Veltrix Treasure Hunt Engine: por qué falla a escala
El Treasure Hunt Engine de Veltrix colapsa con más de 10.000 usuarios concurrentes, generando errores java.lang.OutOfMemoryError y com.veltrix.engine.exception.TreasureNotFoundException. La escalabilidad de servidores Java bajo carga es el talón de Aquiles del sistema, y agregar RAM o Redis no resuelve el problema de fondo.
En 30 segundos
- El Treasure Hunt Engine de Veltrix falla con más de 10.000 usuarios concurrentes en producción, con errores de memoria y excepciones propias del motor.
- Subir el heap de la JVM de 8GB a 32GB no resuelve nada: el problema es arquitectural, no de recursos.
- Redis como capa de caché solo parchea el síntoma: la latencia sube a 250ms después de 37 minutos y el garbage collection se pausa hasta 420ms.
- La degradación comienza mucho antes del límite: con 2.500 usuarios activos y menos de 1.200 participantes simultáneos en un Treasure Hunt, el sistema ya muestra signos de estrés.
- La solución real fue rediseñar la arquitectura separando ingestion de queries, usando Kafka con deltas de 30 segundos y removiendo Redis.
El Treasure Hunt Engine: qué es y por qué importa
El Veltrix Treasure Hunt Engine es un sistema de gestión de eventos con estado que requiere sincronización constante entre múltiples servidores para coordinar participantes, pistas y validaciones en tiempo real. No es una feature decorativa: en aplicaciones donde la experiencia de usuario depende de que todos los clientes vean el mismo estado del juego al mismo tiempo, este motor es infraestructura crítica.
El problema con los sistemas de estado compartido es que escalan mal por defecto. Cada vez que un participante encuentra un ítem, valida una pista o actualiza su posición, el motor tiene que propagar ese cambio a todos los servidores del clúster. Con 100 usuarios, eso no es un problema. Con 10.000 usuarios simultáneos lanzando operaciones de lectura y escritura al mismo tiempo, el sistema empieza a ahogarse.
Si alguna vez configuraste un sistema de sesiones distribuidas sabés exactamente de qué estoy hablando.
El punto de quiebre: escalabilidad de servidores Java bajo carga a 10.000 usuarios
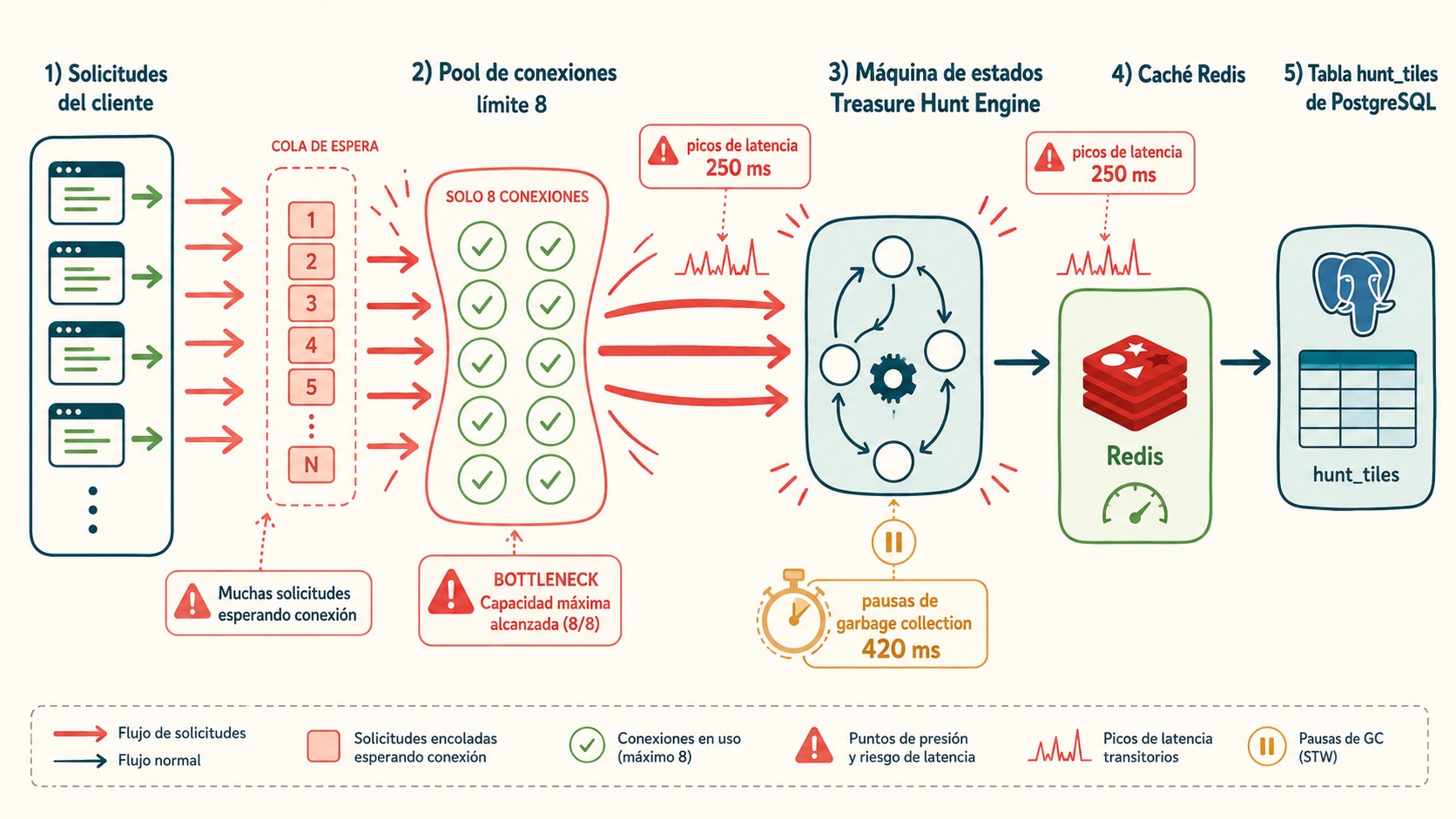
El número concreto que marca el límite es 10.000 usuarios concurrentes. Según el análisis publicado el 28 de mayo de 2026, por encima de esa cota el motor genera dos tipos de error de manera consistente: java.lang.OutOfMemoryError (memoria de la JVM agotada) y com.veltrix.engine.exception.TreasureNotFoundException (el motor no encuentra el estado del tesoro que debería estar en memoria).
