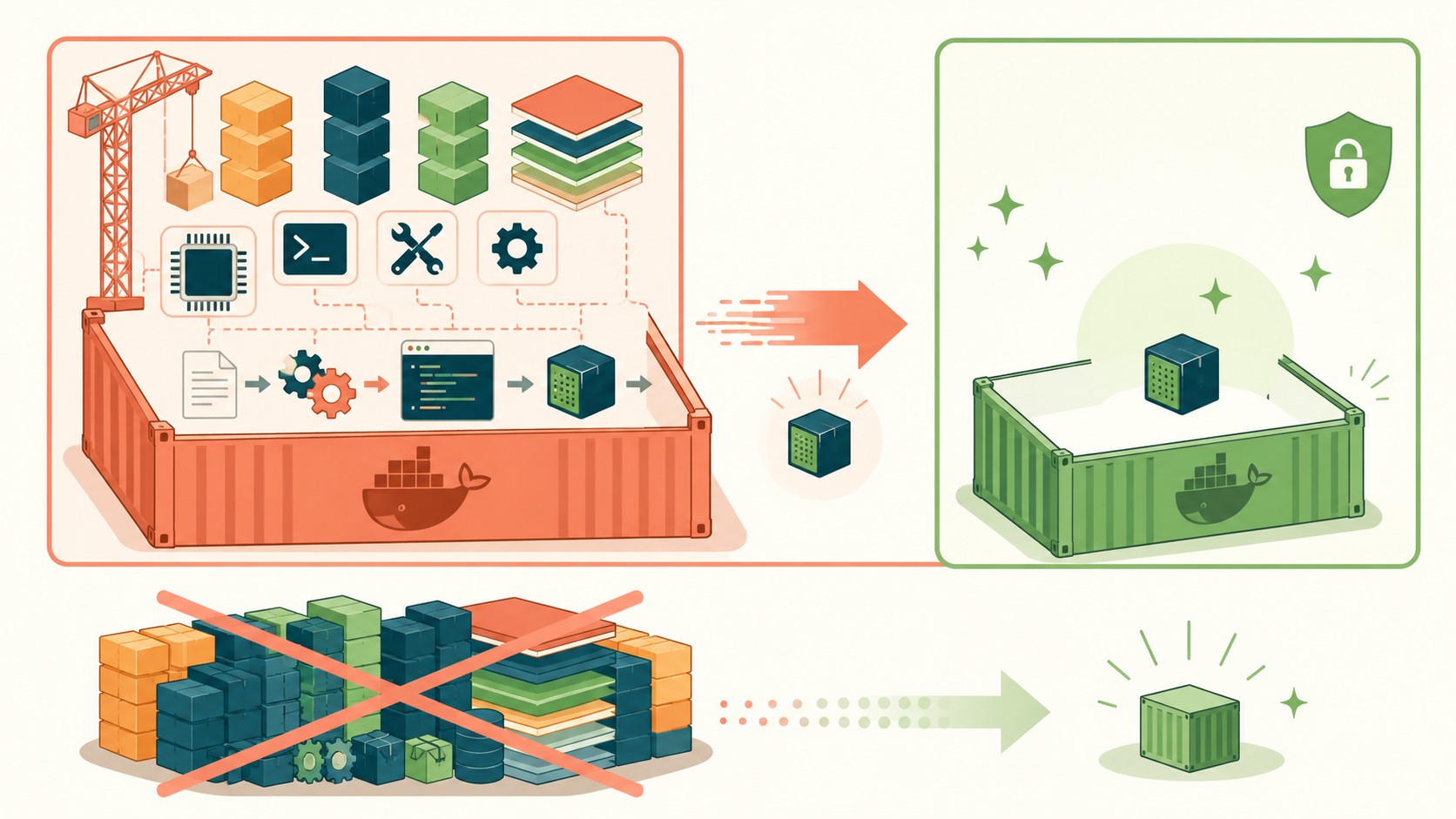
Docker multi-stage en Go: de 500MB a menos de 20MB
Si compilás un servicio en Go y lo metés en una imagen Docker bien armada, el contenedor final pesa menos de 20MB. La misma app en Spring Boot con una JRE adentro se va arriba de 300MB. La diferencia está en la construcción Docker multi-stage: compilás en una imagen pesada con todo el toolchain y corrés en una imagen pelada que solo tiene el binario. Menos peso, deploys más rápidos y menos superficie de ataque.
En 30 segundos
- Imagen final <20MB con Go compilado a binario estático, contra los 300MB+ de un fat jar de Spring Boot con JRE.
- Dos flags hacen casi todo:
CGO_ENABLED=0para binario estático y-ldflags='-s -w'que recorta 20-30% sacando símbolos de debug. - Distroless en vez de Alpine: sin shell (menos ataque) pero con timezone y certificados SSL que tu servicio sí necesita.
- Graceful shutdown obligatorio: ECS Fargate te da 30 segundos antes de matar el contenedor. Sin manejar SIGTERM, perdés requests vivos.
- Fargate sin servidores: definís CPU (256 a 4096) y memoria (512 a 30720MB), Terraform versiona todo en git.
