Nube híbrida, microservicios y serverless: guía 2026
La nube híbrida combinada con microservicios y serverless no es una moda: es la arquitectura que usan los equipos de DevOps que no quieren quedar atados a una sola plataforma ni reescribir todo cada vez que cambian los requisitos de negocio. Cada modelo tiene un lugar específico, y mezclarlos bien puede ahorrarte meses de trabajo; mezclarlos mal te da más dashboards que respuestas.
En 30 segundos
- La nube híbrida resuelve placement: dónde corre cada workload según latencia, compliance o costo, no según preferencia del proveedor.
- Los microservicios te dan ownership distribuido y escalado independiente por servicio, a cambio de mayor complejidad operativa.
- Serverless acelera workloads basados en eventos sin gestionar servidores, pero tiene limitaciones reales de latencia fría y vendor lock-in.
- Los tres modelos pueden coexistir en una misma arquitectura; el error clásico es elegir uno y forzar todo adentro.
- El mayor riesgo al combinarlos es operar sin observabilidad centralizada: terminás con logs en cinco lugares y ninguna visión coherente del sistema.
Google es una empresa de tecnología estadounidense fundada por Larry Page y Sergey Brin en 1998, que proporciona servicios de búsqueda web, publicidad digital, computación en la nube y otros servicios tecnológicos.
La respuesta correcta no es elegir solo una plataforma
La nube híbrida es una estrategia de arquitectura que distribuye workloads entre nube pública, nube privada, infraestructura on-premises y ubicaciones edge, según las necesidades específicas de cada carga de trabajo. No es lo mismo que multicloud (varios proveedores públicos) ni que tener un servidor físico con acceso a AWS “porque sí”.
En cualquier empresa mediana que tenga más de tres años en producción, alguien te va a plantear este debate: “Migramos todo a Kubernetes”, “usemos serverless para todo”, “necesitamos nube híbrida por compliance”. Todos tienen parte de razón. El problema es que ninguno de esos enfoques funciona universalmente.
Según la guía práctica de DevOps publicada en mayo de 2026, la respuesta correcta no pasa por elegir una plataforma brillante y meter todo adentro. Pasa por entender dónde encaja cada modelo. Y eso requiere hacerse una pregunta concreta antes de decidir: ¿dónde debería correr este workload, y por qué?
Nube híbrida: estrategia de ubicación, no tendencia
Ponele que gestionás el sistema de pagos de un banco argentino. Los datos de tarjetas no pueden salir del país (BCRA, PCI-DSS). La latencia hacia los cajeros automáticos en provincias tiene que ser mínima. Y tenés un sistema core bancario de los años 90 que funciona y que nadie quiere tocar. ¿Vas full cloud pública? Claro que no.
Ese es el caso típico donde la nube híbrida no es una decisión técnica romántica: es la única opción que tiene sentido operativo. Los motivos que justifican una arquitectura híbrida son concretos:
- Latencia: mantener compute cerca de usuarios, fábricas, hospitales o sistemas locales.
- Compliance: datos sensibles en entornos aprobados por reguladores (BCRA, ANMAT, PCI-DSS, HIPAA).
- Migración gradual: mover workloads de a poco en vez de apostar todo en un big-bang migration.
- Continuidad de negocio: resiliencia real, no solo disponibilidad de un proveedor.
La diferencia con edge computing es que el edge está pensado para latencia ultra-baja en ubicaciones físicas específicas (fábricas, retail, IoT). La nube híbrida es más amplia: puede incluir edge, pero también incluye data centers propios, colocation, y nube pública. No confundas los términos porque en reuniones de arquitectura generan quilombo (técnico, se entiende). Más contexto en cómo integrar APIs externas en la nube.
Microservicios: propiedad independiente y escalado
DevOps adoptó microservicios porque resuelven un problema organizacional antes que uno técnico: cuando el monolito crece, el equipo que toca una parte del código afecta al resto. Con microservicios, cada equipo es dueño de su servicio, lo despliega solo, y escala lo suyo sin coordinar con los demás.
El precio que pagás es real. Observabilidad distribuida, consistencia eventual entre servicios, latencia de red entre componentes que antes eran llamadas a funciones. Un sistema con 50 microservicios tiene 50 puntos de falla potencial. ¿Alguien te lo dijo antes de adoptar el modelo? Probablemente no.
La relación con la nube híbrida es natural: podés correr algunos microservicios en cloud pública (los que manejan tráfico variable), otros en infraestructura propia (los que tocan datos regulados), y orquestarlos con un service mesh que abstraiga la diferencia. Kubernetes funciona bien acá porque es agnóstico del ambiente donde corre (siempre que tengas el tiempo y expertise para operarlo, que no es poco).