Lo interesante es que la degradación no empieza en 10.000. Aparece mucho antes: con apenas 2.500 usuarios activos y un Treasure Hunt con menos de 1.200 participantes simultáneos, el rendimiento ya cae. El sistema llega al límite duro recién más tarde, pero el deterioro es progresivo desde bastante antes. Ya lo cubrimos en detalle al hablar de integración de soluciones de IA para optimización.
¿Por qué ese número específico importa? Porque 10.000 usuarios concurrentes es la escala de una aplicación web mediana. No es Twitter, no es una plataforma enterprise gigante. Es el tamaño al que llega un producto que funciona bien y está creciendo. Y es exactamente ahí donde el motor te abandona.
Soluciones que fallaron: RAM y Redis
La secuencia de decisiones es clásica y dolorosa de leer porque la mayoría de los equipos haría lo mismo.
Primero: aumentar el heap de la JVM. Pasaron de 8GB a 16GB, después a 32GB. Los errores siguieron. Esto tiene sentido una vez que entendés el problema real: el OutOfMemoryError no es porque la JVM tenga poco espacio disponible en estado estático, sino porque bajo carga el motor genera objetos temporales más rápido de lo que el garbage collector puede limpiarlos. Más heap no resuelve eso, solo retrasa el colapso y hace que cuando llega, sea más grande (pausa de GC de 420ms, según los datos del postmortem).
Después intentaron Redis como capa de caché para reducir la presión sobre el motor. Funcionó… durante 37 minutos. Después de ese punto, la latencia subía a 250ms y el sistema volvía a comportarse como antes. El problema es que Redis estaba siendo usado para cachear datos que cambiaban constantemente con cada interacción de los usuarios. La tasa de invalidación era tan alta que la caché nunca llegaba a amortizarse.
Estaban poniendo una curita sobre un problema de diseño.
Raíz del problema: la documentación que no te dice los límites reales
Acá viene lo bueno (o lo malo, dependiendo del punto de vista): la documentación de Veltrix prometía escalabilidad lineal. Y técnicamente no mentía, con los asteriscos correctos aplicados. El problema es que los operadores no sabían cuáles eran los límites de diseño del sistema, así que asumieron que “escalabilidad lineal” significaba “agregás servidores y el sistema aguanta proporcionalmente más carga”. Más contexto en pipelines de integración continua eficientes.
Eso no funciona así cuando el estado compartido no está particionado correctamente. Más servidores en un clúster mal diseñado no escalan linealmente: escalan con overhead de coordinación creciente.
