Detectar anomalías API detrás de un 200 OK con estadística
Para detectar anomalías API detrás de un 200 OK no alcanza con preguntar “¿está arriba?”. Hay que comparar cada respuesta contra su propia historia: tamaño del payload, latencia y estructura del JSON. Con una media móvil y la regla de 3 desvíos estándar, se marca cualquier valor raro. Sin IA, sin caja negra.
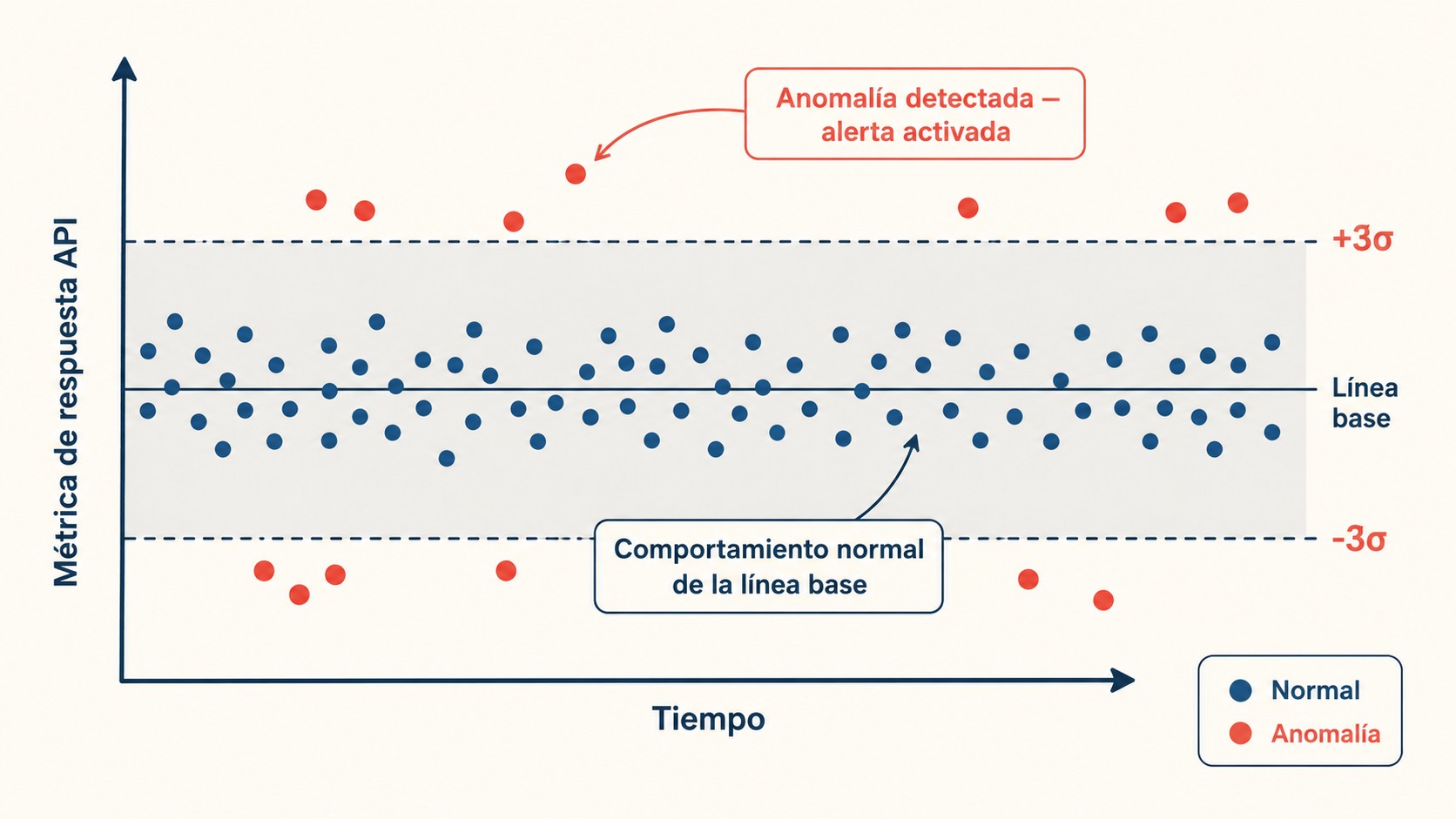
La detección de anomalías API por estadística es una técnica de monitoreo que establece una línea base por cada endpoint (media móvil y desviación estándar) y dispara una alerta cuando una métrica se aleja más de tres sigmas del promedio histórico. Mide señales como bytes de respuesta y tiempo de respuesta, es determinística y explicable, y no requiere datos de entrenamiento ni modelos de machine learning.
