Tu WebSocket dice ‘conectado’ pero no llegan datos
Tu WebSocket dice “conectado” pero no llegó un solo dato en las últimas horas. Eso es exactamente lo que le pasó a un desarrollador el 16 de mayo de 2026: su API de señales cripto falló 22 horas sin errores, sin excepciones, sin alertas. El dashboard mostraba todo verde. La base de datos, sin datos nuevos. La causa: una conexión WebSocket que se perdió en silencio que TCP no detectó.
En 30 segundos
- “Conectado” a nivel TCP no significa que el servidor esté enviando datos — el socket puede estar abierto y el flujo de mensajes, muerto.
- TCP keepalive verifica que la ruta de red exista, no que la aplicación del otro lado siga funcionando. Su intervalo por defecto ronda las 2 horas.
- Proxies, load balancers y NAT de redes móviles cierran conexiones inactivas en 30-90 segundos sin notificarte.
- La solución correcta es un heartbeat a nivel aplicativo: ping/pong de WebSocket (RFC 6455) o mensajes periódicos propios cada 30-45 segundos.
- Sin monitoreo que compare “estado TCP activo” vs “datos recibidos recientemente”, el problema puede durar horas antes de que alguien lo note.
El engaño del estado ‘conectado’
Una pérdida silenciosa de conexión WebSocket ocurre cuando el socket TCP sigue abierto pero la aplicación dejó de recibir mensajes, sin que ningún error lo indique. El caso documentado en dev.to el 16 de mayo de 2026 es perfecto para entender el problema: una API de señales cripto conectada a Binance funcionó 22 horas sin recibir datos, con logs fluyendo normalmente, deploys en verde, y nadie lo notó hasta que alguien revisó la base de datos manualmente.
Cuando abrís una conexión WebSocket, por debajo hay un socket TCP. “Conectado” significa exactamente eso: hay un socket TCP abierto entre tu cliente y el servidor, y TCP cree que la ruta está viva.
Nada más.
TCP no sabe si el servidor sigue enviando mensajes. No sabe si hay un proxy en el medio que cortó tu suscripción. No sabe si un bug en el backend dejó la conexión abierta pero sin emitir eventos. Lo único que TCP verifica es que los paquetes puedan viajar de un punto al otro.
Por qué TCP keepalive no alcanza
TCP keepalive existe, y la gente suele asumir que “cubre” el problema. No lo cubre.
El mecanismo manda paquetes vacíos periódicamente para verificar que la ruta sigue activa. El detalle: el intervalo por defecto en Linux es de 2 horas. Dos horas. En Windows, similar. Y no es algo que tu aplicación pueda cambiar libremente porque depende de configuración del sistema operativo, no del proceso.
¿Y qué pasa si el problema no es la ruta de red sino la aplicación? Exacto, TCP keepalive no ve nada. Los escenarios que no detecta incluyen: que el servidor remoto dejó de emitir eventos (bug en backend), que un load balancer intermediario cortó la suscripción sin cerrar el socket TCP, o que la app del otro lado entró en un estado inconsistente y dejó la conexión abierta sin mensajes. En todos esos casos, TCP dice “todo bien”, y vos estás sin datos.
Pérdida silenciosa de conexión WebSocket: cómo ocurre en producción
Hay tres causas frecuentes que la gente no anticipa cuando diseña el sistema.
Primero, proxies y load balancers. La mayoría cierra conexiones que no tuvieron tráfico de aplicación en 30-90 segundos. Nginx tiene un timeout de 60 segundos por defecto. AWS ALB, 60 segundos también. Tu conexión TCP puede sobrevivir ese timeout si TCP keepalive manda un paquete vacío a tiempo, pero eso no ayuda si el proxy ya decidió internamente que la suscripción está muerta sin avisarte.
Segundo, NAT en redes móviles (que afecta a cualquier app que corra en celulares). El NAT de los carriers mata conexiones inactivas a veces en 30 segundos, a veces en 5 minutos, sin patrón consistente.
Tercero, bugs de backend. El servidor puede tener un estado interno donde dejó de pushear eventos pero mantuvo el socket abierto porque técnicamente no “falló” nada. Desde el lado del cliente, eso es indistinguible de “todo bien, esperando el próximo mensaje”.
El síntoma visible: logs que fluyen normalmente en tu servicio, dashboard verde, proceso vivo, pero la base de datos sin actualizaciones. Si no tenés una métrica que compare “datos recibidos en los últimos N segundos” contra el estado TCP, podés estar ciego por horas.
