GPU desperdiciada en Kubernetes: cómo detectarla
El desperdicio de GPU en Kubernetes es un problema silencioso: tus dashboards muestran verde, el cluster parece sano, pero según análisis publicados en mayo de 2026, entre el 20% y el 40% de la capacidad GPU puede estar quemando dinero sin hacer nada útil. Detectar desperdicio GPU en Kubernetes requiere métricas que Kubernetes simplemente no tiene por defecto.
En 30 segundos
- Kubernetes monitorea asignación de GPU, no utilización real: un pod puede tener una GPU asignada y no hacer nada con ella.
- Las formas más comunes de desperdicio incluyen pods idle, modelos sobre-dimensionados (A10G vs H100), y GPU esperando al CPU.
- NVIDIA DCGM con dcgm-exporter + Prometheus + Grafana es el stack estándar para visibilidad real de GPU en 2026.
- Un cluster con 4 nodos A100 puede desperdiciar USD 5.700/mes si la utilización real es del 35%.
- Dynamic Resource Allocation (DRA) y GPU time-slicing pueden subir la utilización del 13% al 37% según datos de Sedai.
Nvidia es una empresa estadounidense que diseña y fabrica unidades de procesamiento gráfico (GPU) y procesadores para inteligencia artificial. Fue fundada en 1993.
Por qué Kubernetes no detecta el desperdicio de GPU
Kubernetes es un orquestador diseñado para CPU y memoria. Sus métricas nativas, node allocations y el scheduler, trabajan al nivel del pod y te dicen una cosa: si una GPU está asignada. No te dicen si algo útil está corriendo en ella.
El desperdicio de GPU es una categoría de problema que Kubernetes no fue construido para resolver. Cuando un pod solicita una GPU, el scheduler la marca como ocupada. Punto. Lo que pase adentro de ese pod, si está entrenando, infiriendo, esperando, o simplemente existiendo, no le importa al orquestador.
El resultado es que tus dashboards operacionales pueden mostrar todo verde mientras una fracción importante de tu inversión en hardware hace absolutamente nada.
Cinco formas comunes de desperdicio de GPU
Ponele que mirás el cluster y ves GPUs al 60-70% de utilización. Parece razonable. Pero esa métrica agrega todo sin discriminar qué tipo de trabajo se está haciendo. Acá están los cinco patrones de desperdicio que se esconden detrás de esos números:
