Tu rate limiter no protege tus datos: el caso del pasaporte
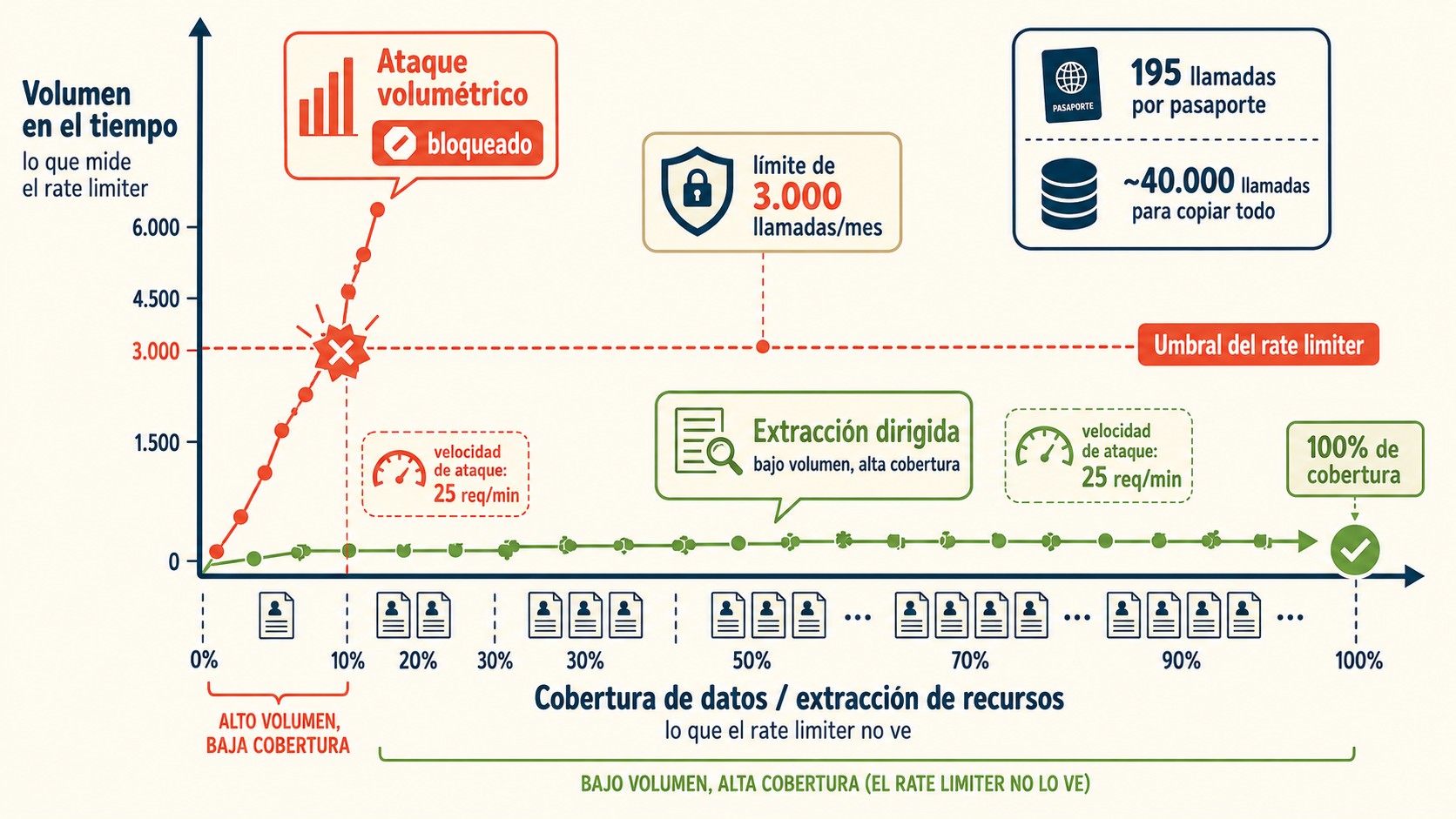
Un bot copió el 100% de los datos de un pasaporte desde una API de visas en pocos minutos, y el rate limiter (3.000 llamadas por mes en el plan gratis) nunca se activó. La moraleja es incómoda: tu rate limiter no es seguridad. Limita el costo de tu infraestructura, no protege tus datos. Son dos problemas distintos.
El rate limiting es un mecanismo que restringe cuántas solicitudes puede hacer un cliente por unidad de tiempo, por ejemplo 3.000 llamadas por mes o 100 por minuto. Sirve para controlar el gasto de servidores y frenar picos de tráfico. No verifica qué datos extrae un cliente ni con qué patrón, así que no detiene una extracción dirigida y de bajo volumen. Ese es todo el problema.
