Saga patrón microservicios y los rollbacks de Cloudflare
Cloudflare anunció el 25 de junio de 2026 los saga rollbacks para Workflows: ahora podés declarar la lógica de compensación dentro de cada paso, así que si un paso falla, los anteriores se revierten solos. Resuelve el dolor clásico del patrón saga en microservicios, donde un paso ya commiteó cambios en un sistema externo y el siguiente se rompe.
En 30 segundos
- Qué cambió: Cloudflare Workflows soporta rollbacks declarativos desde el 25/06/2026, según el anuncio oficial.
- Cómo funciona: definís la compensación como un argumento dentro del paso, no en un tracker manual aparte.
- Qué problema ataca: el paso 2 falla pero el paso 1 ya movió plata o stock en otro sistema.
- No es magia: rollback no “deshace”, ejecuta una operación inversa nueva (un crédito que compensa el débito).
- Para quién: equipos que orquestan transacciones distribuidas sin querer un lock global tipo 2PC.
El patrón saga es una forma de manejar transacciones que tocan varios servicios sin usar una transacción única bloqueante. En vez de un commit atómico global, cada paso commitea local y, si algo falla más adelante, se disparan operaciones de compensación que revierten los pasos ya completados. Apunta a consistencia eventual, no a consistencia fuerte. Lo documenta microservices.io como uno de los patrones base de datos en microservicios.
¿Qué es el patrón Saga y cómo funcionan las transacciones distribuidas?
Ponele que tenés una operación que cruza tres servicios distintos, cada uno con su propia base de datos. En un monolito con una sola base eso sería una transacción ACID: o pasa todo o no pasa nada. En microservicios eso no existe, porque no podés abrir una transacción que abarque bases separadas sin pagar un costo enorme.
Ahí entra la saga. La idea es vieja (el paper original es de 1987, de Garcia-Molina y Salem) y simple: partís la transacción grande en una secuencia de transacciones locales. Cada una commitea en su servicio. Si la número 4 falla, no hay un “rollback” automático de las tres anteriores, porque ya commitearon. Lo que hacés es ejecutar, en orden inverso, una compensación por cada paso que sí salió bien.
El trade-off es claro. Ganás disponibilidad y evitás bloqueos globales. A cambio, durante un rato el sistema queda en un estado intermedio visible. Consistencia eventual, no fuerte. Esto se conecta con lo que analizamos en variables seguras en tus workers.
¿Por qué fallan las transacciones multi-paso sin lógica de compensación?
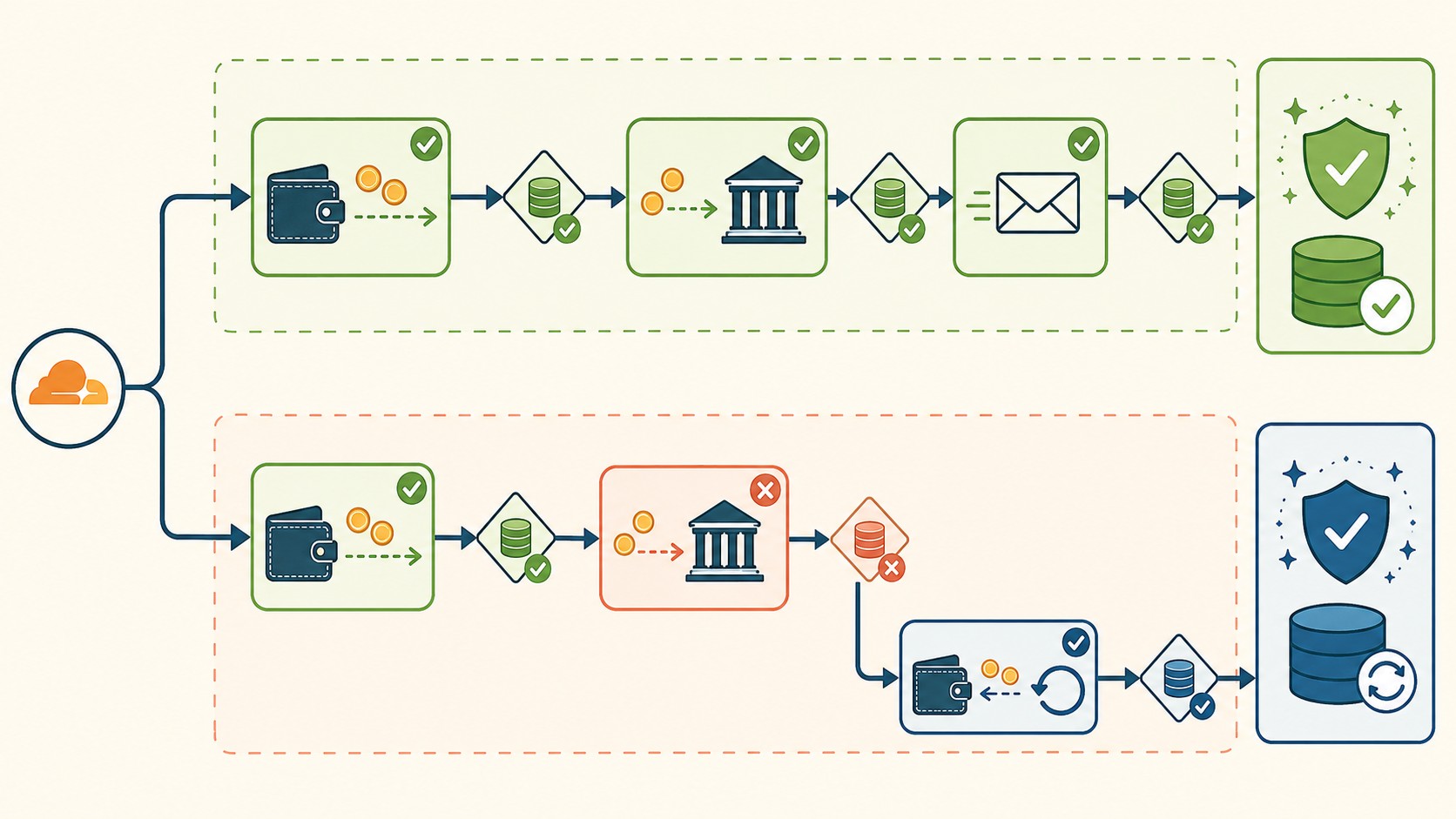
El ejemplo que usa Cloudflare en el anuncio oficial es el más didáctico que hay: una transferencia de plata entre cuentas de dos bancos distintos.
- Paso 1: debitar de la cuenta en el Banco A.
- Paso 2: acreditar en la cuenta del Banco B.
- Paso 3: mandar el mail de confirmación a los dos titulares.
