Modelar Procesos Complejos en APIs REST
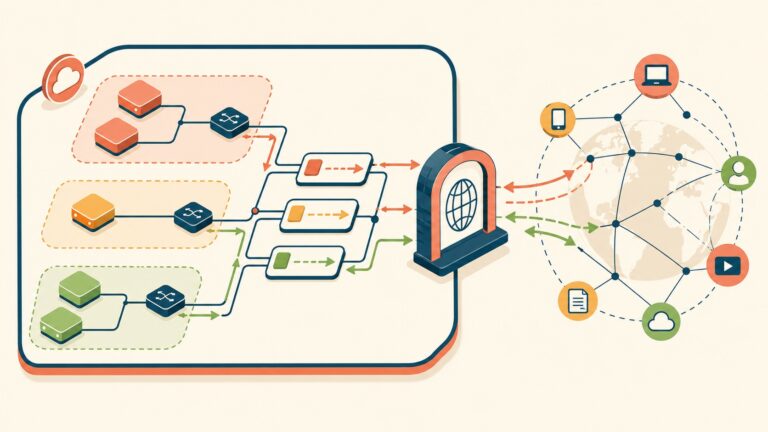
Procesos complejos en APIs REST requieren ir más allá de CRUD: HTTP fue diseñado para documentos, no para aprobaciones, cancelaciones o transiciones de estado. Según Ivan Kahl, especialista en arquitectura de APIs (2026-03-23), el desafío es que los métodos HTTP estándar son insuficientes para operaciones donde un recurso necesita ser aprobado, rechazado, pagado o movido entre múltiples estados válidos, lo que obliga a diseñadores a elegir entre romper REST, proliferar endpoints o modelar explícitamente máquinas de estado finitas.
En 30 segundos
- CRUD no modela aprobaciones, cancelaciones ni transiciones de estado válidas; REST tradicional fue diseñado para documentos, no procesos complejos.
- Máquinas de estados finitos (FSM) funcionan como patrón conceptual para definir qué transiciones son permitidas desde cada estado.
- Sub-recursos de acción (POST /órdenes/{id}/approve) vs. cambios de estado (PATCH con {status}) son dos patrones válidos; elegir según claridad de intención.
- HATEOAS comunica transiciones válidas en cada respuesta: si status=pending, el cliente ve links para /approve y /reject, pero no para /ship.
- Operaciones multi-recurso requieren explícitamente saga patrón o eventos asíncronos; REST sincrónico no garantiza atomicidad.
Por qué CRUD tradicional no es suficiente
Ponele que estás diseñando una API para gestionar órdenes de compra. Las clásicas reglas CRUD (crear, leer, actualizar, borrar) te dicen que hagas POST para crear, GET para leer, PUT/PATCH para actualizar y DELETE para borrar. Lindo en teoría. Pero acá viene lo bueno: en la vida real, una orden pasa por estados como pendiente, en procesamiento, enviada, entregada. Y cada estado tiene acciones distintas que son válidas o no.
Si alguien intenta rechazar una orden que ya fue enviada, eso no debería permitirse. Si intenta aprobar dos veces la misma orden, debería fallar. Estos son problemas que CRUD no resuelve porque CRUD asume que el recurso es un documento: existe o no existe, y vos lo editás. Fin de la historia.
El artículo de Ivan Kahl lo explica así: HTTP fue originalmente diseñado para manejar documentos, no para modelar procesos complejos de negocio. Los métodos REST asumen que todo lo que necesitás con un recurso es crearlo, leerlo, actualizarlo o borrarlo. La realidad empresarial es diferente (si es que eso cuenta como realidad).
Entendiendo recursos y estados en una API REST
Un recurso en REST es cualquier entidad que exponés como endpoint: un usuario, un producto, una orden. Pero un recurso no es sólo un dato; cada recurso tiene un ciclo de vida, un conjunto de estados posibles. Una factura, por ejemplo, no es simplemente “existe” o “no existe”. Una factura está en algún punto de un viaje: borrador, sometida, aprobada, rechazada, pagada, reembolsada.
Y acá está la clave: no todas las transiciones entre estados son válidas. No podés pasar de “aprobada” a “rechazada”. No podés pasar de “pagada” a “borrador”. El flujo tiene reglas.
En un modelo CRUD puro, vos representarías esto con un campo “status” en la orden. Okay, eso funciona para almacenar el dato. Pero el API no comunica qué transiciones son válidas desde el estado actual. El cliente tiene que saber (o adivinar) que desde status=pending puede aprobar o rechazar, pero desde status=paid sólo puede refundar. Eso es frágil, propensoa errores.
