HTTP/2 y detección de bots: el problema que no ves
Si tus requests automatizados se bloquean aunque tengan el User-Agent de Chrome, el problema no está en los headers que ves. La detección de automatización HTTP/2 analiza el orden de pseudo-headers, la compresión HPACK y la secuencia de frames, patrones que los navegadores reales siguen de forma consistente y que la mayoría de los scripts no replican.
En 30 segundos
- HTTP/2 envía headers en formato binario estructurado: primero pseudo-headers (
:method,:scheme,:authority,:path), después los headers regulares en orden predecible. - Los sistemas de detección modernos analizan el comportamiento del protocolo, no solo el contenido de los headers. Copiar un User-Agent de Chrome no alcanza.
- HPACK, el mecanismo de compresión de headers de HTTP/2, genera patrones de compresión distintos en navegadores reales versus librerías como curl, requests o axios.
- Servicios de proxy mejoran el routing y la distribución de IPs, pero no resuelven el fingerprinting HTTP/2 si la librería subyacente no implementa el protocolo correctamente.
- Las alternativas reales para automatización son headless browsers con plugins stealth, navegadores anti-detección, o directamente usar las APIs oficiales de los servicios.
Qué es HTTP/2 y por qué el orden de headers importa
HTTP/2 es la segunda versión del protocolo de transferencia web, lanzado como estándar en 2015 (RFC 7540). A diferencia de HTTP/1.1, que enviaba headers como texto plano, HTTP/2 usa un formato binario con compresión HPACK y multiplexación de streams. Eso cambió algo que nadie anticipó del todo: el orden en que los headers viajan por la red pasó a ser parte de la identidad del cliente.
En HTTP/2, cada request incluye pseudo-headers, que son campos especiales que empiezan con dos puntos: :method, :scheme, :authority y :path. La especificación RFC 7541 establece que estos pseudo-headers deben aparecer antes que los headers regulares. Los navegadores reales respetan eso de forma muy consistente, y además mantienen el mismo orden interno en los headers regulares (como accept, accept-encoding, accept-language) request tras request.
Ese patrón repetible forma una especie de firma digital del cliente. Y ahí está el problema para la automatización.
Cómo los navegadores reales ordenan pseudo-headers y headers
Chrome, por ejemplo, sigue un orden bastante estable: primero :method, luego :authority, :scheme, :path. Firefox tiene su propio orden consistente, que difiere un poco del de Chrome pero que tampoco varía entre requests del mismo navegador. Eso no es casualidad, es el resultado de implementaciones de red maduras que optimizan la compresión HPACK aprovechando los índices de la tabla de headers más usados. Cubrimos ese tema en detalle en en nuestra guía de optimización SEO.
HPACK mantiene una tabla dinámica de headers vistos recientemente. Un navegador real, que hace miles de requests por sesión, llena esa tabla de forma predecible y la reutiliza de manera consistente. Una librería Python que hace tres requests con distintos headers y en distinto orden genera un patrón de compresión que no coincide con ningún navegador real conocido. Los sistemas de detección (Cloudflare lo documenta en su blog técnico desde hace años) construyen whitelists de fingerprints de navegadores legítimos y marcan todo lo que no coincide.
Por qué copiar headers visibles no alcanza para evitar la detección HTTP/2
Ponele que configurás tu script con el User-Agent exacto de Chrome 124 en Windows 11, agregás accept-language: es-AR, accept-encoding: gzip, deflate, br, y hasta metés el sec-ch-ua. El request parece un navegador real si lo mirás a nivel HTTP/1.1. El problema es que HTTP/2 tiene una capa debajo que no estás tocando.
Según el análisis publicado en Dev.to a principios de mayo de 2026, los sistemas de detección modernos evalúan tres cosas que van más allá de los valores de los headers: el casing y formatting (Chrome siempre envía los nombres en minúsculas, pero algunas librerías usan mayúsculas o mezclan), el comportamiento de compresión HPACK, y la consistencia del frame sequencing a lo largo de múltiples requests.
Ese gap entre “parece correcto” y “se comporta correctamente” es lo que lleva a muchos a romperse la cabeza durante días.
Las tres técnicas de detección: casing, HPACK y frame sequencing
Casing y formatting
HTTP/2 especifica que los nombres de headers deben estar en minúsculas. Los navegadores reales lo cumplen al pie de la letra. Algunas librerías HTTP, especialmente versiones viejas o mal configuradas, envían headers con mayúsculas (Content-Type en vez de content-type). Eso ya es una señal.
