Más subagentes paralelos, pipeline más lento: la data
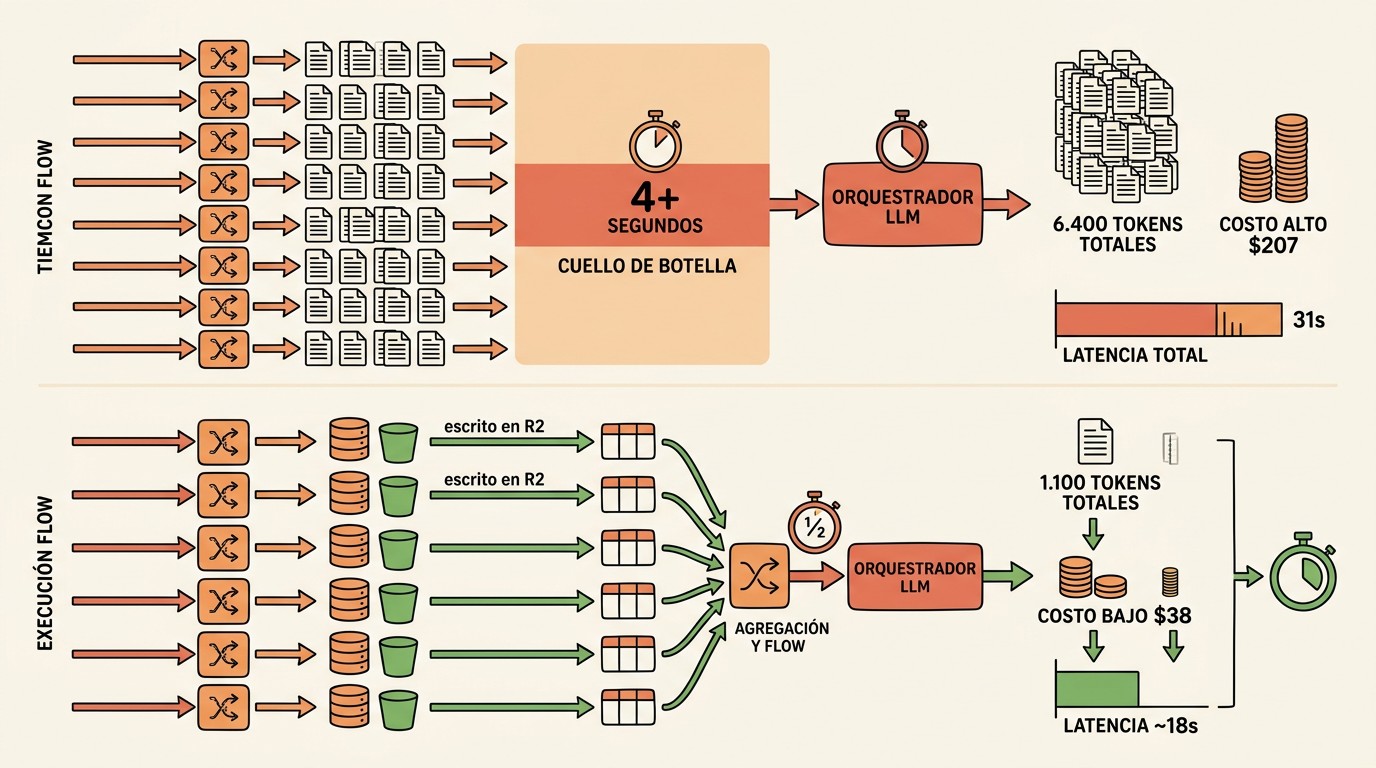
Agregar un séptimo subagente paralelo llevó la latencia del orquestador de 22 a 31 segundos, justo lo contrario de lo que cualquiera esperaría. Y acá está el dato que importa para la optimización de subagentes paralelos en LLM: el paralelismo nunca fue el problema. Cada subagente terminaba en 9 a 12 segundos sin importar cuántos había. El cuello de botella estaba después, en juntar todo.
Lo contó un desarrollador en un análisis publicado en dev.to, con logs de producción de su SaaS de análisis de creatividades publicitarias. Tres semanas de data. Y la conclusión es incómoda para cualquiera que esté escalando agentes.
La optimización de subagentes paralelos en LLM es el conjunto de ajustes de arquitectura que evita que la fase de recopilación de resultados (el “embudo”) se coma todo el tiempo que ganaste corriendo los agentes en paralelo (el “abanico”). No se trata de cuántos agentes lanzás, sino de qué lee el orquestador cuando todos terminan.
En 30 segundos
- El séptimo subagente subió la latencia de 22s a 31s, pero los agentes individuales seguían tardando 9-12s cada uno.
- Con 8 subagentes de ~800 tokens, el orquestador armaba un contexto de 6.400 tokens (52.480 bytes) antes de la primera llamada al modelo.
