Tu stack Docker corre. ¿Alguien lo está mirando?
El monitoreo de Docker es el conjunto de prácticas y herramientas que permiten observar en tiempo real el estado de tus contenedores, detectar fallos silenciosos y recibir alertas antes de que un problema llegue a producción. Según datos publicados en mayo de 2026, el 72% de las organizaciones sufrió al menos un outage por certificado SSL vencido en el último año, y muchos de esos incidentes ocurrieron en stacks Docker que “estaban corriendo bien”.
En 30 segundos
- El 72% de las organizaciones tuvo outages por certificados expirados; el promedio tarda 2.6 horas en detectarse y 2.7 más en resolverse.
- Desde marzo de 2026, el CA/Browser Forum redujo la validez máxima de certificados SSL de 398 a 200 días, camino a 47 días en 2029.
- Puertos expuestos en 0.0.0.0, imágenes desactualizadas y contenedores temporales olvidados son los vectores más comunes de incidentes silenciosos.
- Prometheus + Grafana sigue siendo el stack open-source más completo; Dockprom y TICK son alternativas válidas con menor curva de configuración.
- Con un docker-compose de 30 líneas podés tener alertas en Slack funcionando en menos de una hora.
El problema invisible: qué está fallando en tu Docker sin que lo sepas
Ponele que desplegaste tu app. Los contenedores están verdes en docker ps. El sitio responde. Cerrás el browser convencido de que todo está bien.
Lo que probablemente está pasando en este momento en tu servidor de producción, según un análisis publicado en mayo de 2026: tu contenedor de Postgres está escuchando en 0.0.0.0 porque olvidaste scopear el binding de puertos, tu imagen de MariaDB tiene una actualización crítica pendiente (11.4 a 12.2.2) que lleva semanas sin aplicarse, uno de tus certificados SSL vence en 6 días, ese “contenedor de prueba temporal” que levantaste el viernes a la tarde sigue corriendo expuesto a internet, y tu cron de backups nocturno dejó de funcionar hace 3 días sin que nadie lo notara.
Nadie está mirando. Porque configurar monitoreo para Docker es engorroso, así que la mayoría no lo hace.
Cinco amenazas silenciosas que nadie monitorea
Los problemas que más dañan en producción no son los que explotan ruidosamente. Son los que se pudren despacio.
Puertos expuestos sin scope
Cuando montás un puerto como 5432:5432 sin especificar la IP de bind, Docker lo expone en todas las interfaces, incluida la pública. Tu base de datos queda accesible desde cualquier IP. Esto no aparece como error, no genera logs llamativos, y va a seguir así hasta que alguien lo abuse.
Imágenes desactualizadas con vulnerabilidades conocidas
Una imagen que funcionaba bien en enero puede tener un CVE crítico en mayo. Sin herramientas como Trivy o Clair haciendo escaneo periódico, no tenés forma de saberlo hasta que alguien te lo señala (o explota).
Certificados SSL que expiran en silencio
Los certificados no avisan. No mandan un email. No generan un log de advertencia en Docker. Un día tu sitio tiene HTTPS, al día siguiente le aparece el candado rojo a tus usuarios y vos te enterás por un mensaje de WhatsApp.
Cron jobs fallidos
¿Cuándo fue la última vez que verificaste que tu cron de backup realmente ejecutó y realmente guardó algo? Sin monitoring, un job silencioso que falla tres semanas seguidas pasa completamente desapercibido hasta que necesitás restaurar algo y no hay nada. Lo explicamos a fondo en detectar problemas antes de que causen downtime.
Contenedores temporales que se quedan para siempre
Levantás un contenedor para debuggear algo rápido el viernes. El lunes ya te olvidaste. Ese contenedor sigue corriendo, expuesto, consumiendo recursos, con una imagen sin parchear. Es el tipo de “deuda operacional” que no aparece en ningún backlog.
Certificados SSL: la bomba de tiempo que provoca outages globales
Los números son difíciles de ignorar. El 72% de las organizaciones experimentó al menos un outage relacionado con certificados en el último año. El 34% tuvo múltiples. Y cuando un cert expira en producción, el promedio de tiempo para identificar el problema es 2.6 horas; resolverlo lleva 2.7 horas más. Son más de cinco horas de incidente por algo que con monitoreo básico se previene en minutos.
