Estrategias de despliegue: guía sin humo para devs en 2026
Si alguna vez viste cómo un deploy en producción te tira abajo la app un viernes a las 18:00, ya sabés que “pushear y rezar” no es una estrategia. Las estrategias de despliegue existen justamente para eso: para que no juegues a la ruleta rusa con tus usuarios cada vez que sale una versión nueva. Hoy en día, con la cantidad de equipos que corren en Kubernetes y Cloud Run, tener clara la diferencia entre un rolling update y un canary no es un lujo — es lo que separa un release tranquilo de una madrugada de guardia que preferirías olvidar.
En 30 segundos
- El canary deployment manda la versión nueva a un 5-20% de usuarios reales, monitoreás métricas y si todo anda bien expandís; si no, cortás antes de que el desastre sea masivo.
- El rolling update reemplaza pods de a uno, sin duplicar infraestructura, pero no tenés un stack viejo corriendo en paralelo — el rollback es posible, aunque no instantáneo.
- El blue-green deployment mantiene dos entornos completos (blue y green) y cambiás el tráfico de uno a otro en segundos; rollback también en segundos, pero te sale el doble mientras hacés el switch.
- Ninguna estrategia sirve sin puertas de validación automáticas: si frenás el deploy a ojo en vez de por umbrales de latencia o tasa de error 5xx, estás haciendo teatro.
Una estrategia de despliegue es el plan estructurado que define cómo, cuándo y con qué nivel de exposición el código nuevo llega a producción — y qué tan rápido podés volver atrás si algo sale mal. Según Keploy, la estrategia correcta no se elige una sola vez al inicio del proyecto; se ajusta según el tipo de cambio, la infraestructura y el apetito de riesgo del equipo.
¿Cuándo usar una estrategia de despliegue canary?
Ponele que armaste una feature nueva que toca el flujo de pagos. Estás confiado, los tests pasaron, pero no tenés forma de saber cómo se va a comportar con tráfico real. Ahí es donde el canary brilla: mandás la versión nueva a un porcentaje chico de usuarios — típicamente entre 5% y 20% — mientras el resto sigue con la versión estable.
Podés definir una progresión de porcentajes para targets como Cloud Run: arrancar con 5%, monitorear latencia y tasa de error durante diez minutos, y si las métricas se mantienen dentro de los umbrales que definiste, subir automáticamente a 20%, después a 50% y finalmente a 100%. Si algo se desvía — ponele que el p99 de latencia se dispara — la puerta de validación frena el avance sin intervención humana. Esa automatización es la diferencia entre un canary posta y lo que en la industria llamamos “teatro de canary” (sí, en serio, se usa esa expresión).
Lo interesante es que el impacto de un error está acotado desde el minuto cero: si tu versión nueva rompe algo, afecta solo a ese 5% inicial. Compará eso con un deploy “big bang” donde el 100% de los usuarios se comen el problema de golpe. El canary no te garantiza que no haya bugs — te garantiza que cuando aparezcan, el radio de explosión es chico. Y eso, en producción, es un golazo.
¿Qué diferencia hay entre rolling update y blue-green deployment?
Acá se arma la confusión clásica. Los dos buscan cero downtime, pero funcionan con lógicas opuestas y tienen costos distintos. Vamos por partes. Para más detalles técnicos, mirá cómo integrar la API de Gemini.
El rolling update es la estrategia por defecto en Kubernetes. Actualiza los pods de a uno, reemplazando instancias viejas por nuevas de manera gradual. Vos configurás dos parámetros: maxUnavailable (cuántos pods pueden estar caídos durante el proceso) y maxSurge (cuántos pods extra puede crear temporalmente). Mientras se ejecuta, hay un momento donde conviven pods viejos y nuevos sirviendo tráfico. El tema es que no tenés un “stack viejo” completo corriendo en paralelo — si necesitás rollback, Kubernetes reinicia el proceso en reversa, pero toma su tiempo.