- Serializar esos 8 bloques JSON costaba 4.312 ms de CPU pura en Cloudflare Workers, antes de disparar la API.
- La solución: cada agente escribe en R2 y el orquestador lee solo un resumen de 3 campos. El contexto bajó de 6.400 a 1.100 tokens.
- El costo mensual de ese paso pasó de USD 207 a USD 38.
Cloudflare es una plataforma de red de entrega de contenidos (CDN) y seguridad web desarrollada por Cloudflare, Inc., fundada en 2009. Proporciona servicios de caching, protección contra ataques DDoS, optimización de rendimiento y gestión de DNS para sitios web.
¿Por qué más paralelismo no te da más velocidad?
Ponele que tenés un pipeline de análisis. Lanzás N subagentes en paralelo, cada uno mira un pedazo del problema, y al final un orquestador junta todo en un único veredicto. Patrón clásico de abanico y embudo (fanout/funnel). Lo lógico sería pensar que sumar agentes solo agrega un poco de trabajo en paralelo, que es gratis.
No es así. El abanico escala bárbaro. El embudo no.
En el caso real, cada subagente devolvía cerca de 800 tokens de análisis. Con 8 agentes, eso es 6.400 tokens que el orquestador tenía que serializar a una sola cadena de prompt antes de poder llamar al modelo una sola vez. Y ahí está la trampa: esa serialización ocurre en el CPU del worker, no en el modelo. Es tiempo muerto que no ves si solo mirás cuánto tarda cada agente. Ya lo cubrimos antes en coordinación de workers paralelos.
¿Dónde está el verdadero cuello de botella: ejecución o agregación?
Hay dos fases bien distintas y conviene medirlas por separado.
- Abanico (spawn de los agentes): rápido y sin sorpresas. 9-12 segundos por agente, en paralelo, sin importar si son 3 u 8.
- Embudo (agregación de resultados): acá se pudre todo. A partir de 6 subagentes, la agregación se comía más de la mitad del tiempo total de reloj.
El log que lo dejó en evidencia fue este, según el reporte del autor:
[worker:orchestrator] WARN
aggregate_context_size=52480 bytes
serialize_duration=4312ms
reason="context_assembly_backpressure"52.480 bytes ensamblados. 4.312 milisegundos de serialización. Todo eso antes de la primera llamada a la API. ¿Y qué pasaba si agregabas un agente más para “ir más rápido”? Exacto, ibas más lento, porque agrandabas el blob que había que serializar.
¿Cómo medir dónde se pierde el tiempo en tu pipeline?
Si no instrumentás cada fase, vas a buscar el problema en el lugar equivocado. La receta mínima es poner tres marcas de tiempo: una cuando lanzás los agentes, una cuando vuelve cada uno, y una cuando arranca la llamada de agregación al modelo.
Con esas marcas, la cuenta es directa: si serialize_duration + el ensamblado del contexto superan al tiempo de ejecución de los agentes, tu cuello de botella es el contexto, no el paralelismo. Logueá el tamaño en bytes del contexto agregado. Ese número es el que delata el problema antes que cualquier otra métrica.
La solución: escribir en storage en vez de pasar el contexto completo
El arreglo no fue bajar el paralelismo. Fue cambiar qué lee el orquestador.
Cada subagente, al terminar, escribe su resultado completo en R2 (el object storage de Cloudflare). El orquestador ya no junta 6.400 tokens: levanta solo una estructura de resumen de 3 campos por agente. Ocho agentes siguen produciendo ocho archivos, pero el contexto de agregación cayó de ~6.400 a ~1.100 tokens. Relacionado: impacto del almacenamiento en pipelines.
El resultado en plata: ese paso del pipeline pasó de USD 207 a USD 38 al mes. Misma cantidad de agentes, mismo paralelismo, ochenta por ciento menos de costo. Y de yapa, ahora podés manejar 100 agentes sin que la memoria del worker explote, porque nunca cargás todo junto.
¿Cuándo conviene cada enfoque según la escala?
No todo el mundo necesita montar object storage. Depende de cuántos agentes corras. Si tu infra vive en un VPS o un servidor propio (en donweb.com conseguís opciones en Argentina para ese tipo de cargas), la lógica es la misma: el costo está en serializar, no en ejecutar.
| Escala | Cantidad de agentes | Estrategia recomendada | Por qué |
|---|---|---|---|
| Chico | Menos de 5 | Ignóralo, pasá el contexto completo | El costo de CPU de serializar es despreciable |
| Mediano | 5 a 15 | Filtrar resultados antes de agregar | Quédate solo con los campos clave, descartá el análisis detallado |
| Grande | 15 o más | Storage externo (R2, S3) o chunking | Evitás desborde de memoria y serialización pesada |
El trade-off honesto: el storage externo agrega latencia de lectura y escritura. Pero a partir de cierto volumen, esa latencia es mucho menor que los segundos de CPU que perdés serializando todo en memoria.