Solución 1: Ping/Pong a nivel protocolo
El RFC 6455, que define WebSocket, especifica frames de control ping y pong. La idea: el servidor manda un frame ping, el cliente responde con pong automáticamente (la librería lo hace sola, sin código tuyo). Si el pong no llega en un timeout razonable, sabés que la conexión está muerta.
Ponele que usás ws en Node.js:
La librería tiene soporte nativo. Al crear el servidor podés pasar pingInterval y pingTimeout. Si el cliente no responde al ping en el tiempo configurado, el servidor cierra el socket y el cliente puede reconectar. En Python, la librería websockets tiene el mismo mecanismo con ping_interval y ping_timeout como parámetros del servidor.
La limitación real: JavaScript en el navegador no puede acceder a los frames de ping/pong directamente (la API de WebSocket del browser no los expone). Para clientes web, necesitás la siguiente opción.
Solución 2: Heartbeat a nivel aplicativo
Según websocket.org, el heartbeat a nivel aplicativo es el método más portable porque funciona tanto en servidores como en browsers. La lógica es simple: cliente y servidor se mandan mensajes periódicos entre sí, y si el otro lado no responde en el tiempo esperado, se reconecta.
¿Cada cuántos segundos? El número recomendado es 30-45 segundos. No es arbitrario: está calibrado para ser el 75% del timeout típico de un proxy (60 segundos), lo que garantiza que siempre haya tráfico de aplicación antes de que el intermediario decida matar la conexión.
El flujo básico en un cliente:
- Mandás un mensaje de tipo “ping” (JSON o lo que uses).
- Guardás un timestamp o flag de “ping pendiente”.
- Si en X segundos no llegó el “pong”, cerrás el socket y reconectás.
- Si llegó el pong, limpiás el flag y programás el próximo ping.
Para apps móviles hay un detalle extra: cuando el usuario minimiza la app o apaga la pantalla, el SO puede suspender el proceso. Usando el evento visibilitychange en browser (o el equivalente en iOS/Android), podés pausar los pings mientras la app está en background y forzar una reconexión cuando vuelve al frente. Ignorar esto genera falsos positivos de “conexión muerta” cuando el problema es en realidad que el SO pausó el proceso en background.
Implementación práctica: Node.js y Python
Node.js con la librería ws:
Marcás cada conexión como “viva” cuando recibe un pong. En el intervalo de heartbeat, revisás todas las conexiones: las que no están marcadas como vivas las terminás. Las vivas las desmarcás y mandás el próximo ping. Con ws v8+, esto son unas 15 líneas.
