Resiliencia multi-nube: arquitectura celular en AWS y Azure
La resiliencia multi-nube es la capacidad de un sistema para seguir funcionando cuando un proveedor cloud completo falla, distribuyendo cargas de trabajo entre AWS y Azure (u otros proveedores) en células autónomas y aisladas. Según el blueprint publicado en mayo de 2026, la arquitectura celular event-driven es hoy el patrón más robusto para lograr esto sin introducir dependencias cruzadas entre nubes.
En 30 segundos
- La arquitectura celular divide el sistema en células completamente autónomas, una por proveedor cloud, eliminando el punto único de fallo.
- Event-driven significa que AWS y Azure procesan eventos de forma asincrónica e independiente: si cae uno, el otro no sabe ni le importa.
- El routing de tráfico usa una capa de edge agnóstica que redirige según partition key (tenant ID, región) y puede hacer failover en 3 a 6 minutos.
- Terraform 1.9 o superior es el control plane recomendado: misma sintaxis para AWS y Azure, desplegás infraestructura idéntica en ambas nubes desde un solo repositorio.
- El error más común es construir una arquitectura “estirada” que consulta datos entre nubes: eso garantiza latencia alta y dependencias frágiles.
¿Qué es resiliencia multi-nube?
Resiliencia multi-nube es la capacidad de un sistema distribuido para mantener disponibilidad completa aunque un proveedor cloud entero caiga, gracias a que sus componentes están replicados y operando de forma independiente en al menos dos infraestructuras diferentes.
Según estudio de Gartner de enero 2026, el 85% de las empresas enterprise han adoptado o están explorando estrategias multi-cloud, no por moda sino por necesidad. Mirá lo que pasó en octubre de 2025: el outage de AWS dejó sin servicio a Snapchat, Roblox y sistemas bancarios en simultáneo. Antes que eso, en junio de 2025, Azure tuvo su propio episodio con Azure Front Door que dejó sin servicio a miles de aplicaciones europeas. La pregunta dejó de ser “¿va a caer un proveedor?” y pasó a ser “¿cuándo?”
Eso sí: multi-cloud no es lo mismo que multi-región. Tener tu app en us-east-1 y us-west-2 no te salva si Amazon Web Services completo tiene un problema de plano de control global. Para eso necesitás estar en otro proveedor.
El problema: confiar en un solo proveedor te deja expuesto
Ponele que tenés tu arquitectura completa en AWS: EC2, RDS, Lambda, S3, todo. Un día el servicio de IAM empieza a devolver errores esporádicos (que es exactamente lo que pasó en el outage de octubre 2025). No podés autenticar nada. Tus microservicios no pueden asumir roles. Las Lambdas fallan. La base de datos no acepta conexiones nuevas porque el agente de autenticación no responde. Todo se rompe en cascada (lo que se llama cascading failure) y vos estás mirando el dashboard de CloudWatch sin poder hacer absolutamente nada.
Según datos de Gartner de 2025, el costo promedio de downtime para una empresa enterprise ronda los USD 300.000 por hora. Para ecommerce en pico de ventas, esa cifra se multiplica.
La diferencia clave entre multi-región y multi-cloud: multi-región te da redundancia dentro del mismo proveedor, lo cual soluciona fallos zonales pero no fallos del proveedor completo. Multi-cloud pone tu app en infraestructuras físicamente distintas con APIs, control planes y stacks de seguridad completamente diferentes. Cuando uno falla, el otro ni se entera.