El patrón de resumen de 3 campos, en concreto
La idea es que el agente no devuelva su análisis crudo, sino un struct chico que el orquestrador pueda agregar barato. Algo así:
- decision: el veredicto del agente, un string corto.
- confidence: un número entre 0 y 1.
- reasoning_ref: un identificador que apunta al razonamiento completo guardado en storage.
El orquestrador hace la agregación rápida con esos tres campos. Si en algún caso necesita el razonamiento entero, recién ahí va a buscarlo al storage por su referencia. Así un payload de ~800 tokens por agente se reduce a unos ~200 bytes en el contexto. La diferencia entre iterar resúmenes y cargar todo el análisis en memoria es, justamente, la diferencia entre 1.100 y 6.400 tokens. Esto se conecta con lo que analizamos en qué plataforma de CI/CD elegir.
¿Cuándo el paralelismo sí te suma?
Que quede claro: nadie está diciendo que paralelizar esté mal. Si cada agente tarda 9-12 segundos y corrés 8 en paralelo, te ahorrás más de 60 segundos contra hacerlo en serie. Eso es un golazo.
El error es ignorar la fase de agregación y asumir que es gratis. Con la optimización de almacenamiento, te quedás con lo mejor de los dos mundos: la ejecución sigue siendo paralela y rápida, y la agregación pasa a costar 1-2 segundos en lugar de 4 y pico. Latencia baja y contexto barato, al mismo tiempo.
Errores comunes al escalar subagentes
- Medir solo el tiempo de los agentes: si mirás únicamente cuánto tarda cada subagente, todo parece bien. El problema vive entre que vuelve el último y arranca la llamada de agregación. Instrumentá esa franja.
- Pensar que sumar agentes siempre acelera: a partir de 6 agentes, cada uno nuevo agranda el blob a serializar. La curva se da vuelta y empezás a perder tiempo en vez de ganarlo.
- Pasar el análisis completo cuando alcanza con un resumen: el orquestador casi nunca necesita los 800 tokens de cada agente para decidir. Mandá 3 campos y guardá el resto en storage por si hace falta.
- Montar object storage para 4 agentes: abajo de 5 agentes, el costo de serializar es ruido. No te compliques la vida con R2 o S3 si tu escala no lo justifica.
Preguntas Frecuentes
¿Por qué agregar más subagentes paralelos hace más lento mi pipeline?
Porque cada subagente extra agranda el contexto que el orquestador tiene que serializar antes de llamar al modelo. En el caso documentado, pasar de 6 a 7 agentes subió la latencia de 22s a 31s, ya que serializar los bloques JSON costaba 4.312 ms de CPU. Los agentes corren en paralelo, pero la agregación es secuencial.
¿Cómo sé si el cuello de botella está en los agentes o en la orquestación?
Comparás dos números: el tiempo de ejecución de los agentes contra la suma de serialización más ensamblado de contexto. Si lo segundo supera a lo primero, el problema es el contexto, no el paralelismo. Logueá el tamaño en bytes del contexto agregado, que es la métrica que lo delata. Tema relacionado: comparación práctica Jenkins y GitHub Actions.
¿Cuánto se puede ahorrar con esta optimización?
En el caso real, el costo mensual de ese paso del pipeline cayó de USD 207 a USD 38, un 82% menos. El contexto de agregación bajó de ~6.400 a ~1.100 tokens al reemplazar el payload completo por un resumen de 3 campos guardado en R2.
¿Siempre necesito storage externo como R2 o S3?
No. Con menos de 5 agentes el costo de serializar es despreciable y conviene pasar el contexto completo. Entre 5 y 15 agentes alcanza con filtrar campos antes de agregar. El storage externo se vuelve necesario recién con 15 o más agentes, donde el riesgo de desborde de memoria es real.
¿Qué es el patrón de resumen de 3 campos?
Es devolver desde cada agente solo tres datos (decisión, confianza y una referencia al razonamiento completo) en vez del análisis entero. El orquestador agrega rápido con esos campos y va a buscar el detalle al storage únicamente si lo necesita. Reduce el payload de ~800 tokens a ~200 bytes por agente.
Conclusión
El dato que deja este caso es simple y va contra la intuición: en un pipeline de subagentes, el abanico es rápido y el embudo es el que te mata. Si estás escalando agentes y la latencia sube en vez de bajar, no toques el paralelismo. Andá a medir cuánto tarda tu orquestador en serializar y ensamblar el contexto antes de la llamada al modelo.
La acción concreta: instrumentá las tres marcas de tiempo, mirá el tamaño en bytes del contexto agregado, y si pasás de 15 agentes, mové los resultados a storage y leé solo un resumen. Ochenta por ciento menos de costo por un cambio de arquitectura que no toca un solo modelo. Vale la pena medirlo antes de tirar más agentes al problema.