El blue-green deployment es otra historia: mantenés dos entornos completos, blue (actual) y green (nuevo). Preparás todo en green, hacés pruebas, y cuando estás listo cambiás el tráfico de blue a green de un saque. ¿Rollback? Volvés a apuntar el tráfico a blue y listo — instantáneo. La contra obvia es que necesitás el doble de recursos mientras hacés el switch (no permanentemente, ojo, solo durante la ventana de despliegue).
El punto es que si estás corriendo una app grande, duplicar la infraestructura aunque sea por diez minutos puede doler en la factura de cloud, y ahí tenés que evaluar si el rollback instantáneo justifica el costo extra. Para muchos equipos no lo justifica; para los que manejan transacciones financieras o datos de salud, probablemente sí.
¿Cómo implementar un canary deployment en Kubernetes?
No alcanza con tener dos Deployments y esperar que la magia ocurra. La implementación seria de un canary en Kubernetes pasa por un service mesh (Istio, Linkerd) o por herramientas como Argo Rollouts que manejan el enrutamiento de tráfico con peso porcentual. La idea es sencilla: definís un segundo Deployment con la versión nueva y configurás el tráfico para que solo un porcentaje llegue a esos pods.
Un canary mínimamente decente arranca con 5%, monitorea por un intervalo definido, y si las métricas de latencia, throughput y tasa de error 5xx se mantienen dentro de lo esperado, escala a 20% y después a producción completa. Cada paso está atado a una puerta de validación automática: umbrales que, si se cruzan, frenan el despliegue sin que nadie tenga que estar mirando un dashboard a las 3 AM. Relacionado: nuestra comparativa de CI/CD en 2026.
¿Y si no tenés puertas automáticas? Entonces lo que estás haciendo — y perdoname la franqueza — es teatro. Estás mandando tráfico a una versión nueva y esperando que alguien se dé cuenta si algo falla. Eso no es ingeniería, es wishful thinking con pasos extra. La diferencia entre un canary automatizado y uno “a ojo” es la misma que entre un airbag y un cartel que dice “cuidado con el choque”.
Algunas plataformas permiten definir la progresión de porcentajes y las puertas de validación en un solo archivo de configuración, con integración nativa para disparar rollbacks automáticos.
¿Qué estrategia de despliegue elegir según el riesgo del cambio?
No existe la estrategia universal. Lo que funciona para un fix de padding en CSS no funciona para una migración de base de datos. La decisión se toma en función del riesgo que estás dispuesto a asumir y del tiempo de recuperación que podés tolerar. Acá va un criterio que suelo usar y que, según la publicación de Keploy, varios equipos adoptan:
- Cambios de bajo riesgo (fixes, ajustes de UI, copys): Rolling update. Es rápido, no duplica recursos, y si algo sale mal el rollback toma unos minutos — aceptable para este perfil de cambio.
- Cambios de riesgo medio (features nuevas acotadas, mejoras de performance): Canary. Exponés gradualmente y tenés margen para cortar antes del desastre.
- Cambios de alto riesgo (migraciones de esquema, refactors de servicios core, cambios en autenticación): Blue-green. Rollback instantáneo, y podés probar el entorno green a fondo antes del switch.
- Cambios incompatibles con versión anterior (breaking changes que no pueden coexistir): Recreate. Downtime planificado, se tira todo abajo y se levanta de nuevo. Es la opción menos elegante, pero hay veces que es la única posible.
El matiz importante — y que muchos equipos ignoran — es que la estrategia se elige por cambio, no por proyecto. Podés usar rolling para el 80% de los deploys, blue-green para los de alto riesgo, y canary para experimentos. No te cases con una sola.
¿Cuáles son los elementos no negociables en un despliegue seguro?