¿Y qué pasó cuando grandes empresas ignoraron esto? Algunos casos documentados: Microsoft Teams estuvo caído durante horas por un certificado vencido. Spotify tuvo un outage en su plataforma de podcasts por la misma razón. No son startups improvisadas.
El tema se va a complicar más. Según GeekFlare, el CA/Browser Forum aprobó en marzo de 2026 la reducción de la validez máxima de certificados: de los 398 días que regían a 200 días, y eventualmente a 47 días en 2029. Eso significa pasar de renovar una vez por año a hacerlo aproximadamente 8 veces. Quien confíe en un recordatorio de calendario va a tener un problema crónico.
Let’s Encrypt con renovación automática vía Certbot dentro de Docker es el piso mínimo razonable hoy. La automatización con contenedores como acme-companion maneja la renovación sin intervención manual. Pero igual necesitás alertas que te avisen si la renovación automática falló.
Comparativa de stacks de monitoreo: cuál usar según tu situación
No existe una solución única. Lo que funciona para un equipo de 3 personas gestionando 10 contenedores no escala igual para 50 microservicios. Acá va la comparativa honesta:
| Stack | Tipo | Curva de aprendizaje | Costo | Mejor para | Contras |
|---|---|---|---|---|---|
| Prometheus + Grafana + Loki | Open-source | Alta | Gratis (infra propia) | Equipos con DevOps dedicado, alta personalización | Configuración inicial compleja, requiere mantenimiento |
| Dockprom | Open-source, all-in-one | Media | Gratis | Stacks medianos, arrancar rápido | Menos flexible, actualización manual |
| TICK Stack (Telegraf + InfluxDB + Chronograf + Kapacitor) | Open-source | Media-alta | Gratis / InfluxDB Cloud desde USD 0 | Series temporales, métricas de alto volumen | InfluxDB 2.x cambió bastante, documentación fragmentada |
| DockMon | Open-source | Baja | Gratis | Notificaciones multi-canal rápidas | Métricas básicas, sin dashboards visuales |
| ManageEngine Applications Manager | Comercial | Baja | Desde USD 945/año | Empresas, compliance, soporte incluido | Costo elevado, overkill para equipos chicos |
Para la mayoría de los equipos que recién empiezan, Dockprom es el camino más rápido. Para quienes quieren algo serio y escalable, Prometheus + Grafana. El TICK Stack tiene sentido si ya usás InfluxDB para otra cosa. DockMon zafa para alertas básicas sin dashboards.
Herramientas prácticas: desde la CLI hasta dashboards inteligentes
Nivel básico: lo que Docker trae de fábrica
docker stats te da CPU, memoria y red en tiempo real por contenedor. No guarda historial, no alerta, pero sirve para diagnosticar en el momento. Es el punto de partida de cualquiera.
Terminal avanzada: Ctop y Glances
Ctop es un top para contenedores: lista todos, con métricas, filtrable, navegable. Glances agrega contexto del sistema completo. Ambas son herramientas de terminal, sin configuración, útiles para SSH rápido a un servidor.
Web UI: Portainer y cAdvisor
Portainer tiene interfaz web para gestionar contenedores, redes y volúmenes. cAdvisor (de Google) expone métricas detalladas por contenedor en formato Prometheus. Los dos se despliegan como contenedores y son el complemento natural si ya usás Grafana. Sobre eso hablamos en agregando herramientas al stack containerizado.
Seguridad en runtime: Falco
Falco monitorea comportamiento en tiempo de ejecución: si un contenedor intenta abrir un shell, leer archivos sensibles o hacer llamadas de sistema inusuales, te avisa. No reemplaza al monitoreo de métricas, pero cubre un ángulo completamente diferente.
Vulnerabilidades: Trivy
Trivy escanea imágenes Docker en busca de CVEs conocidos. Se integra en CI/CD o se corre manualmente. Es gratis, rápido y detecta problemas en dependencias de la aplicación además del OS base.
