IDs de correlación en APIs: rastreá cada request
Un ID de correlación es un valor único que se le pega a una solicitud apenas entra a tu sistema y viaja con ella a cada servicio y cada línea de log. Los IDs de correlación en APIs resuelven un dolor concreto: cuando un usuario reporta que “no le guardó el perfil” y el error está repartido entre cinco servicios, ese ID te deja reconstruir la historia completa filtrando por un solo valor. De horas de grep a ciegas a minutos.
Un ID de correlación (también llamado request ID o, con matices, trace ID) es un identificador único que se genera o se acepta en el borde de tu API y se propaga a todas las llamadas aguas abajo y a todas las líneas de log. Sirve para rastrear una única solicitud a través de servicios distribuidos. Es la pieza base de cualquier estrategia de observabilidad en microservicios.
En 30 segundos
- Qué es: un valor único (UUID) que identifica una solicitud de punta a punta entre todos tus servicios.
- Regla del borde: si llega el header
x-correlation-id, lo reusás; si no, lo generás vos. - Dónde vive: en cada línea de log y en cada llamada HTTP hacia otro servicio.
- Herramientas: de un middleware casero a OpenTelemetry + Jaeger o Zipkin para tracing distribuido completo.
- Resultado: el MTTR (tiempo medio de resolución) baja de horas a minutos.
¿Por qué un log suelto no alcanza en microservicios?
Ponele que un usuario te escribe: “guardé el perfil y me tiró error”. Abrís los logs y encontrás un 500. Bárbaro. ¿En cuál de los cinco servicios?
Esa única request tocó tu API gateway, el servicio de auth, el de perfiles y un proxy de base de datos. Cada uno logueó algo, pero nada conecta esas líneas entre sí. Te quedás filtrando por timestamp y rezando para que nadie más haya hecho una request en el mismo segundo. Y si tu sistema tiene tráfico real, alguien la hizo. Para más detalles técnicos, mirá pipelines de despliegue automatizados.
Ese es el problema de fondo. En un monolito, un stack trace te cuenta toda la historia. En sistemas distribuidos, la historia está partida en pedazos que viven en máquinas distintas, con relojes que ni siquiera están perfectamente sincronizados. Sin un hilo que los una, debuggear se vuelve arqueología.
Paso 1: generar o aceptar el ID en el borde
La regla es simple. Si la request entrante ya trae un header de correlación, reusalo. Si no, generás uno nuevo. Así, los clientes y los servicios de arriba pueden hilvanar sus propios IDs a través de tu stack.
Acá va un middleware de Express que hace exactamente eso, tomado del artículo original de dev.to (junio 2026):
const { AsyncLocalStorage } = require('async_hooks');
const { randomUUID } = require('crypto');
const als = new AsyncLocalStorage();
function correlationId(req, res, next) {
const id = req.headers['x-correlation-id'] || randomUUID();
// Se lo devolvés al cliente para que también lo loguee
res.setHeader('x-correlation-id', id);
// Disponible en cualquier parte de la request, sin pasarlo de mano en mano
als.run({ correlationId: id }, () => next());
}El truco clave es AsyncLocalStorage: te da almacenamiento por request que sobrevive a cada await y llega a cualquier función sin tener que pasar el ID como parámetro por toda la cadena (eso que en inglés llaman prop-drilling, y que ensucia todo).
Paso 2: meter el correlation ID en cada línea de log
Un ID de correlación que no está en los logs no sirve para nada. Cero. La idea es envolver tu logger para que lea el ID del contexto de forma automática: Ya lo cubrimos antes en herramientas de automatización.
function log(level, message, extra = {}) {
const store = als.getStore();
const correlationId = store?.correlationId ?? null;
console.log(JSON.stringify({ level, message, correlationId, ...extra }));
}
// En cualquier lado, sin andar arrastrando el ID:
log('info', 'profile updated', { userId: 42 });
// {"level":"info","message":"profile updated","correlationId":"a1b2...","userId":42}Con eso, un grep por el ID (o un filtro en Loki, Datadog o Kibana) te devuelve todas las líneas de esa request, en orden. La diferencia entre tener el ID y no tenerlo es la diferencia entre leer una conversación y leer palabras sueltas de diez conversaciones mezcladas.
Paso 3: propagar el ID aguas abajo
Acá viene el error que casi todos cometen la primera vez: cada servicio genera su propio ID nuevo. Si hacés eso, rompés la cadena y volvés al punto de partida.