Hay cosas que, si no las tenés, da igual qué estrategia elijas porque el resultado va a ser el mismo: vas a rezar y eventualmente el desastre va a llegar. Estos son los cuatro pilares que, a esta altura de 2026, deberían ser línea de base en cualquier equipo:
- Tests automatizados en el pipeline: Si tu CI no tiene una suite que corra antes del deploy y que realmente valide comportamiento, no estás haciendo deploy, estás haciendo apuestas.
- Métricas monitoreadas en tiempo real: Latencia, tasa de error 5xx, throughput, uso de CPU/memoria. Sin visibilidad, estás ciego. Y desplegar a ciegas es — ya sabés — ruleta rusa.
- Puertas de validación automáticas: Acá está el meollo. No alcanza con que una persona “revise” un dashboard. La puerta debe ser un threshold definido (ej: “si el error rate supera el 1% durante más de 60 segundos, frená el avance”). Automático, no opinable.
- Circuit breakers: Si un servicio downstream empieza a fallar, el circuit breaker corta el tráfico antes de que el fallo se propague en cadena. Parece obvio, pero la cantidad de equipos que descubren esto después de un incidente es notable.
La diferencia entre una puerta manual y una automática es lo que separa la ingeniería de producción del voluntariado. Si tu canary avanza porque “Fede dijo que las métricas están bien”, no tenés un proceso, tenés un Fede. Y Fede se toma vacaciones. Ya lo cubrimos antes en la guía de Cloud SQL PostgreSQL con precios.
¿Cómo funcionan los rollbacks en cada estrategia?
Porque al final lo que importa no es cómo deployás, sino qué tan rápido podés des-deployar cuando las papas queman. Cada estrategia tiene su propia curva de recuperación, y no todas son igual de indulgentes:
| Estrategia | Tiempo de rollback | Impacto durante el rollback | Complejidad |
|---|---|---|---|
| Rolling | Minutos (reversión gradual de pods) | Bajo — usuarios en pods viejos no se ven afectados | Baja |