| Tipo de desperdicio | Qué muestra Kubernetes | Qué está pasando realmente |
|---|---|---|
| Pod idle allocation | GPU asignada, utilización baja-media | Procesos en background dan utilización no-zero pero no hay inferencia/training activo |
| Over-provisioning de modelo | GPU ocupada al 70-80% | Modelo que cabe en A10G deployado en H100, consumiendo 3-4x la memoria necesaria |
| CPU bottleneck | GPU al 70% de utilización | GPU esperando preprocessing, tokenización o data loading; throughput real es una fracción |
| KV cache evictions | Utilización estable | Context window creció, se evictan cachés, throughput cae sin bajar el número de utilización |
| Experimentos abandonados | GPU asignada indefinidamente | Notebooks y test deployments sin tráfico siguen ocupando recursos |
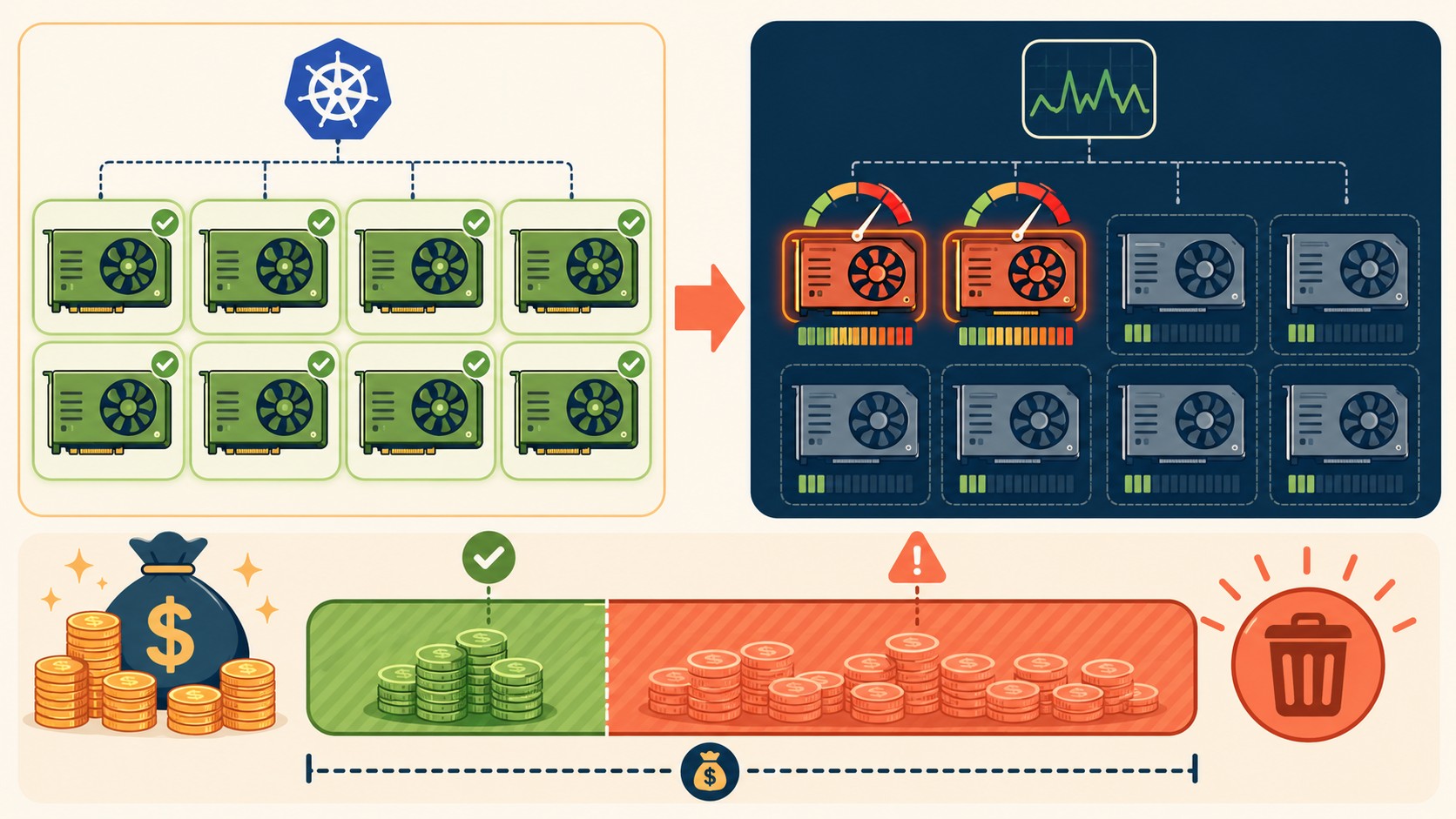
Cada uno de estos parece saludable desde la perspectiva del scheduler. Ninguno dispara alertas. Todos cuestan lo mismo que si estuvieras usando el hardware a full. Te puede servir nuestra comparativa de pipelines CI/CD.
Señales concretas para detectar desperdicio de GPU
La señal más directa es el gap entre GPUs solicitadas y GPUs utilizadas a nivel de namespace. Si un namespace solicita 8 GPUs pero las métricas de DCGM muestran utilización activa en 2, tenés un 75% de desperdicio documentado. No es una estimación: es un número.
Las métricas DCGM que importan son tres: utilización de GPU (DCGM_FI_DEV_GPU_UTIL), utilización de memoria (DCGM_FI_DEV_MEM_COPY_UTIL), y eficiencia de SM (Streaming Multiprocessors). Esta última es la que más se ignora y la que más dice: alta utilización de GPU con baja eficiencia de SM indica que el hardware está ocupado pero no haciendo trabajo útil de cómputo.
Kubecost con su GPU cost allocation te permite traducir esos gaps a dólares por namespace, por pod, por equipo. Eso cambia la conversación: de “parece que desperdiciamos GPU” a “el equipo de data science desperdició USD 12.000 este mes”.
Stack de monitoreo: DCGM, Prometheus y Grafana
NVIDIA DCGM (Data Center GPU Manager) es el estándar de facto para métricas de GPU en 2026. No hay discusión ahí. El camino de instalación más limpio es via NVIDIA GPU Operator en Kubernetes, que maneja drivers, plugins y dcgm-exporter como un stack integrado.