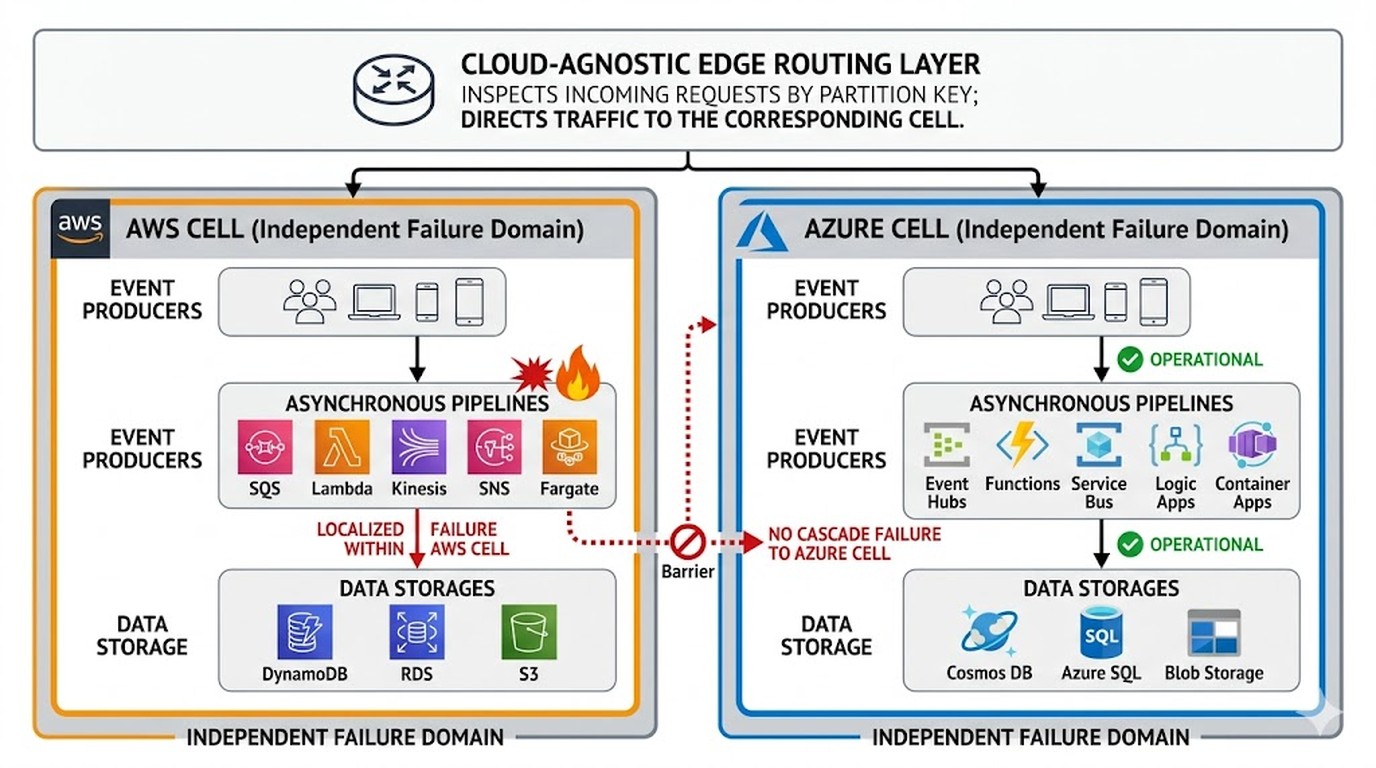
Arquitectura celular: la unidad de aislamiento
Una célula es un sistema completo y autosuficiente. Tiene su propia base de datos, su propio broker de eventos, su propia capa de procesamiento, su propio sistema de autenticación. No consulta datos a otras células ni depende de servicios externos para funcionar.
En el blueprint de arquitectura multi-nube publicado en mayo de 2026, la propuesta es desplegar células lógicamente idénticas en AWS y Azure como hosts físicos separados. AWS tiene su célula completa. Azure tiene su célula completa. Procesan los mismos tipos de eventos, mantienen sus propios datos (replicados asíncronamente), y pueden operar indefinidamente sin comunicarse entre sí. Más contexto en optimizar SEO en múltiples regiones.
El anti-patrón que hay que evitar es la arquitectura “estirada”: una app que guarda datos en S3 (AWS) pero los procesa en Azure Blob, o que consulta una base RDS en AWS desde un servicio en Azure. Esa arquitectura garantiza latencia alta (porque cada operación cruza el internet público entre clouds), dependencias frágiles (si cae un lado, el otro también falla), y costos de egress brutales. Si el diseño requiere que una célula le pregunte algo a otra, el diseño está mal.
