Llama 2 en DigitalOcean: $5/mes con Ollama
Si querés desplegar Llama 2 en DigitalOcean, el costo real es $5/mes usando el droplet básico con Ollama y cuantización Q4_K_M. Un desarrollador documentó en mayo de 2026 que migró de gastar $2.400/mes en APIs de IA a $5/mes en self-hosting, con tiempos de respuesta por debajo de 500ms para el modelo 7B cuantizado.
En 30 segundos
- Ollama + Llama 2 7B cuantizado (Q4_K_M) corre en un VPS de 4GB RAM sin GPU
- El costo total es $5/mes en DigitalOcean vs $2.700/mes en OpenAI con 100K requests mensuales
- La cuantización Q4_K_M reduce el modelo de 13GB a 3.8GB con pérdida mínima de calidad
- Configuración completa: crear droplet, instalar Ollama, descargar modelo, exponer puerto 11434 — menos de 10 minutos
- El punto de quiebre económico está alrededor de los 50 millones de tokens mensuales
Por qué migrar de OpenAI API a Llama 2 self-hosted
Llama 2 es la familia de modelos de lenguaje grande de Meta, disponible en variantes de 7B, 13B y 70B parámetros, con licencia que permite uso comercial bajo ciertas condiciones. A diferencia de las APIs de OpenAI o Anthropic, podés descargar los pesos y correrlos en tu propia infraestructura.
El caso que circuló a finales de mayo de 2026 en dev.to lo pone en perspectiva: según el autor del post, gastaba $2.400 mensuales en Claude API para una carga de trabajo que un colega suyo resolvía con self-hosting por $5. Eso no es ahorro marginal, es un orden de magnitud diferente.
El tradeoff existe, claro. Con las APIs pagás por el acceso a modelos mejores, sin preocuparte por mantenimiento, actualizaciones ni gestión de infraestructura. El self-hosting requiere una tarde de configuración inicial, algún conocimiento básico de Linux, y aceptar que vas a tener una latencia mayor si no tenés GPU. Para muchos casos de uso —automatizaciones internas, procesamiento en batch, herramientas que no son críticas en tiempo real— ese tradeoff tiene sentido. Para otros, no.
Análisis de costos: el umbral donde el self-hosting gana
Los números son los que deciden esta conversación, así que vamos directo.
GPT-4 vía OpenAI API cuesta $0.03 por cada 1.000 tokens de entrada y $0.06 por cada 1.000 de salida. Una request típica con 500 tokens de entrada y 200 de salida sale $0.000027. Con 100.000 requests mensuales, estás pagando alrededor de $2.700/mes. El droplet de $5 en DigitalOcean corre el modelo Llama 2 7B cuantizado durante esas mismas 100.000 requests por $5 fijos, sin importar cuántos tokens proceses.
| Volumen mensual | OpenAI GPT-4 | Self-hosted ($5 VPS) | Ahorro |
|---|---|---|---|