Compresión HPACK
La tabla dinámica de HPACK indexa headers según frecuencia de uso. Un navegador real que navega varios sitios construye esa tabla de una manera muy específica. Una librería que arranca de cero en cada sesión, o que no implementa correctamente la tabla dinámica, produce un patrón de compresión que no coincide con el fingerprint de ningún navegador real. Cloudflare documentó esto como una de las señales más confiables para distinguir tráfico automatizado.
Frame sequencing
HTTP/2 trabaja con frames: HEADERS frames, DATA frames, SETTINGS frames, WINDOW_UPDATE frames. La secuencia en que estos aparecen al inicio de una conexión (el “connection preface”) es distinta entre navegadores y librerías. Chrome envía SETTINGS y WINDOW_UPDATE con valores muy específicos que identifican la versión del motor. ¿Alguien verificó de forma independiente que las librerías más populares replican esto? No de forma exhaustiva, y ahí está el problema. Lo explicamos a fondo en cuando los headers causan indisponibilidad.
Limitaciones de los servicios de proxy
Bright Data, Oxylabs y Smartproxy son servicios mencionados frecuentemente en workflows de data collection. Mejoran la distribución de IPs y el routing, y eso resuelve la detección basada en reputación de IP o en rate limiting por dirección. El tema es que no resuelven el fingerprinting HTTP/2 si la librería cliente no implementa el protocolo correctamente.
El flujo es: tu script (con Python requests, axios, curl) genera un request con un fingerprint HTTP/2 específico. Ese request pasa por el proxy. El proxy cambia la IP de origen, pero el fingerprint del cliente ya está en los frames HTTP/2 que se enviaron. El servidor de destino ve un fingerprint que no corresponde a ningún navegador conocido, aunque la IP sea legítima. El proxy no puede reescribir los frames HTTP/2 de bajo nivel sin romper la conexión.
Esto no quiere decir que los proxies sean inútiles (resuelven otros problemas reales), pero si tu problema específico es el fingerprinting HTTP/2, agregar un proxy no mueve la aguja.
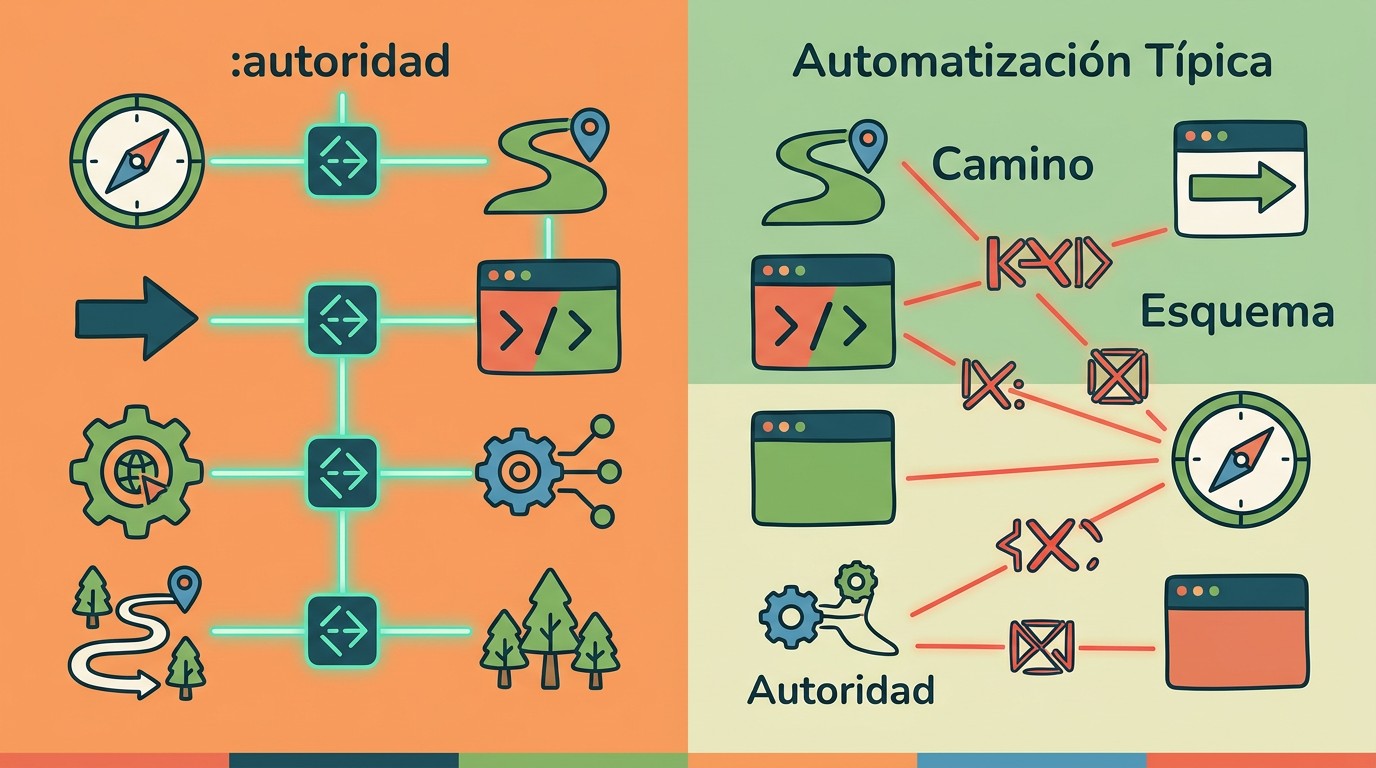
Diferencias reales entre navegador y automatización
| Característica | Navegador real (Chrome) | Librería típica (requests/axios) |
|---|---|---|
| Orden pseudo-headers | :method, :authority, :scheme, :path | Variable o distinto |
| Casing de headers | Siempre minúsculas | Puede mezclar mayúsculas |
| Tabla dinámica HPACK | Construida progresivamente, consistente | Vacía o mal poblada |
| SETTINGS frame inicial | Valores específicos por versión de Chrome | Valores default del stack HTTP |