| Blue-green | Segundos (cambio de tráfico al stack viejo) | Ninguno — el entorno blue sigue intacto | Media |
| Canary | Segundos a minutos (cortar tráfico a la versión nueva) | Limitado al % de usuarios en canary | Alta |
| Recreate | Minutos (redeploy completo de versión anterior) | Downtime total durante el redeploy | Baja |
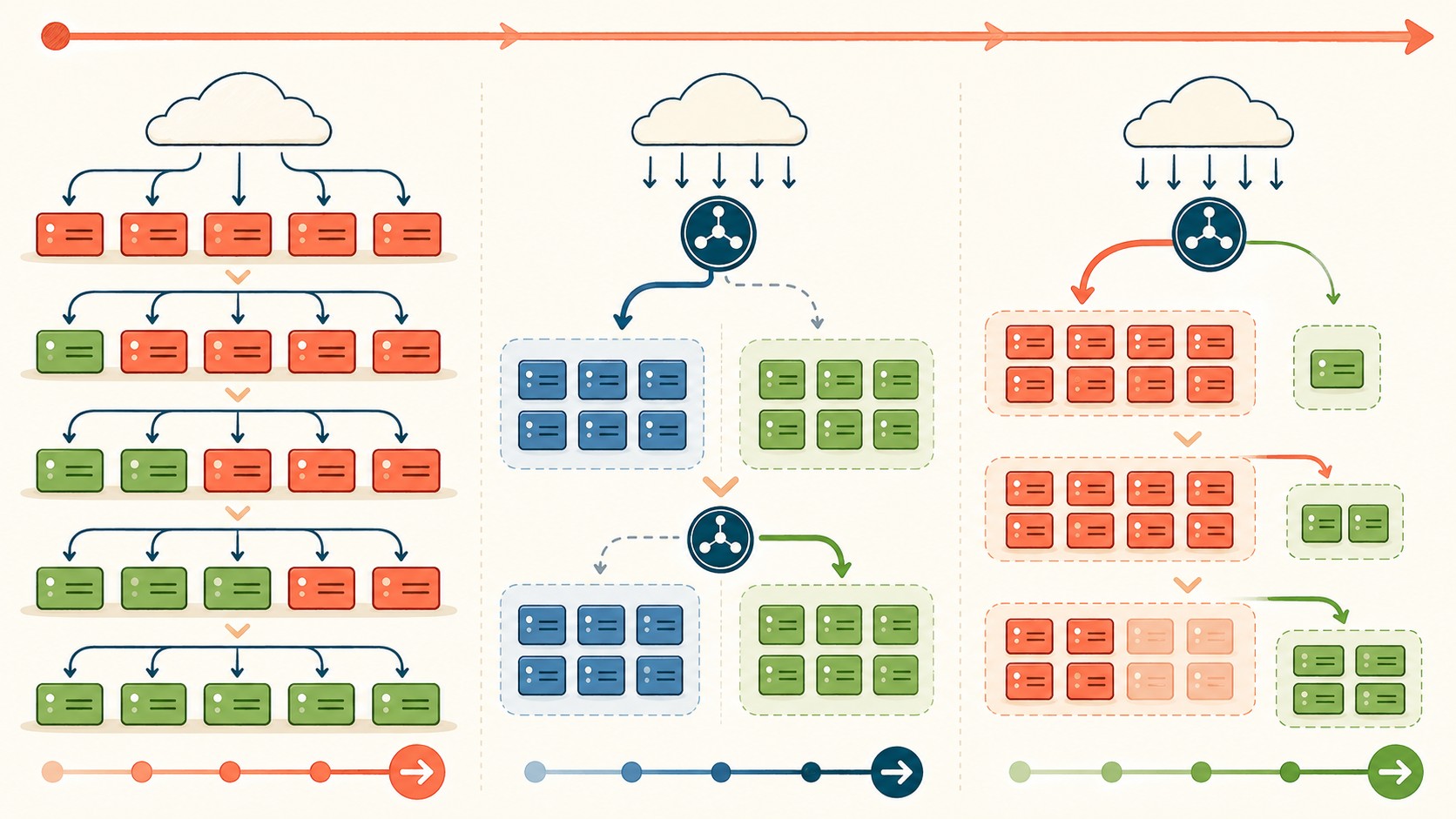
En plataformas de despliegue gestionadas, la restauración y cancelación están soportadas de manera nativa. Si un release en progreso se descontrola, podés cancelarlo y la plataforma maneja el rollback automáticamente según la estrategia configurada. En Kubernetes, con rolling update, un kubectl rollout undo inicia la reversión — pero acordate que no es instantáneo, porque los pods se reemplazan uno por uno de nuevo.
¿Qué errores comunes se cometen al implementar estas estrategias?
Después de ver equipos pasarse a estrategias “avanzadas” y terminar peor que cuando hacían deploys a manopla, armé esta lista de las cagadas más frecuentes. Para que no las repitas vos.
- Confundir canary con rolling: he visto equipos que dicen “hacemos canary” y lo que hacen es un rolling update de a un pod, sin service mesh, sin porcentajes, sin nada. Eso es un rolling más lento, no un canary. El canary requiere enrutamiento por peso, no simple reemplazo secuencial.
- Creer que blue-green siempre cuesta el doble: solo necesitás el doble de infraestructura durante la ventana de despliegue. Una vez que el tráfico migró a green, blue se puede apagar. No es un costo permanente, y aun así mucha gente descarta blue-green “por caro” sin haber hecho la cuenta real.
- Usar recreate sin considerar el downtime: si tu app tolera cinco minutos de piso, recreate es simple y efectivo. Pero si la usan usuarios en producción las 24 horas, hacer un recreate sin ventana de mantenimiento es un error de novato. Y sí, en 2026 todavía pasa.
