De Waterfall a AIOps: la evolución que cambia ops
AIOps y DevOps son hoy dos caras de la misma moneda: DevOps resolvió el conflicto histórico entre desarrollo y operaciones creando una cultura de entrega continua, y AIOps extiende esa cultura con machine learning para anticipar fallos, correlacionar eventos y remediar incidentes sin intervención humana. La transición de Waterfall a AIOps no fue un salto sino una cadena de frustraciones acumuladas que forzaron cambios reales.
En 30 segundos
- Waterfall llegó a representar el 70% de los proyectos en 2015; para 2025 había caído al 37%, reemplazado por Agile y DevOps.
- AIOps agrega inteligencia artificial al ciclo DevOps: detecta anomalías en logs, métricas y eventos en tiempo real, antes de que el usuario note el problema.
- Los equipos DevOps de élite despliegan múltiples veces por hora usando canary releases y feature toggles, con un Change Failure Rate menor al 5%.
- El 97% de las empresas quiere incorporar IA a sus operaciones (datos de 2026), pero según análisis del sector, solo el 2% tiene la madurez de datos y procesos para hacerlo bien.
- La infraestructura autosanadora no es solo automatización: aplica ML para ejecutar playbooks sin que un humano toque nada, cortando el MTTR de horas a minutos.
Gemini es un modelo de lenguaje multimodal desarrollado por Google DeepMind que procesa texto, imágenes y video para generar respuestas y realizar análisis. Fue presentado en 2023.
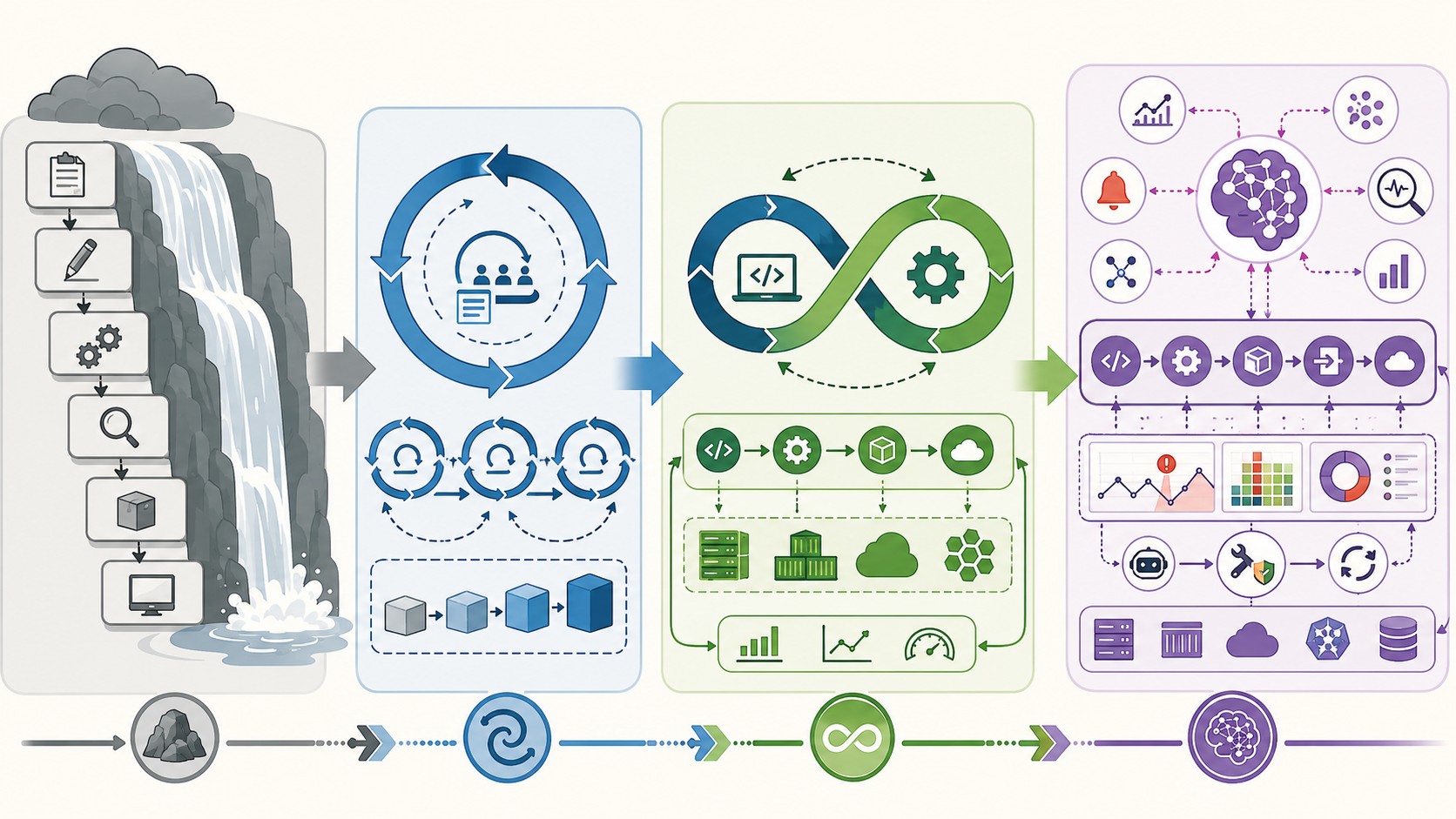
Del Waterfall al DevOps: cómo nació una cultura de la fricción
Antes de DevOps, la dinámica era simple y frustrante: desarrollo terminaba una feature, la tiraba “por encima del muro” a operaciones, y si algo se rompía en producción empezaba el partido de tenis. “Funciona en mi máquina” vs. “¿por qué production está caído?”. El problema no era técnico, era cultural: cada equipo optimizaba su silo sin pensar en el sistema completo.
