StatefulSets vs Deployments: el mito de la pérdida de datos
Si pensás que los Deployments en Kubernetes pierden los datos cuando se reinicia un pod, estás equivocado. El debate de StatefulSets vs Deployments en persistencia de datos arranca con un experimento simple: creás una base MySQL en un Deployment con un Persistent Volume Claim, insertás un registro, borrás el pod y los datos siguen ahí. El PVC tiene su propio ciclo de vida, independiente del pod, y por eso el dato sobrevive.
En 30 segundos
- Los Deployments NO pierden datos por sí solos: si tienen un PVC, la información persiste aunque borres el pod.
- El PVC tiene ciclo de vida propio. Borrás el pod, Kubernetes lo recrea y vuelve a montar el mismo volumen.
- La diferencia real entre StatefulSets y Deployments es identidad estable, almacenamiento dedicado por pod y orden de arranque, no “persistencia mágica”.
- Usá StatefulSets para bases de datos en clúster, Kafka o ZooKeeper, donde cada réplica necesita nombre e identidad fijos.
- Para APIs REST, frontend y apps stateless, un Deployment alcanza y sobra.
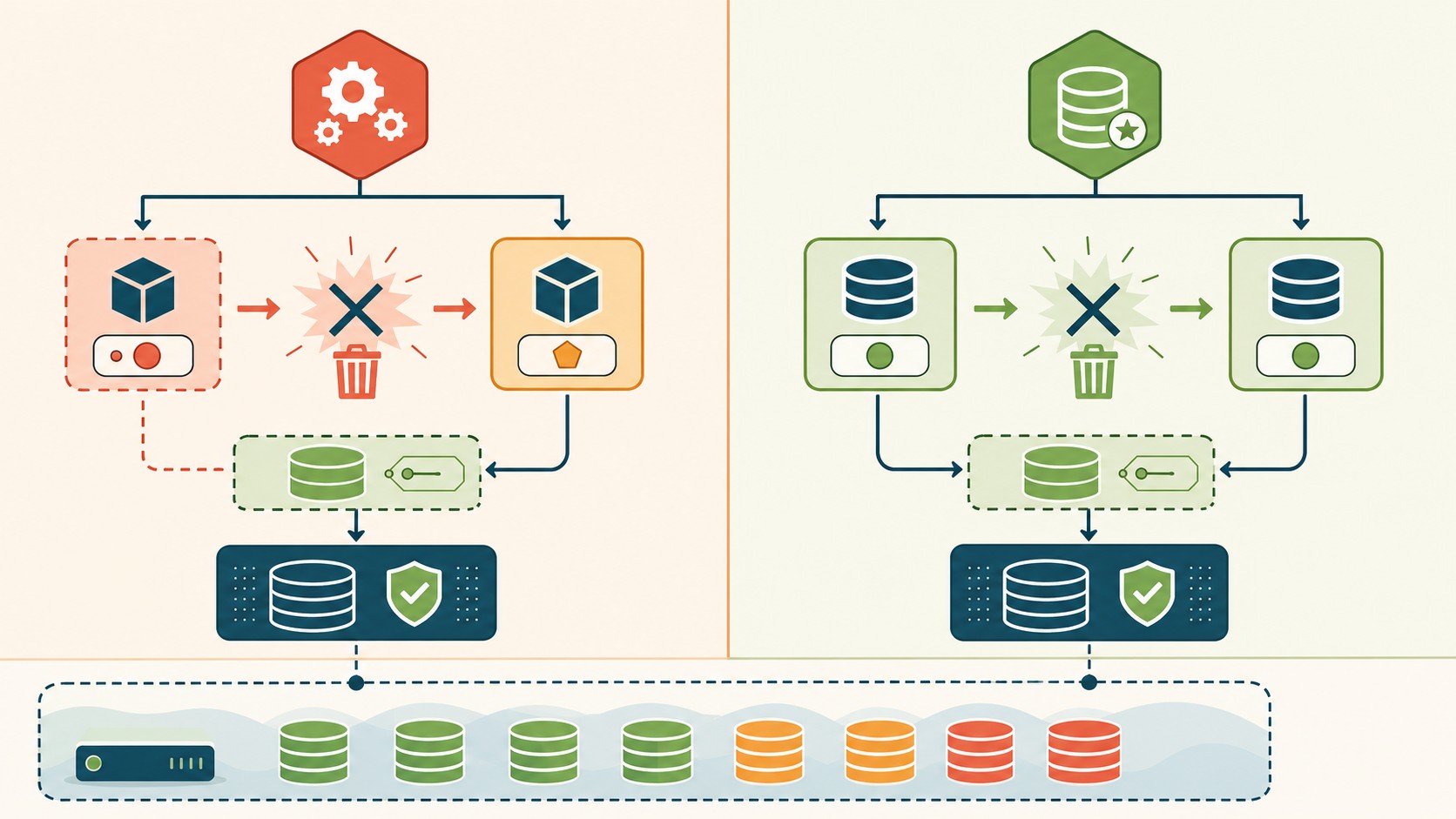
Vamos a aclararlo de entrada. Un StatefulSet es un controlador de Kubernetes que gestiona pods con identidad de red estable, nombres predecibles y un volumen de almacenamiento dedicado por cada réplica. Un Deployment, en cambio, gestiona pods intercambiables y sin identidad fija, pensados para cargas donde un pod es igual a cualquier otro.