- No automatizar las puertas de validación: ya lo dije, pero insisto porque es el error más grave y el más común. Tener un canary con validación manual es como tener un detector de humo que en vez de sonar, te manda un Slack para que vos decidas si hay incendio.
- Usar la misma estrategia para todos los cambios: tratar un cambio de CSS igual que una migración de base de datos no es “consistencia”, es falta de criterio.
Preguntas Frecuentes
¿Qué son las estrategias de despliegue y por qué son importantes?
Son los enfoques estructurados que un equipo usa para llevar código a producción, definiendo cuánta exposición tiene la versión nueva y qué tan rápido se puede volver atrás. Son importantes porque sin una estrategia, cada deploy es una apuesta: podés tener cero downtime o podés tirar abajo la app sin red de contención.
¿Cuándo usar canary deployment en lugar de blue-green?
Usá canary cuando querés validar una versión nueva con tráfico real pero reduciendo el riesgo al mínimo — ideal para features experimentales o cambios con incertidumbre sobre su comportamiento en producción. Blue-green es mejor cuando necesitás rollback instantáneo y el costo de duplicar infraestructura temporalmente está justificado, como en cambios de alto impacto tipo migraciones de esquema. Complementá con el análisis de Jenkins vs GitHub Actions.
¿Cómo funciona un rolling update en Kubernetes?
Es la estrategia por defecto: Kubernetes reemplaza los pods viejos por nuevos de manera gradual, usando los parámetros maxUnavailable y maxSurge para controlar cuántos pods pueden estar fuera de servicio y cuántos extra se crean durante el proceso. No requiere infraestructura adicional, pero el rollback no es instantáneo porque los pods se revierten uno a uno.
¿Qué desventajas tiene blue-green deployment?
La principal es que necesitás el doble de infraestructura durante la ventana de despliegue, lo que puede impactar en costos si tu app consume muchos recursos. También suma complejidad operativa: tenés que mantener dos entornos, asegurar que las bases de datos sean compatibles con ambas versiones durante el switch, y manejar sesiones de usuario que pueden quedar repartidas entre blue y green.
¿Se puede hacer un rollback rápido con canary?
Sí, cortar el tráfico a la versión canary toma segundos si tenés un service mesh o el enrutamiento bien configurado. El impacto durante el rollback está limitado al porcentaje de usuarios que estaban en el canary — típicamente entre 5% y 20% — así que aunque no sea instantáneo como en blue-green, el daño está acotado desde el diseño.
Conclusión
Hoy en día, con herramientas como Cloud Deploy, Argo Rollouts y los service mesh maduros que tenemos, no hay excusa técnica para seguir deployando a ciegas. La diferencia entre un equipo que duerme tranquilo y uno que vive con el cagazo del deploy del viernes no está en la herramienta que usan — está en si automatizaron las puertas de validación o si siguen confiando en que alguien va a mirar el dashboard a tiempo.
Elegí la estrategia según el cambio, no según el proyecto. Automatizá los rollbacks antes de necesitarlos. Y por favor, no le digas “canary” a un rolling update lento. Si tu deploy no tiene thresholds que lo frenen solos cuando las métricas se disparan, lo que tenés es un release con suerte, no una estrategia.
Si estás buscando dónde correr estos deploys con infraestructura en Argentina, donweb.com tiene opciones de cloud y VPS que se integran bien con pipelines de CI/CD. Pero la infraestructura es lo de menos — lo importante es que cuando configures tu primer canary posta, duermas tranquilo porque sabés que si algo explota, se frena solo.
Fuentes
- Keploy – Deployment Strategies Every Developer Should Know — Publicación con análisis detallado de estrategias.
- Google Cloud Deploy – Estrategias de despliegue — Documentación oficial de Google Cloud sobre configuración de canary, blue-green y rolling.
- DonWeb News – Estrategias de deployment: Blue-Green, Canary y Rolling — Artículo en español con ejemplos y comparativas.