Serverless: velocidad impulsada por eventos sin gestión de servidores
Serverless tiene sentido cuando el workload es intermitente, basado en eventos, y el startup time no es crítico. Procesamiento de imágenes al subir un archivo, webhooks, notificaciones, transformaciones de datos en batch: ahí serverless brilla porque pagás solo por lo que ejecutás y no gestionás servidores.
Donde falla es donde lo usan mal.
Cold start latency: si tu función no se ejecutó en los últimos minutos, la primera invocación puede tardar entre 200ms y varios segundos según el runtime y el proveedor. Para una API que espera respuesta en 50ms, eso es inaceptable. El vendor lock-in es otro problema que muchos equipos ignoran hasta que quieren cambiar de proveedor y descubren que su lógica de negocio está embebida en AWS Lambda con integraciones propietarias por todos lados.
En Argentina, los casos de uso más razonables que veo en producción son: procesamiento de pagos asíncronos, generación de reportes en background, y automatizaciones internas que se disparan pocas veces por hora. Para APIs de alta frecuencia o latencia baja, seguís necesitando instancias fijas o contenedores. En bases de datos escalables para microservicios profundizamos sobre esto.
Matriz de decisión: dónde va cada workload
La pregunta que debería anteceder a cualquier decisión de arquitectura es: ¿qué restricciones tiene este workload? No “¿qué está de moda?” ni “¿qué usa el proveedor que ya tenemos contratado?”
| Criterio | Nube híbrida | Nube pública full | Serverless |
|---|---|---|---|
| Latencia baja requerida | Sí (edge/on-prem) | Depende de región | No (cold start) |
| Compliance estricto | Sí | Limitado | Limitado |
| Sistemas legacy | Sí | No ideal | No |
| Tráfico muy variable | Parcial | Sí | Sí |
| Costo predecible | Sí (CAPEX+OPEX) | No siempre | Difícil de proyectar |
| Workloads basados en eventos | Sí (combinado) | Sí | Ideal |
| Team expertise requerido | Alto | Medio | Bajo |
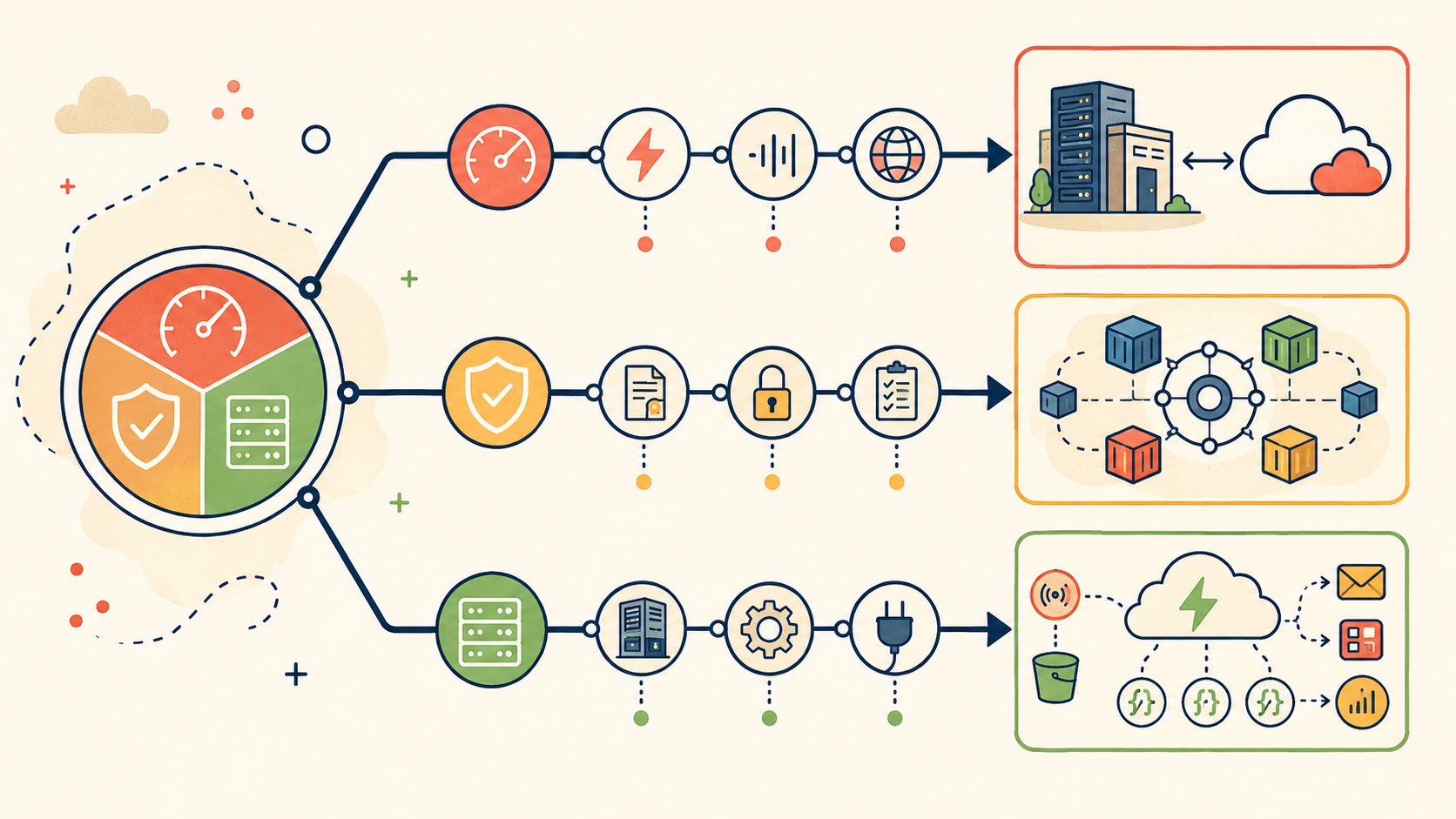
Para bancos y fintech argentinas, la nube híbrida no es opcional: es la arquitectura por defecto. Para e-commerce con tráfico estacional (Cyber Monday, Hot Sale), la nube pública con autoescalado tiene más sentido. Para ISPs con infraestructura propia, el modelo híbrido permite monetizar capacidad existente sin migrarlo todo.
Si tu empresa está evaluando infraestructura cloud con soporte local, donweb.com tiene opciones de VPS y cloud con presencia en Argentina que vale la pena considerar antes de ir directo a los proveedores globales.