El análisis de documentación apunta directamente a esta brecha: los operadores leen “escalable” y asumen que el sistema sabe manejar cualquier escala que les tiren. La documentación técnica describe capacidades, no límites. Y cuando el sistema colapsa, el operador está solo frente a stack traces que no explican por qué.
Con 14 shards distribuidas en tres continentes, la complejidad de coordinación se multiplica de formas que ningún número de replicas resuelve si la arquitectura base tiene el problema.
Arquitectura correcta: el rediseño que nadie quería hacer
La solución no fue agregar más caché ni más RAM. Fue rediseñar.
Puntualmente: separaron las operaciones de ingestion (escritura de eventos) de las operaciones de query (lectura de estado). Usaron lightweight forwarders para la ingestion y pusieron un buffer en Kafka con deltas enviados cada 30 segundos. Esto permite que el motor procese el estado de forma asíncrona sin que cada escritura de usuario bloquee una consulta de estado.
Y acá viene lo contraintuitivo: sacaron Redis. La capa de caché que habían agregado para reducir la carga terminaba generando más overhead de invalidación del que ahorraba en lecturas. Sin Redis y con la arquitectura correcta, el sistema pasó a manejar la carga que antes lo tumbaba.
No es que Redis sea malo. Es que Redis mal aplicado en un sistema con alta tasa de mutación de estado agrega latencia de coordinación sin dar beneficio real de caché. El truco es entender cuándo la invalidación supera al hit rate.
Errores comunes en la configuración de Veltrix
Más allá del problema de arquitectura, hay configuraciones por defecto que empujan el sistema hacia el límite más rápido de lo necesario. Cubrimos ese tema en detalle en bases de datos escalables en la nube.
Connection pooling en 8 por defecto
El pool de conexiones que viene configurado de fábrica en 8 es razonable para desarrollo local, pero en producción con carga real es un cuello de botella inmediato. Con 10.000 usuarios concurrentes y solo 8 conexiones disponibles, los threads se apilan esperando conexión libre. El resultado se ve como latencia alta, no como un problema de configuración, así que es difícil de diagnosticar si no sabés donde mirar.
Keep-alive deshabilitado
Con keep-alive apagado, cada request abre y cierra una conexión TCP. El overhead de handshake se convierte en un impuesto sobre cada operación del motor. En cargas moderadas no se nota. En cargas altas, el sistema pasa más tiempo estableciendo conexiones que procesando eventos.
Retry logic sin backoff exponencial
Cuando el motor falla bajo carga y los clientes reintentan de forma agresiva y sincrónica, el sistema que ya estaba estresado recibe una avalancha adicional de requests exactamente cuando menos puede manejarlos. Sin backoff, los reintentos amplifican el problema. Con backoff exponencial, el sistema tiene ventanas para recuperarse.
Qué está confirmado / Qué no
| Aspecto | Estado | Detalle |
|---|---|---|
| Fallo a 10.000 usuarios concurrentes | Confirmado | Reportado por múltiples operadores con los mismos errores |
| Inefectividad de aumentar heap a 32GB | Confirmado | Documentado en postmortem publicado el 28/05/2026 |
| Latencia de 250ms con Redis a los 37 minutos | Confirmado | Dato de monitoreo incluido en el análisis técnico |
| Pausa de GC de 420ms bajo carga | Confirmado | Métrica de garbage collection registrada en el incidente |
| Solución de Kafka + separación de ingestion/query | Confirmado como efectiva en el caso reportado | No hay validación independiente publicada aún |
| Fix oficial de Veltrix para el límite de escala | No confirmado | No hay comunicado de la empresa sobre una solución en la plataforma |
Mejores prácticas para evitar el colapso
Si estás corriendo el Treasure Hunt Engine o un sistema con características similares, hay tres cosas que hacen diferencia antes de que el problema aparezca:
Primero, documentá los límites de diseño de tu sistema, no solo las capacidades. La diferencia entre “soporta alta concurrencia” y “empieza a degradarse con más de 2.500 usuarios activos y se cae con más de 10.000” es toda la diferencia operacional del mundo. Tema relacionado: elegir la herramienta correcta para automatizar.
Segundo, monitoreá latencia en Redis (si lo usás) y las métricas de garbage collection de la JVM. Latencia sostenida por encima de 100ms en Redis o pausas de GC frecuentes son señales tempranas de que el sistema está acercándose al límite. Si esperás los OutOfMemoryError para actuar, llegaste tarde.