Máquinas de estados finitos como modelo conceptual
Una máquina de estados finitos (FSM) es un modelo matemático donde un sistema existe en uno de varios estados posibles, y puede transicionar entre ellos según reglas explícitas. Eso suena aburrido, pero es exactamente lo que necesitás para modelar procesos complejos de negocio.
Imaginá una orden. Sus estados válidos son:
- pending: acaba de ser creada, esperando revisión
- approved: fue autorizada, lista para procesar
- processing: en preparación, reservando stock
- shipped: salió del almacén
- delivered: llegó al destino
- cancelled: fue cancelada (sin ser borrada de la BD; es un estado válido)
- refunded: el dinero fue devuelto
Ahora, las transiciones válidas:
- pending → approved (alguien revisa y aprueba)
- pending → cancelled (se cancela antes de procesar)
- approved → processing (comienza el trabajo)
- approved → cancelled (se cancela después de aprobar, pero antes de procesar)
- processing → shipped (sale del almacén)
- shipped → delivered (llega al destino)
- delivered → refunded (cliente pide devolución dentro del período)
¿Qué transiciones NO son válidas? No podés volver de delivered a shipped. No podés ir directo de pending a delivered sin pasar por los estados intermedios. Y acá está la magia: si diseñás tu API usando FSM como concepto base, el cliente nunca puede hacer algo inválido porque el API no le ofrece las acciones prohibidas. El cliente sólo ve lo que puede hacer desde el estado actual.
Patrones de diseño: sub-recursos de acción y cambios de estado
Hay dos formas principales de modelar transiciones de estado en REST. Ninguna es “correcta”; depende de tu caso. Tema relacionado: protegiendo datos sensibles en APIs.
Patrón 1: Sub-recursos de acción
POST /órdenes/123/approve → aprueba la orden
POST /órdenes/123/reject → rechaza la orden
POST /órdenes/123/ship → marca como enviada
POST /órdenes/123/refund → emite un reembolso
Ventaja: la intención es cristalina. Leyendo la URL, cualquiera sabe qué acción estás pidiendo. No hay ambigüedad.
Desventaja: si tenés 10 acciones posibles, terminás con 10 endpoints. La proliferación es real. El API se vuelve “verbal” en lugar de “nominal” (acciones en lugar de recursos).
Patrón 2: Cambios de estado explícitos
PATCH /órdenes/123 con body: {"status": "approved"}
Ventaja: un único endpoint, pocos cambios. Si querés cambiar el estado a algo, simplemente lo hacés.
Desventaja: la validación queda del lado del servidor. El cliente no sabe cuáles transiciones son válidas hasta que intenta hacer una y recibe un 400. Eso requiere que el cliente sepa las reglas de negocio (o que consulte documentación constantemente).
Comunicar transiciones disponibles con HATEOAS
HATEOAS = Hypertext As The Engine Of Application State. Suena complicado, pero la idea es simple: en la respuesta del API, incluí links que comunican qué podés hacer desde el estado actual.
Ejemplo. Consulta GET /órdenes/123 devuelve:
{
"id": 123,
"status": "pending",
"total": 1500,
"links": {
"approve": { "href": "/órdenes/123/approve", "method": "POST" },
"reject": { "href": "/órdenes/123/reject", "method": "POST" },
"cancel": { "href": "/órdenes/123/cancel", "method": "POST" }
}
}
El cliente ve exactamente qué puede hacer: approve, reject, cancel. No ve un link para “ship” porque la orden aún no fue aprobada. Esto logra varias cosas: (1) el cliente nunca intenta acciones inválidas, (2) si las reglas de negocio cambian, solo el servidor necesita actualizarse, (3) el cliente es “genérico” y no necesita hardcodear la lógica de estados.
Si la orden pasa a status=processing, la siguiente consulta devuelve diferentes links: Sobre eso hablamos en herramientas esenciales para desarrolladores.
{
"id": 123,
"status": "processing",
"total": 1500,
"links": {
"ship": { "href": "/órdenes/123/ship", "method": "POST" },
"cancel": { "href": "/órdenes/123/cancel", "method": "POST" }
}
}
Ahora sí está disponible “ship”, pero “approve” y “reject” desaparecieron porque ya no tienen sentido.
Operaciones que afectan múltiples recursos
Acá viene lo complicado. A veces, una transición de estado requiere cambios en varios recursos simultáneamente. Creá una factura requiere: (1) crear el documento factura, (2) crear líneas de factura, (3) actualizar el inventario, (4) registrar un pago, (5) disparar una notificación al cliente.
REST sincrónico no garantiza atomicidad. Si el paso 3 falla (no hay stock), ¿qué pasa con los cambios de los pasos 1 y 2? Terminaste con una factura huérfana en la BD, líneas sin inventario actualizado. Eso es un problema.