¿Y si el paso 2 falla? La plata ya salió del Banco A. El débito se commiteó, la operación quedó firme en su sistema. Vos, como orquestador, no podés entrar al Banco A y “cancelar” lo que ya pasó. La única salida es una operación nueva que devuelva ese dinero a la cuenta original.
Sin lógica de compensación, esa plata desaparece en el limbo. El cliente ve menos saldo, el Banco B no recibió nada, y nadie reconcilió. Antes de este lanzamiento, según Cloudflare, los desarrolladores tenían que armar a mano el seguimiento de qué pasos salieron, cuáles fallaron y qué acciones disparar, todo por fuera de la definición de los pasos. Código frágil y fácil de olvidar.
¿Qué son las transacciones compensadas y cómo funcionan los rollbacks automáticos?
Una transacción compensada es la operación que revierte, en términos de negocio, el efecto de un paso ya completado. Lo importante es entender qué significa “en términos de negocio”. No es un ROLLBACK de SQL que borra el commit. Es una acción semántica inversa.
Si el paso fue “debitar 1000 pesos”, la compensación es “acreditar 1000 pesos”. Si el paso fue “reservar un asiento”, la compensación es “liberar el asiento”. Microsoft documenta este patrón como Compensating Transaction y aclara algo incómodo: a veces la compensación no deja el sistema exactamente como estaba. Si entre el débito y la compensación ocurrió otra operación, el saldo final puede diferir del inicial, aunque sea coherente.
Lo que aporta Cloudflare es que ahora declarás esa compensación pegada al paso. El runtime de Workflows lleva la cuenta de qué pasos commitearon y, ante una falla, ejecuta las compensaciones en orden inverso. Vos escribís el “qué deshacer”, el orquestador se encarga del “cuándo y en qué orden”. En opciones de almacenamiento duradero profundizamos sobre esto.
Saga vs Two-Phase Commit vs Event Sourcing: comparativa
| Estrategia | Consistencia | Bloqueos | Recovery | Cuándo usarla |
|---|---|---|---|---|
| Saga | Eventual | Sin lock global | Compensaciones inversas | Flujos largos entre servicios independientes |
| Two-Phase Commit (2PC) | Fuerte | Lock distribuido durante el commit | Coordinador decide abort/commit | Pocos participantes, baja latencia, todo bajo control |
| Event Sourcing | Eventual | Sin lock | Reproceso del log de eventos | Auditoría total y reconstrucción de estado |
El tema con 2PC es que necesita un coordinador y mantiene recursos bloqueados mientras espera el “sí” de todos. Si un participante se cuelga, el resto queda esperando. Por eso en arquitecturas distribuidas grandes casi nadie lo usa para flujos largos. La saga cambia ese bloqueo por compensaciones, y ahí está el quid del nuevo feature de Cloudflare.
¿Cómo implementa Cloudflare los rollbacks en Workflows?
Workflows ya te daba aplicaciones durables de varios pasos, con reintentos y persistencia de estado entre reinicios. Cada paso puede llamar sistemas externos y sobrevivir a una caída. Lo que faltaba era el camino de la falla.