Eso generaba ciclos de entrega de meses, fallos frecuentes en producción y un overhead operativo enorme. Waterfall, el modelo de SDLC secuencial con fases de análisis, diseño, desarrollo, testing e implementación una detrás de otra, era perfectamente adecuado para proyectos de ingeniería civil. Para software, era un desastre: los requerimientos cambiaban a mitad del ciclo y no había forma de pivotar sin tirar semanas de trabajo.
DevOps nació exactamente de esa frustración. No es una herramienta ni un cargo (el famoso “DevOps Engineer” que en realidad hace de todo). Es una filosofía que dice: desarrollo y operaciones trabajan juntos desde el día uno, con feedback loops continuos y responsabilidad compartida sobre lo que va a producción.
Waterfall, Agile y DevOps: la evolución del SDLC en números
Vale la pena poner los modelos en contexto antes de hablar de IA.
| Metodología | Características clave | Ciclo de entrega | Adopción 2026 |
|---|---|---|---|
| Waterfall | Fases secuenciales, sin retroceso | 6-18 meses | 37% |
| Agile | Iterativo, sprints de 2-4 semanas | Semanas | ~45% |
| DevOps | Continuo, CI/CD, cultura integrada | Horas a días | ~18% |
Waterfall tenía el 70% del mercado en 2015. A diez años de distancia, según el análisis publicado en mayo de 2026 por Anshuman Biswal, cayó al 37%. No desapareció, sigue teniendo sentido en contextos regulados o contratos de gobierno donde los requerimientos son fijos. Pero para productos digitales, ya es el modelo residual.
Agile resolvió la rigidez de Waterfall con iteraciones cortas. El problema: Agile solucionó el ciclo de desarrollo pero no el de operaciones. Podías deployar código cada dos semanas con Agile y seguir teniendo un equipo de ops que tardaba tres días en aprobar el cambio. Sobre eso hablamos en plataformas modernas de CI/CD.
DevOps cerró ese gap. La clave es el CI/CD: integración continua para detectar errores apenas se commitea código, y entrega continua para que el camino desde el commit hasta producción sea automático y confiable.
El ciclo DevOps moderno: más que herramientas
El error más común cuando alguien “implementa DevOps” en una empresa es empezar instalando Jenkins o configurando pipelines en GitHub Actions. Las herramientas son visibles y fáciles de vender internamente. La cultura es invisible y difícil de cambiar.