En 30 segundos
- El problema: un endpoint puede devolver 200 OK y aún así servir una página de error cacheada, un JSON con
{"error": ...}o un payload que cayó de 14 KB a 800 bytes. - La solución del dev Dario Le (dev.to, 15/06/2026): una línea base por endpoint usando media móvil, desvío estándar y la regla |valor − media| > 3·σ.
- Por qué no IA: la estadística es más barata, determinística y explicable. El ML necesita datos de entrenamiento y es opaco.
- Qué medir: tamaño en bytes y latencia, como mínimo. Sumá validación de esquema JSON para detectar campos faltantes.
- Herramientas listas: Apigee Anomaly Detection, Azure Anomaly Detector y Datadog ya traen métodos estadísticos nativos.
¿Por qué una API devuelve 200 OK aunque algo esté fallando?
Ponele que tu monitor de uptime te dice que todo está verde. Y sin embargo los usuarios se quejan de que la app devuelve datos vacíos. ¿Cómo puede ser? Exacto: el código HTTP y el éxito funcional son dos cosas distintas. Esto se conecta con lo que analizamos en tus pipelines de integración continua.
El status 200 dice “la petición llegó y el servidor respondió”. No dice “la respuesta es correcta”. Según el artículo de Dario Le en dev.to, los peores incidentes que le tocó resolver devolvían un 200 perfectamente feliz: un endpoint sirviendo una página de error cacheada, una API JSON devolviendo {"error": ...} con status 200, una respuesta que en silencio se volvió 10 veces más lenta, y un payload que pasó de 14 KB a 800 bytes porque el backend empezó a devolver resultados vacíos.
No es un caso de borde raro. La documentación de Singular avisa explícito que su API server-to-server siempre responde 200, así que tenés que validar el campo status dentro del cuerpo. El soporte de Zendesk también documenta casos donde la REST API devuelve 200 pero la operación no se ejecutó. Un chequeo de arriba/abajo pasa de largo por todos estos.
¿Qué diferencia hay entre monitoreo de uptime y detección de anomalías?
El monitor de uptime clásico responde una sola pregunta: ¿el endpoint contesta? Si te devuelve cualquier 2xx, te pone el tilde verde y sigue.
La detección de anomalías mira el comportamiento. No pregunta “¿está arriba?”, pregunta “¿esta respuesta es rara para este endpoint?”. Es la diferencia entre un sensor de encendido y uno que te avisa cuando el motor hace un ruido distinto al de siempre. El primero te deja tranquilo mientras el auto se rompe.
¿Cómo funciona la estadística para detectar anomalías API?
La idea es vieja y aburrida, que es justo lo que la hace confiable. Por cada métrica guardás una media móvil y una desviación estándar. Después aplicás la regla de las tres sigmas: Ya lo cubrimos antes en usando tus herramientas de automatización.
- La fórmula es directa: marcás un valor cuando
|valor − media| > 3·σ. Si se aleja más de tres desvíos del promedio histórico, algo cambió. - El cálculo es barato: se mantiene una media móvil sin cargar todo el historial en memoria, con costo O(1) por request.
- Es explicable: cuando salta la alerta, sabés exactamente por qué (el valor X se alejó N desvíos). Nada de “el modelo lo decidió”.
La tentación de turno es ponerle “detección de anomalías con IA” y cobrar más caro. Pero para métricas por endpoint, el ML es medio sobredimensionado: necesitás datos de entrenamiento, el modelo es opaco y cuesta explicar por qué disparó. La estadística pura es más simple, más barata y determinística. La “inteligencia” acá no aporta nada que la matemática de secundario no resuelva.
¿Por qué cada endpoint necesita su propia línea base?
Acá viene la decisión clave del diseño de Dario: cada endpoint es su propia línea base. Una respuesta JSON de 2 KB cacheada en CDN y una página HTML de 500 KB no tienen nada en común. Un umbral global para los dos no significa nada.
Por eso se siguen dos señales por endpoint, cada una con su baseline rodante: el tamaño de respuesta en bytes y la latencia. Para cada una, la pregunta es siempre la misma. ¿El último valor es raro para este endpoint en particular? Un payload de 800 bytes puede ser normal en un endpoint de health check y una señal de alarma en uno que siempre devuelve 14 KB. Complementá la validación sin depender de APIs externas.
¿Cómo validar payloads JSON sin usar IA?
El tamaño y la latencia te avisan de mucho, pero no de todo. Una API puede devolver {"results": []} cuando debería devolver objetos con diez campos, y pesar parecido. Ahí entra la validación de esquema.
- Validá campos obligatorios: si el contrato dice que cada item tiene
id,nombreyprecio, una respuesta sin alguno de ellos es una anomalía aunque devuelva 200. - Validá tipos de dato: un
precioque viene como string en vez de número rompe a quien consume la API río abajo. - Usá JSON Schema: con librerías como
ajv(JavaScript) ojsonschema(Python) declarás el esquema una vez y validás cada respuesta contra él. La guía de Apidog sobre validación de datos cubre el flujo paso a paso.