| 10K requests | ~$270 | $5 | 98% |
| 50K requests | ~$1.350 | $5 | 99.6% |
| 100K requests | ~$2.700 | $5 | 99.8% |
| 500K requests | ~$13.500 | $15 (3 droplets) | 99.9% |
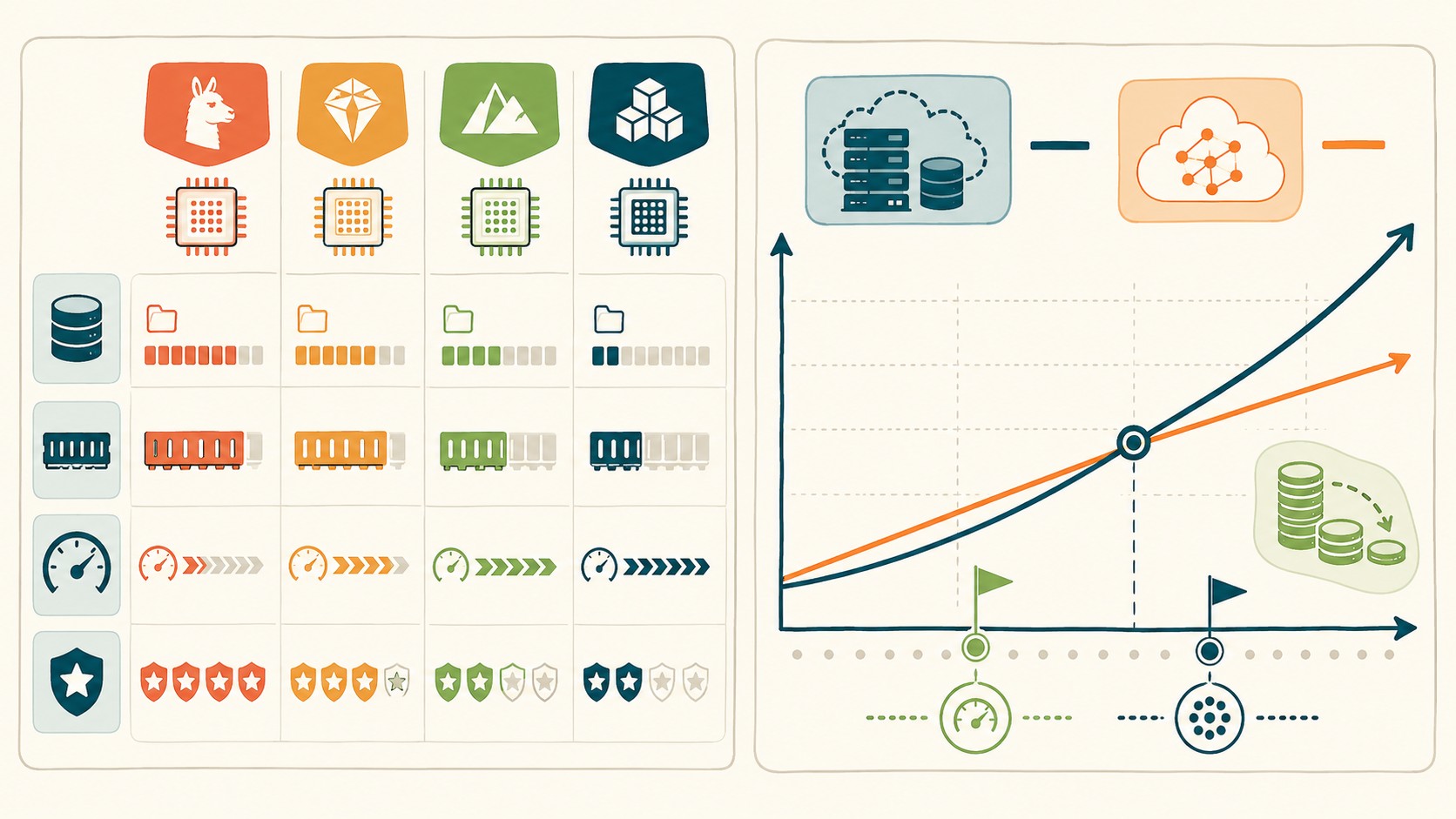
El punto de quiebre donde el self-hosting empieza a valer la pena está en algún lugar entre 50 y 100 millones de tokens mensuales. Antes de ese umbral, la simplicidad de una API puede compensar el costo extra. Después, la diferencia es tan grande que seguir usando APIs solo se justifica si el modelo open-source no da la calidad que necesitás.
Requerimientos de hardware: qué necesitás antes de arrancar
Para desplegar Llama 2 en DigitalOcean o cualquier VPS similar, el mínimo real es 4GB de RAM y 2 vCPU. Con eso corre el modelo 7B cuantizado a Q4_K_M. No es rápido (hablamos de 15-30 segundos por request en CPU pura), pero corre. Esto se conecta con lo que analizamos en automatizar despliegues con CI/CD.
Si querés algo más usable, 8GB de RAM con 4 vCPU es el sweet spot para el 7B sin cuantización extrema. Para el modelo 13B, necesitás mínimo 16GB RAM para que entre cómodo. La GPU es opcional pero transforma los tiempos: un NVIDIA T4 baja la latencia de 30 segundos a 3 segundos para el mismo 7B, según los benchmarks que muestra Floredata en su guía de Ollama.
Presupuestos reales en mayo de 2026: el droplet básico de DigitalOcean a $6/mes (ajustaron precios), Hetzner a €3.79/mes para el CPX11, y VPS de bajo costo como los de Contabo a partir de $5.50/mes. DigitalOcean tiene además $200 de crédito gratis para cuentas nuevas, lo que te da prácticamente cuatro meses gratis para probar.
Instalación de Ollama en DigitalOcean: paso a paso
Ollama es la herramienta que simplifica correr modelos LLM localmente. Maneja la descarga de pesos, cuantización y exposición de API sin que tengas que compilar nada. Es la forma más rápida de tener Llama 2 corriendo.
El proceso completo para desplegar Llama 2 en DigitalOcean es este:
- Crear un droplet Ubuntu 22.04 LTS (4GB RAM mínimo), habilitar acceso SSH
- Conectarse vía SSH y ejecutar:
curl -fsSL https://ollama.com/install.sh | sh - Descargar el modelo:
ollama run llama2(descarga ~3.8GB para el 7B Q4) - Configurar para escuchar externamente:
OLLAMA_HOST=0.0.0.0 ollama serve - Verificar con:
curl http://TU_IP:11434/api/generate -d '{"model":"llama2","prompt":"Hola"}'
El puerto por defecto es el 11434. Acordate de abrir ese puerto en el firewall del droplet o configurar un proxy nginx si querés HTTPS. La guía completa de Ollama en Javadex cubre bien la configuración del firewall ufw para Ubuntu.