Python con websockets:
Pasás ping_interval=30 y ping_timeout=10 al crear el servidor. La librería maneja todo automáticamente: manda pings, espera pongs, y levanta ConnectionClosed si el pong no llega. En el cliente podés usar el mismo parámetro en connect().
Lo importante en ambos casos: la reconexión tiene que ser automática. No es suficiente detectar la desconexión si tu proceso muere ahí. Implementá reconexión con backoff exponencial (no linear, para no martillar el servidor si hay un problema masivo). Cubrimos ese tema en detalle en ejecuta procesos sin depender de APIs externas.
Comparativa: TCP keepalive vs Ping/Pong vs Heartbeat aplicativo
| Mecanismo | ¿Detecta ruta muerta? | ¿Detecta app muerta? | Intervalo típico | Funciona en browser | Control desde la app |
|---|---|---|---|---|---|
| TCP keepalive | Sí | No | 2 horas (OS) | Sí (sin control) | No |
| WebSocket ping/pong (RFC 6455) | Sí | Sí | Configurable (ej. 30s) | No (API no expuesta) | Sí (servidor) |
| Heartbeat aplicativo | Sí | Sí | 30-45 segundos (recomendado) | Sí | Sí (ambos lados) |
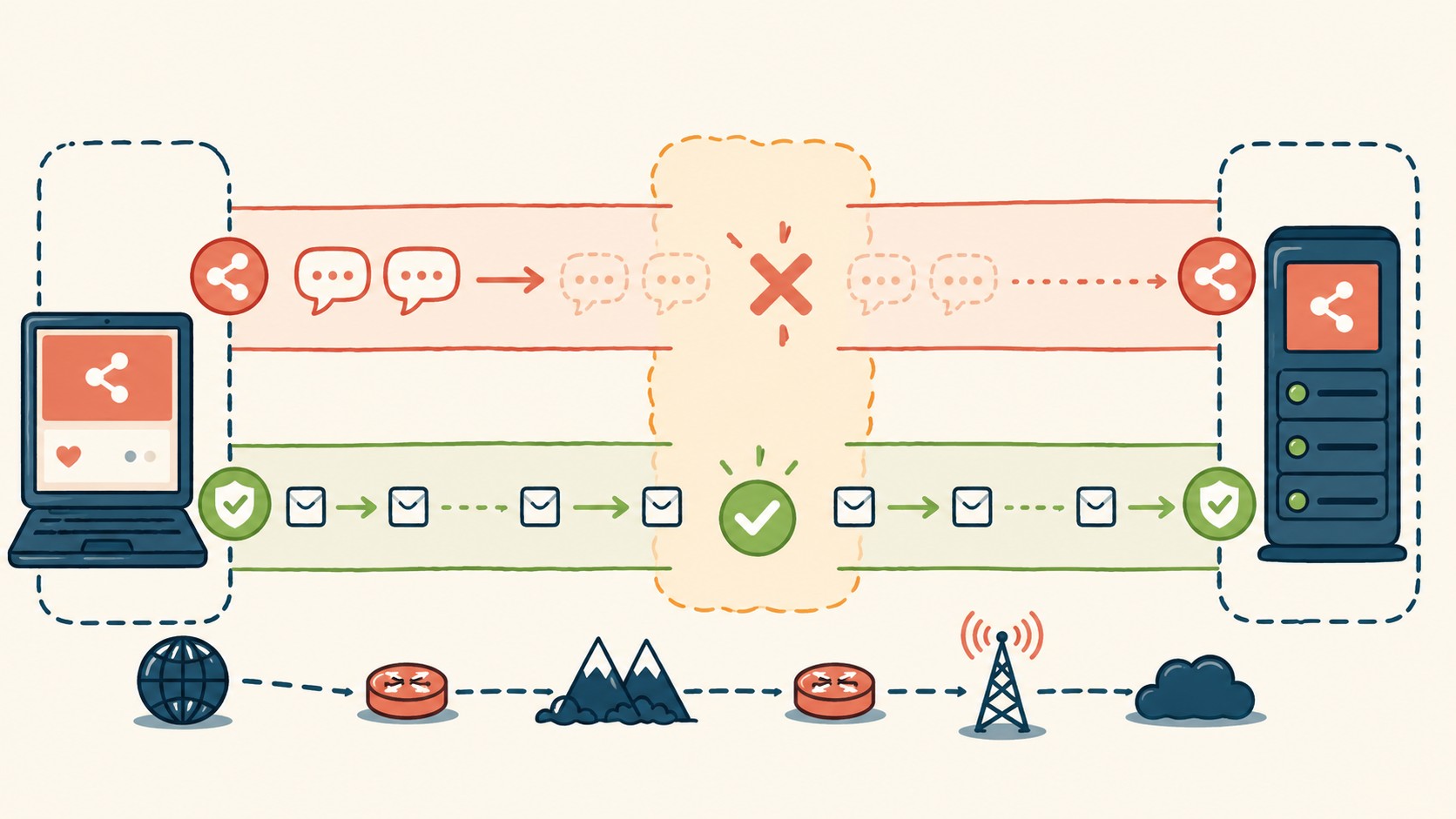
Monitoreo y alertas para conexiones muertas
Detectar el problema en producción requiere métricas que la mayoría no configura.
La métrica clave no es “cuántas conexiones WebSocket activas hay” sino “cuántos datos recibí en los últimos 60 segundos por conexión”. Esa diferencia es lo que hubiera alertado en el caso del crypto signal en menos de 2 minutos en vez de 22 horas.
Con Prometheus podés exportar un gauge de “último mensaje recibido (timestamp)” por conexión. Grafana alertaría si ese timestamp tiene más de N segundos de antigüedad mientras el estado TCP dice “conectado”. También es útil un contador de reconexiones: un pico de reconexiones en un período corto suele indicar que algo upstream está matando las conexiones (un deploy, un cambio de configuración en el proxy, una ventana de mantenimiento).
Logs centralizados ayudan a correlacionar: si ves “conexión cerrada por timeout de heartbeat” repetido cada 45 segundos, el problema es aguas arriba. Si lo ves una sola vez y luego silencio, el problema es local.
Errores comunes al implementar heartbeat
Intervalo demasiado largo
Usar 5 o 10 minutos de intervalo porque “no quiero consumo de ancho de banda”. Con proxies con timeout de 60 segundos, eso es garantía de desconexiones silenciosas frecuentes. 30-45 segundos es el rango correcto, y el overhead de datos es mínimo (un mensaje JSON de unos 20 bytes cada 30 segundos es nada).