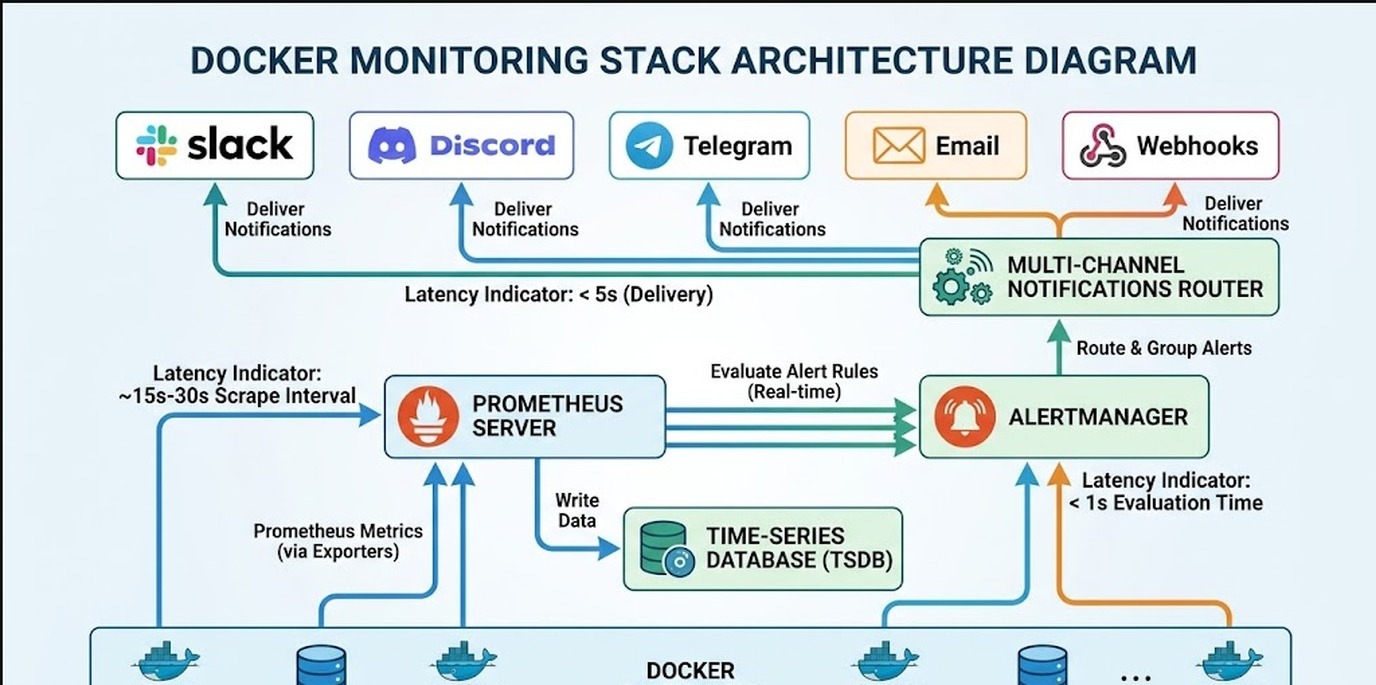
Implementá tu primer stack de alertas en una hora
Si nunca configuraste monitoreo en Docker, este es el punto de entrada más razonable: Prometheus scrapeando métricas de cAdvisor, Grafana mostrando dashboards, y Alertmanager mandando notificaciones a Slack cuando algo sale mal.
El docker-compose.yml mínimo tiene este esquema:
- cAdvisor (imagen
gcr.io/cadvisor/cadvisor): expone métricas de contenedores en:8080/metrics - Prometheus (imagen
prom/prometheus): scrapea cAdvisor cada 15 segundos, retiene 15 días por defecto - Grafana (imagen
grafana/grafana): conectado a Prometheus como datasource, dashboard pre-hecho importable con ID 893 - Alertmanager (imagen
prom/alertmanager): recibe alertas de Prometheus y las enruta a Slack/Discord/Telegram
El archivo de reglas de Prometheus para las alertas críticas básicas tiene que tener al menos estas tres: contenedor caído hace más de 2 minutos, uso de memoria mayor al 85% por más de 5 minutos, y disco del host por encima del 80%. Son los tres que salvan el 80% de los incidentes comunes.
Tiempo real de setup si ya tenés Docker instalado: entre 45 y 90 minutos la primera vez. Luego es copiar el compose y ajustar los targets.
Alertas inteligentes: recibí notificaciones antes de que se caiga
Una alerta que llega cuando el servidor ya está caído no sirve para nada. El objetivo es recibir la notificación cuando el sistema todavía puede responder pero algo está degradándose.