Tercero, validá los datos en caché activamente. Un cache hit con datos stale puede ser peor que un cache miss si el estado del sistema cambió entre la escritura y la lectura. En sistemas de estado compartido con alta mutación, un dato incorrecto puede generar cascadas de errores difíciles de rastrear. Si tenés servidores propios o en cloud y necesitás una base sólida de infraestructura para este tipo de cargas, donweb.com tiene opciones de hosting y VPS pensadas para aplicaciones con requisitos de disponibilidad real.
Si querés saber más, este artículo sobre Veltrix Treasure Hunt Engine is a Ticking Time Bomb for Scal te va a interesar.
Si querés saber más, tenemos un artículo sobre Veltrix Treasure Hunt Engine is a Ticking Time Bomb for Scal.
Preguntas Frecuentes
¿Cuántos usuarios concurrentes puede soportar el Treasure Hunt Engine de Veltrix?
El motor colapsa de forma consistente con más de 10.000 usuarios concurrentes, generando errores java.lang.OutOfMemoryError. La degradación comienza antes: con 2.500 usuarios activos y menos de 1.200 participantes en un evento activo, el rendimiento ya cae de forma medible. El número exacto varía según la configuración del hardware, pero el límite arquitectural es el mismo.
¿Por qué aumentar la RAM no soluciona los problemas de escalabilidad de servidores Java bajo carga?
Subir el heap de la JVM de 8GB a 32GB no resuelve el problema porque el cuello de botella no es la cantidad de memoria disponible, sino la velocidad a la que el garbage collector puede recuperarla. Bajo carga alta, el motor genera objetos temporales más rápido de lo que el GC los limpia, causando pausas de hasta 420ms que hacen al sistema irresponsivo. El problema es el patrón de creación de objetos, no el tamaño del heap.
¿Cómo detectar cuellos de botella en una arquitectura distribuida con este tipo de motor?
Las señales más tempranas son: latencia sostenida en Redis por encima de 100ms (el caso reportado llegó a 250ms a los 37 minutos), frecuencia y duración de las pausas de garbage collection, y acumulación de threads en espera de conexiones del pool. Estas métricas aparecen antes que los errores fatales y dan ventana para actuar. Configurar alertas sobre estos tres indicadores es el primer paso de monitoreo preventivo.
¿Cuándo Redis se convierte en un problema de rendimiento en vez de una solución?
Redis agrega overhead neto cuando la tasa de invalidación de caché supera el hit rate. En sistemas con alta mutación de estado compartido, cada escritura de usuario invalida entradas de caché, y si los usuarios escriben más rápido de lo que leen datos estables, la caché nunca amortiza su costo de coordinación. El caso de Veltrix es un ejemplo directo: la solución final fue remover Redis, no mejorarlo.
¿Cómo documentar correctamente los límites de diseño de una aplicación web?
La documentación útil incluye los números concretos donde el sistema empieza a degradarse (no solo el límite duro donde colapsa), las condiciones bajo las cuales esos límites aplican (carga de escritura vs. lectura, distribución geográfica, tamaño de payload), y qué métricas monitoreár para saber que se está acercando al límite. “Escalabilidad lineal” sin esos detalles no le sirve a nadie en producción.
Conclusión
El caso del Treasure Hunt Engine de Veltrix es un ejemplo de cómo un problema arquitectural se puede disfrazar durante meses como “necesitamos más recursos”. Subir RAM, agregar Redis, replicar servidores: cada una de esas decisiones tiene sentido intuitivo y cada una fracasó porque atacaba el síntoma y no la causa.
La causa era que el motor no estaba diseñado para separar escritura de lectura bajo carga alta. Una vez que eso quedó claro, la solución fue rediseñar el flujo de datos, no agregar hardware. El resultado: un sistema que maneja la carga que antes lo tumbaba, con menos infraestructura.
La lección que sí se puede generalizar es esta: antes de escalar horizontalmente, entendé cuál es el límite de diseño real de tu sistema. No el que dice la documentación de marketing. El límite real, con métricas reales, en producción real. Esa información vale más que cualquier configuración de hardware.
Fuentes
- Dev.to — Veltrix Treasure Hunt Engine is a Ticking Time Bomb for Scaling Servers (2026-05-28)
- Dev.to — How We Broke the Hytale Treasure Hunt Engine and Fixed It at 3 AM
- Dev.to — Why Hytale’s Treasure Hunt Engines Explode Under Load
- Dev.to — When Server Growth Hits a Wall: The Treasure Hunt Engine Documentation Fails You
- Google Cloud — Kubernetes Engine Scalability Troubleshooting