Base de datos caída en Kubernetes: klink lo resuelve en 30s
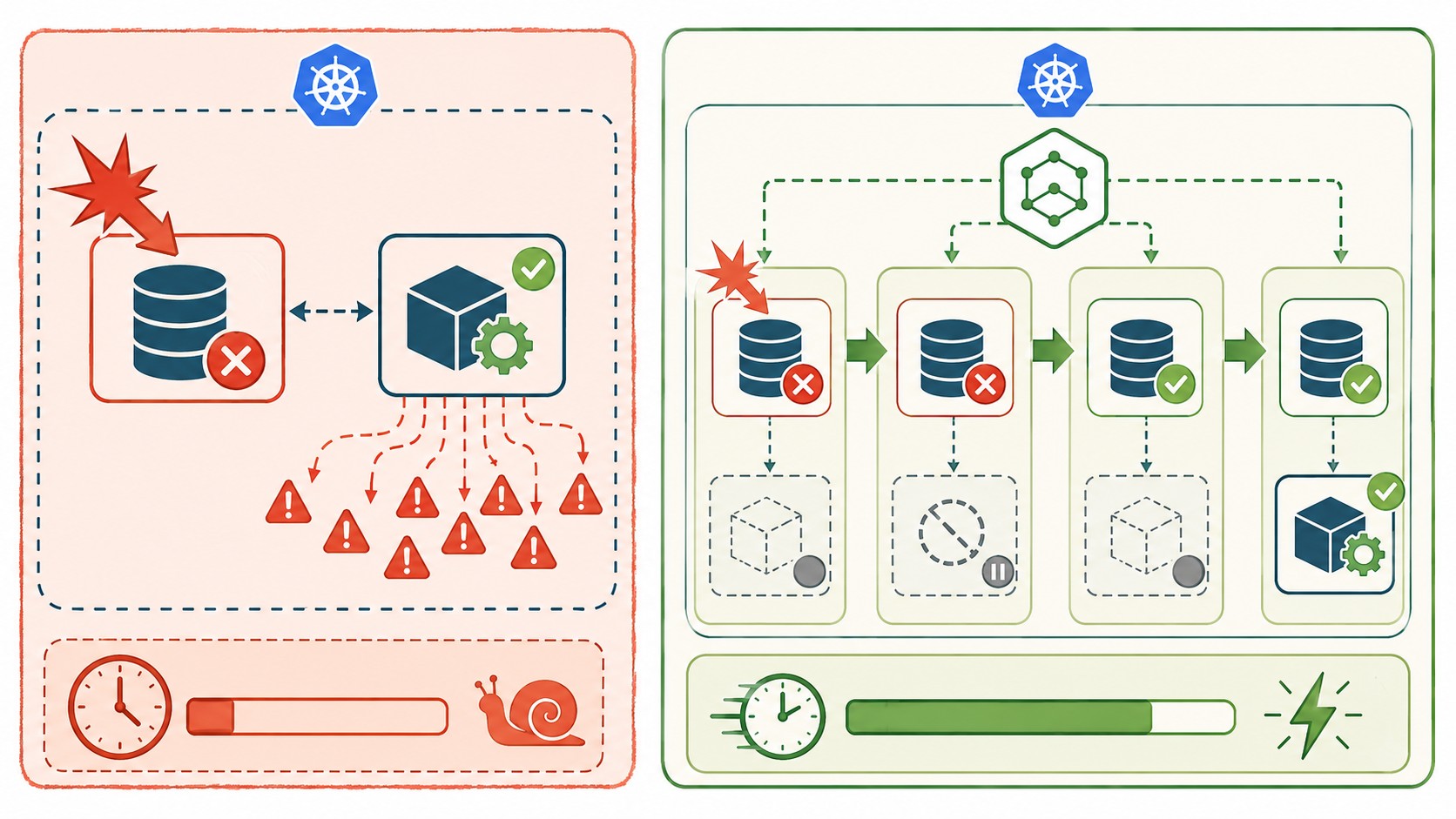
Son las 3 AM. Tu pod de PostgreSQL se va a pique. La alerta de on-call dispara. El ingeniero se despierta, abre el dashboard, y pasa 20 minutos revisando métricas hasta que cae en la cuenta: la base de datos está caída en Kubernetes, pero el servicio de payments sigue corriendo como si nada, martillando los connection pools, escupiendo miles de errores 500 por segundo y generando alertas en cascada que no dejan ver el problema real. Escala payments a cero manualmente. Ahí recién empieza la recuperación. Esos 20 minutos eran evitables.