No implementar reconexión automática
Detectar la desconexión sin reconectar automáticamente es la mitad del trabajo. Si tu proceso simplemente loguea “conexión perdida” y sigue vivo sin datos, el problema funcional es el mismo. La reconexión tiene que ser parte del diseño, con backoff para no saturar el servidor. Ya lo cubrimos antes en cómo proteger tus conexiones remotas.
Confundir ping de red con heartbeat de aplicación
Un ping ICMP al servidor confirma que el host responde. No confirma que el proceso WebSocket en ese host esté funcionando, ni que la suscripción específica de tu cliente esté activa. Son capas distintas. Si el proceso del servidor crasheó pero el OS sigue vivo, el ping responde pero el WebSocket está muerto.
No probar con proxies en el entorno de desarrollo
En local, la conexión va directo sin intermediarios. Todo funciona. En producción, hay un load balancer con timeout de 60 segundos. El heartbeat tiene que testearse con Nginx o HAProxy en el medio, no solo con el servidor directamente. Sin ese test, estás volando a ciegas.
Preguntas Frecuentes
¿Cómo sé si mi WebSocket realmente está conectado y recibiendo datos?
El estado OPEN del WebSocket solo confirma que el socket TCP subyacente está activo. Para saber si estás recibiendo datos, guardá el timestamp del último mensaje recibido y comparalo con el tiempo actual. Si pasaron más de 60-90 segundos sin mensajes en un feed que normalmente es activo, la conexión probablemente está muerta aunque diga “conectado”.
¿Cuál es la diferencia entre TCP keepalive y WebSocket heartbeat?
TCP keepalive opera a nivel de red y verifica que la ruta entre los dos hosts esté activa, con intervalos de 2 horas por defecto. El WebSocket heartbeat opera a nivel de aplicación y verifica que el proceso remoto esté respondiendo, con intervalos de 30-45 segundos. Solo el heartbeat detecta el caso donde la conexión de red está viva pero la aplicación dejó de funcionar.
¿Cada cuántos segundos debo enviar ping en WebSocket?
El intervalo recomendado según oneuptime.com es 30-45 segundos. Ese rango está calibrado para ser el 75% del timeout típico de proxies y load balancers (60 segundos), lo que garantiza tráfico antes de que el intermediario cierre la conexión. El timeout para considerar el pong perdido debería ser 10-15 segundos adicionales.
¿Cómo implementar detección de conexión muerta en un browser?
En el browser no podés usar los frames ping/pong de RFC 6455 porque la API de WebSocket no los expone. Usá heartbeat a nivel aplicativo: mandá un mensaje JSON de tipo “ping” desde el cliente cada 30 segundos y esperá un mensaje “pong” del servidor. Si no llega en 15 segundos, cerrá el socket y reconectá. Para apps web, sumá el evento visibilitychange para pausar pings cuando la pestaña no está activa.
¿Por qué los proxies cierran conexiones WebSocket inactivas?
La mayoría de los proxies y load balancers tienen un timeout de inactividad para liberar recursos. Nginx cierra conexiones sin tráfico de aplicación en 60 segundos por defecto, y AWS ALB tiene el mismo timeout. Eso no significa que el socket TCP se cierre inmediatamente (TCP keepalive puede mantenerlo vivo), pero sí que el proxy puede cortar la suscripción de aplicación sin notificar al cliente.
Conclusión
El caso de la API cripto con 22 horas de datos perdidos es un accidente fácil de reproducir. El problema de fondo es que WebSocket, como protocolo, heredó la semántica de TCP: “conectado” significa que el canal existe, no que fluye información. Esa distinción importa mucho en sistemas donde la ausencia de datos no genera un error visible.
La solución está clara y no es costosa: heartbeat a nivel aplicativo cada 30-45 segundos, reconexión automática con backoff, y métricas que distingan “estado TCP activo” de “datos recibidos recientemente”. Sin esas tres cosas juntas, el dashboard puede estar verde y el sistema, roto.
Si tu app consume feeds de larga duración (precios, telemetría IoT, streams de logs), revisá si tenés implementado algún heartbeat. Si la respuesta es “no, confío en TCP keepalive”, tenés un problema esperando a materializarse.
Fuentes
- dev.to/mixa_dev — Your WebSocket says “connected” but stopped sending data (2026)
- websockets.readthedocs.io — Keepalive en la librería Python websockets
- websocket.org — Guía de implementación de heartbeat
- oneuptime.com — WebSocket heartbeat: intervalos y mejores prácticas (2026)
- appmaster.io — Problemas comunes de WebSocket y sus soluciones