Un ciclo DevOps completo cubre ocho fases que se retroalimentan: plan, code, build, test, release, deploy, operate y monitor. Lo que distingue a un equipo DevOps maduro de uno que solo usa las herramientas es el feedback loop real: cuando monitoring detecta un problema, ese insight vuelve a la fase de plan. No queda atrapado en un ticket de ops que nadie lee.
La toolchain típica incluye Git para control de versiones, pipelines de CI/CD (GitHub Actions, GitLab CI), infraestructura como código con Terraform o Ansible, contenedores con Docker y orquestación con Kubernetes, y observabilidad con stacks de métricas, logs y trazas. Cualquiera que haya pasado por una migración a cloud sabe que la parte difícil no es aprender las herramientas: es convencer al equipo de que los cambios de infraestructura también van al repositorio como código.
DORA Metrics: lo que separa a los equipos élite del resto
¿Cómo sabés si tu equipo DevOps es bueno o solo parece bueno? Las métricas DORA de Atlassian son el estándar del sector: cuatro indicadores que miden rendimiento real de entrega de software.
- Deployment Frequency: con qué frecuencia deployás a producción. Élite: varias veces por hora. Bajo rendimiento: menos de una vez por mes.
- Lead Time for Changes: tiempo desde que un commit entra al repositorio hasta que está en producción. Élite: menos de 1 hora. Bajo rendimiento: más de 6 meses.
- Change Failure Rate: porcentaje de deployments que causan incidentes. Élite: menos del 5%. Bajo rendimiento: entre 46% y 60%.
- Time to Restore Service: cuánto tardás en recuperarte de un incidente. Élite: menos de 1 hora. Bajo rendimiento: más de 6 meses.
Los equipos de élite no deployean con más frecuencia porque son más valientes. Lo hacen porque tienen canary releases que exponen el cambio solo a un porcentaje del tráfico, feature toggles para activar funcionalidades sin deployar código nuevo, y rollback automático si las métricas caen. El riesgo por deployment es tan pequeño que la frecuencia alta se vuelve la estrategia de bajo riesgo. Esto se conecta con lo que analizamos en modelos de lenguaje avanzados.
IA entra a DevOps: qué es AIOps y cómo funciona
Ponele que tu sistema recibe un pico de tráfico a las 3 de la mañana. Los logs empiezan a mostrar latencias elevadas en el servicio de pagos, las métricas de CPU en tres microservicios diferentes se disparan casi al mismo tiempo, y hay un aumento de errores 5xx que todavía no afectó a usuarios pero va en esa dirección. ¿Cuántos humanos necesitás despiertes para correlacionar esos tres eventos y entender que vienen del mismo root cause?
AIOps resuelve exactamente eso. Según Red Hat, AIOps aplica machine learning y big data analytics a las operaciones de IT para automatizar la identificación y resolución de problemas comunes. No es que reemplaza al ingeniero de turno: es que maneja el 80% de los incidentes que antes lo despertaban a las 3 AM, y escala solo lo que realmente necesita un humano.
Las tres capacidades centrales de AIOps son:
- Detección de anomalías: identifica patrones inusuales en logs, métricas y eventos en tiempo real, sin umbrales fijos configurados a mano.
- Análisis de causa raíz: correlaciona eventos de múltiples fuentes para pinpoint el origen del problema, no solo los síntomas.
- Predicción proactiva: anticipa cuellos de botella antes de que afecten usuarios, basándose en patrones históricos.
Auto remediación: infraestructura que se arregla sola
La infraestructura autosanadora es el paso que más le cuesta creer a los equipos ops tradicionales. La lógica es: si el sistema puede detectar que un pod de Kubernetes está crasheando, sabe cuál es el playbook estándar para ese tipo de fallo, y tiene permisos para ejecutarlo, ¿para qué despertar a alguien?
El punto es que AIOps va más allá de automatización de runbooks. La automatización tradicional ejecuta scripts predefinidos cuando se cumplen condiciones fijas (“si CPU > 90%, reiniciar servicio”). AIOps usa ML para distinguir entre un pico de CPU que se va a resolver solo en 30 segundos y uno que es síntoma de un memory leak que va a crecer. El primer caso: ignorar. El segundo: ejecutar el playbook de diagnóstico y escalar si la anomalía persiste.
