99) en los logs del balanceador y del backend, estás adivinando. Herramientas como las que describe GeeksForGeeks en su análisis de bottlenecks en system design ayudan a identificar los cuellos de botella primarios antes de actuar.
Patrones probados para eventos de alto volumen
Si tu sistema es event-driven y tiene picos de tráfico, hay alternativas más sólidas que tuning de parámetros en el balanceador: Relacionado: reducir carga con procesamiento local.
| Patrón | Cuándo usarlo | Complejidad | Latencia adicional |
|---|---|---|---|
| Message queue (RabbitMQ, Redis Streams) | Picos cortos e intensos, procesamiento async | Media | Alta (async) |
| Circuit breaker | Dependencias externas que pueden fallar | Media | Baja |
| Rate limiting en la aplicación | Control por usuario/recurso, no por servidor | Baja | Muy baja |
| Service boundary separada | Desacoplar sistemas con velocidades distintas | Alta | Media |
| Event bus con particionado | Volumen muy alto, múltiples consumidores | Alta | Media |
El punto es que la decisión debe salir del análisis del problema, no de qué herramienta estás más cómodo usando. El equipo de Veltrix necesitaba desacoplamiento, y eso indicaba una service boundary o una queue. No un ajuste de parámetros.
Testing antes de producción: lo que el equipo no hizo
La lección más directa del caso es que un load test antes del deploy habría revelado el bottleneck en horas en vez de semanas de iteración en producción.
Con wrk podés simular carga HTTP concurrente en minutos:
wrk -t12 -c400 -d30s http://tu-endpoint/events
Con ese comando: 12 threads, 400 conexiones concurrentes, 30 segundos. Si el sistema empieza a mostrar latencias p99 superiores a 500ms o errores HTTP 503 antes de llegar a las conexiones que esperás en producción, encontraste el límite antes de que lo encuentre el usuario.
¿Y si el load test pasa sin problemas? Subí la carga. El objetivo es encontrar el punto de quiebre, no confirmar que todo está bien bajo carga normal.
Si tenés infraestructura en cloud o VPS y querés hacer estos tests sin afectar producción, podés levantar un entorno de staging en donweb.com y replicar la configuración ahí antes de tocar el servidor principal.
Preguntas Frecuentes
¿Por qué limitar la concurrencia no soluciona problemas de escalabilidad?
Limitar la concurrencia reduce el throughput del sistema sin aumentar su capacidad de procesamiento. El resultado es que las requests no desaparecen sino que se acumulan en otro punto, generalmente el balanceador de carga. Para resolver un problema de escalabilidad, hay que aumentar la capacidad o redistribuir mejor la carga, no restringir la entrada. Más contexto en plataformas seguras para infraestructura.
¿Qué es un bottleneck en el balanceador de carga?
Un bottleneck en el balanceador es cuando ese componente, cuyo trabajo es distribuir tráfico, se convierte en el punto de saturación del sistema. Según Redeszone, el balanceador gestiona la distribución de requests entre servidores backend; si la cola de espera en el balanceador supera su capacidad de procesamiento, los timeouts aumentan aunque los servidores backend tengan capacidad libre.
¿Cómo se resuelve un colapso de servidor en arquitectura event-driven?
La solución recomendada es introducir una capa de desacoplamiento entre la fuente de eventos y el sistema de procesamiento: una message queue, un event bus, o una service boundary separada. Esto permite que los picos de eventos se absorban en la cola en vez de saturar directamente el backend o el balanceador.
¿Cuándo necesito un service boundary en mi arquitectura?
Cuando dos partes de tu sistema operan a velocidades muy distintas y la parte más lenta no puede escalar tan rápido como la parte más rápida genera carga. En el caso Veltrix, el sistema de eventos generaba requests más rápido de lo que el backend podía procesarlas. Una service boundary permite que ambas partes operen a su ritmo sin bloquearse mutuamente.
¿Cuál es la diferencia entre escalar configuración vs escalar arquitectura?
Escalar configuración es ajustar parámetros de sistemas existentes: límites de concurrencia, timeouts, pool sizes. Tiene un límite físico: llegás al máximo que el hardware o el software pueden dar. Escalar arquitectura es rediseñar cómo los componentes interactúan, agregando capas de desacoplamiento, particionado o procesamiento distribuido. Es más costoso de implementar pero no tiene el mismo techo.
Conclusión
El caso Veltrix de mayo 2026 es un ejemplo bien documentado de un error que cometen equipos con buenas intenciones: atacar los síntomas con la herramienta más cercana, que en este caso era la capa de configuración del balanceador. El resultado fue empeorar el problema que querían resolver.
La moraleja no es que la configuración no importa, sino que cualquier ajuste de parámetros tiene que estar guiado por datos de dónde está realmente el bottleneck. Sin load testing, sin métricas de percentiles, sin entender el flujo de datos bajo carga real, estás adivinando. Y en sistemas que tienen que escalar, adivinar en producción es demasiado caro.
Si estás enfrentando colapsos similares, la secuencia correcta es: medí primero (load test, percentiles, identificación del punto de saturación), luego decidí si el problema se resuelve con configuración o con rediseño arquitectónico. En la mayoría de los casos de alto volumen de eventos, la respuesta es rediseño.


![[FREE] I built a no-code RPG game engine plugin for WordPress. Here's a 30 minute build demo - ilustracion](https://donweb.news/wp-content/uploads/2026/04/plugin-rpg-wordpress-sin-codigo-hero-768x429.jpg)