Con el cambio del 25/06/2026, definís la lógica de compensación como un argumento dentro del paso mismo. Eso elimina el tracker manual: no llevás vos una lista de “qué hice y qué tengo que deshacer”. El propio Workflows registra los pasos exitosos y, cuando uno revienta, recorre hacia atrás ejecutando cada compensación declarada. Menos código de plomería, menos lugares donde meter la pata.
¿Cuáles son los desafíos al implementar sagas en producción?
Que el runtime te dé el andamiaje no te salva de los problemas difíciles. Hay cuatro que aparecen sí o sí. Más contexto en automatización del deployment moderno.
- Idempotencia obligatoria: si un reintento vuelve a disparar el mismo crédito, no podés acreditar dos veces. Cada operación y cada compensación necesita una clave de idempotencia.
- La compensación también falla: ¿qué pasa si el “devolver la plata” tira error? Necesitás reintentos, alertas y, en el peor caso, intervención manual con cola de muertos.
- No todo es reversible: mandar un mail no se “des-manda”. Para esos pasos, la compensación real es enviar otro mail aclaratorio, no borrar el anterior.
- Observabilidad: sin logs de qué pasó y qué se compensó, debuggear una saga rota es a ciegas.
La pregunta incómoda: ¿alguien verificó de forma independiente cuánto baja esto el código boilerplate? Todavía no. El dato sale del propio anuncio de Cloudflare, así que tomalo con pinzas hasta que aparezcan benchmarks de terceros.
Casos reales donde la saga con rollbacks es esencial
Más allá de la transferencia bancaria del ejemplo, hay tres escenarios donde esto se vuelve casi obligatorio.
Reservas de viaje combinadas
Reservás vuelo, después hotel, después auto. Si el hotel no tiene disponibilidad, ya tenés el vuelo pago. La compensación cancela el vuelo (con su política de reembolso, que es otra historia).
Órdenes ecommerce con varios vendors
Cobrás la tarjeta, reservás stock en el depósito de un vendor, generás el envío. Si el stock no estaba, compensás liberando la reserva y reembolsando el cobro. Sin esto, le cobraste a un cliente algo que no le vas a mandar. Tema relacionado: herramientas CI/CD para producción.
Aprovisionamiento de infraestructura
Si automatizás el alta de servicios en la nube o en un VPS (algo común cuando montás workflows sobre hosting como donweb.com), un alta a medias deja recursos colgados que igual te facturan. La compensación libera lo que ya se creó.
Errores comunes al usar sagas
- Suponer que rollback borra el commit: no lo hace. Si tu compensación asume que el dato anterior desapareció, vas a duplicar efectos. La compensación es una operación nueva.
- Olvidar la idempotencia: en sistemas con reintentos, ejecutar dos veces la misma compensación es el bug más caro. Siempre con clave única por operación.
- No planear la falla de la compensación: mucha gente diseña el camino feliz y el de error, pero no el error del error. Esa rama necesita alertas y cola manual.
Preguntas Frecuentes
¿Qué es el patrón saga en microservicios?
Es una secuencia de transacciones locales donde cada paso commitea en su propio servicio, y si uno falla se ejecutan operaciones de compensación que revierten los pasos previos. Apunta a consistencia eventual sin usar un bloqueo distribuido global.
¿Qué diferencia hay entre saga y two-phase commit?
El 2PC ofrece consistencia fuerte pero bloquea recursos durante el commit coordinado, lo que escala mal entre muchos servicios. La saga cambia esos bloqueos por compensaciones y acepta consistencia eventual, ganando disponibilidad.
¿Cuál es el nuevo feature de rollbacks en Cloudflare Workflows?
Desde el 25 de junio de 2026 podés declarar la lógica de compensación como argumento dentro de cada paso. El runtime registra los pasos exitosos y ejecuta las compensaciones en orden inverso si algo falla, sin tracking manual.
¿Cómo hacer rollbacks sin bloquear la base de datos?
No se hace un rollback de base, se ejecuta una operación inversa de negocio: un crédito que compensa un débito, una liberación que compensa una reserva. Así evitás locks distribuidos y mantenés cada servicio independiente.
¿Toda operación se puede compensar?
No. Acciones como enviar un email o publicar un mensaje no se deshacen. Para esos casos la compensación es una acción correctiva nueva, como un segundo mail aclaratorio, no la eliminación de la original.
Conclusión
Lo que cambió es concreto: la compensación deja de ser código suelto que vos mantenés y pasa a vivir pegada al paso, con el orquestador llevando la cuenta. Eso reduce la superficie de error en el camino que casi nadie testea bien, que es el de la falla.
Si ya usás Workflows para flujos de varios pasos contra sistemas externos, vale la pena migrar tu lógica de compensación manual al nuevo modelo declarativo. Eso sí: no te relajes con la idempotencia ni con el plan para cuando la compensación falle. El feature te da el andamiaje, el diseño de negocio sigue siendo tuyo.