Alertmanager soporta Slack, Discord, Telegram, Pushover y email de fábrica. La config base es un YAML con receivers y routes. Lo interesante es que podés agrupar alertas para no recibir 40 notificaciones cuando un deploy nuevo rompe varios checks a la vez.
¿Y qué reglas específicas convienen para certificados SSL? La de uso extendido es monitorear los días restantes con una expresión PromQL usando el exporter blackbox_exporter: alerta cuando quedan menos de 30 días, y alerta crítica cuando quedan menos de 7. Con la reducción a 47 días de validez que viene en camino, esos umbrales van a tener que ajustarse. Para más detalles técnicos, mirá automatizar respuestas a las alertas críticas.
Para el silenciamiento temporal (cuando sabés que algo va a estar caído por mantenimiento programado), Alertmanager tiene silences con duración definida. Así evitás el fatiga de alertas que lleva a que la gente las ignore.
Qué está confirmado y qué no
Confirmado
- La reducción de validez de certificados a 200 días fue aprobada por el CA/Browser Forum en marzo de 2026.
- El 72% de incidentes por certs y el tiempo promedio de resolución de 5.3 horas son datos de estudios del sector publicados en 2026.
- Prometheus, Grafana y cAdvisor son proyectos activos con releases recientes en 2026.
- Falco 0.38.x soporta detección de comportamientos en contenedores Docker y Kubernetes.
Pendiente de verificar en tu entorno
- La reducción a 47 días está planificada para 2029 pero puede cambiar según negociaciones entre browsers y CAs.
- Los costos de soluciones comerciales varían por región y plan; verificá los precios actuales antes de cotizar.
- La integración de DockMon con algunos canales de notificación tiene reportes de inconsistencias en versiones recientes.
Errores comunes al implementar monitoreo en Docker
Error 1: monitorear solo si el contenedor corre, no lo que hace
Un contenedor puede estar “running” y tener la aplicación interna colgada, consumiendo el 100% de CPU, o con la base de datos inaccesible. docker ps no te dice eso. Necesitás healthchecks dentro del compose y métricas de la aplicación, no solo del proceso.
Error 2: configurar alertas pero nunca verificar que llegan
El webhook de Slack estaba mal configurado desde el día uno. Las alertas se generaban, Alertmanager las recibía, y nadie se enteraba porque el destino fallaba silenciosamente. Hacé un test de alerta manual cada vez que configurés un canal nuevo.
Esto se conecta con nuestro artículo sobre Your Docker Stack Is Running. But Is Anyone Actually Watchin.
Igual, sin monitoreo de verdad, tu stack corre pero andás a ciegas; chequeá nuestro artículo: Your Docker Stack Is Running. But Is Anyone Actually Watchin.
Si querés profundizar en monitoreo y automatización, podés leer Your Docker Stack Is Running. But Is Anyone Actually Watchin.
Relacionado con esto tenés Your Docker Stack Is Running. But Is Anyone Actually Watchin, que cubre la temática en profundidad.
Si querés meterte en tema, acá va Your Docker Stack Is Running. But Is Anyone Actually Watchin.
Esto se conecta con Your Docker Stack Is Running. But Is Anyone Actually Watchin, donde cubrimos el tema en profundidad.
Si querés profundizar en esto, tenemos un artículo sobre Your Docker Stack Is Running. But Is Anyone Actually Watchin.
Si querés saber más sobre esto, está Your Docker Stack Is Running. But Is Anyone Actually Watchin.
Todo esto lo cubrimos en detalle acá: Your Docker Stack Is Running. But Is Anyone Actually Watchin.
Esto se conecta con nuestro artículo Your Docker Stack Is Running. But Is Anyone Actually Watchin si querés profundizar.
Error 3: retener métricas por defecto (15 días) para proyectos con SLA
Si tenés acuerdos de nivel de servicio que requieren reportes mensuales, 15 días de retención no alcanza. Configurá --storage.tsdb.retention.time=90d en Prometheus desde el arranque, antes de tener que migrar datos.
Error 4: ignorar el monitoreo del host
Docker corre sobre un host. Si el disco del host se llena, todos los contenedores se caen. Si la memoria del host se agota, el OOM killer empieza a matar procesos. node_exporter de Prometheus monitorea el host; no lo omitas pensando que “eso no es Docker”.