El mito de la pérdida de datos en Deployments
La creencia más repetida es que necesitás StatefulSets porque los Deployments “borran todo” al reiniciarse. Falso.
El artículo de la serie publicado el 1 de junio de 2026 lo demuestra con un caso concreto. Lo que persiste no depende del controlador. Depende del volumen. Un Persistent Volume Claim vive por fuera del pod: cuando el pod muere, el PVC sigue existiendo, y el pod nuevo lo vuelve a montar. Por eso el dato aparece intacto.
Entonces, si la persistencia ya la resuelve el PVC, ¿para qué sirve un StatefulSet? Para todo lo demás: identidad, orden y almacenamiento individual. Ahí está la respuesta real, y la vamos a ver paso a paso. Tema relacionado: en tu pipeline de CI/CD.
Experimento práctico: Deployment + PVC
Replicar esto te lleva diez minutos. La idea es montar MySQL en un Deployment con un PVC, meter un registro y después matar el pod a propósito.
Primero aplicás los Secrets y ConfigMaps (ahí van la contraseña, el nombre de la base y el script de inicialización). Después el manifiesto del Deployment, que incluye el PVC:
kubectl apply -f secrets-and-config.ymlkubectl apply -f mysql-deployment.yml
Con el pod corriendo, entrás a MySQL y creás un registro de prueba, ponele un usuario con el mail [email protected]. Salís, y ahora viene la parte divertida:
kubectl delete pod mysql-XXXXXX-XXXX- Kubernetes crea un pod de reemplazo automáticamente.
- Te conectás al pod nuevo y corrés el
SELECT.
¿Y el registro? Ahí está. El pod era nuevo, el dato era el de antes. Eso es lo que confunde a casi todo el mundo: el almacenamiento nunca dependió del pod. Dependía del PVC, que ni se enteró de que borraste algo. Lo explicamos a fondo en como parte de tu orquestación.
Diferencias reales: identidad, almacenamiento y orden
Si los datos sobreviven en ambos casos, la pregunta correcta es qué hace un StatefulSet que un Deployment no puede. Son tres cosas concretas.
| Característica | Deployment | StatefulSet |
|---|---|---|
| Nombre de los pods | Aleatorio (mysql-7d8f-x9k2) | Ordinal y estable (mysql-0, mysql-1) |
| Almacenamiento | Un PVC, compartido entre réplicas | Un PVC dedicado por pod (volumeClaimTemplates) |
| Orden de arranque | Todos en paralelo, sin garantía | Secuencial: 0, después 1, después 2 |
| Identidad de red | Sin DNS estable por pod | DNS fijo por pod vía headless service |
| Caso típico | API, frontend, workers stateless | MySQL, PostgreSQL, Kafka, ZooKeeper |
El tema es que un clúster de base de datos necesita que la réplica primaria sea siempre la misma y que arranque antes que las secundarias. Si los nombres cambian en cada reinicio y todo arranca en desorden, el quórum se rompe. El StatefulSet garantiza ese orden.
Cuándo usar StatefulSets: casos reales
Hay un patrón claro. Cuando cada réplica es distinta de las demás y tiene que mantener su identidad, vas con StatefulSet.
Bases de datos replicadas
MySQL o PostgreSQL en modo primario-réplica. La réplica db-0 es el primario, db-1 y db-2 son secundarios. Cada una con su propio disco. Si db-1 se cae y vuelve, recupera exactamente su volumen, no el de un vecino. Cubrimos ese tema en detalle en mejorá la visibilidad de tu contenido.
Sistemas de mensajería y coordinación
Kafka asigna particiones por broker, y cada broker necesita identidad estable para que los consumidores sepan a quién hablarle. ZooKeeper arma quórum entre nodos con nombre fijo. Sin identidad estable, estos sistemas no pueden coordinar. Por eso acá un Deployment directamente no sirve.
Cuándo usar Deployments (que es casi siempre)
APIs REST. Frontend. Workers que procesan colas. Microservicios stateless.