El direccionamiento del tráfico usa una partition key, típicamente el tenant ID o la región del usuario. Un tenant europeo siempre va a la célula A (Azure), un tenant norteamericano siempre va a la célula B (AWS). La capa de routing conoce estas reglas y las aplica en el edge, antes de que el request toque cualquier infraestructura del proveedor.
Event-driven vs acoplado: por qué importa la asincronía
Una arquitectura síncrona en multi-cloud es una trampa. Si el servicio A en AWS llama directamente al servicio B en Azure y espera respuesta, tenés una dependencia de latencia cruzada. Cada request suma 20-80ms de latencia de red adicional. Si Azure tiene degradación parcial (no caída total, sino simplemente más lento de lo usual), todos tus requests se vuelven lentos. Y si falla completamente, todos tus requests fallan.
Event-driven resuelve esto con asincronía. En vez de “llamar y esperar”, los servicios publican eventos en un broker local a su célula y se olvidan. En AWS usás EventBridge como broker central de la célula. En Azure usás Service Bus. Cada uno procesa su cola de eventos de forma independiente, a su propio ritmo, sin saber que existe el otro.
¿Y cómo viajan los datos que necesitan estar en ambos lados? Replicación asincrónica de eventos. Cuando algo importante pasa en la célula AWS (un usuario se registra, una orden se completa), ese evento se replica hacia la célula Azure con un pequeño delay aceptable. No es real-time, pero en la mayoría de los casos de uso no necesita serlo. El trade-off es eventual consistency a cambio de disponibilidad total.
Implementación técnica con Terraform
Terraform 1.9 o superior es el control plane recomendado para esta arquitectura, y la razón es simple: es el único que puede hablarle a AWS y Azure con la misma sintaxis desde un solo repositorio. Sin Terraform, tenés que mantener scripts de CloudFormation para AWS y ARM templates para Azure de forma separada, con dos pipelines distintos, dos conjuntos de variables, dos equipos que no se coordinan. En seguridad integrada en Azure profundizamos sobre esto.
Con Terraform, definís la infraestructura de ambas células una sola vez. Si necesitás agregar una cola SQS en AWS y un Service Bus namespace en Azure para el mismo propósito, lo hacés en el mismo archivo con providers distintos. El mismo `terraform apply` despliega todo en paralelo.
El stack con Kubernetes y Crossplane que documentaron en 2026 lleva esto un paso más allá: Crossplane permite gestionar recursos cloud (instancias, colas, bases de datos) como objetos Kubernetes nativos, con el mismo kubectl que usás para tu app. Si ya tenés un cluster K8s, Crossplane reduce la superficie operativa.
Un detalle operativo que no es obvio: en Terraform multi-cloud, los workspaces por ambiente (dev, staging, prod) se vuelven críticos. No querés que un `terraform apply` en el ambiente equivocado toque producción en ambas nubes simultáneamente.
Routing inteligente y failover automático
La capa de routing de edge es el componente más crítico de toda la arquitectura y, paradójicamente, el que más se pasa por alto en los diseños iniciales.
Este componente vive fuera de ambos providers (en Cloudflare Workers, en un load balancer propio, o en una región neutral) y tiene una sola responsabilidad: inspeccionar el request entrante, extraer la partition key, y mandarlo al proveedor correcto. También monitorea la salud de cada célula y puede desviar tráfico automáticamente cuando detecta degradación.
El tiempo de failover automático ronda los 3 a 6 minutos con health checks bien configurados. El failover manual, donde alguien tiene que detectar el problema, escalar, decidir, y ejecutar, tarda entre 2 y 4 horas en promedio. La diferencia entre 5 minutos y 3 horas de downtime para una empresa de servicios digitales puede ser la diferencia entre un incidente menor y una crisis de reputación.
Para prevenir cascading failure hay que agregar rate limiting en la capa de routing: si una célula empieza a fallar y el router le manda todo el tráfico a la otra, la segunda célula puede saturarse y caer también (spoiler: eso pasó varias veces en outages documentados). El router tiene que tener guardrails que limiten cuánto tráfico puede desviar de golpe y que degraden gradualmente en vez de hacer un switch binario. Complementá con analizar eventos de indisponibilidad.