Preguntas Frecuentes
¿Cómo monitorear mi stack de Docker en producción sin experiencia previa?
Empezá con Dockprom: es un repositorio con docker-compose que levanta Prometheus, Grafana y Alertmanager preconfigurados. Cloná el repo, ajustá las variables de entorno con tu token de Slack y ejecutá docker compose up -d. Tenés dashboards funcionales en menos de una hora sin escribir configuración desde cero.
¿Qué herramientas me alertan sobre certificados SSL que vencen?
Blackbox Exporter de Prometheus monitorea endpoints HTTPS y expone los días restantes de validez del certificado como métrica. Con una regla de alertas en Prometheus podés recibir notificaciones 30 días antes del vencimiento. También existen herramientas dedicadas como Certificate Expiry Monitor que se despliegan como contenedor y envían alertas por email o Slack.
¿Por qué mis contenedores fallan sin que me entere?
Docker reporta el estado del proceso principal del contenedor, no el estado de la aplicación. Si tu app tiene un deadlock interno o la conexión a la base de datos se cortó, el contenedor sigue “running”. Los healthchecks en el docker-compose.yml permiten definir un comando de verificación que Docker ejecuta periódicamente para evaluar si la app responde correctamente.
¿Cómo evitar outages por certificados expirados en Docker?
Usá Let’s Encrypt con renovación automática vía acme-companion o Traefik con ACME integrado. Complementá con monitoreo de expiración para detectar si la renovación automática falla. Con la reducción de validez de certificados a 200 días vigente desde 2026, la renovación manual es inviable en cualquier stack con más de 3-4 dominios.
¿Qué es observabilidad en Docker y cómo implementarla?
Observabilidad es la capacidad de entender el estado interno del sistema a partir de sus salidas externas: métricas (qué tan bien funciona), logs (qué pasó) y trazas (cómo fluye una request). En Docker, implementarla significa combinar Prometheus para métricas, Loki para logs centralizados y opcionalmente Tempo o Jaeger para trazas distribuidas, todo visualizable desde Grafana.
Conclusión
Un stack Docker sin monitoreo no es un stack en producción. Es un stack que todavía no explotó. Los datos de 2026 confirman que el 72% de las organizaciones ya pagó el costo de ignorar el monitoreo de certificados, y la reducción de validez a 200 días convierte esto en un problema que va a empeorar si no se automatiza ahora.
La buena noticia es que el umbral de entrada bajó mucho. Con Dockprom o un compose mínimo de Prometheus + Grafana, en una tarde tenés dashboards y alertas funcionando. Si tu infraestructura está en un VPS (en donweb.com o en otro proveedor), el proceso es el mismo. Lo que no podés seguir haciendo es esperar que “los contenedores estén verdes” sea suficiente señal de que todo está bien.
¿Cómo uso Glances para monitorear mis contenedores Docker?
Glances es una herramienta de terminal que muestra CPU, memoria y red en tiempo real por contenedor. Instalá con `pip install glances`, ejecutá el comando en tu servidor, y navegá con las flechas para ver cada contenedor. Ideal para diagnosticar problemas rápido sin configurar dashboards complejos.
¿Cuál es la alerta más importante para monitorear en Docker?
Los certificados SSL vencidos. El 72% de las organizaciones tuvo outages por certificados expirados. Después, controlá puertos expuestos (0.0.0.0), imágenes desactualizadas y fallos en cron jobs de backups. Sin alertas en estos puntos, tu stack está en riesgo constante.
¿Cuál es la diferencia entre Prometheus y Grafana para monitorear Docker?
Prometheus recolecta y almacena las métricas de tus contenedores; Grafana visualiza esos datos en dashboards. Necesitás ambas: Prometheus es el motor, Grafana es la interfaz. Sin Prometheus no hay datos; sin Grafana no ves nada en la web.
Fuentes
- Dev.to – Your Docker Stack Is Running. But Is Anyone Actually Watching It?
- GeekFlare – Cómo monitorear la expiración de certificados SSL
- Elastic – Monitoreo de contenedores Docker con Beats
- AdministracionDeSistemas.com – DockMon: monitorización de Docker
- ichasco.com – TICK Stack de monitorización en Docker