Lo correcto es pasar el mismo ID en los headers de cada llamada saliente:
async function callDownstream(url, body) {
const { correlationId } = als.getStore() ?? {};
return fetch(url, {
method: 'POST',
headers: {
'content-type': 'application/json',
'x-correlation-id': correlationId, // el mismo de siempre
},
body: JSON.stringify(body),
});
}Si usás colas de mensajes (RabbitMQ, Kafka, SQS), el mismo principio aplica: el ID viaja como metadato del mensaje, no en el body. Así la traza sobrevive incluso cuando la comunicación es asincrónica y el productor ya respondió hace rato. Tema relacionado: servicios distribuidos multiidioma.
¿Cuándo conviene saltar a OpenTelemetry, Jaeger o Zipkin?
El middleware casero zafa para arrancar y para sistemas chicos. Pero cuando tenés decenas de servicios y querés ver no solo dónde falló sino cuánto tardó cada salto, ahí necesitás tracing distribuido de verdad.
OpenTelemetry es el estándar abierto de la CNCF para instrumentación: define cómo se generan y propagan trazas, métricas y logs, sin atarte a un proveedor. Después elegís el backend donde visualizar. Jaeger y Zipkin son las dos opciones clásicas.
| Herramienta | Qué es | Cuándo usarla |
|---|---|---|
| OpenTelemetry | Estándar de instrumentación (CNCF), agnóstico de backend | Siempre: es la capa de captura, no compite con las otras dos |
| Jaeger | Backend de tracing, nació en Uber, fuerte en escala | Volúmenes altos, sampling avanzado, equipos grandes |
| Zipkin | Backend de tracing, más viejo, setup liviano | Sistemas chicos a medianos, arranque rápido y simple |
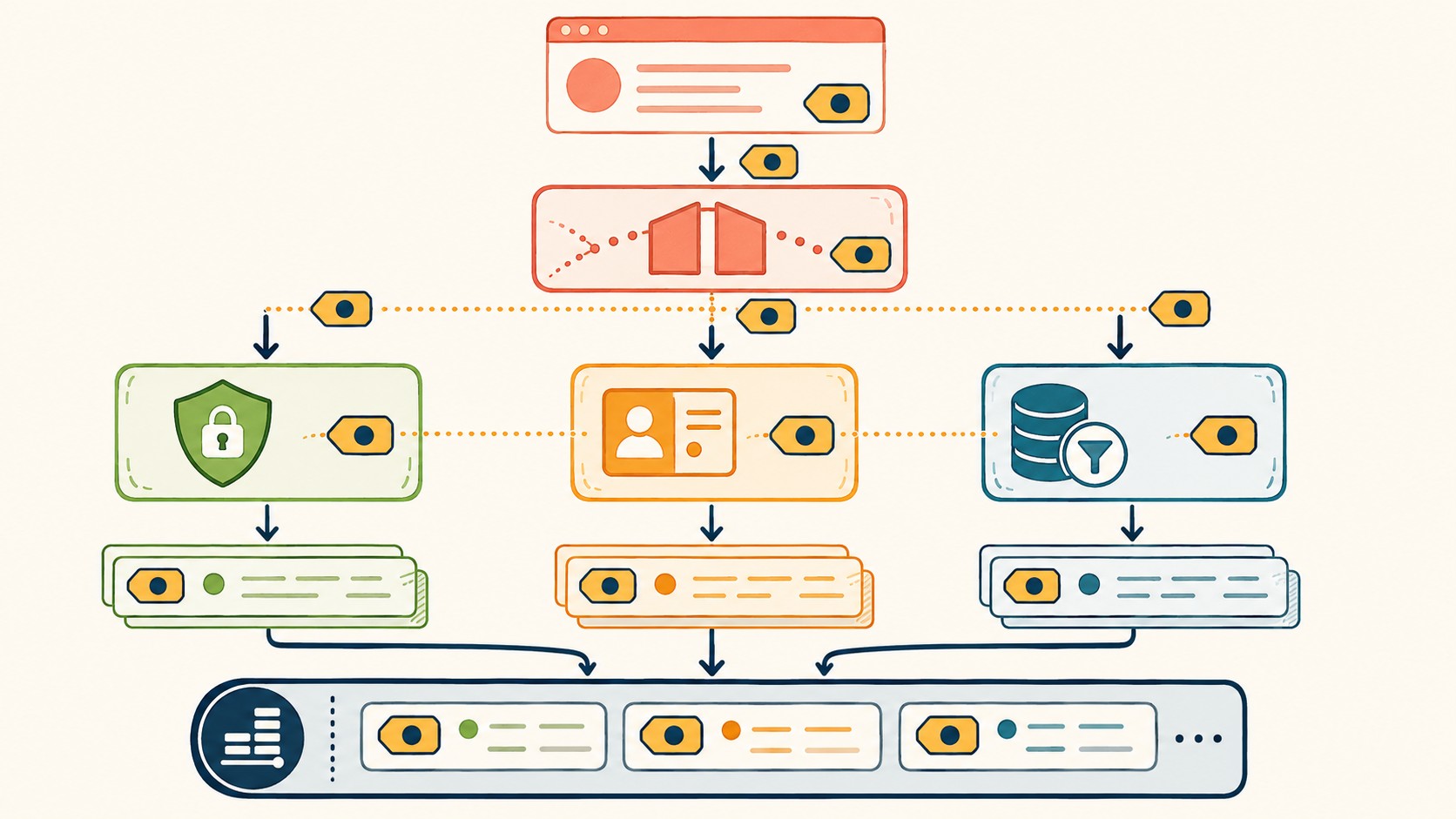
Un detalle clave: OpenTelemetry no pelea contra Jaeger ni Zipkin. Instrumentás con OpenTelemetry y exportás a cualquiera de los dos. Si recién empezás, Zipkin te levanta el entorno en minutos. Si ya tenés volumen serio, Jaeger escala mejor.