Monitoreo y observabilidad en dos nubes
Tenés dos stacks de observabilidad nativos que no hablan entre sí: CloudWatch en AWS y Azure Monitor en Azure. Los dos recopilan métricas excelentes de sus propios recursos. El problema es que cuando querés ver qué pasó durante un incidente, necesitás correlacionar eventos de ambos lados en la misma timeline.
La solución estándar en 2026 es una capa de observabilidad neutral: Prometheus como collector en ambas células, Grafana para dashboards unificados, y Datadog o un stack similar para alertas centralizadas. Cada célula exporta sus métricas al mismo sistema central, donde podés ver en el mismo dashboard la latencia de la célula AWS y la célula Azure en tiempo real.
La trazabilidad de eventos que cruzan nubes requiere trace IDs que persistan durante la replicación. Si un evento se genera en AWS y se replica a Azure, el trace ID del evento original tiene que sobrevivir intacto para que puedas seguir el flujo completo de principio a fin. Parece obvio pero es uno de los olvidos más comunes en implementaciones reales.
Tabla comparativa: enfoques de resiliencia
| Enfoque | Protege contra | No protege contra | Tiempo de failover | Complejidad |
|---|---|---|---|---|
| Multi-AZ (mismo provider) | Fallo de datacenter | Fallo de provider completo | Segundos | Baja |
| Multi-Región (mismo provider) | Fallo regional, desastres naturales | Fallo global del provider | 1-10 minutos | Media |
| Multi-Cloud activo-pasivo | Fallo completo de un provider | Latencia de activación manual | 2-4 horas (manual) | Alta |
| Multi-Cloud celular event-driven | Fallo completo de un provider | Fallo simultáneo de ambos providers | 3-6 minutos (auto) | Muy alta |
Mejores prácticas y errores que vas a cometer igual
El error más caro que cometen los equipos cuando migran a multi-cloud es reutilizar componentes de identidad entre nubes. Ponen el mismo Identity Provider central que autentica tanto en AWS como en Azure, y se quedan sin failover real: si cae el IdP, caen los dos. DNS compartido es el mismo problema. La regla es: todo lo que sea “infraestructura de soporte” (DNS, auth, networking) tiene que estar duplicado y ser independiente en cada célula.
Otro clásico: no probar el failover hasta que pasa en producción. Los health checks dicen que la célula de backup está bien, pero nadie verificó que el routing realmente funciona, que la replicación de eventos está al día, y que la célula de backup puede aguantar el tráfico completo. Hacé fire drills mensuales. Apagá la célula principal en staging y verificá que todo llega al otro lado en el tiempo esperado.
El load balancing mal configurado es una trampa silenciosa: si el router manda el 80% del tráfico a la célula AWS porque tiene mejor latencia para tu base de usuarios, la célula Azure nunca tiene carga real. Cuando necesitás hacer el failover, Azure tiene que absorber de golpe el 100% con recursos sub-dimensionados. Distribuí tráfico real en ambas células, aunque sea 70/30, para que las dos estén calientes. Relacionado: desplegar en containers con Docker.
Qué significa esto para equipos en Latinoamérica
Para empresas argentinas y latinoamericanas que alojan infraestructura crítica en la nube, la resiliencia multi-nube pasó de ser “nice to have” a requisito en sectores regulados (fintech, salud, gobierno). Las regiones disponibles más cercanas son us-east-1 (AWS Virginia) y East US (Azure Virginia), con latencias de 120-180ms desde Buenos Aires, lo cual es manejable para la mayoría de los casos de uso.
Si estás evaluando dónde alojar la capa de edge routing (la parte que tiene que sobrevivir a ambas nubes), servicios como donweb.com pueden ser una opción para el hosting de componentes livianos de routing y monitoreo desde infraestructura local, sin depender de ninguno de los dos grandes.
Si querés entender mejor este enfoque, tenemos más detalles en Multi-Cloud Resilience: The Event-Driven Cellular Architectu.
Para profundizar, mirá Multi-Cloud Resilience: The Event-Driven Cellular Architectu, donde cubrimos el tema en detalle.
Esto se relaciona directamente con Multi-Cloud Resilience: The Event-Driven Cellular Architectu, que cubrimos en detalle acá.