Primera vez que lo corrés, la descarga tarda unos minutos. Después de eso, el modelo queda cacheado en disco y el tiempo de inicio es de segundos.
Cuantización: cómo bajar de 13GB a 3.8GB sin perder demasiado
La cuantización reduce la precisión numérica de los pesos del modelo para que ocupe menos memoria. Q4_K_M es el estándar de facto para Ollama: usa 4 bits por peso con un método de mezcla (K_M) que preserva mejor los valores importantes.
Los tamaños resultantes son concretos: Llama 2 7B pasa de 13GB en float16 a 3.8GB en Q4_K_M. El 13B pasa de 26GB a 7.5GB. Eso es la diferencia entre necesitar un servidor de $80/mes o uno de $6.
¿Qué nivel de cuantización elegir?
Q4_K_M es el punto de equilibrio para la mayoría. Q5 y Q5_K_M dan mejor calidad con ~20% más de memoria. INT8 (Q8) es casi indistinguible del modelo original pero duplica el tamaño. Según el análisis de cuantización con llama.cpp de jacar.es, la pérdida de perplexity entre Q4_K_M y el original está por debajo del 1% en la mayoría de benchmarks estándar. Para la mayoría de los casos de uso prácticos, eso no se nota.
Ollama ya descarga versiones cuantizadas por defecto. Si querés elegir explícitamente: ollama run llama2:7b-chat-q5_K_M o ollama run llama2:13b-chat-q4_K_M. Sobre eso hablamos en elegir herramienta de despliegue.
Containerizar con Docker para producción
Para un setup más serio, Docker te da reproducibilidad y facilita el escalado. Ollama tiene imagen oficial:
docker run -d -p 11434:11434 --name ollama ollama/ollama— arranca el servidordocker exec -it ollama ollama pull llama2— descarga el modelo dentro del container- Para persistir el modelo entre reinicios: montar volumen en
/root/.ollama
El health check básico para Docker Compose es una llamada GET a http://localhost:11434/ que devuelve “Ollama is running”. Con eso configurás reintentos automáticos si el proceso cae.
Si manejás tu infraestructura en donweb.com o pensás migrar a un VPS local con soporte en español, el proceso es idéntico: cualquier VPS Linux con Ubuntu 22.04 y los recursos mínimos mencionados.
Latencia y performance: qué esperar de verdad
El artículo que circuló promete respuestas bajo 500ms. Eso es posible, con condiciones.
En CPU pura, el 7B Q4_K_M genera aproximadamente 5-10 tokens por segundo en un droplet de 4 vCPU. Para una respuesta de 150 tokens, estás en 15-30 segundos. Lejos de los 500ms. ¿Cómo llegan a ese número? Con GPU (NVIDIA T4 o similar), el mismo modelo genera 50-100 tokens por segundo. Ahí sí llegás a los 500ms para respuestas cortas. El problema es que una GPU en la nube te cuesta entre $0.35 y $0.70/hora, o sea $250-$500/mes mínimo. No es el droplet de $5.
Para requests en batch (procesamiento asíncrono, no interactivo), el CPU puro zafa perfectamente. Para una aplicación de chat interactiva, si no tenés GPU, las expectativas de latencia tienen que estar calibradas distinto.
Escalado horizontal: cuando un servidor no alcanza
Tres droplets de $5 (o el equivalente actual, cerca de $18-20/mes total) con nginx como load balancer te dan capacidad para manejar tráfico concurrente. La configuración es un upstream simple de nginx apuntando a las tres IPs, con las instancias de Ollama corriendo en cada una. Lo explicamos a fondo en posicionar en múltiples idiomas.
Con ese setup de tres nodos, el costo por millón de tokens generados sigue siendo fracciones de centavo comparado con cualquier API comercial. El failover básico lo maneja nginx automáticamente si una instancia no responde.
Para escala mayor, Kubernetes es una opción. Pero honestamente, salvo que estés manejando cientos de requests por minuto, tres instancias con nginx son suficientes y mucho más simples de operar.
Errores comunes al desplegar Llama 2 en un VPS
Subestimar la RAM necesaria
El error más frecuente es intentar correr el 7B en un droplet de 2GB. El modelo no carga, Ollama falla silenciosamente o el proceso queda en swap infinito. Mínimo 4GB RAM para el 7B Q4_K_M, punto. Si el presupuesto no da, bajá a Phi-3 mini o Gemma 2B que corren en 2GB.