¿Y qué pasa cuando el sistema ejecuta una remediación equivocada? Es la pregunta que nadie quiere hacerse, pero es la que separa a los equipos que implementan AIOps bien de los que se mandan una cagada de producción automatizada. La respuesta correcta: empezar con remediaciones de bajo riesgo (reiniciar pods, ajustar scaling), con aprobación humana para cambios de mayor impacto, y auditoría completa de cada acción automática.
Los desafíos reales de implementar AIOps en una empresa
El 97% de las organizaciones quiere incorporar IA a sus operaciones de IT (datos de 2026). Solo el 2% tiene la infraestructura de datos y la madurez de procesos para hacerlo de forma que realmente funcione (y no solo en las demos para el directorio). Te puede servir nuestra cobertura de asistentes de IA para código.
La brecha es enorme y tiene causas concretas. AIOps necesita datos: logs estructurados, métricas históricas, trazas distribuidas. Si tu observabilidad actual es una mezcla de logs de texto libre, alertas de Nagios configuradas hace cinco años y un Excel de incidentes, el modelo de ML no tiene nada bueno para aprender. Garbage in, garbage out, pero a escala y automatizado.
La madurez de implementación tiene tres etapas claras:
- Etapa 1 — Identificación y notificación: el sistema detecta incidentes y alerta. Parece básico, pero el 60% de las empresas que “implementa AIOps” está solo acá, reduciendo el ruido de alertas con correlación simple.
- Etapa 2 — Predicción de fallos: análisis proactivo que identifica problemas antes de que ocurran. Requiere al menos 6-12 meses de datos históricos de buena calidad.
- Etapa 3 — Auto remediación: el sistema ejecuta acciones correctivas sin intervención humana. Acá está el 2% que llega de verdad.
Para equipos que están empezando a construir la base de infraestructura necesaria, el hosting y los servidores donde corre todo esto importan: donweb.com tiene opciones de cloud y VPS que encajan bien para equipos que quieren empezar a instrumentar observabilidad sin la complejidad de los hyperscalers.
El futuro: operaciones inteligentes y sistemas agentic
El cambio de paradigma más importante no es técnico: es pasar de operar en modo reactivo a modo predictivo. La ops tradicional es básicamente firefighting sofisticado. Alerta, diagnóstico, remediación, postmortem, repetir. AIOps interrumpe ese ciclo en el primer paso.
Lo que viene después son sistemas de IA agentic para operaciones: modelos que no solo detectan el problema sino que redactan el fix, lo proponen para revisión humana, y aprenden del feedback del equipo para mejorar la próxima sugerencia. La correlación de root causes entre cientos de microservicios, la optimización automática de costos de infraestructura basada en patrones de uso real, el healing de issues que antes requerían tres ingenieros y un postmortem de dos horas.
Dicho esto, habría que ver con pinzas las promesas más agresivas del sector. Los vendors de AIOps tienen un historial de overselling, y la frase “auto-healing infrastructure” en un deck de ventas puede significar desde Kubernetes reiniciando pods (automatización básica que existe desde 2015) hasta ML genuino que correlaciona causas raíz en tiempo real. La diferencia está en los datos, en la madurez del equipo, y en cuánto tiempo lleva el sistema operando antes de que las predicciones sean confiables.
Errores comunes al implementar DevOps y AIOps
Empezar por las herramientas en vez de la cultura
El error más caro: comprar licencias de una plataforma AIOps antes de tener los datos y procesos básicos. Sin logs estructurados, sin métricas históricas, sin runbooks documentados, el sistema de ML no tiene nada con qué trabajar. El resultado es una plataforma cara que genera falsos positivos y que el equipo ops termina ignorando. Relacionado: optimización técnica en desarrollo.
Medir DevOps con métricas de vanidad
Los equipos que reportan “deployamos 200 veces por mes” sin monitorear su Change Failure Rate están optimizando la métrica equivocada. Deployer más frecuente con un 30% de failure rate es peor que deployer una vez por semana con 2%. Las métricas DORA son un conjunto: si reportás solo las que te favorecen, no estás midiendo nada útil.