Hay varias respuestas a esto:
- Saga Pattern: dividir en pasos, ejecutar cada uno, y si algo falla, ejecutar compensaciones (rollback manual). Más complejo, más robusto.
- Transacciones implícitas: el servidor hace todo en una transacción de BD. El cliente POST una vez, y si falla algún paso, todo se reviierte. Simple, pero solo funciona si todo está en la misma BD.
- Eventos asíncronos: el servidor crea la factura, dispara eventos (factura creada, inventario debe actualizarse, pago debe procesarse), y los consumidores de eventos actúan en paralelo. Resiliente, pero requiere un sistema de eventos.
Para APIs REST puras, lo más práctico es: el endpoint que crea la factura hace todo lo que puede sincronónamente en una transacción. Si algo de ahí falla, reviértelo todo y devolvé un error. Si hay pasos que no pueden sincronizarse (notificaciones, integraciones externas), lanzalos como eventos y manejálos asincronónicamente. El cliente no espera por ellos, pero si fallan, tenés mecanismos de reintento.
Tabla comparativa: patrones de diseño
| Patrón | Sintaxis | Ventaja | Desventaja | Caso de uso |
|---|---|---|---|---|
| Sub-recursos de acción | POST /órdenes/{id}/approve | Intención clara, HATEOAS natural | Proliferación de endpoints | Acciones bien definidas, pocos estados |
| Cambios de estado explícitos | PATCH /órdenes/{id} {status: ‘approved’} | Pocos endpoints, flexible | Validación compleja en servidor | Muchos estados posibles, flujos variables |
| Máquinas de estado con HATEOAS | GET devuelve links válidos | Cliente nunca hace acciones inválidas | Requiere comunicación de links | Flujos críticos, auditoría importante |
| Event-driven | POST crea evento, retorna async | Desacoplado, escalable | Consistencia eventual, debugging complejo | Sistemas distribuidos, alta concurrencia |

Errores comunes y cómo evitarlos
1. Endpoints de acción desorganizados
Proliferar /órdenes/123/approve, /órdenes/123/reject, /órdenes/123/cancel, /órdenes/123/refund sin ninguna estructura clara. Cada desarrollador agrega lo que necesita. Al año, tenés 15 endpoints dispersos, sin patrón, y nadie entiende cómo se comunican.
Solución: decidí un patrón y adherí a él. Si usás sub-recursos de acción, todos siguen el mismo formato: POST /resource/{id}/{action}. Si usás cambios de estado, un único PATCH endpoint con validaciones en servidor. Documentá las máquinas de estado en un diagrama central (texto, no en la cabeza de alguien).
2. No validar transiciones en servidor
Permitir cualquier transición: pending→delivered en un salto, approved→pending de retroceso, cancelled después de delivered. Esto parece que “da más flexibilidad”, pero en realidad mata la integridad de datos.
Solución: en el servidor, antes de permitir cualquier transición, validá que sea válida según tu FSM. Devolvé 400 Bad Request si alguien intenta algo prohibido. El cliente necesita saber qué está permitido, no adivinar. Te puede servir nuestra cobertura de plataformas líderes en versionado.
3. No documentar qué estados existen
El API devuelve status=”processing”, pero el cliente nunca vio esa lista de valores posibles. Termina haciendo consultas específicas, chequeando valores específicos, si el servidor cambia un valor, todo se rompe.
Solución: documentá explícitamente qué estados existen. En un enum, en una tabla, en donde sea. El cliente necesita poder listar estados válidos (podés hacer un endpoint GET /metadata/order-states que devuelva [pending, approved, processing, shipped, delivered, cancelled, refunded]). Esto es trivial pero salvador.
4. Confundir estado con metadata
Guardar status en un lado, y datos sobre transiciones (quién aprobó, cuándo, por qué) en otro lado, sin relación. O peor: guardar la transición en un log separado, y cuando consultás el recurso actual, la historia se perdió.
Solución: cada transición de estado es un evento. Guardá el evento (timestamp, usuario, antes/después de estado). El recurso actual refleja el estado final, pero la historia de cómo llegó ahí es auditable. Esto no es solo para compliance; es para debugging (ojo: si alguien cambió el estado, necesitás saber quién y cuándo).
5. Status ocultos en respuestas
El cliente nunca ve el campo “status” en la respuesta. En cambio, intenta adivinar el estado mirando otros campos (¿tiene un date_shipped?, entonces está shipped. ¿tiene un date_delivered?, entonces está delivered). Frágil, implícito, imposible de depurar.