Esto se conecta directamente con Multi-Cloud Resilience: The Event-Driven Cellular Architectu, donde lo explicamos en detalle.
Preguntas Frecuentes
¿Qué es resiliencia multi-nube y cómo funciona?
Resiliencia multi-nube es la capacidad de mantener disponibilidad total aunque un proveedor cloud (AWS, Azure, GCP) falle completamente. Funciona desplegando células autónomas e idénticas en cada proveedor: cada célula tiene su propia base de datos, brokers de eventos y capa de procesamiento. Una capa de routing de edge redirige el tráfico entre células según partition keys y hace failover automático en 3 a 6 minutos si detecta degradación.
¿Cómo implementar failover automático entre AWS y Azure?
El failover automático requiere una capa de routing neutral (fuera de ambos providers) con health checks configurados que monitoreen latencia y tasa de errores de cada célula. Cuando los checks detectan que una célula supera umbrales definidos (por ejemplo, más del 5% de errores en 2 minutos), el router redirige el tráfico automáticamente. Terraform gestiona la configuración de ambas células y Prometheus/Grafana centraliza el monitoreo.
¿Cuál es la diferencia entre multi-región y multi-cloud?
Multi-región distribuye tu app en varias regiones del mismo proveedor (por ejemplo, us-east-1 y eu-west-1 en AWS) y protege contra fallos zonales o regionales. Multi-cloud usa dos proveedores completamente diferentes (AWS + Azure) y protege contra fallos del proveedor completo, incluyendo problemas de plano de control global. El outage de AWS de octubre 2025 afectó múltiples regiones simultáneamente: multi-región no hubiera ayudado, multi-cloud sí.
¿Qué es arquitectura event-driven en multi-cloud?
En arquitectura event-driven, los servicios se comunican publicando eventos en un broker (EventBridge en AWS, Service Bus en Azure) sin esperar respuesta sincrónica. Cada célula procesa su propia cola de eventos de forma independiente, sin consultar a la otra nube. Esto elimina dependencias de latencia cruzada y permite que cada célula funcione aunque la otra esté completamente caída. La replicación de datos entre nubes también es asincrónica, con eventual consistency como trade-off.
¿Cómo evitar downtime total si cae un proveedor cloud?
La arquitectura celular event-driven con routing automático reduce el downtime a 3-6 minutos de failover automático. Los requisitos son: células completamente independientes (sin shared DNS, auth o networking), routing de edge neutral fuera de ambos providers, health checks configurados con umbrales claros, y fire drills mensuales para verificar que el failover funciona en la práctica. Sin pruebas regulares, el failover “automático” suele tener sorpresas el día que más lo necesitás.
Conclusión
La arquitectura celular event-driven en multi-cloud dejó de ser un experimento de empresas Fortune 500 y se convirtió en el patrón de referencia para cualquier sistema que no pueda permitirse horas de downtime. El outage de AWS de octubre 2025 aceleró esa transición: muchos equipos que tenían multi-cloud “en el roadmap” lo movieron a prioridad inmediata después de ver el impacto real.
La complejidad es alta. No hay que romantizarla: Terraform multi-provider, células autónomas, replicación asincrónica, routing de edge, observabilidad centralizada: son muchas piezas. Pero cada componente existe, tiene documentación, y ya hay equipos que lo operan en producción. Lo que antes requería meses de diseño custom hoy tiene blueprints concretos con código incluido.
Si tu sistema procesa datos críticos y todavía depende de un solo provider, el primer paso es el más impactante: diseñar la capa de routing con health checks reales. No necesitás tener dos células perfectamente configuradas para empezar. Necesitás saber cómo desviar tráfico cuando lo necesitás.
Fuentes
- Dev.to – Multi-Cloud Resilience: Blueprint de Arquitectura Celular Event-Driven (2026)
- Microsoft Learn – Guía de arquitectura event-driven en Azure
- AWS – Arquitectura event-driven: documentación oficial
- Northflank – AWS Outage octubre 2025 y estrategia multi-cloud
- TechBytes – Multi-cloud failover con Kubernetes y Crossplane (2026)