| WINDOW_UPDATE frame | Enviado con tamaño específico (65535 bytes Chrome) | Distinto o ausente |
| Orden headers regulares | accept, accept-encoding, accept-language, cache-control | Sin orden garantizado |
Subís el script, configurás todos los headers visibles, lo probás contra un endpoint que solo lee los valores, pasa perfecto, lo mandás contra un sitio con detección seria y lo bloquean al tercer request porque el SETTINGS frame initial window size es 65535 en Chrome pero 16384 en la librería que estás usando y nadie documentó eso en ningún tutorial.
Implicaciones: defensa y alternativas técnicas
Para equipos de seguridad, este mecanismo es una buena noticia. El fingerprinting HTTP/2 es una capa de detección difícil de falsificar sin reescribir la implementación del protocolo, lo que eleva significativamente el costo para atacantes que usan tooling estándar. Si tu WAF o tu reverse proxy analiza fingerprints HTTP/2 (y si usás infraestructura en donweb.com o cualquier CDN con capacidades de inspección profunda), esa capa agrega una señal de detección real.
Para automatización legítima (scraping de datos propios, testing, monitoreo), las opciones son más acotadas de lo que muchos esperan: Tema relacionado: configurar correctamente tu servidor.
- Headless browsers con plugins stealth (Playwright con stealth, Puppeteer extra): sincronizan el comportamiento HTTP/2 porque usan el motor real de Chrome. El costo es en recursos y velocidad.
- Navegadores anti-detección: herramientas como Camoufox o Rebrowser están construidas sobre Firefox/Chrome con modificaciones que hacen coincidir los fingerprints con perfiles reales. Ojo, son soluciones más complejas de operar.
- APIs oficiales: si el sitio tiene API, usarla es la opción más estable a largo plazo. No hay cat-and-mouse con fingerprinting si la fuente de datos te da acceso directo.
- Librerías con soporte HTTP/2 correcto:
httpxen Python tiene mejor soporte HTTP/2 querequests, pero aun así requiere configuración explícita del orden de headers y los valores de SETTINGS para coincidir con un navegador real.
Errores comunes al lidiar con detección HTTP/2
Error 1: creer que el problema son los headers que “faltan”. La reacción típica cuando te bloquean es agregar más headers: sec-ch-ua, sec-fetch-site, sec-fetch-mode. Si el problema es el fingerprinting HTTP/2 a nivel de frames, agregar headers no resuelve nada. Estás pintando las paredes de una casa con los cimientos rotos.
Error 2: asumir que un proxy premium resuelve todo. Los proxies resuelven detección por IP, no por fingerprint de protocolo. Combinados con un headless browser real son útiles. Solos, no tocan el problema HTTP/2.