En todos esos casos un pod es reemplazable por cualquier otro, no hace falta nombre fijo ni orden de arranque, y el Deployment es más simple de operar, escala más fácil y se actualiza sin dramas. Si necesitás guardar algo (cachés, uploads temporales, archivos compartidos), le agregás un PVC al Deployment y listo. Eso sí: si ese almacenamiento tiene que ser único por réplica, ahí ya estás pidiendo un StatefulSet sin saberlo.
Almacenamiento en StatefulSets: volumeClaimTemplates
La diferencia técnica más importante está acá. Un StatefulSet no usa un PVC fijo: usa una plantilla llamada volumeClaimTemplates. Kubernetes crea un PVC por cada réplica, con nombre derivado del pod (data-mysql-0, data-mysql-1).
Un detalle que salva datos: cuando borrás un StatefulSet, los PVC NO se eliminan. Quedan ahí, esperando. Es una protección deliberada contra el borrado accidental. Sobre los modos de acceso, lo habitual es ReadWriteOnce (un solo nodo escribe, ideal para bases de datos) y ReadWriteMany cuando varios pods necesitan el mismo volumen a la vez. Si corrés esto en infraestructura propia o en un VPS con Kubernetes administrado, conviene revisar qué tipo de almacenamiento ofrece tu proveedor; en donweb.com tenés opciones de cloud y servidores para montar este tipo de cargas.
Seguridad de datos: reclaim policies
El que decide qué pasa con el disco físico cuando borrás el PVC es la Reclaim Policy del Persistent Volume. Hay tres: Sobre eso hablamos en para agentes que necesitan estado.
- Retain: el volumen queda intacto y lo recuperás a mano. La opción segura para datos críticos.
- Delete: borra el volumen y los datos al borrar el PVC. Cómodo, peligroso.
- Recycle: deprecada hace tiempo, no la uses.
La regla práctica: en producción, las bases de datos van con Retain. Un borrado accidental con Delete no tiene vuelta atrás.
Errores comunes
- Usar StatefulSet “por las dudas” para una API stateless. Sumás complejidad operativa sin ningún beneficio. Si no necesitás identidad ni orden, es un Deployment.
- Compartir un mismo PVC entre varias réplicas de una base de datos. Dos instancias MySQL escribiendo el mismo archivo corrompen los datos. Cada réplica necesita su volumen propio: eso es
volumeClaimTemplates. - Dejar la Reclaim Policy en
Deleteen producción. Unkubectl deletemal apuntado se lleva la base entera. ConfiguráRetainantes, no después del incidente. - Creer que borrar el StatefulSet borra los PVC. No los borra, y está bien que sea así. Pero si no lo sabés, vas a tener PVC huérfanos acumulándose y gastando almacenamiento.
Preguntas Frecuentes
¿Realmente los Deployments pierden datos en Kubernetes?
No. Un Deployment con un Persistent Volume Claim mantiene los datos aunque borres y recrees el pod. El PVC tiene ciclo de vida independiente del pod, así que el dato persiste mientras exista el PVC.
¿Cuál es la diferencia real entre StatefulSets y Deployments?
El StatefulSet da identidad estable a cada pod (nombres ordinales como mysql-0), un PVC dedicado por réplica y orden de arranque secuencial. El Deployment trata a los pods como intercambiables, sin identidad fija ni orden garantizado.
¿Cuándo debo usar StatefulSets en vez de Deployments?
Usá StatefulSets cuando cada réplica necesita identidad propia: bases de datos replicadas, Kafka, RabbitMQ o ZooKeeper. Para APIs REST, frontend y aplicaciones stateless, el Deployment es la opción correcta y más simple.
¿Un Deployment con PVC puede mantener datos persistentes?
Sí. Si le asociás un PVC, el Deployment conserva los datos entre reinicios de pod. La limitación es que ese PVC se comparte entre réplicas, así que no sirve para bases de datos que necesitan almacenamiento individual por instancia.
¿Por qué necesito StatefulSets si ya tengo PVC?
Porque el PVC resuelve la persistencia, pero no la identidad ni el orden. Un clúster de base de datos necesita que cada réplica tenga nombre fijo, su propio volumen y arranque en secuencia, y eso solo lo garantiza el StatefulSet con volumeClaimTemplates.
Conclusión
La frase “uso StatefulSet porque si no pierdo los datos” es un mito que se cae con un experimento de diez minutos. Los datos los protege el PVC, no el controlador.
Lo que define la decisión es otra cosa: ¿tus réplicas son intercambiables o cada una tiene que ser ella misma? Si son intercambiables, Deployment. Si cada una necesita nombre, disco propio y orden, StatefulSet. Antes de mover una base de datos a producción, configurá la Reclaim Policy en Retain y probá borrar un pod a propósito. Mejor descubrir cómo se comporta tu almacenamiento en una prueba que en un incidente real.