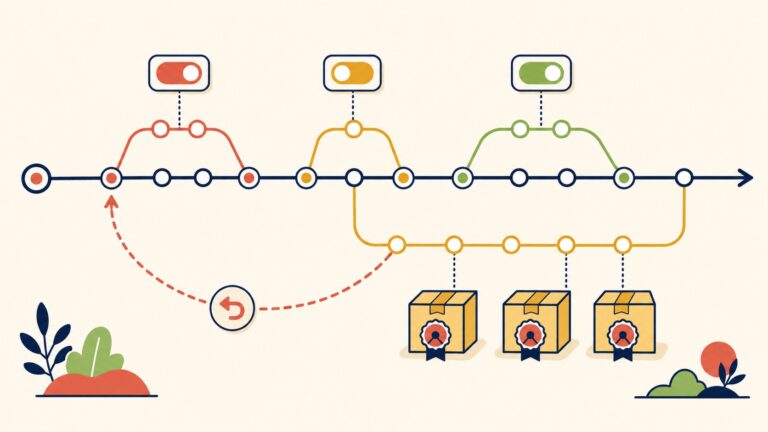
klink introduce un nuevo recurso, Dependency (deps.klink.dev/v1alpha1), para declarar que un servicio B depende de un servicio A. Cuando A deja de estar healthy, klink escala B a cero automáticamente en segundos; cuando A se recupera, restaura B sin intervención manual. No requiere cambios de código, sidecars ni configuraciones complejas. El proyecto fue presentado por el desarrollador conocido como n0rm4l en un artículo publicado en dev.to y apunta directo a un hueco que Kubernetes nunca cubrió: las relaciones entre workloads.
En segundos
- klink escala servicios dependientes a cero cuando la base de datos (o cualquier servicio del que dependan) deja de estar healthy, y los restaura automáticamente al recuperarse.
- Automatización declarativa: reacciona en segundos ante caídas de dependencias, evitando largos debugging manuales.
- Configuración mínima sin tocar código: un recurso YAML de tipo
Dependencydefine qué servicio depende de cuál, con políticas de threshold, estabilización y cooldown. - No reemplaza circuit breakers ni health checks: los complementa atacando el problema desde la orquestación, no desde la lógica de aplicación.
¿Por qué Kubernetes no detiene los servicios cuando la base de datos se cae?
Kubernetes es excelente manteniendo pods individuales vivos. Liveness probes, restart policies, resource limits: todo eso funciona bárbaro. El problema es que Kubernetes no tiene idea de las relaciones entre workloads. Un deployment de payments y un StatefulSet de PostgreSQL son, para el scheduler, dos cosas que casualmente comparten clúster. Nada más.
Cuando la base de datos falla, Kubernetes hace exactamente lo que le pediste: mantiene los servicios dependientes corriendo. Esos servicios no hacen nada útil — generan ruido, consumen recursos, saturan los connection pools y convierten un incidente manejable en un despelote multialerta donde cuesta encontrar la causa raíz. (Cualquiera que haya estado de guardia un fin de semana sabe de qué hablo.) Sobre eso hablamos en nuestra comparativa de herramientas CI/CD.
El punto es que Kubernetes no “piensa” en dependencias. No es un bug: es una decisión de diseño. La orquestación de pods es genérica a propósito. Pero eso deja un agujero enorme que durante años tapamos con guardias humanas, dashboards y, si tenías suerte, algún circuit breaker en el código que al menos frenaba las consultas antes de que revienten todo.
¿Cómo funciona klink cuando hay una base de datos caída en Kubernetes?
klink introduce un recurso nuevo: Dependency. Vos declarás que el servicio B depende del servicio A — por ejemplo, payments depende de database — y klink se queda mirando. Cuando A se va a unhealthy, klink escala B a cero. Cuando A se recupera, klink restaura B a su estado anterior. Todo automático.
Así de simple. Subís el YAML, aplicás kubectl, y te olvidaste. No hay sidecars inyectados, no hay que tocar el código de los servicios, no hay que configurar Istio ni Envoy ni nada que pese más que el operador mismo (spoiler: pesa poco). La lógica es declarativa: decís qué depende de qué, y el operador ejecuta.