Error 3: probar contra endpoints propios y asumir que funciona en producción. La mayoría de los servidores de test no tienen detección de fingerprinting activa. Que pase en local dice muy poco sobre si va a pasar contra un sitio con WAF serio. Si no probaste específicamente contra el sistema de destino, no sabés nada.
Para más detalles, podés ver nuestro artículo sobre HTTP/2 Header Order and Why Browser-Like Requests Still Get.
Si necesitás profundizar en HTTP/2, mirá HTTP/2 Header Order and Why Browser-Like Requests Still Get .
Esto se conecta con HTTP/2 Header Order and Why Browser-Like Requests Still Get, donde cubrimos el tema en detalle.
Si querés meterte más en el tema, tenemos HTTP/2 Header Order and Why Browser-Like Requests Still Get.
Si querés profundizar, tenemos un artículo sobre HTTP/2 Header Order and Why Browser-Like Requests Still Get.
Si querés profundizar en esto, tenemos un artículo sobre HTTP/2 Header Order and Why Browser-Like Requests Still Get.
Esto se relaciona con HTTP/2 Header Order and Why Browser-Like Requests Still Get, donde cubrimos el tema.
Preguntas Frecuentes
¿Por qué mis requests automáticos se bloquean aunque tengan headers de navegador?
Porque los sistemas de detección modernos no solo leen los valores de los headers, analizan el comportamiento HTTP/2 completo: orden de pseudo-headers, compresión HPACK, y los frames de bajo nivel al inicio de la conexión. Si tu librería no replica el comportamiento de un navegador real a ese nivel, el fingerprint no coincide con ningún cliente legítimo conocido, independientemente de qué User-Agent configuraste.
¿Qué es el orden de headers en HTTP/2 y por qué importa?
En HTTP/2, los headers se transmiten en formato binario y deben seguir una estructura específica: primero los pseudo-headers (:method, :authority, :scheme, :path) y después los headers regulares. Los navegadores reales mantienen un orden consistente y predecible entre requests. Esa consistencia forma parte del fingerprint del cliente que los sistemas de detección aprenden a reconocer. Ya lo cubrimos antes en automatizá la gestión de headers.
¿Qué es HPACK y cómo se usa para detectar automatización?
HPACK es el algoritmo de compresión de headers de HTTP/2, especificado en RFC 7541. Mantiene una tabla dinámica de headers usados recientemente para evitar reenviarlos completos. Un navegador real construye esa tabla de forma predecible a lo largo de una sesión de navegación. Una librería que implementa HPACK de manera diferente (o incorrecta) genera patrones de compresión que no coinciden con ningún fingerprint de navegador real, lo que es una señal de automatización.
¿Puedo burlar la detección de bots solo falsificando headers?
No. Falsificar headers es el primer paso pero insuficiente. La detección HTTP/2 opera a nivel de protocolo, no de contenido. Para replicar el comportamiento de un navegador real necesitás usar el motor real (headless browser) o implementar correctamente todos los parámetros del protocolo: SETTINGS frame, WINDOW_UPDATE, orden de headers y comportamiento HPACK. Es técnicamente posible pero requiere trabajo significativo.
¿Cómo detectan los servidores que un request viene de un script?
Combinando múltiples señales: fingerprint HTTP/2 (orden de headers, compresión HPACK, valores de SETTINGS), reputación de IP, frecuencia y patrones de requests, y comportamiento de JavaScript si hay challenge pages. Ninguna señal sola es concluyente, pero sistemas como los de Cloudflare cruzan todas estas capas simultáneamente. El fingerprinting HTTP/2 es especialmente efectivo porque requiere reescribir la implementación del protocolo para falsificarlo, no solo cambiar valores de texto.
Conclusión
El fingerprinting HTTP/2 cambió la ecuación de detección de automatización de forma silenciosa pero efectiva. Que tus requests “parezcan” un navegador a nivel de valores de headers es condición necesaria pero no suficiente. El protocolo tiene una capa de identidad más profunda, en el orden de los frames, en cómo se construye la tabla HPACK, en los valores exactos del connection preface, que la mayoría de las librerías no replica correctamente.
Para defensa, esto es una herramienta concreta: agregar análisis de fingerprinting HTTP/2 a tu stack de seguridad web sube el piso de lo que un atacante necesita hacer para parecer legítimo. Para automatización legítima, la conclusión práctica es más incómoda: si necesitás pasar por sistemas con detección seria, usá el motor real (headless browser con stealth) o trabajá con APIs oficiales. El header spoofing solo ya no alcanza.