Dejar el puerto 11434 abierto sin autenticación
Ollama no tiene autenticación por defecto. Si exponés el puerto directo a internet, cualquiera puede usar tu modelo. Usá un proxy nginx con autenticación básica, o dejá el puerto cerrado externamente y accedé solo vía SSH tunnel o desde tu aplicación backend.
No persistir el modelo en Docker
Si usás Docker sin volumen, cada vez que el container se reinicia perdés los modelos descargados (los 3.8GB que tardaron varios minutos en bajar). El volumen va en /root/.ollama: -v ollama:/root/.ollama. Si te olvidás de esto la primera vez, te acordás rápido cuando el container se cae a la madrugada y el modelo no está.
Comparar calidad con GPT-4 y frustrarse
Llama 2 7B no es GPT-4. Es un modelo mucho más capaz que GPT-3.5 en muchas tareas específicas, pero si lo comparás directamente con GPT-4 Turbo en razonamiento complejo, vas a quedar insatisfecho. El modelo correcto para self-hosting hoy, si querés calidad competitiva, sería Llama 3.1 70B o Mistral 7B. Para casos de uso más acotados, el 7B alcanza y sobra. En ejecutar agentes sin APIs externas profundizamos sobre esto.
Si te interesa la implementación de modelos de IA, tenés nuestro artículo How to Deploy Llama 2 on DigitalOcean for $5/Month: Complete.
Mirá cómo Desplegar Llama 2 en tu propio servidor con Docker.
Si querés meterte en esto, tenemos un artículo sobre desplegar modelos localmente.
Preguntas Frecuentes
¿Cómo despliego Llama 2 en un VPS económico sin GPU?
Instalás Ollama con el script oficial (curl -fsSL https://ollama.com/install.sh | sh) en cualquier VPS Ubuntu 22.04 con 4GB RAM mínimo, y ejecutás ollama run llama2. El modelo se descarga en versión Q4_K_M (~3.8GB) y queda disponible en el puerto 11434. Sin GPU, la latencia es de 15-30 segundos por request.
¿Cuánto cuesta realmente hostear Llama 2 vs usar OpenAI API?
El VPS básico sale $5-6/mes fijos. GPT-4 vía API cuesta $0.000027 por request típica; con 100.000 requests mensuales, son cerca de $2.700/mes. Para volúmenes bajos (menos de 10.000 requests/mes), la diferencia no justifica el setup. Para volúmenes medios-altos, el self-hosting es órdenes de magnitud más barato.
¿Qué especificaciones de servidor necesito para Llama 2 cuantizado?
Para Llama 2 7B Q4_K_M: 4GB RAM, 2 vCPU, 10GB disco mínimo. Para el 13B Q4_K_M: 16GB RAM, 4 vCPU. La GPU no es obligatoria pero cambia la latencia de 30 segundos a 3 segundos para el 7B. Sin GPU, el self-hosting sirve para procesamiento en batch pero no para chat interactivo de baja latencia.
¿Cómo instalo Ollama en DigitalOcean paso a paso?
Creás un droplet Ubuntu 22.04 con 4GB RAM, te conectás por SSH, corrés curl -fsSL https://ollama.com/install.sh | sh, luego ollama run llama2 para bajar el modelo, y finalmente OLLAMA_HOST=0.0.0.0 ollama serve para exponerlo externamente. Todo el proceso toma menos de 10 minutos más el tiempo de descarga del modelo.
¿En cuánto tiempo responde Llama 2 en self-hosting sin GPU?
En CPU pura con el 7B Q4_K_M en un droplet de 4 vCPU, esperá entre 15 y 30 segundos por respuesta de longitud media. El tiempo de 500ms que mencionan algunas guías corresponde a setups con GPU (NVIDIA T4 o similar), que cuestan $250-500/mes extra. Para uso interactivo sin GPU, considerá modelos más pequeños como Phi-3 mini o Gemma 2B que generan a 20-40 tokens por segundo en CPU.
Conclusión
Desplegar Llama 2 en DigitalOcean tiene sentido cuando el volumen de requests es lo suficientemente alto como para que la diferencia de costos sea inapelable. Con 100.000 requests mensuales, la diferencia entre $5 y $2.700 habla por sí sola. El setup con Ollama es sorprendentemente simple para lo que da: modelo corriendo en menos de 10 minutos, API compatible HTTP, escalado horizontal con nginx.
El único punto donde hay que ser honesto con las expectativas es la latencia sin GPU. Si necesitás respuestas en tiempo real para un chat interactivo, el $5/mes no alcanza: necesitás GPU, y eso cambia completamente la ecuación de costos. Pero para automatizaciones, procesamiento en batch, herramientas internas o cualquier flujo donde 15-30 segundos no son un problema, este setup es una opción muy sólida en 2026.