Lo interesante es que las políticas de escalado van más allá de un simple “está caído/apagá todo”. klink usa tres parámetros clave: threshold (porcentaje de pods ready, por defecto 80%), stabilization (ignorar reinicios transitorios que no indican una falla real) y cooldown (esperar a que el servicio A esté estable antes de restaurar B, para no generar un efecto rebote de apagado/encendido constante). En el debate entre Jenkins y GitHub Actions profundizamos sobre esto.
Configuración de dependencias con klink: el YAML que necesitás
El manifiesto es ridículamente corto. Creás un recurso Dependency en tu namespace y especificás origen, destino y política de escalado. Así se ve:
- from: el servicio dependiente (el que se va a escalar a cero).
- to: el servicio del que depende (el que, si se cae, dispara la acción).
- scalingPolicy: tres campos —
threshold(80% de pods ready para considerar healthy),stabilization(ignora flaps transitorios),cooldown(espera antes de restaurar).
El ejemplo del artículo original es un recurso que se llama payments-needs-database-policy. Define que payments depende de database, que el threshold es 80%, y configura estabilización y cooldown para evitar falsos positivos. No necesitás un solo cambio en los deployments existentes.
¿Y si tenés un servicio que depende de tres bases de datos? Creás tres recursos Dependency. ¿Y si querés que el threshold sea más estricto para ciertos servicios críticos? Lo ajustás por recurso, sin afectar a los demás. La granularidad está ahí, sin volverse un infierno de configuración.
Beneficios concretos de escalar a cero automáticamente
Volvamos al incidente de las 3 AM. La base de datos se cae, los connection pools empiezan a saturarse, payments genera errores 500 al 100% y las alertas se multiplican porque cada servicio downstream también empieza a fallar. El ingeniero de guardia se despierta, abre la laptop, intenta entender qué pasó entre el diluvio de alertas, y recién después de 20 minutos escala payments a cero. Ahí empieza la recuperación posta. Ya lo cubrimos antes en la guía completa de hreflang.
Con klink, payments se va a cero automáticamente después de que la base de datos se declara unhealthy. Sin intervención humana, sin alertas en cascada, sin connection pools martillados al pedo. Cuando la base de datos vuelve, klink restaura payments solo, respetando el cooldown para asegurarse de que el recovery es genuino y no un falso positivo que dure dos segundos.
Los beneficios no son solo tiempo de resolución (que ya es un montón). Es también reducción de ruido: menos alertas falsas, menos páginas de on-call a las 3 AM por síntomas y no por causas. Es menor consumo de recursos en medio de un incidente. Y es, sobre todo, debugging más rápido: si lo único que falla es la base de datos, no tenés 15 servicios saturando logs y métricas con errores que no aportan nada.
Alternativas a klink para gestionar dependencias en Kubernetes
klink no inventa la rueda. El problema de las dependencias entre servicios existe desde que existe la arquitectura distribuida, y hay varias formas de atacarlo. La pregunta es dónde ponés la lógica.
| Enfoque | Dónde vive | Requiere cambios de código | Maneja escalado a cero | Complejidad |
|---|---|---|---|---|
| klink | Operador Kubernetes (nivel orquestación) | No | Sí, automático | Baja |
| Circuit breaker en código | Lógica de aplicación | Sí | No (protege llamadas, no escala) | Media |
| Envoy / Istio circuit breaking | Sidecar proxy | No (configuración de malla) | No | Alta |
| Keda (escalado por eventos) | Operador Kubernetes | No | Parcial (escala por métricas, no por dependencias) | Media |
| Escalado manual | Humano + kubectl | No | Sí, con 20 minutos de delay | Cero código, alto costo operativo |
Los circuit breakers en el código son excelentes para evitar que tu aplicación se quede colgada esperando una respuesta que nunca va a llegar. Pero no escalan pods a cero: siguen consumiendo CPU, memoria y, si el circuit está abierto, reintentan cada tanto para ver si la BD volvió. Envoy e Istio llevan esto al plano de la malla de servicios, pero configurar circuit breaking a ese nivel, con reglas por ruta y por upstream, es un viaje (y sumás sidecars a cada pod). Esto se conecta con lo que analizamos en cómo ejecutar agentes locales sin API.