Solución: “status” es un campo de primera clase en la respuesta. Siempre presente, claro, actualizado. Sin adivinanzas.
Esto se conecta con Modeling Complex Business Processes in REST APIs, donde profundizamos en el tema.
Preguntas Frecuentes
¿Cómo modelar aprobaciones y rechazos en una API REST?
Dos opciones: (1) sub-recursos de acción — POST /órdenes/{id}/approve, POST /órdenes/{id}/reject; el servidor valida que la orden esté en estado válido para aprobar/rechazar, actualiza el status, devuelve 200 OK. (2) Cambios de estado — PATCH /órdenes/{id} con {status: ‘approved’} o {status: ‘rejected’}; el servidor valida la transición. La primera es más explícita; la segunda es más flexible si hay múltiples transiciones posibles.
¿Qué hacer cuando CRUD no es suficiente para operaciones complejas?
Modelá la operación como una máquina de estados finitos. Identificá todos los estados posibles del recurso, las transiciones válidas entre ellos, y las acciones que disparan cada transición. Luego, exponé esas acciones como endpoints (sub-recursos de acción) o como cambios de estado validados (PATCH). El punto es que el servidor valide cada transición según la FSM, nunca permitiendo saltos o retrocesos inválidos. En en procesos de modernización estructural profundizamos sobre esto.
¿Cómo comunicar al cliente qué acciones están disponibles desde el estado actual?
HATEOAS: en la respuesta de GET /recurso/{id}, incluí un campo “links” o “_links” con hipervínculos a las acciones válidas desde el estado actual. Si status=pending, links incluye approve, reject, cancel. Si status=processing, links incluye ship, cancel. El cliente nunca intenta una acción que no esté en los links, por lo que nunca recibe errores por transiciones inválidas.
¿Cómo manejar operaciones que afectan múltiples recursos?
Tres opciones según escala: (1) transacción de BD — todo sincrónico en una transacción; si algo falla, reviértelo todo. Simple, pero solo funciona en una sola BD. (2) Saga patrón — divide en pasos, ejecuta cada uno, y si uno falla, ejecutá compensaciones (undo del paso anterior). Más complejo, pero distribuido. (3) Eventos asincronónicos — crea el recurso principal sincronónicamente, luego dispara eventos para los cambios secundarios (inventario, notificaciones, etc.). El cliente no espera; el sistema maneja consistency eventual.
¿Cuál es la diferencia entre cancelación (estado) y eliminación (DELETE)?
Eliminación (DELETE) borra el recurso de la BD; ya no existe. Cancelación es un estado; el recurso sigue en la BD, pero marcado como inactivo o rechazado. Para auditoría, compliance y debugging, cancelación es mejor. DELETE debería ser raro en APIs reales; casi siempre querés un estado de “deleted” o “cancelled”.
Qué significa para desarrolladores y equipos en Latinoamérica
La mayoría de APIs construidas aquí sigue patrones CRUD simples. Funciona para CRUD, pero cuando el negocio pide un flujo de aprobaciones, cambios de estado, o múltiples pasos en un proceso, el API colapsa (proliferación de endpoints, validaciones dispersas, errores silenciosos). Entender máquinas de estado y HATEOAS no requiere tecnología sofisticada; requiere pensar una vez upfront.
Si estás construyendo un sistema de facturación, pedidos, workflows de aprobación, o cualquier cosa con múltiples estados válidos, dedica unas horas a mapear la FSM en papel. Documentala. Diseña el API basándote en eso. Cuando lo hagas, el cliente verá un API claro, predecible, y casi imposible de usar incorrectamente.
Conclusión
Procesos complejos en APIs REST requieren ir más allá de CRUD. HTTP no fue diseñado para eso, pero eso no significa que no se pueda. La clave es modelar explícitamente una máquina de estados finitos: definir qué estados son válidos, cuáles transiciones son permitidas, y comunicar eso al cliente a través de HATEOAS.
Cuando hacés esto bien, pasan cosas buenas: (1) el cliente nunca intenta una acción inválida, (2) si las reglas de negocio cambian, solo el servidor se actualiza, (3) la auditoría es clara (sabés exactamente qué estado tenía el recurso en cada momento), (4) debugging es más fácil porque los errores son explícitos, no silenciosos.
No es revolucionario. Es ingeniería de software básica aplicada a APIs. Pero la mayoría no lo hace, y eso explica por qué tantos APIs son frágiles, confusos, y propensos a errores. Si vos lo hacés, tu API sale ganando.

![[FREE] I built a WordPress plugin for private team/client documents - ilustracion](https://donweb.news/wp-content/uploads/2026/04/plugin-wordpress-documentos-privados-hero-768x429.jpg)