Un Dockerfile multi-stage es un archivo con dos o más etapas, cada una arrancando con su propio FROM. La primera etapa (builder) compila el código con el toolchain completo. La segunda copia solo el artefacto final, el binario, a una imagen mínima. El compilador, las dependencias de build y el código fuente nunca llegan a producción. Es la técnica estándar para imágenes chicas en Go, y la documenta el propio manual de Docker.
Esto sale del último post de una serie de Mihir Mohapatra publicada el 25 de junio de 2026, donde toma un proyecto de aprendizaje en Go y lo lleva a producción real en AWS. Vale la pena desarmar cada parte.
¿Por qué una imagen Go pesa 15 veces menos que una de Java?
Go compila a un único binario autocontenido. No hay runtime que instalar, no hay JVM, no hay classpath que armar. Eso cambia todo el juego del deploy.
Ponele que tenés que levantar veinte réplicas de tu API en un cluster. Con una imagen de 300MB, cada nodo tiene que descargar esos cientos de MB antes de arrancar, y eso se nota cuando escalás rápido por un pico de tráfico. Con una imagen de 18MB, el pull es casi instantáneo. La diferencia se traduce en arranques más rápidos, menos memoria en reposo y una factura de hosting más baja. En nuestro artículo sobre cómo implementar pipelines CI/CD modernos profundizamos en este tema.
El binario chico también significa menos cosas adentro del contenedor. Y menos cosas adentro es menos software con vulnerabilidades potenciales. Eso lo apreciás el día que tenés que pasar un scan de seguridad.
¿Cómo escribir un Dockerfile multi-stage paso a paso?
La estructura tiene dos bloques bien marcados. El de build y el de run.
- Stage builder: arranca de
golang:1.25 AS builder, copia el código y corrego buildcon los flags de optimización. - Stage run: arranca de
gcr.io/distroless/static-debian12y hace unCOPY --from=buildertrayéndose nada más que el binario compilado.
Tres detalles del build que conviene entender en serio:
- CGO_ENABLED=0 desactiva los bindings con C. Sin eso no tenés un binario 100% estático y se rompe al correr en una imagen pelada sin libc dinámica.
- -ldflags=’-s -w’ saca la tabla de símbolos de debug y la info DWARF. Eso te recorta entre 20% y 30% del tamaño del binario sin tocar una línea de código. Gratis.
- El COPY selectivo es la clave del multi-stage: la imagen final no se entera de que existió un compilador.
¿El resultado típico? Abajo de 20MB. El fat jar equivalente de Spring Boot con una JRE de base se va, según el autor, bastante arriba de los 300MB.
¿Qué son las imágenes distroless y cuándo conviene usarlas?
Distroless es una imagen mínima de Google que no tiene shell, ni gestor de paquetes, ni las herramientas Unix de siempre. No hay /bin/sh, no hay apt, no hay ls. Trae solo lo esencial para correr tu binario: libc, datos de zona horaria y certificados SSL.
Acá viene lo bueno: sin shell, un atacante que logre ejecutar algo adentro del contenedor no tiene desde dónde agarrarse. No puede abrir una sesión interactiva ni encadenar comandos. Esa es la ventaja de seguridad que conlleva este cambio. Tema relacionado: cómo elegir entre Jenkins y GitHub Actions.
¿Y por qué no usar scratch, que es todavía más chica y está literalmente vacía? Porque scratch no trae los certificados SSL ni la timezone data, y tu servicio casi seguro los necesita la primera vez que hace una llamada HTTPS a otra API. Por eso el autor elige la variante static-debian12 de distroless sobre scratch.
| Imagen base | Tamaño aprox. | Shell | Certificados SSL | Cuándo usarla |
|---|---|---|---|---|
| scratch | 0 MB | No | No | Binarios sin red ni TLS |
| distroless static | ~2 MB base | No | Sí | Producción (la opción del autor) |
| Alpine | ~5 MB base | Sí (ash) | Sí | Cuando necesitás debuggear adentro |
| Imagen Go + JRE estilo Java | 300 MB+ | Sí | Sí | Evitar para servicios Go |
¿Cómo implementar graceful shutdown en Go y Gin?
El graceful shutdown es darle tiempo a los requests en vuelo para que terminen antes de apagar el contenedor. Suena obvio, pero la mayoría se lo saltea hasta que pierde transacciones en producción.
El escenario es este. ECS Fargate decide reemplazar tu contenedor, le manda una señal SIGTERM y arranca un reloj de 30 segundos por defecto. Si tu app no escucha esa señal, sigue procesando como si nada hasta que Fargate la mata de cuajo a los 30 segundos, y todo request que estaba a mitad de camino se pierde.
La solución en Go es directa: capturás syscall.SIGTERM, usás un context.Context con timeout y llamás a server.Shutdown() sobre el server de Gin. Eso le dice al server que deje de aceptar conexiones nuevas pero termine de atender las que ya están abiertas. Subís el contenedor, lo probás en local, mandás un par de requests largos, le tirás la señal y ves que los requests terminan limpios en vez de cortarse a la mitad. Recién ahí sabés que está bien cableado. Relacionado: en deployments geográficamente distribuidos.