Keda escala workloads por eventos externos — métricas de Prometheus, colas de mensajes, lo que sea — y podrías usarlo para detectar que la BD no responde y escalar a cero. Pero no es su propósito nativo y requiere armar las reglas a mano. klink va directo al hueso: “este servicio depende de este otro, si se cae, apagalo”. Sin adaptadores, sin métricas custom, sin malabares.
Errores comunes al manejar dependencias entre servicios en Kubernetes
- Asumir que las liveness probes alcanzan. Una liveness probe te dice si tu pod está vivo, no si su base de datos responde. Si tu app crashea porque la BD no está, la probe la reinicia, y el ciclo sigue infinitamente mientras los connection pools se saturan. klink corta ese loop desde la orquestación.
- Poner circuit breakers y olvidarse del escalado. El circuit breaker frena las consultas, pero el pod sigue corriendo, ocupando recursos y generando logs de error. Para incidentes largos, escalar a cero es más limpio y ahorra plata (sí, en cloud cada minuto de CPU ociosa se factura).
- No probar el camino de recuperación. Muchos equipos configuran failover y se olvidan de probar qué pasa cuando el servicio vuelve. Si restaurás todo a mano, podés olvidarte de un deployment o volver con configuraciones inconsistentes. La automatización de klink en la restauración ahorra ese riesgo.
Preguntas Frecuentes
¿Qué es klink y quién lo creó?
klink es un operador de Kubernetes que escala servicios dependientes a cero cuando el servicio del que dependen falla y los restaura cuando se recupera. Lo presentó el desarrollador conocido como n0rm4l en un artículo publicado en dev.to. Introduce el recurso Dependency (deps.klink.dev/v1alpha1) para declarar relaciones entre workloads.
¿Cómo se instala klink en un clúster existente?
Se instala como cualquier operador de Kubernetes: desplegás el controlador en su namespace, aplicás los CRDs que definen el recurso Dependency, y empezás a crear manifiestos de dependencia. No interfiere con otros controladores ni requiere reconfigurar la malla de servicios. Si ya tenés experiencia desplegando operadores, es un trámite de minutos.
¿Qué pasa cuando la base de datos se recupera?
klink monitorea la salud del servicio A. Cuando detecta que está healthy de nuevo y que pasó el período de cooldown (para evitar falsos positivos de recuperación), restaura el servicio B a la cantidad de réplicas que tenía antes del incidente. Todo automático, sin intervención manual.
¿Funciona con cualquier tipo de base de datos?
Sí, klink trabaja a nivel de recursos de Kubernetes, no a nivel de protocolo de base de datos. Mientras el servicio del que dependés tenga pods con health checks que klink pueda monitorear, funciona. PostgreSQL, MySQL, Redis, MongoDB, lo que sea que corra en pods dentro del clúster.
¿Necesito modificar el código de mis servicios para usar klink?
No. klink opera exclusivamente a nivel de orquestación. No inyecta sidecars, no requiere librerías, no pide cambios en la lógica de conexión. El servicio ni se entera de que klink existe: un momento está corriendo, al siguiente fue escalado a cero, y cuando vuelve retoma como si nada.
Conclusión
klink ataca un problema que todos los que operan Kubernetes en producción conocen pero que pocos resolvieron de forma limpia: las dependencias entre servicios no existen para el scheduler. La solución declarativa con el recurso Dependency es elegante y mínima — no suma complejidad, no pide cambios de código, y reduce drásticamente el tiempo de resolución de incidentes donde la base de datos es el punto de falla.
Ojo, no es magia. Si tu aplicación no tolera ser escalada a cero (porque necesita mantener estado en memoria, porque tiene conexiones persistentes que no renegocia bien al volver), vas a tener que combinar klink con otras estrategias. Pero para la mayoría de los microservicios stateless que hablan con una BD, es un golazo.
Si estás corriendo servicios en Kubernetes — ya sea en cloud propia, en un proveedor gestionado, o sobre infraestructura más tradicional con hosting administrado para entornos que no justifican un clúster completo — vale la pena probar klink en staging y ver cómo reacciona tu stack. Los minutos que te ahorra a las 3 AM no tienen precio.
Fuentes
- Your Database Just Died. Why Is Everything Still Running? — Artículo original de n0rm4l en dev.to
- Agente IA borró base de datos en producción: logs y guardrails — Juanchi.dev
- Notion desactivó Claude tras apagón de Anthropic (junio 2026) — WWWhatsNew
- Scaling PostgreSQL — OpenAI