Si preferís instalación más liviana, el NVIDIA GPU Usage Monitor tiene un chart de Helm que despliega dcgm-exporter + Prometheus + Grafana con dashboards pre-construidos. En 15 minutos tenés visibilidad básica.
El flujo completo:
- dcgm-exporter corre como DaemonSet en cada nodo con GPU y expone métricas en formato Prometheus
- Prometheus scrapea esas métricas cada 15-30 segundos
- Grafana visualiza con los dashboards oficiales de NVIDIA (disponibles en grafana.com/grafana/dashboards)
- Kubecost consume las mismas métricas y agrega costo por namespace/pod
Si trabajás en clouds managed, los tres principales tienen integraciones nativas: GKE con DCGM metrics, AKS con GPU monitoring, y EKS via Container Insights. Útil si no querés gestionar el stack de observabilidad vos mismo.
El impacto económico: números reales
Acá viene lo concreto. Al mayo de 2026, cuatro nodos A100 en un cloud provider típico cuestan aproximadamente USD 8.800/mes. Si tu utilización real es del 35% (número común en clusters de ML sin optimización), el trabajo útil que estás comprando vale USD 3.100. Los USD 5.700 restantes se van en humo. En entre las plataformas de automatización más utilizadas profundizamos sobre esto.
¿Y qué pasó cuando equipos reales empezaron a monitorear esto? Según datos de Sedai de 2026, clusters sin gestión activa operan con 13% de utilización de GPU en promedio. Con ajustes de scheduling avanzado y Dynamic Resource Allocation, llegaron al 37%. Sigue siendo bajo, pero la mejora en costo relativo es enorme.
El over-provisioning por SLA es otro vector de desperdicio que se justifica con “necesitamos el hardware disponible para picos de tráfico”. Tiene sentido en algunos casos. El problema es cuando ese argumento se usa para dejar clusters sobredimensionados durante meses sin revisión.
Estrategias para reducir el desperdicio
Una vez que tenés visibilidad, las palancas de optimización son concretas:
Dynamic Resource Allocation (DRA): Feature de Kubernetes que permite que los pods soliciten fracciones de GPU en vez de unidades enteras. Mejora de utilización del 20-40% según la carga de trabajo. Disponible desde Kubernetes 1.26, estabilizado en versiones recientes.
GPU time-slicing: NVIDIA permite particionar una GPU para múltiples pods con time-sharing. Funciona bien para cargas de inferencia con batch pequeño. No es magia: si todos los tenants mandan trabajo a la vez, compiten.
Multi-Instance GPU (MIG): En A100 y H100, permite partición física de la GPU en instancias independientes con memoria aislada. Más seguro que time-slicing para workloads que requieren predictibilidad.
El resultado alcanzable con un stack completo de optimización, según datos de 2026, es pasar del 30% de utilización al rango 70-80%. No es trivial de implementar, pero el retorno es obvio cuando sabés cuánto estás pagando por el 70% que se desperdicia. Cubrimos ese tema en detalle en en el análisis de optimización técnica.
Pasos prácticos para empezar a monitorear GPU hoy
Si partís de cero, el orden es este:
- Paso 1: Instalá NVIDIA GPU Operator (si tenés nodos con GPU) o dcgm-exporter como DaemonSet. El Operator es más completo pero requiere permisos de cluster-admin.
- Paso 2: Conectá dcgm-exporter a tu instancia de Prometheus. Si no tenés Prometheus, el chart de NVIDIA GPU Usage Monitor lo incluye.
- Paso 3: Importá los dashboards de Grafana de NVIDIA. Buscar “NVIDIA DCGM Exporter Dashboard” en grafana.com/grafana/dashboards.
- Paso 4: Mirá el gap entre DCGM_FI_DEV_GPU_UTIL y las requests declaradas en los pods. Ese gap es tu baseline de desperdicio.
- Paso 5: Identificá los namespaces con mayor desperdicio. Con Kubecost podés poner número en dólares a cada uno y priorizar dónde actuar primero.
Con esto tenés visibilidad real en un día. Lo que hacés con esa información después depende del equipo y del contexto, pero al menos la conversación pasa de vaga a concreta.