En 30 segundos
- Un pasaporte completo son ~195 llamadas. Muy por debajo del límite de 3.000/mes, así que el rate limiter jamás se disparó.
- El scraper corría a ~25 req/min. Carga trivial, invisible en cualquier gráfico de tráfico.
- Copiar toda la base habría requerido ~40.000 llamadas. Repartidas en unas pocas cuentas gratis, indetectables por límite de clave.
- El volumen es el eje equivocado. Los ejes correctos son identidad, cobertura y forma del acceso.
- La defensa real es en capas: registrar la IP, limitar por recurso (no por request) y detectar patrones.
Cloudflare es una plataforma de seguridad web y CDN fundada en 2010 que proporciona servicios de aceleración, protección DDoS y control de tráfico para sitios web. Opera una red global de servidores para distribuir contenido, aplicar políticas de seguridad y limitar el acceso de acuerdo a reglas definidas.
¿Por qué el rate limiting no bloquea la extracción de datos?
Un rate limiter responde una sola pregunta: ¿este cliente me está costando demasiado por unidad de tiempo? La extracción dirigida está diseñada justamente para quedarse por debajo de esa línea. En el caso que documentó Mathis Higuinen, el scraper pedía datos a ~25 solicitudes por minuto. Nada. Un usuario real navegando genera más ruido que eso.
Ponele que tu API cobra por llamada y ponés un tope de 3.000 mensuales para no fundirte. Suena prudente. Pero si un solo registro valioso (un pasaporte entero, un perfil de cliente, una ficha médica) se arma con menos de 200 llamadas, el atacante entra, saca lo que quiere y se va sin rozar el límite. ¿Alguien lo notó en los gráficos de tráfico? No, porque no hubo pico.
Y acá viene lo bueno: si repartís esas 40.000 llamadas necesarias para clonar toda la base entre cinco o seis cuentas gratuitas, cada clave individual queda muy por debajo de su cupo. El límite por clave no ve el ataque porque el ataque nunca vive en una sola clave. Lo explicamos a fondo en gestión segura de credenciales.
¿Cuál es la diferencia entre proteger infraestructura y proteger datos?
Son dos ejes que no se cruzan. El rate limiting trabaja sobre el eje del tiempo: cuánto me cuesta este cliente ahora. La extracción trabaja sobre el eje de los datos: cuánto de mi base logra tocar antes de que lo frene.
El autor lo resume en tres ejes que sí importan cuando querés proteger información: identidad (quién es el cliente de verdad, más allá de la API key), cobertura (cuántos recursos distintos toca) y forma (con qué patrón los pide). El volumen no aparece en ninguno. Por eso confundir “tengo límites restrictivos” con “estoy seguro” es el error que hace que un builder solitario filtre su activo más valioso.
Defensa 1: ¿cómo registrar la IP real detrás de Cloudflare?
Lo primero que lo mordió: podía deshabilitar la API key del atacante, pero no había guardado la IP de origen. ¿Resultado? Volver a registrarse era gratis (sí, gratis). Cortás una clave, aparece otra en dos minutos.
La solución es loguear la red, no solo la clave. Si estás detrás de un proxy o CDN, la IP que ves en el borde no es la del cliente real. En Cloudflare tenés que leer el header CF-Connecting-IP (o validar con cuidado X-Forwarded-For), nunca confiar en la IP del edge. Con la IP real guardada, un reincidente pasa a ser bloqueable a nivel de red y podés alimentar directo una regla de firewall. Más contexto en control real de acceso a recursos.
Si tu API corre en un VPS o hosting administrado (por ejemplo los de donweb.com), podés sumar además reglas a nivel de servidor o de Nginx para cortar rangos abusivos antes de que la request llegue a tu aplicación. Cuantas más capas, mejor.
Defensa 2: ¿cómo limitar por recurso en lugar de por volumen?
Este es el cambio de mentalidad más importante. En vez de “N solicitudes por mes”, contás “N destinos distintos por pasaporte por día”. La diferencia parece sutil y es enorme.
Fijate el patrón: un usuario legítimo chequea los requisitos de visa de su propio pasaporte para un puñado de destinos, capaz cinco países antes de un viaje. Un scraper quiere absolutamente todos los destinos (195 y contando). Entonces, si un mismo pasaporte empieza a pedir 40, 80, 150 destinos en un día, no importa cuán lento venga: ya sabés que no es un turista planificando vacaciones.