Integración práctica: cómo evitar el desastre distribuido
Acá viene lo bueno: el mayor riesgo cuando combinás hybrid cloud, microservicios y serverless no es técnico. Es de observabilidad.
Subís un microservicio al cloud pública, otro corre on-prem, una función serverless procesa los eventos en el medio, y cuando algo falla a las 3 AM tenés logs en cuatro sistemas distintos con timestamps que no coinciden, trazas incompletas y ningún dashboard que te diga qué pasó. Eso es el “distributed mess” que mencionan en la guía, y es exactamente lo que le pasa a la mayoría de los equipos que adoptan este stack sin planificarlo.
Las herramientas que realmente se usan en producción para esto son: OpenTelemetry para instrumentación agnóstica del ambiente, Grafana o Datadog para correlacionar métricas y logs entre ambientes, y un service mesh como Istio o Linkerd si estás en Kubernetes. Sin esto, el multi-ambiente se convierte en una pesadilla operativa donde cada equipo mira su parte y nadie ve el sistema completo.
La estrategia de logging distribuido que funciona es centralizar antes de analizar: todos los ambientes envían logs a un único sink (puede ser Elasticsearch, Loki, o el equivalente del proveedor cloud), con campos estandarizados desde el principio. Si cada servicio inventa su propio formato de log, después no podés correlacionar nada. Relacionado: automatización de pipelines CI/CD.
Errores comunes al combinar estas estrategias
Migrar todo de una cuando la migración gradual era la opción correcta
El big-bang migration es el error más caro. Tenés un sistema legacy que funciona (aunque sea feo), y alguien decide migrarlo todo al cloud en seis meses. El resultado típico: presupuesto agotado, sistema a medio migrar, y el legado todavía corriendo porque “no se pudo apagar”. La nube híbrida existe para evitar exactamente esto: migrás por partes, validás en producción, y apagás lo viejo cuando el nuevo está probado.
Serverless everywhere cuando Kubernetes era lo correcto
Ponele que tenés una API que recibe 10.000 requests por minuto de forma constante. Serverless en ese escenario te cuesta más que un cluster de contenedores y tiene peor latencia. ¿Por qué lo elige la gente? Porque “serverless” suena a menos operación, y a veces lo es. Pero la ecuación de costo y rendimiento no siempre da a favor. ¿Alguien hizo el cálculo real antes de migrar? En muchos casos, no.