Errores comunes al monitorear GPU en Kubernetes
Confiar solo en GPU utilization como métrica de salud. Ya lo vimos: 70% de utilización puede esconder CPU bottleneck, KV cache evictions o trabajo inútil. Siempre cruzar con eficiencia de SM y throughput de requests.
No diferenciar entre asignación y utilización a nivel de cluster. Kubernetes te muestra cuántas GPUs están asignadas. DCGM te muestra cuántas están haciendo trabajo útil. Si solo mirás la primera, el problema es invisible.
Deployar DCGM sin ajustar el scrape interval. Con el default de 60 segundos, los picos y caídas de workloads de inferencia quedan suavizados en las métricas. Para detección real de idle pods, bajá a 15-30 segundos y aceptá el overhead de Prometheus.
Ignorar los experimentos y notebooks abandonados. En clusters de ML es casi seguro que hay al menos 2-3 pods corriendo que nadie recuerda haber deployado. Una revisión mensual de pods sin requests en los últimos 7 días suele liberar recursos sorprendentes. Para más detalles técnicos, mirá ejecutando agentes sin depender de servicios externos.
En otro artículo profundizamos sobre optimizar GPU en Kubernetes si te interesa saber más.
Preguntas Frecuentes
¿Cómo sé si estoy desperdiciando GPU en Kubernetes sin instalar herramientas adicionales?
Con las herramientas nativas de Kubernetes no podés saberlo. kubectl top nodes no incluye métricas de GPU. Lo mínimo indispensable es instalar dcgm-exporter como DaemonSet, que es liviano y no requiere cambios en la arquitectura del cluster. Sin eso, la información simplemente no existe.
¿Qué es el desperdicio de GPU en Kubernetes?
El desperdicio de GPU en Kubernetes es la brecha entre la capacidad de GPU asignada a pods y la que realmente se usa para trabajo útil de cómputo. Kubernetes asigna GPU como recurso discreto a nivel de pod, pero no mide ni reporta si ese hardware hace inferencia, entrenamiento, o simplemente existe sin carga. La diferencia puede representar el 20-40% del gasto total en GPU.
¿Cuánto puede costar el desperdicio de GPU en un cluster típico?
Con 4 nodos A100 a USD 8.800/mes y 35% de utilización real, el desperdicio es USD 5.700 mensuales. El porcentaje varía según el tipo de workload: clusters de ML research o desarrollo tienen utilización más baja que producción de inferencia, por lo que el desperdicio relativo suele ser mayor en entornos no-productivos.
¿Qué herramientas son el estándar para monitorear GPU en Kubernetes en 2026?
NVIDIA DCGM con dcgm-exporter es el estándar. Se integra con Prometheus para almacenamiento de métricas y Grafana para visualización. Para costo por namespace, Kubecost es la opción más usada. GKE, AKS y EKS tienen integraciones nativas con DCGM que simplifican el setup en clouds managed.
¿Cómo mejorar la utilización de GPU en Kubernetes sin cambiar los workloads?
Dynamic Resource Allocation (DRA) permite fracciones de GPU por pod y da mejoras del 20-40% de utilización sin tocar el código de los workloads. GPU time-slicing y MIG en hardware A100/H100 también mejoran densidad de pods por GPU. Con estas técnicas, la utilización puede subir del rango 13-30% al 70-80% según datos de 2026.
Conclusión
El problema con el desperdicio de GPU en Kubernetes no es técnico en el fondo: es de visibilidad. Kubernetes nunca prometió medir utilización de GPU, y sin métricas de DCGM, ese 20-40% de capacidad desperdiciada simplemente no aparece en ningún dashboard.
El stack para verlo existe, no es complejo, y el retorno de instalarlo se mide en horas. Si tenés nodos GPU en producción y no tenés dcgm-exporter corriendo, no sabés lo que estás gastando de verdad.
¿Por dónde empezar? Instalá dcgm-exporter, conectalo a Prometheus, y mirá el gap entre solicitudes y utilización real en cada namespace. Con eso ya tenés los números para saber si el problema vale la atención. En la mayoría de los clusters, la respuesta es sí.
![[Databricks on AWS #4] The BOOTSTRAP_TIMEOUT Mystery: Tracing a Databricks Cluster from Data Plane to Control Plane (Transit Gateway + Firewall) - ilustracion](https://donweb.news/wp-content/uploads/2026/07/databricks-cluster-bootstrap-timeout-aws-firewall-hero-768x432.jpg)