El tope deja de medir carga y pasa a medir intención. Es la misma idea aplicable a cualquier API: cantidad de clientes distintos consultados por vendedor, cantidad de historias clínicas abiertas por profesional, cantidad de perfiles vistos por cuenta. La “seguridad” del plan gratis no está en el número total, está en cuánta cobertura permitís por identidad.
¿Cómo combinar las defensas en capas?
Ninguna capa alcanza sola. El rate limiting sigue siendo útil para lo suyo (que no es poco): evitar que te vacíen la billetera con un pico de tráfico. Lo que hay que hacer es sumarle las otras tres. Acá la comparación directa. Sobre eso hablamos en limitar ejecuciones de forma segura.
| Capa | Eje que cubre | Qué frena | Qué NO frena |
|---|---|---|---|
| Rate limiting | Volumen / tiempo | Picos de costo, abuso masivo | Extracción lenta y dirigida |
| Log de red (IP real) | Identidad | Reincidentes, re-signup gratis | Rotación por proxies/cuentas |
| Límite por recurso | Cobertura | Barrido de toda la base | Un registro único puntual |
| Detección de patrones | Forma | IDs secuenciales, timing raro | Acceso humano legítimo |
Sobre la última fila: las señales de “forma” son las que atrapan al scraper prolijo. IDs consultados en secuencia (1, 2, 3, 4…), destinos impredecibles para un humano, timing demasiado regular, correlación entre requests que un usuario real jamás haría. Subís el modelo mental de “cuánto pide” a “cómo pide”, y el atacante que era invisible en los gráficos de volumen empieza a dejar huellas que sí podés alertar.
Errores comunes al asumir el rate limiting como seguridad
- “Mis límites son restrictivos, así que estoy protegido.” El límite mide costo, no exposición de datos. Un registro valioso puede caber en menos de 200 llamadas y quedar muy por debajo de tu tope.
- “Si no hay picos de tráfico, no hay ataque.” La extracción dirigida corre a ritmo bajo a propósito. El daño no se ve en el gráfico de volumen, se ve en la cobertura.
- “Cloudflare me cubre todo.” El CDN te protege del borde, pero si no guardás la
CF-Connecting-IPreal, no podés bloquear a un reincidente ni alimentar una regla de firewall. - “Deshabilito la API key y listo.” Sin la IP registrada, el atacante se re-registra gratis. Cortás la clave, no cortás la persona.
Preguntas Frecuentes
¿Es el rate limiting suficiente para proteger mi API?
No. El rate limiting protege el costo de tu infraestructura frente a picos de tráfico, pero no impide que un cliente extraiga datos de a poco sin superar el límite. Para proteger información necesitás sumar registro de identidad, límites por recurso y detección de patrones.
¿Por qué un bot extrajo datos con el rate limiting activo?
Porque cada registro valioso costaba pocas llamadas (un pasaporte completo son ~195) y el scraper corría a ~25 req/min, muy debajo del tope de 3.000 mensuales. El límite nunca se disparó porque el ataque estaba diseñado para quedarse por debajo de esa línea.
¿Cómo me protejo contra scraping si respeta mis límites?
Cambiá el tope de “solicitudes por tiempo” a “recursos distintos por identidad por día”. Un usuario legítimo consulta pocos destinos o registros; un scraper los quiere todos. Ese contador expone la intención aunque el volumen total sea bajo. Complementá con implementar seguridad en workflows.
¿Qué defensas hay además del rate limiting?
Tres capas complementarias: registrar la IP real de origen (para bloquear reincidentes a nivel de red), limitar por recurso o cobertura, y detectar patrones sospechosos como IDs secuenciales o timing regular. Juntas cubren los ejes de identidad, cobertura y forma que el rate limiting ignora.
¿Cómo detecto extracción de datos en mi API?
Monitoreá cobertura y forma, no solo volumen. Alertá cuando una misma identidad toca demasiados recursos distintos en poco tiempo, pide IDs en secuencia o mantiene un ritmo demasiado regular. Guardá la IP real (por ejemplo la CF-Connecting-IP) para correlacionar y bloquear.
Conclusión
El caso deja una lección clara para cualquiera que exponga una API: el rate limiter y la protección de datos resuelven problemas distintos, y tratarlos como si fueran el mismo es cómo se filtra la base entera sin que salte una sola alarma. El volumen no alcanza como métrica de defensa.
¿Qué hacer hoy? Guardá la IP real de cada request, cambiá al menos un endpoint sensible de “N llamadas” a “N recursos distintos por identidad”, y armá una alerta simple sobre patrones de cobertura. Con esas tres cosas ya dejás de depender de un número que el atacante conoce mejor que vos.