Saltear las etapas de madurez de AIOps
Querer llegar directo a auto remediación sin pasar por la etapa de identificación y correlación es como querer correr sin haber aprendido a caminar. Los modelos de ML necesitan datos de calidad, y los datos de calidad necesitan instrumentación básica que la mayoría de los equipos todavía no tiene. La etapa 1 puede llevar 6-12 meses. Es aburrida. Es necesaria.
Para profundizar en cómo cambió el DevOps, tenemos este análisis: From Waterfall to AIOps: The Evolution of DevOps and the Fut.
Para profundizar en esto, mirá nuestro artículo sobre From Waterfall to AIOps: The Evolution of DevOps and the Fut.
Preguntas Frecuentes
¿Qué es AIOps y cómo funciona?
AIOps es la aplicación de machine learning y análisis de big data a las operaciones de IT para automatizar detección, diagnóstico y resolución de problemas. Funciona ingiriendo en tiempo real datos de logs, métricas, eventos y trazas de múltiples fuentes, aplicando modelos de ML para identificar anomalías y correlacionar causas raíz, y ejecutando acciones correctivas automáticas cuando la confianza del modelo es suficiente.
¿Cuál es la diferencia entre DevOps y AIOps?
DevOps es una cultura y conjunto de prácticas que unifica desarrollo y operaciones para entregar software más rápido y confiable, con CI/CD, IaC y feedback loops continuos. AIOps extiende esas prácticas con inteligencia artificial: agrega capacidad predictiva y de auto remediación a la capa de operaciones. DevOps dice cómo trabajar juntos; AIOps dice cómo automatizar el trabajo de operaciones con ML.
¿Cómo pasar de Waterfall a DevOps y AIOps?
La transición tiene orden: primero Waterfall a Agile (sprints, releases frecuentes), luego Agile a DevOps (CI/CD, IaC, cultura de colaboración dev-ops), luego DevOps a AIOps (instrumentación de observabilidad, datos históricos, modelos de ML). Saltearse pasos genera deuda técnica y organizacional. El mínimo para empezar con AIOps es 6-12 meses de datos de calidad en logs, métricas y eventos.
¿Cuáles son los beneficios de implementar AIOps?
Los beneficios concretos son: reducción del MTTR (tiempo de restauración) de horas a minutos mediante auto remediación, reducción del ruido de alertas por correlación inteligente (equipos reportan eliminar entre 50% y 80% de alertas redundantes), y detección proactiva de problemas antes de que afecten usuarios. El beneficio más subestimado es el operacional: los ingenieros de turno dejan de ser firefighters de incidentes predecibles.
¿Qué son las métricas DORA y cómo miden los equipos élite?
Las métricas DORA son cuatro indicadores de rendimiento de entrega de software: Deployment Frequency, Lead Time for Changes, Change Failure Rate y Time to Restore Service. Un equipo de élite deploya varias veces por hora, tiene un lead time de menos de una hora, un Change Failure Rate menor al 5% y restaura servicios en menos de 60 minutos. Publicadas originalmente por el DORA Research Group y ahora parte del framework de métricas de DevOps de Google Cloud.
Conclusión
La evolución de Waterfall a AIOps no es una historia de tecnología: es una historia de cómo las organizaciones aprendieron, a fuerza de incidentes y proyectos fallidos, que la velocidad y la confiabilidad no son opuestas. DevOps demostró que podés deployar rápido si construís la cultura y los procesos correctos. AIOps agrega la capa de predicción que faltaba para que las operaciones escalen sin escalar el equipo de guardia.
En 2026 la pregunta ya no es si incorporar IA a las operaciones, sino en qué etapa de madurez está tu organización para hacerlo bien. Si todavía tenés logs sin estructurar y runbooks en la cabeza de dos personas, la prioridad no es una plataforma AIOps: es instrumentación básica y documentación. Esa base es lo que separa al 2% que llega a auto remediación real del 97% que compra la promesa y termina con una herramienta cara que nadie usa bien.