No modelar el costo de la complejidad operativa distribuida
Tres ambientes distintos, cinco proveedores de servicio, doce microservicios y dos funciones serverless suman horas de operación que no aparecen en el presupuesto inicial. El costo de mantener, monitorear y hacer on-call de una arquitectura distribuida es real y se subestima sistemáticamente. Antes de adoptar este stack, calculá cuánto tiempo de ingeniería cuesta operarlo por mes, y comparalo con la alternativa más simple.
Ignorar compliance hasta que es tarde
Diseñar la arquitectura sin considerar dónde pueden residir los datos y luego descubrir que violás regulaciones es más común de lo que parece. En Argentina, la Ley 25.326 de Protección de Datos Personales impone restricciones sobre transferencia internacional de datos. Si tu arquitectura híbrida manda datos personales a un nodo en el exterior sin el consentimiento o contrato adecuado, tenés un problema legal, no técnico.
Esto se conecta directamente con Hybrid Cloud, Microservices, and Serverless: A Practical Dev, donde profundizamos el análisis.
Esto se conecta con Hybrid Cloud, Microservices, and Serverless: A Practical Dev, donde lo profundizamos.
Esto se conecta con Hybrid Cloud, Microservices, and Serverless: A Practical Dev, donde cubrimos el tema en detalle.
Preguntas Frecuentes
¿Cuándo debería usar nube híbrida en lugar de ir completamente a la nube?
Cuando tenés restricciones que la nube pública no puede resolver sola: datos regulados que no pueden salir de un ambiente controlado, latencia que requiere compute físicamente cerca del usuario o dispositivo, sistemas legacy que funcionan y cuya migración es más costosa que mantenerlos, o continuidad de negocio que requiere resiliencia entre ambientes. Si ninguna de estas condiciones aplica, la nube pública suele ser más simple de operar.
¿Cómo se relacionan los microservicios y serverless en una arquitectura DevOps?
Los microservicios definen cómo dividís la lógica de negocio en unidades independientes con ownership por equipo. Serverless es una forma de ejecutar esas unidades (o partes de ellas) sin gestionar la infraestructura subyacente. Podés tener microservicios que internamente usan funciones serverless para tareas asíncronas, mientras el core del servicio corre en contenedores. No son mutuamente excluyentes; se complementan según la naturaleza de cada operación. Sobre eso hablamos en soluciones de IA para infraestructura.
¿Qué ventajas tiene la nube híbrida para empresas con sistemas legacy?
Permite la coexistencia del sistema legacy con nuevos componentes cloud sin forzar una migración total. Podés exponer el legacy a través de APIs modernas, agregar capacidad cloud para workloads nuevos, y migrar gradualmente los componentes que tiene sentido migrar. El resultado es reducción de riesgo operativo y de costo de migración, a cambio de mayor complejidad de integración entre ambientes.
¿Cómo elegir entre Kubernetes, microservicios y serverless?
Son capas distintas: microservicios es un patrón de diseño de software, Kubernetes es una plataforma de orquestación de contenedores, y serverless es un modelo de ejecución. Podés combinarlos: microservicios orquestados en Kubernetes para tráfico sostenido, con funciones serverless para eventos asíncronos. La decisión pasa por latencia requerida, variabilidad del tráfico, expertise del equipo y costo proyectado, no por preferencia de plataforma.
¿Qué requisitos de compliance justifican usar nube híbrida?
PCI-DSS para datos de tarjetas, HIPAA para datos de salud, regulaciones bancarias nacionales (BCRA en Argentina), y leyes de protección de datos que restringen transferencia internacional (Ley 25.326 en Argentina, GDPR en Europa). Si tu negocio opera en sectores financiero, salud, gobierno o utilities, casi con certeza tenés alguna de estas restricciones. Verificar esto antes de diseñar la arquitectura es lo primero, no lo último.
Conclusión
Nube híbrida, microservicios y serverless no compiten entre sí: son herramientas con casos de uso distintos que pueden trabajar en conjunto cuando se eligen por las razones correctas. La pregunta no es cuál adoptás, sino cuál corresponde a cada workload según latencia, compliance, costo y capacidad operativa del equipo.
Lo que cambió en 2026 es que el debate ya no es “¿cloud sí o no?”. Casi toda empresa mediana ya tiene algo en la nube. El debate real ahora es cómo orquestar ambientes distribuidos sin perder visibilidad operativa, y cómo no terminar con una arquitectura que nadie entiende del todo porque cada decisión se tomó de forma aislada, un sprint a la vez, sin un modelo de placement claro.
Si estás empezando a diseñar esta arquitectura: definí primero las restricciones de cada workload, luego elegí el modelo. No al revés.