¿Cómo deployar a ECS Fargate con Terraform?
Fargate es el modo de ECS donde no gestionás instancias EC2. No hay servidores que parchear ni capacidad que aprovisionar a mano. Definís cuánto CPU y memoria querés por tarea, AWS te corre el contenedor y pagás por el uso real.
Los pasos, resumidos:
- Task definition: declarás la imagen, el CPU (de 256 a 4096 unidades) y la memoria (de 512 a 30720 MB), más las variables de entorno.
- Servicio ECS: define cuántas réplicas querés y se encarga de mantenerlas vivas y de reemplazar las que fallan.
- Target group: conecta el load balancer con las tareas para repartir el tráfico.
El autor arma todo esto con Terraform: aws_ecs_task_definition, aws_ecs_service y aws_lb_target_group. La gracia de hacerlo como infraestructura como código es que queda versionado en git, es reproducible y lo revisás en un pull request antes de aplicarlo. Corrés terraform plan para ver qué va a cambiar, después terraform apply. Si mañana querés levantar un entorno idéntico de staging, es el mismo código con otras variables.
Si en vez de la nube de AWS estás evaluando dónde alojar tus servicios y dominios en la región, en donweb.com tenés infraestructura local pensada para Latinoamérica.
Errores comunes al dockerizar un servicio Go
- Dejar CGO activado sin querer: si no ponés
CGO_ENABLED=0y después copiás el binario a scratch o distroless, revienta al arrancar porque busca librerías de C que no están. El error es confuso y muchos pierden horas ahí. - Compilar y correr en la misma imagen: si te olvidás del multi-stage y usás
golang:1.25como imagen final, te llevás el compilador entero a producción. Ahí se te infla la imagen con todo el toolchain que no usás en runtime. - No manejar SIGTERM: sin graceful shutdown, cada deploy o cada reescalado te corta requests vivos. En una API de pagos eso no es un detalle, es plata.
- Usar scratch cuando necesitás TLS: copiás el binario a scratch, anda en local, lo subís y la primera llamada HTTPS falla por falta de certificados. Por eso distroless static es más seguro como default.
Preguntas Frecuentes
¿Cuál es el tamaño mínimo de una imagen Docker para Go?
Una imagen Go con un binario estático sobre distroless suele quedar por debajo de 20MB. Con scratch podés bajar todavía más porque la base ocupa 0MB, pero perdés los certificados SSL y la timezone data que la mayoría de los servicios necesitan.
¿Qué hace el flag -ldflags=’-s -w’ en go build?
Saca la tabla de símbolos de debug (-s) y la información DWARF (-w) del binario. Eso reduce entre 20% y 30% el tamaño sin cambiar el comportamiento. La contra es que perdés info para debuggear con herramientas que leen esos símbolos, así que se usa en builds de producción, no de desarrollo. Para más detalles técnicos, mirá ejecutar procesos sin dependencias externas.
¿Por qué distroless es más segura que Alpine?
Distroless no incluye shell ni gestor de paquetes, así que un atacante que ejecute código adentro del contenedor no tiene desde dónde lanzar comandos ni abrir una sesión interactiva. Alpine sí trae un shell (ash), que es útil para debuggear pero amplía la superficie de ataque.
¿Cuánto tiempo da ECS Fargate antes de matar un contenedor?
Fargate manda una señal SIGTERM y espera 30 segundos por defecto antes de forzar el kill. Durante esa ventana tu app tiene que terminar los requests en vuelo y cerrar conexiones con server.Shutdown(). Ese timeout se puede ajustar con stopTimeout en la task definition.
¿Qué ventaja tiene Fargate sobre EC2 para correr contenedores?
Con Fargate no gestionás instancias: no aprovisionás capacidad, no parcheás el sistema operativo del host ni configurás auto scaling de máquinas. Definís CPU y memoria por tarea y pagás por el uso real del contenedor. La contra es que el costo por unidad de cómputo suele ser más alto que administrar tus propias EC2.
Conclusión
El cambio de fondo es que un servicio Go bien empaquetado no se parece en nada a uno de Java. Pasás de cientos de MB a menos de 20MB, y eso baja costos, acelera deploys y reduce el riesgo de seguridad de un saque.
Si arrancás hoy, el orden tiene sentido: primero el Dockerfile multi-stage con CGO_ENABLED=0 y -ldflags='-s -w', después la base distroless static, después el graceful shutdown cableado a SIGTERM y recién ahí el deploy a Fargate con Terraform. Cada pieza resuelve un problema concreto que vas a tener sí o sí en producción. Probá el shutdown en local antes de confiar en él, que es donde casi todos se queman.
Fuentes
- From Learning to Shipping — Docker, Graceful Shutdown & ECS Fargate (Mihir Mohapatra, dev.to, 25/06/2026)
- Documentación oficial de Docker sobre builds multi-stage
- GoogleContainerTools/distroless en GitHub
- Guía de AWS ECS Fargate