Todo esto corre en tu infraestructura, claro. Si estás montando los servicios y el backend de trazas en un VPS o cloud, podés alojarlo donde tengas control real del entorno, por ejemplo en donweb.com para proyectos en la región.
Errores comunes al implementar IDs de correlación en APIs
- Generar un ID nuevo sin mirar el header: rompés la cadena con los servicios de arriba. Revisá siempre
x-correlation-idantes de crear uno. - No propagarlo aguas abajo: el ID muere en el primer servicio y las llamadas siguientes quedan huérfanas. Pasalo en cada request saliente.
- Olvidar los logs internos: si un servicio intermedio no loguea el ID, tenés un agujero ciego justo en el medio de la traza.
- Confundir correlation ID con trace ID: son parientes, pero no idénticos (lo aclaramos abajo). Mezclar conceptos te lleva a esperar cosas que la herramienta no hace.
- No devolver el ID al cliente: sin el header en la respuesta, el front no puede mandarte el ID cuando reporta un bug. Y ahí perdés la mitad del valor.
Preguntas Frecuentes
¿Qué es un ID de correlación?
Es un valor único que se asigna a una solicitud cuando entra a tu sistema y se propaga a cada servicio y línea de log que esa solicitud toca. Te deja reconstruir el recorrido completo de una request filtrando por un solo identificador.
¿Cómo implementar un correlation ID en Express o Node.js?
Con un middleware que lee el header x-correlation-id o genera un UUID con crypto.randomUUID(), y guarda ese valor en AsyncLocalStorage. Así queda disponible en todo el contexto de la request sin pasarlo como parámetro por cada función. Lo explicamos a fondo en agentes sin dependencias externas.
¿Cuál es la diferencia entre correlation ID y trace ID?
El correlation ID es un valor único por solicitud, pensado sobre todo para agrupar logs. El trace ID es parte del modelo de tracing distribuido (OpenTelemetry), donde una traza se divide en spans con tiempos por operación. El trace ID mide latencia por salto; el correlation ID, en su forma básica, solo agrupa.
¿Cómo propago el ID a servicios aguas abajo?
Agregás el mismo ID en el header x-correlation-id de cada llamada HTTP saliente, leyéndolo del contexto. En comunicación asincrónica (Kafka, RabbitMQ, SQS) viaja como metadato del mensaje, no en el body. Nunca generes uno nuevo en cada servicio.
¿Por qué importa rastrear solicitudes en microservicios?
Porque una sola request toca varios servicios en máquinas distintas y el error queda repartido. Sin un ID que una los logs, el debugging se vuelve búsqueda por timestamp con riesgo de mezclar requests. Con correlación, el tiempo de resolución baja de horas a minutos.
Conclusión
Los IDs de correlación en APIs son lo más barato que podés agregar para ganar visibilidad real sobre lo que pasa entre tus servicios. Un middleware de veinte líneas, el ID en cada log y la propagación en cada llamada saliente. Con eso ya pasás de adivinar a saber.
Si tu sistema crece, el siguiente paso es instrumentar con OpenTelemetry y mandar las trazas a Jaeger o Zipkin para medir también la latencia de cada salto. Pero no empieces por ahí. Empezá por el correlation ID: es el 20% del esfuerzo que te da el 80% del alivio cuando algo se rompe en producción un viernes a las seis de la tarde.
Fuentes
- Correlation IDs: Trace a Single Request Across Every Service in Your API (dev.to) – artículo base con el middleware de Express
- Microsoft Engineering Playbook – patrón de correlation ID en observabilidad
- Jaeger – backend de tracing distribuido (CNCF)
- Paradigma Digital – trazabilidad de peticiones en microservicios
- Izertis – logging en Express.js con identificador único por request