¿Qué herramientas detectan anomalías API sin machine learning?
Si no querés construirlo a mano, hay opciones que ya traen métodos estadísticos. Apigee de Google Cloud tiene detección de anomalías nativa sobre tráfico y latencia. La elección depende de cuánto quieras armar vos y cuánto presupuesto tengas.
| Herramienta | Método | Mejor para |
|---|---|---|
| DIY (statsmodels / scipy.stats) | Media móvil + 3σ propias | Control total y costo cero de licencia |
| Apigee Anomaly Detection | Estadístico sobre tráfico/latencia | Quien ya usa Google Cloud Apigee |
| Azure Anomaly Detector | Series temporales | Stacks sobre Azure |
| Datadog | Algoritmos estadísticos configurables | Equipos con observabilidad centralizada |
Si el monitor corre como un servicio chico en tu propio servidor o VPS, la versión DIY es la más liviana: un script que guarda la baseline y dispara alertas. Para alojar ese tipo de microservicio en Argentina, donweb.com tiene planes de hosting y VPS donde encaja sin drama.
Errores comunes al monitorear APIs
- Confiar solo en el status code. Es el error madre. Validá siempre el cuerpo: un 200 con
{"error": ...}adentro es un fallo disfrazado. - Usar un umbral global para todos los endpoints. Lo que es normal en un health check de 200 bytes es una catástrofe en un endpoint de 14 KB. Una baseline por endpoint o nada.
- Alertar solo por latencia. Una respuesta puede ser rapidísima y estar igual de rota. Si el payload bajó de 14 KB a 800 bytes pero respondió en 50 ms, sigue siendo un problema. Combiná señales.
- Fijar el umbral muy fino. Si ponés 1σ en vez de 3σ, te llenás de falsas alarmas y terminás ignorando todas. Tres desvíos es el punto razonable para arrancar.
Preguntas Frecuentes
¿Cómo detectar errores en una API que devuelve 200 OK?
Validá el contenido de la respuesta, no solo el código HTTP. Revisá el campo de estado interno del JSON, el tamaño del payload en bytes y la latencia, y comparalos contra la línea base histórica de ese endpoint con la regla de tres desvíos estándar.
¿Qué es la regla de las tres sigmas?
Es marcar como anómalo todo valor que cumpla |valor − media| > 3·σ, es decir, que se aleje más de tres desviaciones estándar del promedio histórico. En una distribución normal, eso cubre el 99,7% de los casos esperados, así que lo que cae afuera es estadísticamente raro. Relacionado: desde la perspectiva de seguridad.
¿Hace falta machine learning para detectar anomalías API?
No para métricas por endpoint. La estadística clásica (media móvil y desviación estándar) es más barata, determinística y explicable. El machine learning necesita datos de entrenamiento, es opaco y cuesta justificar por qué disparó una alerta, así que para este caso es sobredimensionado.
¿Cómo validar payloads JSON sin IA?
Con JSON Schema y librerías como ajv en JavaScript o jsonschema en Python. Declarás los campos obligatorios y sus tipos de dato una sola vez, y validás cada respuesta contra ese esquema. Si falta un campo o cambia el tipo, lo detectás aunque la API devuelva 200.
¿Qué señales conviene monitorear en una API?
Como mínimo, tamaño de respuesta en bytes y latencia, cada una con su propia línea base por endpoint. Sumá validación de estructura JSON para campos faltantes o tipos incorrectos. Combinar las tres señales detecta tanto backends caídos como datos vacíos o respuestas malformadas.
Conclusión
El 200 OK te miente seguido, y el monitor de uptime clásico le cree. Lo que cambia con este enfoque es que dejás de preguntar “¿está arriba?” para preguntar “¿esta respuesta es normal para este endpoint?”. Y la respuesta no la da una IA cara y opaca, la da una media móvil y la regla de tres sigmas, que entendés y podés depurar.
Si gestionás APIs, el próximo paso concreto es elegir dos señales (bytes y latencia), guardar una baseline por endpoint y empezar a alertar a 3σ. Sumá validación de esquema JSON para los campos. Con eso ya detectás la mayoría de los fallos que hoy te pasan de largo, sin pagar por la “inteligencia” de nadie.
Fuentes
- Detecting API anomalies behind a 200 OK — with statistics, not AI (dev.to, Dario Le, 15/06/2026)
- Google Cloud Apigee – About anomaly detection (documentación oficial)
- Singular – Server-to-Server API Response Codes & Errors
- Zendesk – REST API gives 200 response but the request didn’t work
- Apidog – Cómo validar datos de respuesta de API
![[Workflow Included] LinkedIn Posting using n8n through HTTP node - ilustracion](https://donweb.news/wp-content/uploads/2026/04/automatizar-publicaciones-linkedin-n8n-hero-768x429.jpg)